基础数据分析
以下图表均取自互联网,本文是在“已经获取所需数据”的前提下,讲解性能测试的一些设计思路。至于如何才能取得这些数据,将在后续的文章中说明。
系统访问量分布
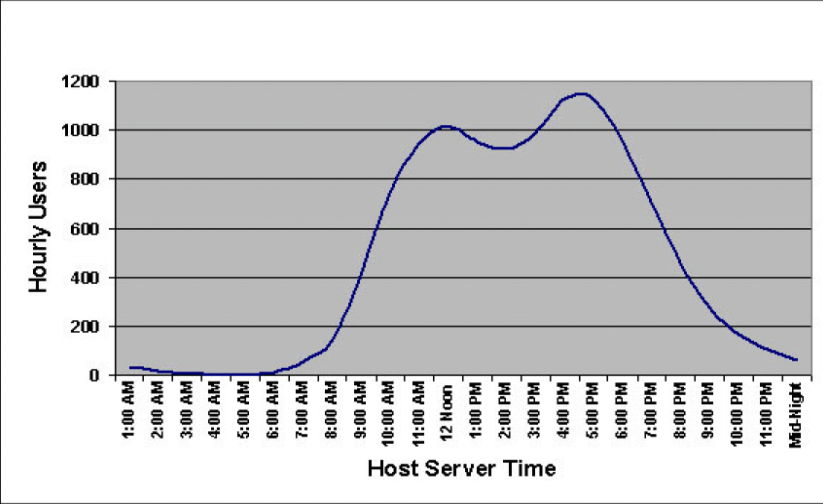
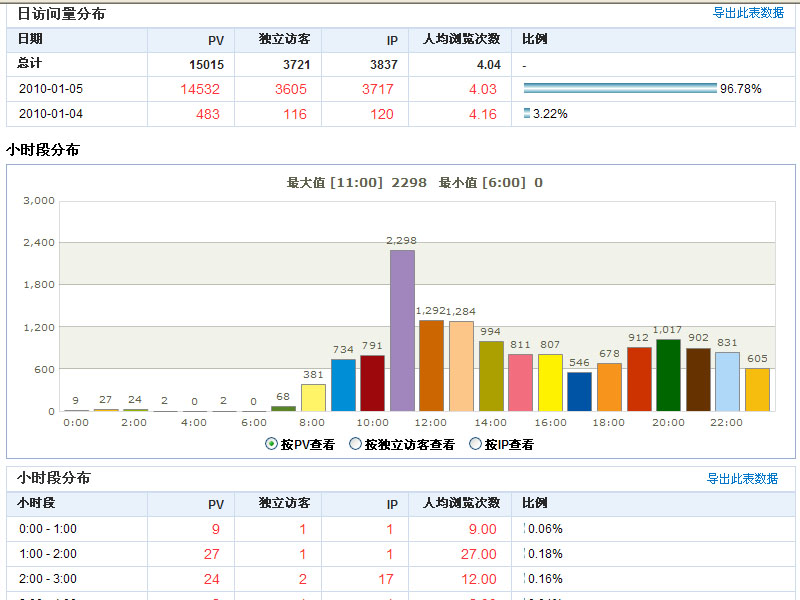
由系统的日访问量分布图,可知系统的访问压力集中在哪个时间段内。系统的压力是在一天中平均分布的,还是集中在某几个更小的时间段内。根据此信息,我们对测试场景的时间进行设计,如从分布图中明显看出每天的大部分访问量集中在9:00~11:00和14:00~16:00两个时段,那么就可以设计2小时内完成一半访问量的测试场景。
用户的平均活跃时间
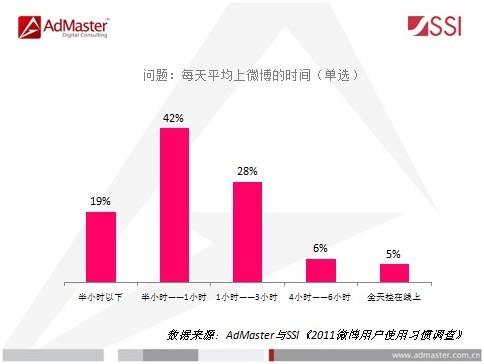
用户活跃时间,是指用户一次使用系统的时长,可用来指导测试脚本的设计,即每个虚拟用户脚本应该在多长时间内执行完。
由系统访问量分布和用户活跃时间两个数据,可以对系统使用的并发度进行估算。比如已知系统在2个小时内有200访问量,且分布接近于平均,用户的平均活跃时间为30分钟,那么此时间段的并发度应为:200*30/120=50。这里并发度50传递的信息是,在一个用户活跃周期内,总共会有50个用户与服务端进行交互(即相对并发)。也就是说任意时间点,最大的绝对并发可能性是50,当然实际可能远低于此,可以根据业务特点再乘以相应比例进行估算。
在性能测试时,可以依据此数据设计系统高峰期压力的测试场景。比如我们已知,系统压力最大时,单位时间段内活跃用户有100人(并发度100),那么这种压力场景,就可以以用户平均活跃时间为测试时间段,启动100个虚拟用户并在该时间段内完成各自的工作量。
页面停留时间
即请求之间的间隔(思考)时间,如在编辑页面上停留多久才会点提交按钮。如果无此数据,性能测试脚本只有运行时长是有数据(活跃时间)支撑的,脚本中的各请求之间的思考时间,只能通过常规判断和猜测,由性能测试人员自己掌控。收集到此数据后,性能测试脚本会更加符合真实用户的操作习惯,更加接近真实用户。
热点模块(页面)
分析系统各模块或页面的访问频率,可以用来检查性能测试是否设计了足够的覆盖、是否遗漏的用户频繁使用的功能,并据此对用户模型进行完善。
此外,此数据可用来分析各模块或功能所涉及到的工作量,如每天平均完成多少次提交操作、多少次统计操作。这对于确定系统的使用压力有很大的作用。
场景数据
最后,综合所有数据,为特定测试场景制订出成如下表格:
|
总体 |
||
|
|
场景名称 |
100用户负载场景 |
|
|
场景描述 |
模拟系统使用高峰期时,在2小时左右有100用户的访问 |
|
|
场景时长 |
2h |
|
|
场景加载策略 |
每4.5分钟加载5个虚拟用户。因为要在2小时内完成100用户的访问,而每个用户的运行时间在30分钟左右,那么在1小时30分钟时就最后一批用户就要开始访问系统,即90分钟内加载100个用户。 |
|
|
虚拟用户数 |
100 |
|
|
用户模型 |
见XX用户模型 |
|
|
虚拟用户运行时间 |
30min |
|
|
平均思考时间 |
30~60s |
|
|
场景并发度 |
25。 虚拟用户数*(虚拟用户运行时间/场景时长) |
|
操作说明 |
||
|
登录 |
Think Time |
平均8s,最小5s,最大20s |
|
Pass/Fail 条件 |
如果失败,重试一次,依然失败就中止。 |
|
|
数据 |
每虚拟用户使用不同的账号 |
|
|
... |
|
|
可以说,用户模型表达的是,系统运行中的压力是如何分布的。
而场景数据表达的是,要给系统施加多大的压力。
只有结合用户模型和场景数据两部分,才能构造出一个确定的负载场景。
如果到这里都已经做好,并且经过了技术负责人和业务负责人的确认,那么接下来要做的就是按照设计来实现测试脚本了。
来源:https://www.cnblogs.com/twocats/archive/2013/02/19/2916416.html