这一篇将会介绍什么是双向递归模型和如何使用双向递归模型实现根据上下文补全句子中的单词。
双向递归模型
到这里为止我们看到的例子都是按原有顺序把输入传给递归模型的,例如传递第一天股价会返回根据第一天股价预测的涨跌,再传递第二天股价会返回根据第一天股价和第二天股价预测的涨跌,以此类推,这样的模型也称单向递归模型。如果我们要根据句子的一部分预测下一个单词,可以像下图这样做,这时 天气 会根据 今天 计算, 很好 会根据 今天 和 天气 计算:
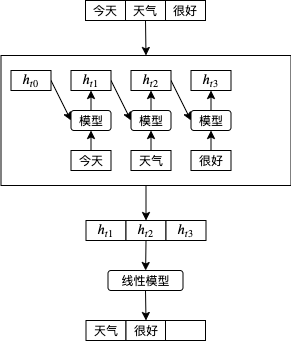
那么如果想要预测在句子中间的单词呢?例如给出 今天 和 很好 预测 天气,因为只能根据前面的单词预测,单向递归模型的效果会打折,这时候双向递归模型就派上用场了。双向递归模型 (BRNN, Bidirectional Recurrent Neural Network) 会先按原有顺序把输入传给递归模型,然后再按反向顺序把输入传给递归模型,然后合并正向输出和反向输出。如下图所示,hf 代表正向输出,hb 代表反向输出,把它们合并到一块就可以实现根据上下文预测中间的内容,今天 会根据反向的 天气 和 很好 计算,天气 会根据正向的 今天 和反向的 很好 计算,很好 会根据正向的 今天 和 天气 计算。

在 pytorch 中使用双向递归模型非常简单,只要在创建的时候传入参数 bidirectional = True 即可:
self.rnn = nn.GRU(
input_size = 20,
hidden_size = 50,
num_layers = 1,
batch_first = True,
bidirectional = True
)
单向递归模型会返回维度为 批次大小,输入次数,隐藏值数量 的 tensor,而双向递归模型会返回维度为 批次大小,输入次数,隐藏值数量*2 的 tensor。
你可能还会有疑问,双向递归模型会怎样处理批次呢?如果批次中每组数据的输入次数都不一样,那么反向计算的时候会不会从那些填充的 0 开始计算呢?以下是一个小实验,我们可以看到反向计算的时候 pytorch 会跳过结尾的填充值,不需要做特殊的处理🥳。
>>> import torch
>>> from torch import nn
>>> x = torch.zeros((3, 3, 1))
>>> lengths = torch.tensor([1, 2, 3])
>>> rnn = torch.nn.GRU(input_size=1, hidden_size=1, batch_first=True, bidirectional=True)
>>> packed = nn.utils.rnn.pack_padded_sequence(x, lengths, batch_first=True, enforce_sorted=False)
>>> output, hidden = rnn(packed)
>>> unpacked, _ = torch.nn.utils.rnn.pad_packed_sequence(output, batch_first=True)
>>> unpacked
tensor([[[0.2916, 0.2377],
[0.0000, 0.0000],
[0.0000, 0.0000]],
[[0.2916, 0.2239],
[0.3949, 0.2377],
[0.0000, 0.0000]],
[[0.2916, 0.2243],
[0.3949, 0.2239],
[0.4263, 0.2377]]], grad_fn=<IndexSelectBackward>)
此外,如果你想使用双向递归模型来实现分类(例如文本情感分类),那么可以只抽出 (torch.gather) 每组数据的最后一个正向隐藏值和第一个反向隐藏值,然后把它们组合 (torch.cat) 一起传递到多层线性模型,尽管大多数情况下单向递归模型足以实现分类功能。提取组合的代码例子如下 (unpacked 来源于上一个例子):
>>> hidden_size = unpacked.shape[2]//2
>>> forward_last = unpacked[:,:,:hidden_size].gather(1, (lengths - 1).reshape(-1, 1, 1).repeat(1, 1, hidden_size))
>>> forward_last
tensor([[[0.2916]],
[[0.3949]],
[[0.4263]]], grad_fn=<GatherBackward>)
>>> backward_first = unpacked[:,:1,hidden_size:]
>>> backward_first
tensor([[[0.2377]],
[[0.2239]],
[[0.2243]]], grad_fn=<SliceBackward>)
>>> combined = torch.cat((forward_last, backward_first), dim=2)
>>> combined
tensor([[[0.2916, 0.2377]],
[[0.3949, 0.2239]],
[[0.4263, 0.2243]]], grad_fn=<CatBackward>)
>>> combined.shape
torch.Size([3, 1, 2])
例子 - 根据上下文补全单词
还记得我们小学语文做的填空题吗,这回我们试试写一个程序帮我们自动填空吧👦,为了这个例子我消耗了一个多月的时间,走了很多冤枉路,下图是最终使用的训练流程和模型结构:
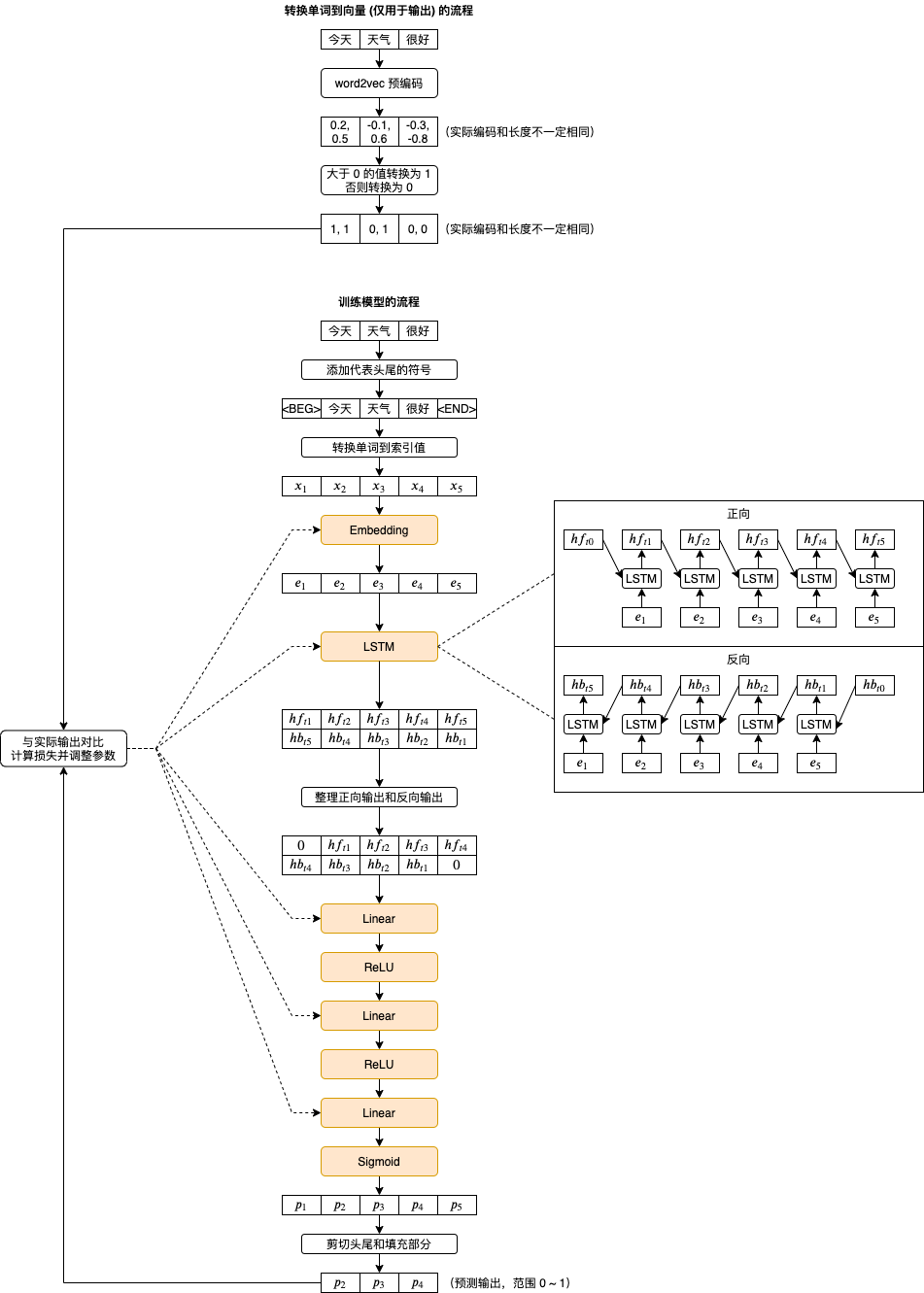
以下是踩过的坑一览🤕:
- 输入和输出的编码需要分开 (使用不同的向量)
- 输入的编码最好不固定 (跟随训练调整),输出的编码需要固定 (否则模型会作弊让所有单词的输出编码相同)
- 输出的编码只能由 0 和 1 组成,不能直接使用浮点数组成的向量 (模型无法调整所有输出到精确的向量,只能调整到方向大致相同的值然后用 Sigmoid 处理)
- 输出的编码向量长度大约 50 以上即可避免 13000 个单词转换到 0 和 1 以后的编码冲突,向量长度越大效果越好但需要更多内存和训练时间
- 每个句子需要添加表示开头和结尾的符号 (
<BEG>与<EOF>),它们会当作预测第一个单词和最后一个单词的输入,比使用 0 效果要好一些 - 输出中表示开头和结尾的向量不参与损失的计算 (预测它们没有意义)
- 根据预测输出的向量查找对应的单词可以计算欧几里得距离,找出距离最接近的单词
- 参数调整器可以使用 Adam,在这个例子中比 Adadelta 快一些
这个例子最大的特点是输出的编码使用了 Embedding 的变种,使得编码近似于 binary。传统的做法是使用 onehot + softmax,但随着单词数量增多需要的处理时间和内存大小会暴增,我目前的机器是训练不过来的。输出编码使用 Embedding 变种的好处还有可以同时找出接近的单词,但计算欧几里得距离的效率会比 onehot + softmax 直接得出最可能单词索引的时间差很多。
首先我们需要使用 word2vec 生成输出使用的编码,来源是京东商品评论(下载地址请参考上一篇文章),每个单词对应一个长度 100 的向量:
import jieba
f = open('chinese.text8', 'w')
for line in open('goods_zh.txt', 'r'):
line = "".join(line.split(',')[:-2])
words = list(jieba.cut(line))
words = [w for w in words if not (w.isascii() or w in (",", "。", "!"))]
words.insert(0, "<BEG>")
words.append("<EOF>")
f.write(" ".join(words))
f.write(" ")
import torch
from gensim.models import word2vec
sentences = word2vec.Text8Corpus('chinese.text8')
model = word2vec.Word2Vec(sentences, size=100)
生成编码以后我们需要把编码中的浮点数转换为 0 或者 1,执行以下代码后编码中小于 0 的值会当作 0,大于或等于 0 的值会当作 1:
v = torch.tensor(model.wv.vectors)
v1 = (v > 0).float()
model.wv.vectors = v1.numpy()
然后再来测试一下编码是否有冲突(两个单词对应完全相同的向量),如果它们输出相同那就代表没有问题:
print("wv shape:", v1.shape)
print("wv unique shape:", v1.unique(dim=0).shape)
最后保存编码模型到硬盘:
model.save("chinese.model")
接下来使用以下代码训练和使用模型:
import os
import sys
import torch
import gzip
import itertools
import jieba
import json
import random
from gensim.models import word2vec
from torch import nn
from matplotlib import pyplot
class MyModel(nn.Module):
"""根据上下文预测句子中的单词"""
def __init__(self, w2v):
super().__init__()
self.hidden_size = 500
self.embedded_in_size = 100
self.embedded_out_size = 100
self.linear_l1_size = 600
self.linear_l2_size = 300
self.embedding_in = nn.Embedding(
num_embeddings=len(w2v.wv.vocab),
embedding_dim=self.embedded_in_size,
padding_idx=0
)
self.rnn = nn.LSTM(
input_size = self.embedded_in_size,
hidden_size = self.hidden_size,
num_layers = 1,
batch_first = True,
bidirectional = True
)
self.linear = nn.Sequential(
nn.Linear(in_features=self.hidden_size*2, out_features=self.linear_l1_size),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(in_features=self.linear_l1_size, out_features=self.linear_l2_size),
nn.ReLU(),
nn.Dropout(0.05),
nn.Linear(in_features=self.linear_l2_size, out_features=self.embedded_out_size),
nn.Sigmoid())
def forward(self, x, lengths):
# 转换单词对应的数值到输入使用的向量
embedded_in = self.embedding_in(x)
# 附加长度信息,避免 RNN 计算填充的数据
packed = nn.utils.rnn.pack_padded_sequence(
embedded_in, lengths, batch_first=True, enforce_sorted=False)
# 使用递归模型计算,接下来的步骤需要所有输出,所以忽略最新的隐藏状态
output, _ = self.rnn(packed)
# output 内部会连接所有隐藏状态,shape = 实际输入数量合计, hidden_size
# 为了接下来的处理,需要先整理 shape = batch_size, 每组的最大输入数量, hidden_size
# 第二个返回值是各个 tensor 的实际长度,内容和 lengths 相同,所以可以省略掉
unpacked, _ = nn.utils.rnn.pad_packed_sequence(output, batch_first=True)
# 整理正向输出和反向输出,例如有 8 个单词,2 个填充
# B 1 2 3 4 5 6 7 8 E 0 0
# 0 B 1 2 3 4 5 6 7 8 E 0 (对应正向)
# 1 2 3 4 5 6 7 8 E 0 0 0 (对应反向)
h = self.hidden_size
hidden_forward = torch.cat((torch.zeros(unpacked.shape[0], 1, h), unpacked[:,:,:h]), dim=1)[:,:-1,:]
hidden_backward = torch.cat((unpacked[:,:,h:], torch.zeros(unpacked.shape[0], 1, h)), dim=1)[:,1:,:]
hidden = torch.cat((hidden_forward, hidden_backward), dim=2)
# 使用多层线性模型推测各个单词以接近原有句子
y = self.linear(hidden)
return y
def calc_loss(self, loss_function, batch_y, predicted, batch_x_lengths):
# 剪切 batch_y 使得维度与 predicted 相同,因为子批次的最大长度可能与批次的最大长度不一致
batch_y = batch_y[:,:predicted.shape[1],:]
# 根据实际长度清零头尾和填充的部分
# 不能就地修改否则会导致 gradient computation has been modified by an inplace operation 错误
mask = torch.ones(predicted.shape)
for index, length in enumerate(batch_x_lengths):
mask[index,0,:] = 0
mask[index,length-1:,:] = 0
predicted = predicted * mask
batch_y = batch_y * mask
return loss_function(predicted, batch_y)
def save_tensor(tensor, path):
"""保存 tensor 对象到文件"""
torch.save(tensor, gzip.GzipFile(path, "wb"))
def load_tensor(path):
"""从文件读取 tensor 对象"""
return torch.load(gzip.GzipFile(path, "rb"))
def load_word2vec_model():
"""读取 word2vec 编码库"""
return word2vec.Word2Vec.load("chinese.model")
def prepare_save_batch(batch, pending_tensors):
"""准备训练 - 保存单个批次的数据"""
# 打乱单个批次的数据
random.shuffle(pending_tensors)
# 划分输入和输出 tensor,另外保存各个输入 tensor 的长度
in_tensor_unpadded = [p[0] for p in pending_tensors]
in_tensor_lengths = torch.tensor([t.shape[0] for t in in_tensor_unpadded])
out_tensor_unpadded = [p[1] for p in pending_tensors]
# 整合长度不等的 tensor 到单个 tensor,不足的长度会填充 0
in_tensor = nn.utils.rnn.pad_sequence(in_tensor_unpadded, batch_first=True)
out_tensor = nn.utils.rnn.pad_sequence(out_tensor_unpadded, batch_first=True)
# 切分训练集 (60%),验证集 (20%) 和测试集 (20%)
random_indices = torch.randperm(in_tensor.shape[0])
training_indices = random_indices[:int(len(random_indices)*0.6)]
validating_indices = random_indices[int(len(random_indices)*0.6):int(len(random_indices)*0.8):]
testing_indices = random_indices[int(len(random_indices)*0.8):]
training_set = (in_tensor[training_indices], in_tensor_lengths[training_indices], out_tensor[training_indices])
validating_set = (in_tensor[validating_indices], in_tensor_lengths[validating_indices], out_tensor[validating_indices])
testing_set = (in_tensor[testing_indices], in_tensor_lengths[testing_indices], out_tensor[testing_indices])
# 保存到硬盘
save_tensor(training_set, f"data/training_set.{batch}.pt")
save_tensor(validating_set, f"data/validating_set.{batch}.pt")
save_tensor(testing_set, f"data/testing_set.{batch}.pt")
print(f"batch {batch} saved")
def prepare():
"""准备训练"""
# 数据集转换到 tensor 以后会保存在 data 文件夹下
if not os.path.isdir("data"):
os.makedirs("data")
# 准备词语到数值的索引
w2v = load_word2vec_model()
beg_index = w2v.wv.vocab["<BEG>"].index
eof_index = w2v.wv.vocab["<EOF>"].index
# 提前转换输出的编码
embedding_out = nn.Embedding.from_pretrained(torch.FloatTensor(w2v.wv.vectors))
# 从 txt 读取原始数据集,分批每次处理 2000 行
# 这里使用原始方法读取,最后一个标注为 1 代表好评,为 0 代表差评
batch = 0
pending_tensors = []
for line in open("goods_zh.txt", "r"):
parts = line.split(',')
phase = ",".join(parts[:-2])
positive = int(parts[-1])
# 使用 jieba 分词,然后转换单词到索引
words = jieba.cut(phase)
word_indices = [beg_index] # 代表语句开始
for word in words:
vocab = w2v.wv.vocab.get(word)
if vocab:
word_indices.append(vocab.index)
word_indices.append(eof_index) # 代表语句结束
if len(word_indices) <= 2:
continue # 没有单词在编码库中
# 输入是各个句子对应的索引值列表,输出是各个各个句子对应的向量列表
tensor_in = torch.tensor(word_indices)
tensor_out = embedding_out(tensor_in)
pending_tensors.append((tensor_in, tensor_out))
if len(pending_tensors) >= 2000:
prepare_save_batch(batch, pending_tensors)
batch += 1
pending_tensors.clear()
if pending_tensors:
prepare_save_batch(batch, pending_tensors)
batch += 1
pending_tensors.clear()
def train():
"""开始训练"""
# 创建模型实例
w2v = load_word2vec_model()
model = MyModel(w2v)
# 创建损失计算器
loss_function = torch.nn.BCELoss()
# 创建参数调整器
optimizer = torch.optim.Adam(model.parameters())
# 记录训练集和验证集的正确率变化
training_accuracy_history = []
validating_accuracy_history = []
# 记录最高的验证集正确率
validating_accuracy_highest = -1
validating_accuracy_highest_epoch = 0
# 读取批次的工具函数
def read_batches(base_path):
for batch in itertools.count():
path = f"{base_path}.{batch}.pt"
if not os.path.isfile(path):
break
yield load_tensor(path)
# 计算正确率的工具函数,除去头尾和填充值
def calc_accuracy(actual, predicted, lengths):
acc = 0
for x in range(len(lengths)):
l = lengths[x]
predicted_record = (predicted[x][1:l-1] > 0.5).int()
actual_record = actual[x][1:l-1].int()
acc += (predicted_record == actual_record).sum().item() / predicted_record.numel()
acc /= len(lengths)
return acc
# 划分输入和长度的工具函数
def split_batch_xy(batch, begin=None, end=None):
# shape = batch_size, input_size
batch_x = batch[0][begin:end]
# shape = batch_size, 1
batch_x_lengths = batch[1][begin:end]
# shape = batch_size. input_size, embedded_size
batch_y = batch[2][begin:end]
return batch_x, batch_x_lengths, batch_y
# 开始训练过程
for epoch in range(1, 10000):
print(f"epoch: {epoch}")
# 根据训练集训练并修改参数
# 切换模型到训练模式,将会启用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.train()
training_accuracy_list = []
for batch_index, batch in enumerate(read_batches("data/training_set")):
# 切分小批次,有助于泛化模型
training_batch_accuracy_list = []
for index in range(0, batch[0].shape[0], 100):
# 划分输入和长度
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch, index, index+100)
# 计算预测值
predicted = model(batch_x, batch_x_lengths)
# 计算损失
loss = model.calc_loss(loss_function, batch_y, predicted, batch_x_lengths)
# 从损失自动微分求导函数值
loss.backward()
# 使用参数调整器调整参数
optimizer.step()
# 清空导函数值
optimizer.zero_grad()
# 记录这一个批次的正确率,torch.no_grad 代表临时禁用自动微分功能
with torch.no_grad():
training_batch_accuracy_list.append(calc_accuracy(batch_y, predicted, batch_x_lengths))
# 输出批次正确率
training_batch_accuracy = sum(training_batch_accuracy_list) / len(training_batch_accuracy_list)
training_accuracy_list.append(training_batch_accuracy)
print(f"epoch: {epoch}, batch: {batch_index}: batch accuracy: {training_batch_accuracy}")
training_accuracy = sum(training_accuracy_list) / len(training_accuracy_list)
training_accuracy_history.append(training_accuracy)
print(f"training accuracy: {training_accuracy}")
# 检查验证集
# 切换模型到验证模式,将会禁用自动微分,批次正规化 (BatchNorm) 与 Dropout
model.eval()
validating_accuracy_list = []
for batch in read_batches("data/validating_set"):
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch)
predicted = model(batch_x, batch_x_lengths)
validating_accuracy_list.append(calc_accuracy(batch_y, predicted, batch_x_lengths))
validating_accuracy = sum(validating_accuracy_list) / len(validating_accuracy_list)
validating_accuracy_history.append(validating_accuracy)
print(f"validating accuracy: {validating_accuracy}")
# 记录最高的验证集正确率与当时的模型状态,判断是否在 20 次训练后仍然没有刷新记录
if validating_accuracy > validating_accuracy_highest:
validating_accuracy_highest = validating_accuracy
validating_accuracy_highest_epoch = epoch
save_tensor(model.state_dict(), "model.pt")
print("highest validating accuracy updated")
elif epoch - validating_accuracy_highest_epoch > 20:
# 在 20 次训练后仍然没有刷新记录,结束训练
print("stop training because highest validating accuracy not updated in 20 epoches")
break
# 使用达到最高正确率时的模型状态
print(f"highest validating accuracy: {validating_accuracy_highest}",
f"from epoch {validating_accuracy_highest_epoch}")
model.load_state_dict(load_tensor("model.pt"))
# 检查测试集
testing_accuracy_list = []
for batch in read_batches("data/testing_set"):
batch_x, batch_x_lengths, batch_y = split_batch_xy(batch)
predicted = model(batch_x, batch_x_lengths)
testing_accuracy_list.append(calc_accuracy(batch_y, predicted, batch_x_lengths))
testing_accuracy = sum(testing_accuracy_list) / len(testing_accuracy_list)
print(f"testing accuracy: {testing_accuracy}")
# 显示训练集和验证集的正确率变化
pyplot.plot(training_accuracy_history, label="training")
pyplot.plot(validating_accuracy_history, label="validing")
pyplot.ylim(0, 1)
pyplot.legend()
pyplot.show()
def eval_model():
"""使用训练好的模型"""
# 读取 word2vec 编码库
w2v = load_word2vec_model()
# 创建模型实例,加载训练好的状态,然后切换到验证模式
model = MyModel(w2v)
model.load_state_dict(load_tensor("model.pt"))
model.eval()
# 获取单词索引到向量的 tensor
embedding_tensor = torch.tensor(w2v.wv.vectors)
# 查找最接近单词数量的函数,根据欧几里得距离比较
# 也可以使用 w2v.wv.similar_by_vector
def find_similar_words(target_tensor):
top_words = 10
similar_words = []
for word, vocab in w2v.wv.vocab.items():
index = vocab.index
distance = torch.dist(embedding_tensor[index], target_tensor, 2).item()
if len(similar_words) < top_words or distance < similar_words[-1][1]:
similar_words.append((word, distance))
similar_words.sort(key=lambda v: v[1])
if len(similar_words) > top_words:
similar_words.pop()
return similar_words
# 询问输入并预测输出
# __ 为预测目标,例如下次还来__购买 表示预测 __ 处的单词,只支持一个预测目标
while True:
try:
phase = input("Sentence: ")
phase = phase.replace("\t", "").replace("__", "\t")
if "\t" not in phase:
raise ValueError("Please use __ to represent predict target")
if phase.count("\t") > 1:
raise ValueError("Please only use one predict target")
# 分词
words = list(jieba.cut(phase))
# 转换到数值列表
word_indices = [1] # 代表语句开始
for word in words:
if word == '\t':
word_indices.append(0) # 预测目标
continue
vocab = w2v.wv.vocab.get(word)
if vocab:
word_indices.append(vocab.index)
word_indices.append(2) # 代表语句结束
if len(word_indices) <= 2:
raise ValueError("No known words")
# 构建输入
x = torch.tensor(word_indices).reshape(1, -1)
lengths = torch.tensor([len(word_indices)])
# 预测输出
predicted = model(x, lengths)
# 找出最接近的单词一览
target_index = word_indices.index(0)
target_tensor = (predicted[0, target_index] > 0.5).float()
similar_words = find_similar_words(target_tensor)
for word, distance in similar_words:
print(word, distance)
except Exception as e:
print("error:", e)
def main():
"""主函数"""
if len(sys.argv) < 2:
print(f"Please run: {sys.argv[0]} prepare|train|eval")
exit()
# 给随机数生成器分配一个初始值,使得每次运行都可以生成相同的随机数
# 这是为了让过程可重现,你也可以选择不这样做
random.seed(0)
torch.random.manual_seed(0)
# 根据命令行参数选择操作
operation = sys.argv[1]
if operation == "prepare":
prepare()
elif operation == "train":
train()
elif operation == "eval":
eval_model()
else:
raise ValueError(f"Unsupported operation: {operation}")
if __name__ == "__main__":
main()
执行以下命令准备训练需要的数据和开始训练:
python3 example.py prepare
python3 example.py train
训练结果如下(使用 CPU 训练需要大约两天时间🤢),这里的正确率代表预测输出和实际输出向量中有多少个值是相等的:
training accuracy: 0.8106725109454498
validating accuracy: 0.7361285656628191
stop training because highest validating accuracy not updated in 20 epoches
highest validating accuracy: 0.7382469316157465 from epoch 18
testing accuracy: 0.7378169895469142
执行以下命令可以使用训练好的模型:
python3 example.py eval
以下是一些使用例子,__ (两个下划线)代表预测目标的单词,会输出最接近的 10 个单词:
Sentence: 衣服质量__哦
不错 0.0
很棒 3.872983455657959
挺不错 4.0
物有所值 4.582575798034668
物超所值 4.795831680297852
很赞 4.795831680297852
超好 4.795831680297852
太好了 4.795831680297852
好 5.0
太棒了 5.0
Sentence: 鞋子轻便__,好穿,值得推荐。
修身 3.316624879837036
身材 3.464101552963257
显 3.464101552963257
贴身 3.464101552963257
休闲 3.605551242828369
软和 3.605551242828369
保暖 3.7416574954986572
凉快 3.7416574954986572
柔软 3.7416574954986572
轻快 3.7416574954986572
Sentence: 鞋子轻便舒服,好穿,值得__。
拥有 3.316624879837036
够买 3.605551242828369
信赖 3.7416574954986572
购买 4.242640495300293
信耐 4.582575798034668
推荐 4.795831680297852
入手 4.795831680297852
表扬 4.795831680297852
点赞 5.0
下手 5.0
Sentence: 鞋子轻便舒服,好穿,__推荐。
值得 1.4142135381698608
放心 4.690415859222412
值 4.795831680297852
物美价廉 5.099019527435303
价廉物美 5.099019527435303
价格便宜 5.196152210235596
加油 5.196152210235596
一百分 5.196152210235596
很赞 5.196152210235596
赞赞赞 5.196152210235596
Sentence: 发货__很赞,东西也挺好
速度 2.4494898319244385
迅速 4.898979663848877
给力 5.0
力 5.0
价格便宜 5.0
没得说 5.196152210235596
超值 5.196152210235596
很赞 5.196152210235596
小哥 5.291502475738525
小巧 5.291502475738525
Sentence: 半个月就出现这问题 ,__直接说找附近站点售后 ,浪费时间,还得自己修,差评一个
客服 0.0
商家 4.690415859222412
卖家 4.898979663848877
售后 5.099019527435303
没人 5.099019527435303
店家 5.196152210235596
补发 5.291502475738525
人工 5.291502475738525
客户 5.385164737701416
机器人 5.385164737701416
Sentence: 不错给老公买了好几个了,穿着特别__
舒服 0.0
舒适 3.316624879837036
挺舒服 4.242640495300293
帅气 4.690415859222412
脚疼 4.690415859222412
很帅 4.795831680297852
凉快 4.898979663848877
合身 5.0
暖和 5.099019527435303
老公 5.291502475738525
Sentence: 不错给__买了好几个了,穿着特别舒服
老爸 2.8284270763397217
爸爸 3.0
弟弟 3.0
妹妹 3.0
女朋友 3.0
男朋友 3.1622776985168457
老妈 3.1622776985168457
女儿 3.316624879837036
表弟 3.316624879837036
家人 3.316624879837036
可以看到预测出来的效果还不错😈,尽管部分语句没有完全准确的预测出原有的单词但是语义很接近。如果你想得到更好的效果,可以增加输出向量长度 (word2vec 生成时的 size 参数,对应 embedded_out_size),输入向量长度(embedded_in_size),和模型的隐藏值数量(hidden_size, linear_l1_size, linear_l2_size),但会需要更多的训练时间和内存🤢。
写在最后
关于递归模型就介绍到这里了,下一篇开始将会介绍适合处理图像的卷积神经网络 (CNN) 模型,敬请期待。
本来想买台带显卡 (支持 CUDA) 的机器减少训练所需的时间,但是黄脸婆不允许🥵,估计一段时间内只能继续用 CPU 训练了。
来源:oschina
链接:https://my.oschina.net/u/4397293/blog/4329779