前言
由于logstash内存占用较大,灵活性相对没那么好,ELK正在被EFK逐步替代.其中本文所讲的EFK是Elasticsearch+Fluentd+Kfka,实际上K应该是Kibana用于日志的展示,这一块不做演示,本文只讲述数据的采集流程.
前提
架构
数据采集流程
数据的产生使用cadvisor采集容器的监控数据并将数据传输到Kafka.
数据的传输链路是这样: Cadvisor->Kafka->Fluentd->elasticsearch
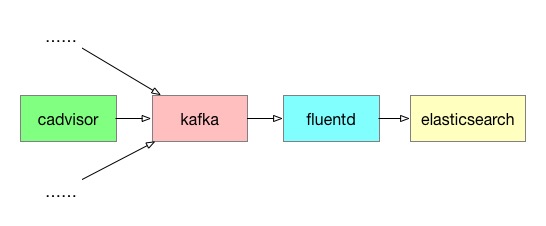
每一个服务都可以横向扩展,添加服务到日志系统中.
配置文件
docker-compose.yml
version: "3.7"
services:
elasticsearch:
image: elasticsearch:7.5.1
environment:
- discovery.type=single-node #使用单机模式启动
ports:
- 9200:9200
cadvisor:
image: google/cadvisor
command: -storage_driver=kafka -storage_driver_kafka_broker_list=192.168.1.60:9092(kafka服务IP:PORT) -storage_driver_kafka_topic=kafeidou
depends_on:
- elasticsearch
fluentd:
image: lypgcs/fluentd-es-kafka:v1.3.2
volumes:
- ./:/etc/fluent
- /var/log/fluentd:/var/log/fluentd
其中:
- cadvisor产生的数据会传输到192.168.1.60这台机器的kafka服务,topic为kafeidou
- elasticsearch指定为单机模式启动(
discovery.type=single-node环境变量),单机模式启动是为了方便实验整体效果
fluent.conf
#<source>
# type http
# port 8888
#</source>
<source>
@type kafka
brokers 192.168.1.60:9092
format json
<topic>
topic kafeidou
</topic>
</source>
<match **>
@type copy
# <store>
# @type stdout
# </store>
<store>
@type elasticsearch
host 192.168.1.60
port 9200
logstash_format true
#target_index_key machine_name
logstash_prefix kafeidou
logstash_dateformat %Y.%m.%d
flush_interval 10s
</store>
</match>
其中:
-
type为copy的插件是为了能够将fluentd接收到的数据复制一份,是为了方便调试,将数据打印在控制台或者存储到文件中,这个配置文件默认关闭了,只提供必要的es输出插件.
需要时可以将@type stdout这一块打开,调试是否接收到数据. -
输入源也配置了一个http的输入配置,默认关闭,也是用于调试,往fluentd放入数据.
可以在linux上执行下面这条命令:
curl -i -X POST -d 'json={"action":"write","user":"kafeidou"}' http://localhost:8888/mytag
- target_index_key参数,这个参数是将数据中的某个字段对应的值作为es的索引,例如这个配置文件用的是machine_name这个字段内的值作为es的索引.
开始部署
在包含docker-compose.yml文件和fluent.conf文件的目录下执行:docker-compose up -d
在查看所有容器都正常工作之后可以查看一下elasticsearch是否生成了预期中的数据作为验证,这里使用查看es的索引是否有生成以及数据数量来验证:
-bash: -: 未找到命令
[root@master kafka]# curl http://192.168.1.60:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open 55a4a25feff6 Fz_5v3suRSasX_Olsp-4tA 1 1 1 0 4kb 4kb
也可以直接在浏览器输入 http://192.168.1.60:9200/_cat/indices?v查看结果,会更方便.
可以看到我这里是用了machine_name这个字段作为索引值,查询的结果是生成了一个叫55a4a25feff6的索引数据,生成了1条数据(docs.count)
到目前为止kafka->fluentd->es这样一个日志收集流程就搭建完成了.
当然了,架构不是固定的.也可以使用fluentd->kafka->es这样的方式进行收集数据.这里不做演示了,无非是修改一下fluentd.conf配置文件,将es和kafka相关的配置做一下对应的位置调换就可以了.
鼓励多看官方文档,在github或fluentd官网上都可以查找到fluentd-es插件和fluentd-kafka插件.
始发于 四颗咖啡豆 ,转载请声明出处.
关注公众号->[四颗咖啡豆] 获取最新内容

来源:oschina
链接:https://my.oschina.net/u/3022563/blog/3167635