一、参考资料
1.《Python网络数据采集》图灵工业出版社
2.《精通Python爬虫框架Scrapy》人民邮电出版社
3.[Scrapy官方教程](http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html)
4.[Python3网络爬虫](http://blog.csdn.net/c406495762/article/details/72858983
二、前提知识
url、http协议、web前端:html\CSS\JS、ajax、re、Xpath、xml
三、基础知识
1.爬虫简介
爬虫定义:网络爬虫(又被称为网页蜘蛛、网络机器人、在FOAF社区中,更经常的称为网页追逐者)是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。两外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者如蠕虫。
2.两大特征
(1)能按作者要求下载数据或者内容
(2)能自动在网络上流窜
3.三大步骤
(1)下载网页;
(2)提取正确的信息
(3)根据一定规则自动跳到另外的网页上执行上两步内容
4.爬虫分类
(1)通用爬虫
(2)专用爬虫
5.Python网络包简介
Python2:urllib\urllib2\urllib3\httplib\httplib2\requests
Python3.x:urllib\urllib3\httplib2\requests
其中python2中urllib和urllib2配合使用,或者requests
Python3就是使用urllib.requests
6.urllib
包含模块
urllib.requests:打开和读取urls
urllib.error:包含urllib.requests产生的常见的错误,使用try捕捉
urllib.parse:包含即时url的方法
urllib.robotparse:解析roobs.txt文件
from urllib import request
"""
使用urllib,request请求一个网页内容,并把内容打印出来
"""
if __name__ == "__main__":
url = "https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=984602018"
#打开相应的url并把相应页面作为返回
rsp = request.urlopen(url)
#返回结果读取出来
html = rsp.read()
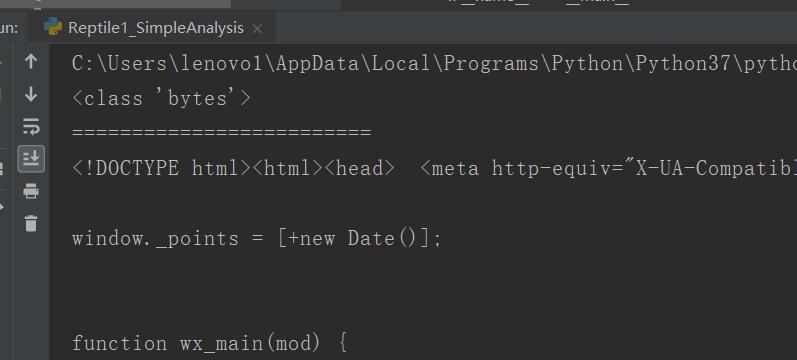
print(type(html))##bytes类型
html = html.decode()
print(html)
7.网页编码解析方式chardet包的使用
from urllib import request
import chardet
"""
使用urllib,request请求一个网页内容,并把内容打印出来
"""
if __name__ == "__main__":
url = "https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN&token=984602018"
#打开相应的url并把相应页面作为返回
rsp = request.urlopen(url)
#返回结果读取出来
html = rsp.read()
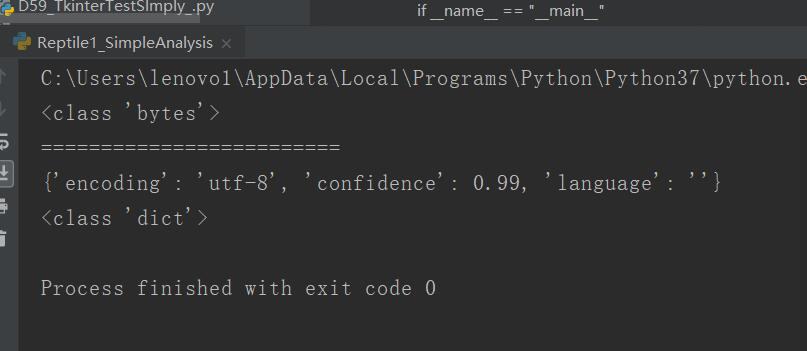
print(type(html))##bytes类型
print("=========================")
cs = chardet.detect(html)#利用chardet来检测这个网页使用的是什么编码方式
print(cs)
print(type(cs))
#使用get方法是为了避免如果取不到值报错,程序就崩溃了
html = html.decode(cs.get("encoding","utf-8"))#取cs字典中encoding属性,如果取不到,那么就使用utf-8
四、源码
Reptile1_SimpleAnalysis.py
https://github.com/ruigege66/PythonReptile/blob/master/Reptile1_SimpleAnalysis.py
2.CSDN:https://blog.csdn.net/weixin_44630050(心悦君兮君不知-睿)
3.博客园:https://www.cnblogs.com/ruigege0000/
4.欢迎关注微信公众号:傅里叶变换,个人公众号,仅用于学习交流,后台回复”礼包“,获取大数据学习资料

来源:https://www.cnblogs.com/ruigege0000/p/12169312.html