协方差矩阵
由上,我们已经知道:协方差是衡量两个随机变量的相关程度。且随机变量 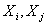 之间的协方差可以表示为:
之间的协方差可以表示为: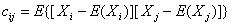
故根据已知的样本值可以得到协方差的估计值如下: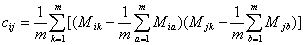
可以进一步地简化为: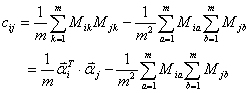
如此,便引出了所谓的协方差矩阵: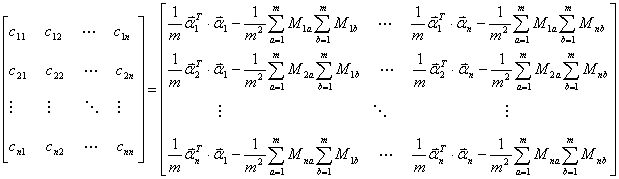
主成成分分析
尽管从上面看来,协方差矩阵貌似很简单,可它却是很多领域里的非常有力的工具。它能导出一个变换矩阵,这个矩阵能使数据完全去相关(decorrelation)。从不同的角度看,也就是说能够找出一组最佳的基以紧凑的方式来表达数据。这个方法在统计学中被称为主成分分析(principal components analysis,简称PCA),在图像处理中称为Karhunen-Loève 变换(KL-变换)。
根据wikipedia上的介绍,主成分分析PCA由卡尔·皮尔逊于1901年发明,用于分析数据及建立数理模型。其方法主要是通过对协方差矩阵进行特征分解,以得出数据的主成分(即特征矢量)与它们的权值(即特征值)。PCA是最简单的以特征量分析多元统计分布的方法。其结果可以理解为对原数据中的方差做出解释:哪一个方向上的数据值对方差的影响最大。
然为何要使得变换后的数据有着最大的方差呢?我们知道,方差的大小描述的是一个变量的信息量,我们在讲一个东西的稳定性的时候,往往说要减小方差,如果一个模型的方差很大,那就说明模型不稳定了。但是对于我们用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。
简而言之,主成分分析PCA,留下主成分,剔除噪音,是一种降维方法,限高斯分布,n维眏射到k维,
- 减均值,
- 求特征协方差矩阵,
- 求协方差的特征值和特征向量,
- 取最大的k个特征值所对应的特征向量组成特征向量矩阵,
投影数据=原始样本矩阵x特征向量矩阵。其依据为最大方差,最小平方误差或坐标轴相关度理论,及矩阵奇异值分解SVD(即SVD给PCA提供了另一种解释)。
也就是说,高斯是0均值,其方差定义了信噪比,所以PCA是在对角化低维表示的协方差矩阵,故某一个角度而言,只需要理解方差、均值和协方差的物理意义,PCA就很清晰了。
再换言之,PCA提供了一种降低数据维度的有效办法;如果分析者在原数据中除掉最小的特征值所对应的成分,那么所得的低维度数据必定是最优化的(也即,这样降低维度必定是失去讯息最少的方法)。主成分分析在分析复杂数据时尤为有用,比如人脸识别。
来源:https://blog.csdn.net/qq_20042935/article/details/100669356