solr8.3.1加入中文分词(solr在docker容器中运行)
创建的核心默认情况下没有中文分词,当我们输入一串中文,进行词语拆分时,solr会把每一个汉字都拆开,比如输入“我是中国人”,进行词语拆分的时候会拆成:“我”,“是”,“中”,“国”,“人”五个词。如下图。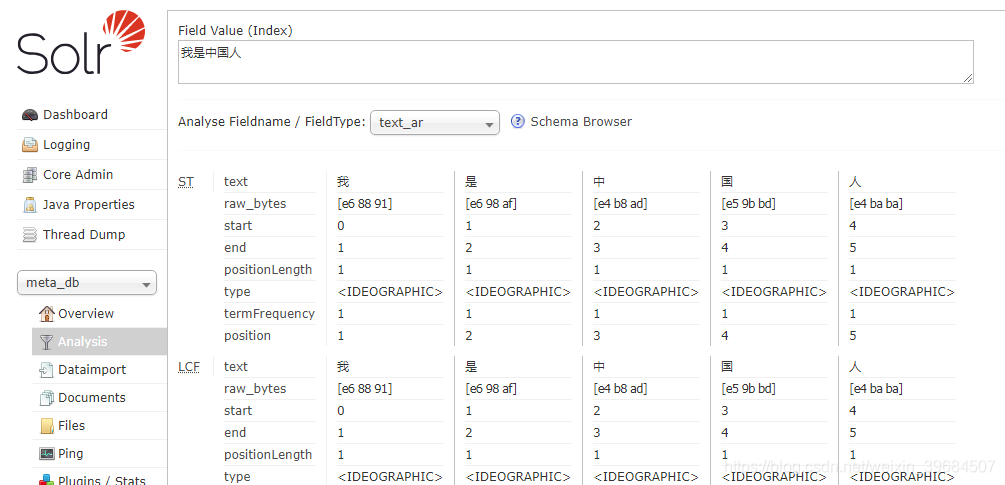
这明显不是我们想要的结果。我们需要将中文分词加入到solr中,才能得到我们想要的结果。
如何加入中文分词器?
1、下载中文分词器jar包 ik-analyer-8.3.0.jar。
百度网盘下载
2、上传jar包并拷贝到 /usr/local/solr/solr/server/solr-webapp/webapp/WEB-INF/lib目录下
cp /data/soft/ik-analyer-8.3.0.jar /usr/local/solr/solr/server/solr-webapp/webapp/WEB-INF/lib
chmod a+r ik-analyzer-8.3.0.jar
说明:/data/solft是docker容器中的目录,已经挂在到宿主机目录/data/coowalt/solr目录。请参考《Docker 安装solr8.3.1》一文。
3、修改/data/solr/data/meta_db/conf/目录下的managed-schema文件。加入ik-analayer配置信息
cd /data/solr/data/meta_db/conf/
vi managed-schema
<!-- ik analysis -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
说明:
fieldType 标签的name属性指定拆除器的名称,这里我们默认为text_ik,当然你也可以写别的名称。只要不和当>前已经存在的拆词器重名。
4、保存退出,重启solr服务
service solr restart
5、刷新solr页面,在进行中文拆词分析,拆词器选择刚才我们配置的text_ik(filedType的name属性值,参考第3步的说明)。拆词分析结果如下图: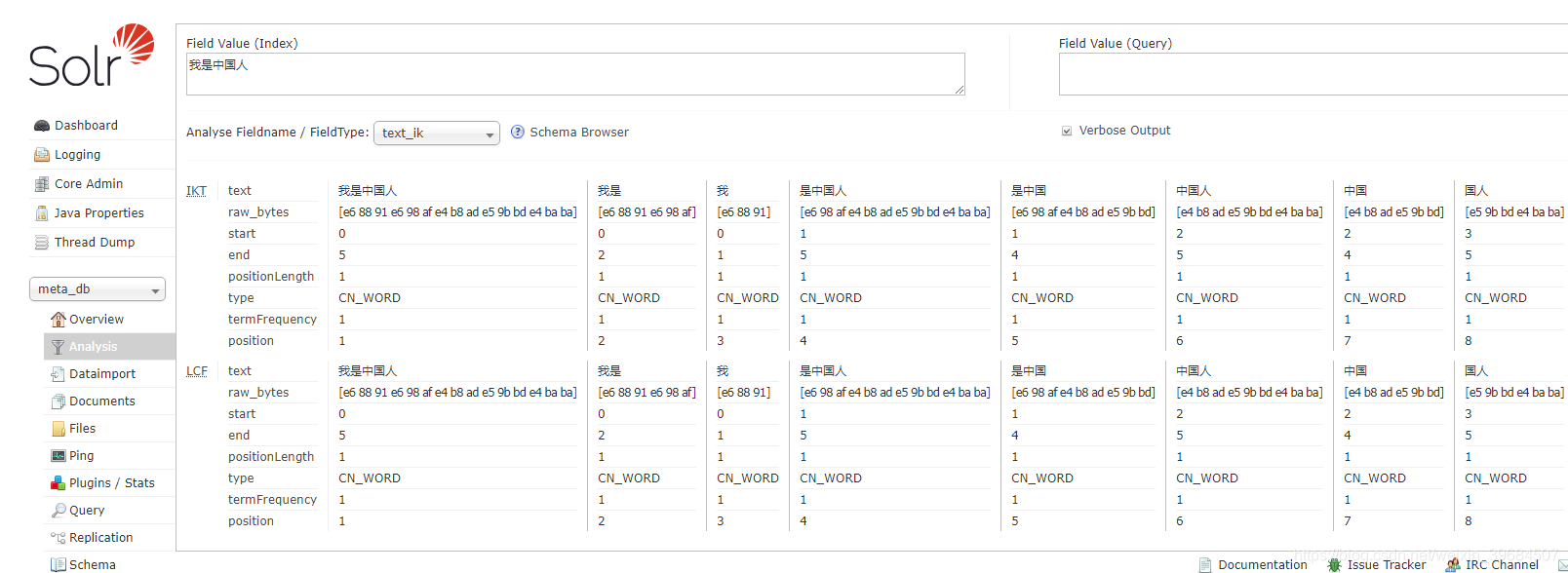
来源:CSDN
作者:coowalt
链接:https://blog.csdn.net/weixin_39684507/article/details/103613996