- 前言
网络应用持续扩张的过程中,为了处理海量数据往往首先遇到的挑战就是数据存储的扩展
数据存储的扩展一般以切分来实现,切分的技术实现又可分为垂直切分和水平切分:
以表(或Schema)为切分粒度的是垂直切分
以表内行为切分粒度的是水平切分
初期扩展使用垂直切分就可以基本解决问题,垂直切分也相对简单,但随着数据行成量级的持续增长,针对这张表的各层面操作性能都会显著降低,此时就不得不进行水平切分了,水平切分就要复杂很多
为了应对此类挑战,就产生了一类新的数据库 NoSQL (Not Only SQL) ,此类的代表有 MongoDB、Redis、Memcached、Elasticsearch ,这类数据库可以轻松应对数据库的扩展(不论是水平还是垂直切分都非常高效),在海量数据的情况下,也能有着极佳的读写性能,NoSQL的根本优势就在于大数据时代易于进行大规模分布式扩展
但是由于NoSQL固有的分布式架构,目前对事务的支持非常弱,存储也是弱结构的,join等复杂操作能力很差,应用场景比较局限
数据库弱了,就意味着,如果要实现一样的特性,应用层面的设计得更复杂才能弥补,这也无形地引入了架构风险
为了使用到关系模型的一些特性(交易或支付的场景,前几年非常火热的去IOE),还是绕不过关系型数据库,但是关系型数据库先天就对分布式支持很弱
简单点可以这么理解:
事务性就是序列化,高并发就是分布式,序列化与并行相背离,所以事务性和分布式很难和谐共处
在事务性和高并发中得有取舍,所以市面上又出现了很多用来进行协调的中间件
- MyCat关键特性
支持SQL92标准
遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。
基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群。
支持Galera for MySQL集群,Percona Cluster或者MariaDB cluster
基于Nio实现,有效管理线程,高并发问题。
支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数,支持跨库分页。
支持单库内部任意join,支持跨库2表join,甚至基于caltlet的多表join。
支持通过全局表,ER关系的分片策略,实现了高效的多表join查询。
支持多租户方案。
支持分布式事务(弱xa)。
支持全局序列号,解决分布式下的主键生成问题。
分片规则丰富,插件化开发,易于扩展。
强大的web,命令行监控。
支持前端作为mysq通用代理,后端JDBC方式支持Oracle、DB2、SQL Server 、 mongodb 、巨杉。
支持密码加密
支持服务降级
支持IP白名单
支持SQL黑名单、sql注入攻击拦截
支持分表(1.6)
集群基于ZooKeeper管理,在线升级,扩容,智能优化,大数据处理(2.0开发版)。
- 什么是MyCat
一个彻底开源的,面向企业应用开发的大数据库集群
支持事务、ACID、可以替代MySQL的加强版数据库
一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
一个新颖的数据库中间件产品
- MyCat架构
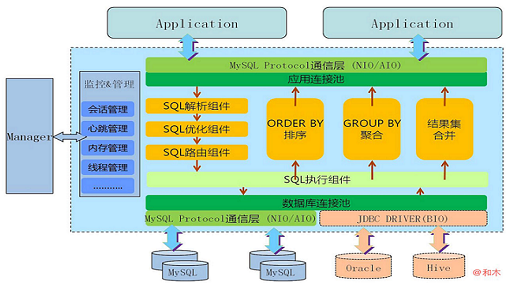
4、MyCat配置
MyCAT 是作为通用代理设计的,后端是以 Mysql协议 和 JDBC 的方式连接数据库,可以支持 Oracle、DB2、SQL Server 、 mongodb、mysql
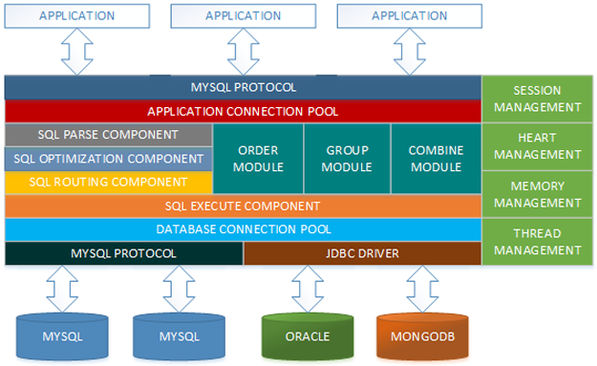
4.1、数据库中间件
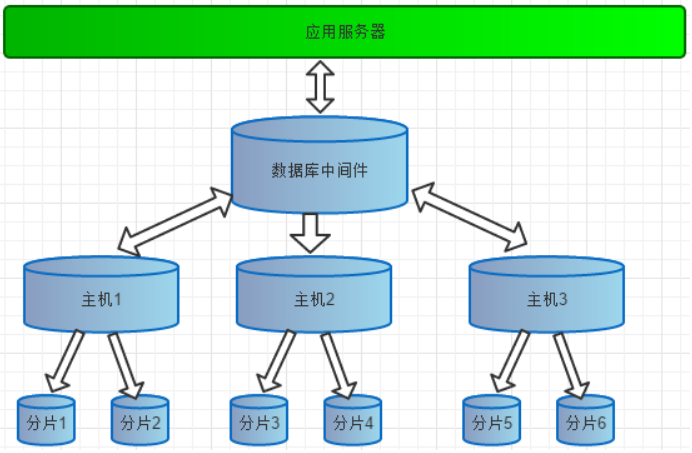
所以Mycat没有存储引擎,本身并不存储数据,只是起到了请求分析,拆解,路由与结果聚合的作用,为前端应用提供统一接口,Mycat 与后端的数据库集群有机组合才一起构成一个分布式数据库系统。
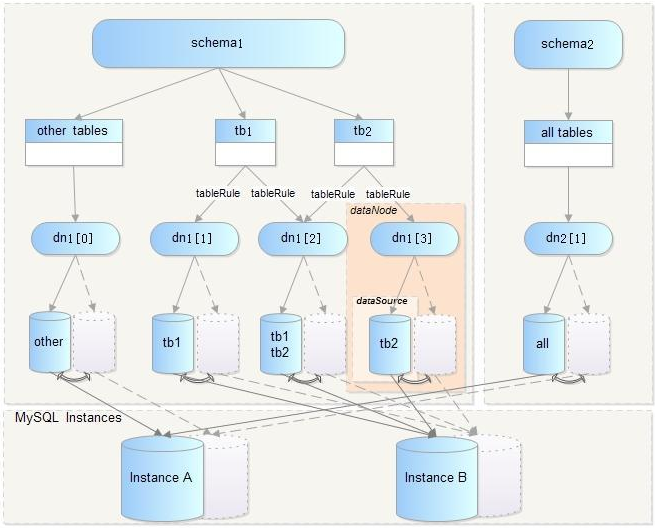
4.2、逻辑库(schema)
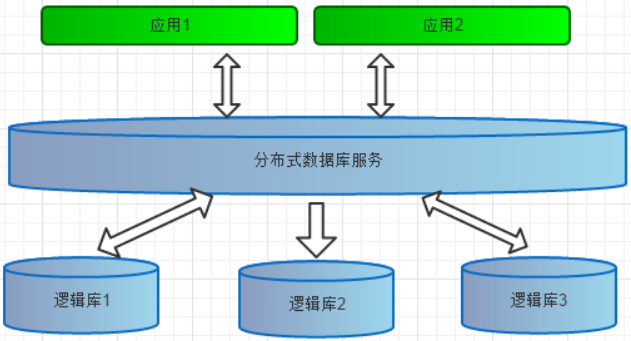
类似于LVM中VG的概念(VG由一个或多个PV构成),逻辑库是由一个或多个后端数据库构成的,展示给应用的是一个单一视图,是分布式数据库在逻辑上的一个抽象
4.3、逻辑表(table)
4.3.1、逻辑表
与数据库中表相对应的,分布式数据表在逻辑上的一个抽象
4.3.2、分片表
数据表切分后的一个部分(原表的一个真子集)
4.3.3、非分片表
没有分片的表,就是非分片表
4.3.4、ER表
保留了实体关系特性的表,就是ER表
关系型数据库是基于实体关系模型的相关理论来构建的数据库,表与表间有依赖关系,通过表分组(Table Group) 让有依赖的表在同一实例库中从而避免了数据Join不会跨库操作
4.3.5、全局表
全局表是所有分片上都有一份完整拷贝的表
字典表或符合字典特性的表可以被设置为全局表
有以下特点的表,被称作字典表:
变动不频繁
数据量总体变化不大
数据规模不大(很少超过十万条记录)
会与其它表发生关联
这类表可以通过冗余来解决join问题,也就是所有的分片都放上一份数据的拷贝来避免跨分片联查
4.4、分片节点(dataNode)
每个表分片所在的数据库就是分片节点
4.5、节点主机(dataHost)
分片节点所在的服务器就是节点主机,尽量将读写压力高的分片节点均衡放在不同的节点主机上,以避免单节点主机并发数限制
4.6、分片规则(rule)
分片规则就是切分数据的规则
4.7、全局序列号(sequence)
保证数据全局唯一性标识的外部机制就是全局序列号
4.8、多租户
多租户技术也叫多重租凭技术,就是在确保用户间数据隔离的前提下实现在多用户环境中共用相同系统或程序等软硬件资源的一种软件架构技术
独立数据库
共享数据库,隔离数据架构
共享数据库,共享数据架构
隔离级别越来越低,共享程度越来越高,均摊成本越来越低
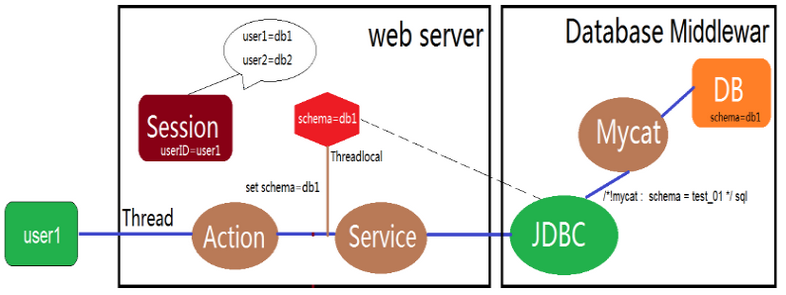
-
- 整体关系
5、MyCat配置
Mycat 的大部分配置都是以 XML 的格式设定的。
| Conf |
Comment |
| conf/wrapper.conf |
JVM运行环境配置 |
| conf/server.xml |
用来定义系统相关变量 |
| conf/schema.xml |
用来定义逻辑库,表,分片节点 |
| conf/rule.xml |
用来定义分片规则 |
5.1、schema.xml配置
| Attribute |
Comment |
| maxCon |
一个读写实例链接池的最大连接数 |
| minCon |
一个读写实例链接池的最小连接数,初始化连接池的大小 |
| balance |
负载均衡类型:0 代表不开启读写分离机制,只使用writeHost; 1 代表readHost与writeHost分担读请求; 2 代表随机分配读请求和1类似; 3 代表只由readHost来承担读请求 |
| writeType |
负载均衡类型:0 代表发到第一个writeHost,挂了后切到还生存的第二个writeHost,重新启动后以切换后的为准,也就是不漂回;1 代表写操作随机发送到writeHost,这样不安全; |
| dbType |
后端数据库类型 |
| dbDriver |
mysql系可以使用native,其它系列得使用JDBC |
| switchType |
切换类型:-1 代表不切换,1 代表自动切换, 2 代表基于主从同步状态决定是否切换 |
| slaveThreshold |
slave读的安全边界,如果Seconds_Behind_Master 大于这个值,这台slave会被临时剔除,以免被读 |
writeHost/readHost
| Attribute |
Comment |
| host |
一个主机标识,便于区分,不必和真实主机名一致 |
| url |
后端实例连接地址 |
| user |
连接账户 |
| password |
连接密码 |
为什么需要mycat
应对大数据量的存储与操作,传统单机单库的数据库无法很好的扩展性切分,架构规模和性能缺陷被放大。
Mycat的目标
解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。2014年上海《中华架构师》大会上对外宣讲,截止2015年4月约估计有60多项目在使用,主要包括电信,互联网,交易管理等领域项目。
Mycat是什么
是一个开源的分布式数据库系统
是一个实现了MySQL协议的服务器,前端可以看做是一个数据库代理,可以通过MySQL的客户端工具访问,后端用MySQL的原生协议与多个MySQL服务器通信,也可以通过JDBC协议与大多数主流数据库服务器通信,其核心是分表分库,即将一个大表水平分割为N个小表,存储在后端MySQL服务器或者其他数据库服务器里。
后端目前支持oracle,sqlserver,db2,postgresql,mysql,也支持mongodb的nosql方式存储,对前端支持标准的SQL语句进行数据操作,可以大幅度的降低前端开发难度,提升开发速度。
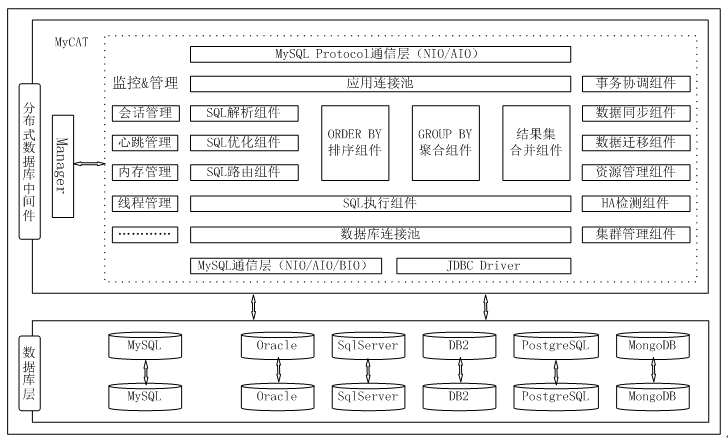
Mycat解决了哪些问题
连接过多导致应用竞争问题,mycat统一管理所有数据源,后端数据库对前端应用透明;
ER关系分片,解决ER分片难处理问题,提高夸节点join的效率;
采用全局分片技术,每个节点同时并发读取、插入和更新数据;
支持基于MySQL主从复制状态的高级读写分离控制机制;
全局表
HBT(Human Brain Tech)人工智能catlet
MyCAT技术原理
拦截,mycat拦截用户发送的SQL语句,对SQL做特定的分析如分片分析,路由分析,读写分离分析,缓存分析等,然后将SQL发往后端的真是数据库,并将返回结果做适当处理,最终返回给用户。
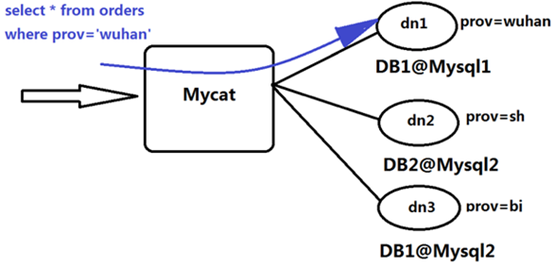
MyCAT的问题:
非分片字段查询
MyCAT中的路由结果是通过分片字段和分片方法来确定的,如果查询条件是分片字段,查询将路由到某个具体的分片上;如果查询条件没有分片字段,MyCAT无法计算路由,便发送到所有节点,随着节点的增多,会消耗更多的数据库资源;
分页排序问题:消耗大量的计算资源;
无法实现任意表join,必须确保相关联的表的关联字段具有相同的分布;
MyCat无法实现事务强一直性;
趋势:数据库应用已经普遍建立于计算机网络之上了
集中式数据库的不足
集中式处理势必造成存储和性能瓶颈
无法高可用;
系统的规模和配置都不够灵活,系统的可扩展性差
Amoeba专注于分布式数据库前端代理层,具有负载均衡,高可用,SQL过滤,读写分离,SQL路由,结果合并等功能,稳定性,性能和功能支持不够好,核心人员的离开
Cobar 基于Amoeba开发,稳定,可靠,优秀的架构设计2013年后没在更新
MyCat 基于Cobar开发,
解决数据存储和业务规模迅速增长的情况下的数据瓶颈问题;
单主机模式:LAMP服务都在一台主机上;
独立主机模式:将web服务器和MySQL服务器分开,分别部署独立主机模式;
读写分离:考虑业务实时性要求,写库不方便横向扩展;
业务垂直拆分:解决高并发下单库写入压力无法分担的问题,单库的压力还没有明显的缓解;
单业务库水平垂直切分:水平拆分横向扩展比较好,对查询挑战比较大;
业务垂直切分,业务无关的关键字水平拆分,不能无限扩展,确定好分库个数后基本不可添加
来源:oschina
链接:https://my.oschina.net/u/3967174/blog/2877530