
来源:arxiv
编辑:雅新
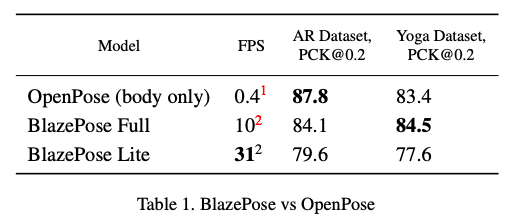
【新智元导读】谷歌研究人员最近在CVPR 2020上发表的一篇论文提出了用于边缘设备上运行的单人人体姿态估计算法BlazePose。该算法在中端手机CPU上的性能比20核桌面CPU上的OpenPose还要快25-75倍。
根据图像或视频进行人体姿势估计在如健康跟踪、手语识别等实际应用中起着核心作用。由于个体会做出各种各样的姿势,此任务具有极大的挑战性。
谷歌研究人员最近在 CVPR 2020 上发表的一篇论文
提出了用于边缘设备上运行的单人人体姿态估计算法BlazePose
。
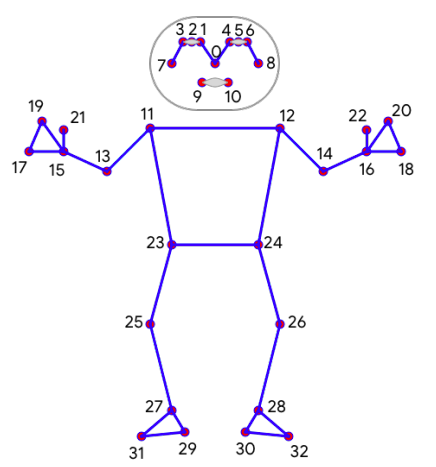
在推断过程中,采用推断身体33个关键点的轻量卷积网络,用编解码器直接推断边框,并在Pixel 2手机上推断速度可达到30fps。BlazePose在中端手机CPU上性能比20核桌面CPU上的OpenPose还要快25-75倍。
论文地址:https://arxiv.org/pdf/2006.10204.pdf
用面部检测器代替身体检测器,速度超OpenPose
最近的研究工作在姿势估计方面有了重大进展。而这些进展大都采用的方法是为每个关节生成热图以及每个坐标精炼偏移量。
虽然这种选择的热图可以扩展到多个人,但它使一个人的模型比适用于手机上的实时推断的模型大得多。而谷歌研究人员在此解决了这个特殊的用例,并演示了该模型的显著加速,而几乎没有质量下降。
与基于热图的技术相比,基于回归的方法虽然对计算的要求较低且可扩展性更高,但它们试图预测平均坐标值,但往往无法解决潜在的歧义。
研究人员在人体姿态估计上和之前的做法有很大的不同。
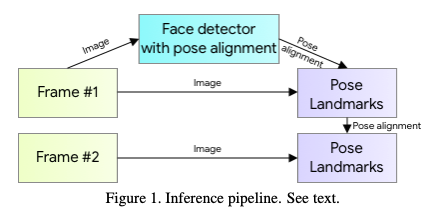
使用面部检测器而不是人体检测器检测人体。
研究人员发现,由于使用身体检测器容易受场景中密集人群遮挡的影响,如果在遮挡严重状态下,身体检测器的信任值不会很高。
但是人的脸部比起全身就不容易被遮挡,而且在神经网络中这一部分的响应值往往是最高的。
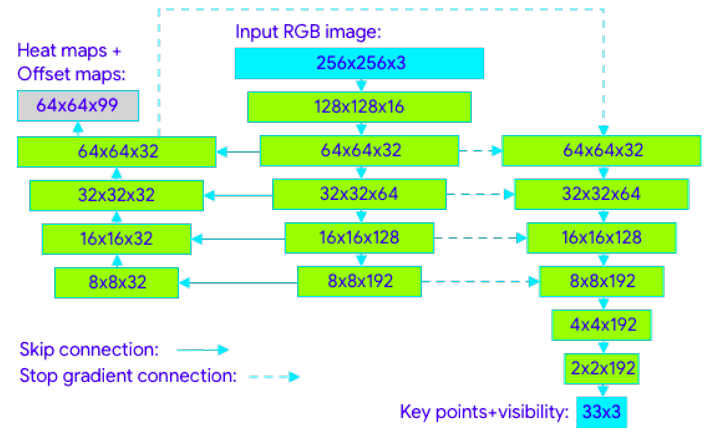
网络是有两个部分组成,分别是关键点检测部分和关键点回归部分。
这个网络新颖的地方在于,在训练阶段,关键点检测和回归一起训练。
在测试的时候,去掉检测部分,仅保留回归部分,这样可以加快运行速度。
研究人员通过实验证明了这种方法在大幅加速的同时也没有损失精度,网络结构如下:
除此之外,研究人员在训练阶段根据模型的应用场景,针对性的对数据增强部分做了限制,这样降低了模型学习复杂场景的能力,但能让模型更快的去学习真实场景下的数据。除了姿势检测部分,整体模型还包含了一个pose tracker用来做跟踪。
如果在当前姿势检测器能够预测到下一帧中姿势位置的时候,姿势检测器就不会运行,会一直使用姿势追踪器的结果,否则就会运行检测器,并重新初始化追踪器。
研究人员最后在自己创建的数据集上,将自己的模型和OpenPose的做了比较,速度远超OpenPose精度略差。
研究人员开发了这种新的,在设备上单人特定的人体姿势估计模型,可以支持各种性能要求高的用例,例如手势,健身跟踪和AR。
该模型在移动CPU上几乎实时工作,并且可以在移动GP
U上加快超实时延迟。
研究人员表示,「即使参数数量较少,堆叠式沙漏架构也可以显着提高预测质量。我们在工作中扩展了这个想法,并使用编码器-解码器网络体系结构预测所有关节的热图,然后使用另一个编码器直接回归到所有关节的坐标。我们工作背后的关键点是可以在推理过程中丢弃热图分支,使其足够轻巧,可以在手机上运行。」
参考链接:
https://arxiv.org/abs/2006.10204
https://www.arxiv-vanity.com/papers/2006.10204/
推荐阅读
谷歌小姐姐开源姿势动画师项目,组合现有TF模型,只需一张SVG图片便可配置
点击“阅读原文”图书配套资源
本文分享自微信公众号 - 相约机器人(xiangyuejiqiren)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
来源:oschina
链接:https://my.oschina.net/u/3267804/blog/4429173

 论文地址:https://arxiv.org/pdf/2006.10204.pdf
论文地址:https://arxiv.org/pdf/2006.10204.pdf


 点击“阅读原文”图书配套资源
点击“阅读原文”图书配套资源