文章目录
Nguyen, D. B., et al. (2017). J-REED: Joint Relation Extraction and Entity Disambiguation. Proceedings of the 2017 ACM on Conference on Information and Knowledge Management - CIKM '17: 2227-2230.
提取+嵌入+消歧联合模型
abstract
从文本源中提取信息(IE)既可以作为基于模型的IE(即通过使用目标实体和关系的预定域)执行,也可以作为开放式IE(即对目标域没有特殊假设)执行。虽然基于模型的IE的覆盖范围有限,但是Open IE只能产生三元组的表面短语,通常不会将它们模糊化为一组规范的实体和关系。本文介绍了J-REED:一种基于概率图形模型的实体歧义和关系提取联合方法。通过将表面名称映射到背景知识库,并使表面关系尽可能清晰,J-REED融合了来自基于模型和Open IE的思想。
- IE提取信息
- open IE
- 智能产生三元组的表面短语,不规范
- 基于模型的IE
- 覆盖范围有限
- J-REED:
- 基于概率图模型
- 实体消歧+关系抽取
- 规范化:表面名映射到背景知识库,使表面关系尽可能清晰
- 结合open IE和基于模型的IE
- open IE
1. INTRODUCTION & RELATED WORK
动机。信息提取(IE)旨在从自然语言文本中提取关系三元组,每个三元组由一个实体对(或一个实体和一个文字值)以及一个连接关系组成。此目标已通过两种主要方法实现。基于模型的IE [5、7、8、18、23、25]集中于一组预先指定的关系,例如存在于知识库(KB)中的关系,例如DBpedia [1],NELL [7]或Yago [24]。通过将输入名称中识别的实体名称映射到KB中的适当实体,可以消除歧义。关系具有细粒度的类型签名,需要由分配的实体进行匹配。基于模型的IE技术利用此策略来实现高精度,但是它们在召回方面固有地受到相对少量给定关系的限制。另一方面,开放式IE [2,10,17]提取了表面短语的三倍,从而实现了较高的查全率。它可以潜在地找到两个参数之间的任何关系。但是,这些论点没有被规范化,并且由此产生的关系常常是嘈杂的。
- 动机
- 信息提取IE:提取三元组
- 基于模型的方法
- 提取并映射到KB中相应实体上消歧
- 关系需要有分配的实体进行匹配
- 高精度,低召回率(受到少量给定关系的限制)
- open IE
- 提取的是表面短语,不限制关系数量
- 召回率高
- 未规范化,产生的关系嘈杂
- 基于模型的方法
- 信息提取IE:提取三元组
Example. Consider the following four input sentences:
(1) Amy received the Oscar for the best documentary
(2) Amy received the Grammy for the best new artist.
(3) Amy received her degree in neurobiology from Harvard.
(4) Simone received honorary degrees in music and humanities, from both UMass Amherst and Malcolm X College.
句子(1),(2)和(3)指的是不同的实体-电影,歌手和电影角色-都被命名为“艾米”。这些句子提供了识别词汇类型的线索,但是没有现有的IE方法可以稳健地处理这种情况。此外,(3)和(4)用不同的短语表示相同的关系(即“从…接收学位”),但是Open IE会将它们视为独立的关系。
- 最新技术和局限性
- 调和基于模型的IE和openIE
- Hoffmann et al. [15]
- 根据关系的自变量和类型标签对他们聚类,处理数千个关系
- 特定于wikepedia
- Galárraga等。 [13]:
- 名词短语聚类->自变量(实体)
- 动词短语聚类->关系
- 缺点:使用freebase为后端,仅限于数百个关系集群
- Li and Ji [16]
- 联合抽取关系和实体,但无消歧
- 不足:
- 未考虑过将实体消歧和关系抽取结合起来,以利用词法类型与关系类型的耦合
- Hoffmann et al. [15]
- 调和基于模型的IE和openIE
最新技术和局限性。最近的工作旨在调和基于模型的IE和Open IE。霍夫曼等。 [15]提出了一种远程监督的IE系统,该系统可以通过根据关系参数的自变量和类型签名对它们进行聚类来处理数千个关系(例如,在实验中使用1,282个此类聚类)。但是,此方法高度定制,可以使用Wikipedia信息框作为输入。Galárraga等。 [13]通过将名词短语聚类为参数,将语言短语聚类为关系来规范化Open IE三元组。但是,通过使用Freebase [4]作为关系的后端,此方法仅限于数百个关系集群。另一方面,Li和Ji [16]联合提取实体和关系名称,但不要对它们进行歧义。
在先的工作都没有考虑联合推理来一步一步地提取关系并消除实体的歧义。相反,所有先前的工作都使用流水线架构,因此无法充分利用实体的词法类型与关系的类型签名的耦合。例如,要正确地区分上述示例(2)和(3)中的实体Amy_Winehouse和Amy_Farrah_Fowler,理解关系“receive prize” (SINGER × MUSIC AWARD) and “receive degree from” (PERSON × UNIVERSITY)的不同类型签名至关重要。本文提出的方法可以利用这些相互依存关系
- 贡献
- 提出J-REED:消歧+关系抽取
- 实体名称映射到后台KB(DBPedia)中的实体id
- 关系模式尽可能清晰地提取
- 效果好
贡献。本文介绍了J-REED,这是一种用于Wikipedia风格的输入文本的实体消歧和关系提取的联合模型。J-REED基于概率图形模型,该模型捕获了实体和关系之间的相互依赖性。具体而言,通过考虑实体的哪些词汇类型与哪种关系的类型签名兼容,我们可以提高两个子任务的准确性。实体名称映射到在后台KB中注册的实体(在我们的实验中使用DBpedia),而关系模式则尽可能地清晰地提取。我们对120万个有关PERSON类型实体的Wikipedia页面进行了大规模实验,并获得了约950万个三元组。 80%的准确性。J-REED的性能始终优于OLLIE [17],最先进的Open IE系统以及最近的NED系统(如Babelfy [19]和Spotlight [9])的流水线组
- J-REED
- 消歧+关系抽取
- 输入:wikipedia风格的文本
- 基于:概率图
- 捕获:实体和关系之间的相互依赖型
- 关系的自变量类型约束
- 步骤
- 预处理(共现)
- 随后用于挖掘关系模式
- 可充当关系模式标记
- 联合关系抽取和实体消歧的特征函数的输入
通过将这些预处理步骤应用到专用的开发语料库(与我们的实验中使用的测试文档的集合不相交),我们还可以计算名词,动词,介词和实体之间的各种(共现)统计信息。这些统计信息随后用于挖掘关系模式(第3节),并且进一步充当用于关系模式标记(第4节),联合关系提取和实体消歧(第5节)的特征函数的输入。
- 预处理(共现)
2 DOCUMENT PROCESSING
J-REED分几个步骤处理文本语料库。我们首先通过标准的NLP管道传递所有文档,包括令牌化,POS标记,依赖项解析,NER标记和自定义名词短语组块器。具体来说,我们将Stanford CoreNLP工具套件用于所有文本处理步骤(依赖项解析除外)。对于后者,我们使用MaltParser [22],它比斯坦福解析器更有效。文本中的提及名称主要由Stanford NER [12]标记器识别
- 标准nlp pipeline:
- 预处理可得到共现统计信息
* 随后用于挖掘关系模式
* 可充当关系模式标记
* 联合关系抽取和实体消歧的特征函数的输入 - 步骤
- tokenization,
- POS tagging,
- dependency parsing, (MaltParser [22])
- NER tagging,(识别了mention)
- a customized noun-phrase chunker.
- 工具:
- MaltParser [22]:依赖解析
- 其他:Stanford CoreNLP工具套件
- 自实现:a customized noun-phrase chunker.
- (在POS标签上使用一组正则表达式)
- 提取了NER没有提取的名词短语
- 降噪:仅保留信息性名词短语
- 信息性名词短语:出现频率在5%以上的名词短语
- 作用:提取文中ner没有提取到的实体提及(候选)
- 预处理可得到共现统计信息
此外,我们实现了一个自定义的名词短语组块器(在POS标签上使用一组正则表达式),还提取了与NER标记程序提取的任何名称都不重叠的名词短语。我们通过仅保留那些至少包含一个信息性名词的短语来消除所获得的名词短语中的噪音,我们将其定义为由当前文档中排名前5%的频率最高的名词组成。例如,在的Wikipedia文章中,信息最丰富的名词包含“专辑”,“酒精”等。因此,即使NER tagger错过了该短语,“酒精中毒”(即,她的死因)这个名词短语也被认为是提及。
通过将这些预处理步骤应用到专用的开发语料库(与我们的实验中使用的测试文档的集合不相交),我们还可以计算名词,动词,介词和实体之间的各种(共现)统计信息。这些统计信息随后用于挖掘关系模式(第3节),并且进一步充当用于关系模式标记(第4节),联合关系提取和实体消歧(第5节)的特征函数的输入。
3 RELATION PATTERN MINING
- 关系模式挖掘
- J-REED:考虑四种关系模式
- verb (e.g., marry),
- verb-noun (e.g., win prize),
- verb-preposition (e.g. play for)
- verb-noun-preposition (e.g., win prize for)
- 语态
- 主动语态:中的名词,介词和动词以其词素化(形容词)形式(例如结婚)考虑。
- 被动语态:中的动词由其过去分词(例如已婚)表示,以捕捉关系的反方向。
- 缩小范围:取至少出现过次的关系模式
- 提取的关系模式,作为下一阶段(概率图模型)的输入(进一步提纯),可获得更简洁的关系模式(更泛化
- J-REED:考虑四种关系模式
J-REED考虑四种类型的关系模式:动词(例如结婚),动词-名词(例如获胜),动词介词(例如play for)和动词-介词(例如获胜)。主动语态中的名词,介词和动词以其词素化形式(例如结婚)考虑。被动语态中的动词由其过去分词(例如已婚)表示,以捕捉关系的反方向。J-REED只考虑在发展语料库中至少发生τ次的频繁关系模式。在我们的实验中,我们设置并获得了9,248个频繁模式(在320,143个不同的模式中)。通过仅将这些模式视为下一部分中图形模型的关系候选,J-REED可以提取简洁的关系模式。例如,J-REED提取了关系模式“从……获得学位”,而不是许多其他Open IE方法所考虑的表面短语“从……获得音乐和人文学科的荣誉学位”。这对于进一步的应用程序(例如知识库结构,问题解答等)很有用。
4 RELATION PATTERN LABELING
为了从测试语料库中的句子中提取一种关系模式,我们将两次提及之间的依存路径视为令牌序列。因此,从句子中提取关系可以看作是序列标记任务,我们的目标是通过使用四个标记来找到标记的最佳序列:N代表所选名词,V代表所选动词,P代表介词,以及O代表“其他”。每个关系模式必须包含一个V标签,其中V标签最多包含一个N标签,P标签最多包含一个P标签。为了提高召回率,J-REED考虑了另外两种启发式方法。
- 提取关系模式
- token序列:两个提及词之间的依存路径
- 任务转化:序列标注任务
- 标记:N名词,V动词,P介词,O其他
- 每个关系模式:必须有一个V,之多一个N,至多一个P
- 提高recall的启发式方法
- 如果“Mary’s son Bill Gates”出现,则添加have-V(Mary have son)
- 如果没有V,则添加be-V
- 线性链CRF
- 特征集:标记,POS标签,大写/小写字母,第一个动词,最后一个介词,英语单词,在介词“ to”之后,在动词之后,在任何带有标签“ NNP”的令牌之后,以及上一个标签
- 训练:L-BFGS优化最大化条件似然函数[26]来训练CRF
- 预测:Exact inference 精确的推论是可行的,这是维特比动态编程算法的一种变体[3]
- 如果仅考虑最可能的关系候选,此方法类似于OpenIE
- 区别:在下一部分描述的联合模型中,所有关系模式候选(及其权重)都被视为特征。
- If only one N label is returned under the text pattern NAMELEFT’s noun NAME-RIGHT (e.g. “Mary’s son Bill Gates”), we add “have” with label V to the beginning of the sequence (e.g., “have son”).
- If no V label is returned after an apposition, we add “be” with label V to the beginning of the sequence (e.g., “be daughter of”).
5 JOINT MODEL
- 联合模型
- 输入:mention-pair+两个提及之间依存路径的token
- 输出:r(e1,e2)
- r由4中CRF得到
- 实体候选:命名实体词典
- 词典来自wikipedia的链接和表面形式
- 为了提高召回率,词典包含了wikipedia的所有人名
- 特征:
- 一个用于关系提取的特征
- 关系优先
- 三个用于实体歧义消除的特征
- 提及实体优先,
- 提及实体令牌上下文相似性和
- 实体-实体令牌上下文相似性
- 一个特征联合推断
- 类型签名
- 用了数千种的类型签名扩展了的
- 定义为:在关系模式下两个实体的语义类型出现的相对频率
- 频率统计信息:来自开发数据集
- NER,PERSON,ORGANIZATION,LOCATION和MISC,还有出现频次多的信息框类型(在wikipeidia的1000个以上的文档中出现过)
- 这些关系手动层次化
- (e.g. FOOTBALLER ⊆ SPORTS-PERSON ⊆ PERSON).
- 类型签名
- 不考虑实体消歧常用特征
- 面向领域的功能[20]:在Wikipedia样式的文本中效率较低,
- 句法依赖性功能[21]:因为嵌入了类型签名。
- 类型签名的功能:捕获实体(即参数)之间的类型依赖性以及这些实体之间的关系模式
- 数本文用数千种关系的类型签名来扩展这个技术
- 一个用于关系提取的特征
- 目标函数:
6 EXPERIMENTS
6.1 Corpora
- 适用于任何以实体为中心的语料库
- 实验中使用有关人的Wikipedia文章
- Wikipedia-develop
- J-REEDtrain
- 实验中使用有关人的Wikipedia文章
- 评估:
- 仅当r/e1/e2均正确,此事实才为真
- 两个评估者
J-REED适用于以实体为中心的文档的任何语料库,例如人员,公司的主页等。在我们的实验中,我们重点关注有关人的Wikipedia文章。我们指出,这并不将J-REED限于PERSON实体。J-REED提取各种类型的实体(例如,PERSON,MOVIE,AWARD等)以及各种类型的关系(例如,“接收奖励”:PERSON x AWARD)。
发展和培训语料库。对于训练,调整和收集统计数据的各个阶段,我们考虑了来自01/2015英语Wikipedia转储的有关PERSON实体的1,215,956篇Wikipedia文章(基于Yago [14]中的类型)。这些文章中有80%包含来自8,312,439个句子的19,287,432个三元组,称为“ Wikipedia-develop”,用于开发J-REED(即,计算名词,动词,介词和实体的各种(共)同时出现统计信息)。此外,我们从这些Wikipedia文章中的5篇(称为“ J-REEDtrain”)中手动注释了162个句子,这些句子涉及杰出人物实体,包括Andrew Ng,Angela Merkel,David Beckham,Larry Page和Paris Hilton(涵盖科学家,政治家) ,体育明星,商人和演员/歌手/名人)。这些注释包括203个三元组,每个三元组由两个DBpedia实体以及沿着连接这两个实体的依赖路径的N,V,P,O标签序列组成。J-REED训练集合用于训练CRF模型(第4节)和联合模型(第5节)。
评估:评定。我们有两名评委独立评估我们的实验结果。从不同方法的输出中向他们显示了采样的事实(即两个实体和一个关系),以及从中提取事实的源语句。仅当所有三个成分均正确时,才要求法官将事实标记为真,否则将事实标记为假。我们观察到强烈的法官间协议。科恩的卡帕[6]为0.7。
6.2 Systems under Comparison
-
实验
-
比较对象
- 最新的Open IE方法(即OLLIE [17])和命名实体消歧(NED)工具(即Babelfy [19]和Spotlight [ 9])。
- Babelfy [19]和Spotlight [ 9]专注于DBpedia实体以及它们处理Open IE系统输出的能力,而其他只能在纯文本下使用
- OLLIE-Spotlight
- OLLIE-Babelfy
- 几种J-REED变体进行了实验,
- J-REED:(第五节
- J-REED-pipeline(仅用4中CRF考虑的最可能的关系标签),关系在实体消歧前固定
- 最新的Open IE方法(即OLLIE [17])和命名实体消歧(NED)工具(即Babelfy [19]和Spotlight [ 9])。
J-REED是第5节中描述的联合模型。我们通过假设代词(即“他”和“她”)始终指代文章的主要实体,来启发式地解决代词。此假设基于常见的Wikipedia写作风格(并延续到其他种类的以实体为中心的文档,例如人们的主页)。
•J-REED管道仅根据第4节中所述的CRF模型考虑最可能的关系标签。换句话说,关系在实体消除歧义之前是固定的。代名词的解析如上所述。
•OLLIE-Spotlight是结合OLLIE和Spotlight的流水线方法。
•OLLIE-Babelfy是将OLLIE和Babelfy结合在一起的流水线方法。
- ablation
- -REED-nopronoun:葫芦代词解析
- J-REED-notype:忽略类型签名
- J-REED-noprior:忽略关系先验特征
我们还使用三种设置执行消融测试:
• J-REED-nopronoun performs joint entity-relation disambiguation but omits pronoun resolution.
•J-REED-代词执行联合实体关系歧义消除,但省略代词解析。
• J-REED-notype omits the type signature feature. • J-REED-noprior omits the relation prior feature.
•J-REED-notype忽略类型签名功能。 •J-REED-noprior省略了关系先验特征。
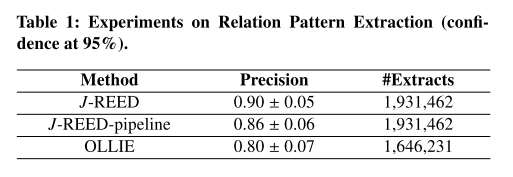
6.3 Experiments on Relation Pattern Extraction
精确度报告为95%置信水平下Wald间隔的平均值。
召回率测量为提取的关系三元组的绝对数量。
只考虑了最多由6个标记组成的提取。其他提取通常是噪音。
- OLLIE:错误源于忽略关系的类型约束;原文中解决了但没用,为了增加召回率
- J-REED最好

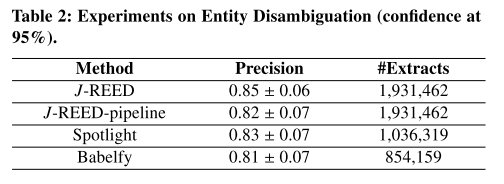
6.4 Experiments on Entity Disambiguation
- 由于其他NED系统(Spotlight和Babelfy)未将代词映射到实体,因此我们忽略了包含代词的提取。
- 仅当两个实体正确消除歧义时,提取才被认为是正确的。
- 对于系统而言,消除歧义的实体对的数量是不同的,因为在最终结果中我们不考虑空实体。
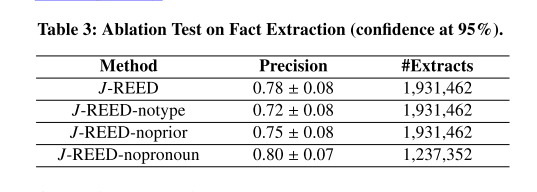
6.5 End-to-End Experiments
- 判定:只有事实提取的所有三个组成部分(即关系和两个实体)均已正确消除歧义时,事实提取才被认为是正确的。
- 对于正确的结果为True,
- 对于错误的结果为False(实体或关系错误)
- 当OLLIE返回的关系由6个以上的标记组成时(例如,通常是OLLIE-Spotlight和OLLIE-Babelfy被忽略)噪声)
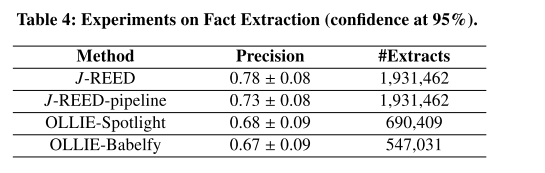
- ablation
- 如表3所示,类型签名和先验特征对于J-REED的精度至关重要。
- 如表3所示,类型签名和先验特征对于J-REED的精度至关重要。
来源:CSDN
作者:叶落叶子
链接:https://blog.csdn.net/weixin_40485502/article/details/104771746