目录
- Learning from class-imbalanced data: Review of methods and applications
- 摘要
- Introdution 介绍
- Research methodology and initial statistics 调研方法和初始统计
- Imbalanced data classification approaches 不平衡数据分类方法
- Basic strategies for dealing with imbalanced learning 处理不平衡学习的基本方法
- Classification algorithms for imbalanced learning 针对不平衡学习的分类算法
- Ensemble methods 集成方法
- Iterative based ensemble 基于迭代的集成
- Parallel based ensembles 基于并行的集成
- Base classifier choice in ensemble models 集成模型的基分类器选择
- Algorithmic classifier modification 分类器算法修改
- Multi-class imbalanced learning 多类别不平衡学习
- Model evaluation in the presence of rare classes 罕见类模型评估
- Imbalanced data classification application domains 不平衡学习应用领域
- Taxonomy of application domains 应用领域的分类
- Chemical and biomedical engineering Biomedical 化学和生物医学工程生物医学
- financial management 金融管理
- Information technology 信息技术
- Energy management 能源管理
- Security management 安全管理
- Electronics and communications 电子与通信
- Infrastructure and industrial manufacturing 基建及工业制造业
- Business management 商业管理
- Emergency management 紧急情况管理
- Environmental management Environmental 环境管理
- Policy, social and education
- Agriculture and horticulture
- Other areas and non-specific applications Applications
- Future research directions of imbalanced learning
- At the technical level
- Diversity within ensembles
- Adaptive learning
- Online learning for imbalanced data stream classificatio
- Semi-supervised learning and active learning
- At a practical level
- Conclusions
Learning from class-imbalanced data: Review of methods and applications
摘要
罕见的事件(rare event),尤其是那些可能对社会产生负面影响的事件,往往需要人类做出决策。在数据挖掘和机器学习领域,罕见事件的检测可以看作是一项预测任务。由于这些事件在日常生活中很少被观察到,预测任务缺乏平衡的数据。本文从不平衡学习的角度,对罕见事件预防进行了深入的研究。在过去的十年中,共收集了517篇相关论文。最初的统计数据表明,从管理科学到工程学的广泛研究领域都在关注罕见事件检测和不平衡学习。我们从技术和实践的角度对所收集的论文进行了回顾。讨论的建模方法包括数据预处理、分类算法和模型评估等技术。对于应用程序,我们首先提供了不平衡学习的现有应用程序领域的一个全面分类,然后详细介绍了每个类别的应用程序。最后,结合本文的研究经验和判断,提出一些建议,为不平衡学习和罕见事件检测领域提供进一步的研究方向.
Introdution 介绍
罕见的事件、异常的模式和异常的行为是很难检测到的,但往往需要各种管理功能的及时响应。根据定义,罕见事件是指发生频率远远低于通常发生事件的事件(Maalouf和Trafalis, 2011)。罕见事件的例子包括软件漏洞(Rodriguez等,2014)、自然灾害(Maalouf和Trafalis, 2011)、癌症基因表达(Yu等,2012)、信用卡欺诈交易(Panigrahi等,2009)和电信欺诈(Olszewski, 2012)。
在数据挖掘领域,事件检测是一种预测问题,或者通常是数据分类问题。由于罕见事件发生的频率低、偶然性强,很难发现;然而,对罕见事件的错误分类可能会导致沉重的代价。对于金融欺诈的检测来说,无效的交易可能只会出现在成千上万的交易记录中,但如果不能识别出严重的欺诈交易,将会造成巨大的损失。罕见事件的罕见发生削弱了数据分类问题的检测任务的不平衡性。不平衡数据指的是一个数据集,其中一个或一些类比其他类有更多的例子。最普遍的类别被称为多数类别,而最罕见的类别被称为少数类别(Li et al., 2016c)。虽然数据挖掘方法已被广泛应用于建立分类模型来指导商业和管理决策,但对这些传统的分类模型解决不平衡数据的分类问题提出了很大的挑战。正如我们在现有调查中所讨论的,原因有五方面:
- 标准分类器如logistic回归、支持向量机(SVM)和决策树等都适用于平衡训练集。当面临不平衡的场景时,这些模型往往会提供次优分类结果,即对大多数例子有很好的覆盖,而少数例子是扭曲的(Lopez et al., 2013)。
- 由预测精度等全局性能指标引导的学习过程导致了对多数类的偏倚,而即使预测模型总体精度较高,罕见的类别仍然未知(Loyola-Gonzalez et al., 2016)。在Weiss and Hirsh(200 0)和Weiss(2004)中可以找到一些原始的讨论。
- 学习模型可能将少数类别中的例子视为噪声。相反,噪声可能被错误地定义为少数例子,因为它们都是数据空间中罕见的模式 (Beyan和Fisher, 2015)。
- 虽然不平衡的样本分布并不总是很难学习(例如当类是分离的),但少数类别通常与和其有相同先验概率分布的其他区域重叠。Denil和Trappenberg(2010)讨论了不平衡情况下的重叠问题。
- 此外,小析取量、缺乏密度、样本容量小、特征维数高是对学习不平衡的挑战,往往导致学习模型无法检测到罕见模式。
过去十年来许多机器学习方法已经开发出来,为了应对数据分类的不平衡,大多数数据分类都是基于样本技术、对代价敏感的学习和集成方法(Galar et al., 2012;Krawczyk等,2014;Loyola-Gonzalez等人,2016)。在这个领域还有一本书,见He and Ma(2013)。虽然已经发表了一些与不平衡学习相关的调查(Branco et al., 2016;Fer- nandez等,2013;Galar等,2012;他和加西亚,2009;洛佩兹等人,2012;Sun et al., 2009),他们都专注于详细的技术而忽略了应用文献。对于来自管理、生物学或其他领域的研究人员来说,利用国际先进的学习技术和用成熟而有效的方法建立不平衡的学习系统来解决问题,而不是单纯的算法,可能更值得关注。
在本文中,我们的目标是提供一个全面的分类不平衡的总结,包括技术和应用。在技术层面,我们介绍了处理不平衡学习的常用方法,并提出了一个通用的框架,在其中可以放置每个算法。该框架是一个统一的数据挖掘模型,包括预处理、分类和评价。在实践层面,我们回顾了162篇试图构建特定系统来解决罕见模式检测问题的论文,并对现有的不平衡学习应用领域进行了分类。现有的应用文献涵盖了从医学到工业到管理的大部分研究领域。
本文的其余部分组织如下。第2节描述了本研究的研究方法,以及关于最近不平衡学习趋势的初步统计数据。第3节介绍了处理二进制和多个类不平衡数据的方法。在第4节中,我们首先将现有的不平衡学习应用文献分为13个领域,然后介绍了各自的研究框架。第五部分从技术和实践两方面论述了我们对未来不平衡学习研究方向的思考。最后,第六部分给出了本文的结论。
Research methodology and initial statistics 调研方法和初始统计
Research methodology 调研方法
本研究基于Govindan和Jepsen(2016)的研究方法,采用两阶段检索的方法,对2006 - 2016年10月发表的相关论文进行整理。在初始阶段,我们使用了7个涵盖自然科学和社会科学研究领域的图书馆数据库来搜索和收集文献:Elsevier、IEEExplore、施普林格、ACM、Cambridge、Wiley和Sage。使用全文搜索,搜索词按照Fahimnia等人(2015)概述的搜索过程设计。构建了一个两级关键字树,提供了一套完整的搜索词集,用于捕获关于罕见事件和非国际性学习的技术和应用文章。图1为本研究的搜索词。第一层的搜索阶段仅限于不平衡/不平衡/倾斜数据,重点是不平衡数据的分类。第二级搜索词分为两部分,包括技术和实用文章。在技术方面,使用了涉及数据挖掘方法的关键字,在实际应用方面,使用了关注事件检测和预测的关键字,包括罕见事件、常见事件、异常事件、缺陷程序、欺诈、疾病和入侵。请注意,单词的对应屈折形式和同义词(如“unusual”对应“abnormal”,“fraudulence”对应“fraud”)也被考虑在内。最初的搜索结果是657篇论文,这些论文被下载到下一个过滤过程中。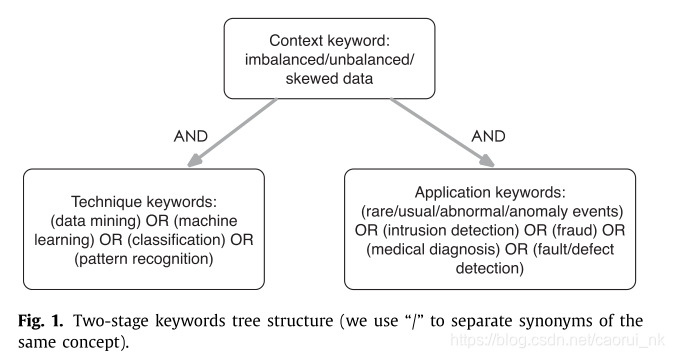
在手工审阅每篇论文后,发现与本研究相关的论文有464篇。在评审过程中进行第二阶段搜索,使用谷歌Scholar搜索相关交叉参考文献。在这个阶段,尝试访问谷歌Scholar中的所有交叉引用,或者包含在可访问的图书馆数据库中。第二阶段后,我们的review中增加了63篇论文。因此,本研究共纳入527篇论文。
Initial statistics 初步统计
在这一节中,我们将介绍不平衡学习趋势的初步统计数据。图2为2006年至2016年的出版趋势。2006年以后,刊物数目有相对稳定的增长。2011 - 2013年期间唯一的下降趋势是2013-2016年出版物数量的急剧上升。这一趋势表明,迄今为止,学习不平衡仍然是一个有价值的研究课题。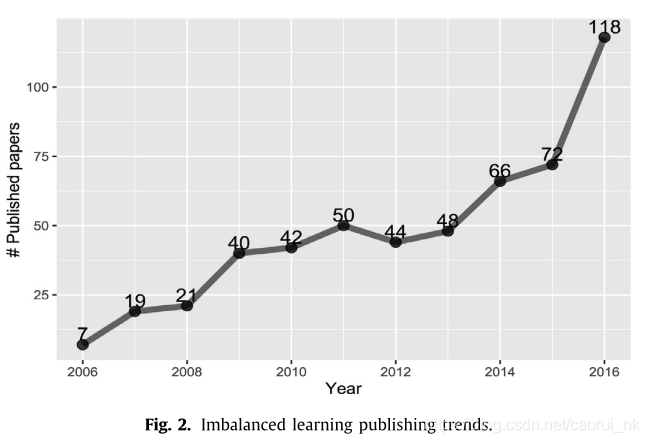
初步统计还显示,192种期刊和会议论文集共发表论文527篇。统计各期刊的贡献,前20名的期刊/会议如图3所示。在过去的十年中,这些期刊的发表论文占全部发表论文的43.5%,其中大多数是在计算机科学、运筹学、管理学、工程学和生物技术领域具有影响力的期刊。这也说明,不平衡学习研究既包括计算机科学领域的学习技术,也包括从自然科学到管理科学等广泛领域的实际应用。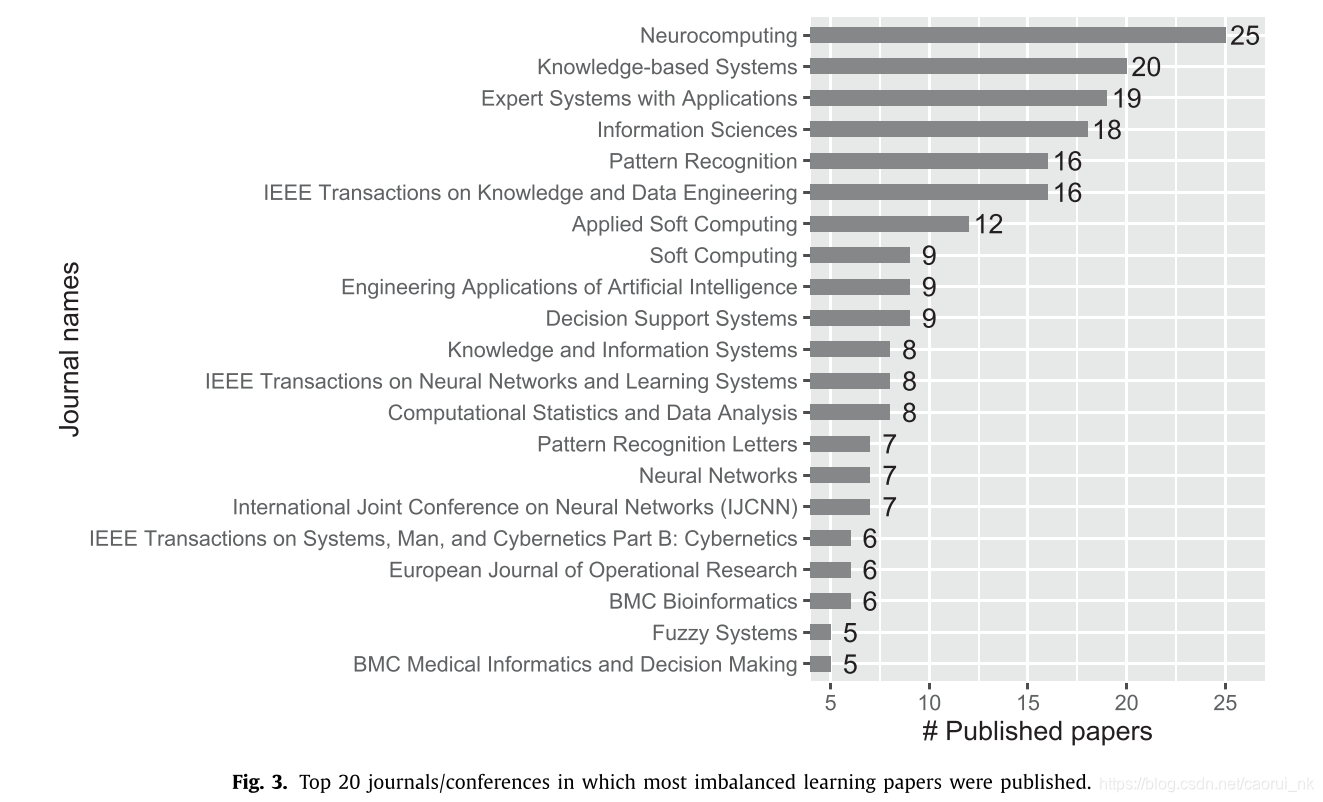
我们还收集了本研究涉及的所有论文的标题,并生成一个词云来捕捉研究最多的不平衡学习主题。为了构建图4所示的单词云,我们首先去掉了英语中最常用的停止词,如“the”和“and”,然后使用NLTK工具对每个单词进行lemmatize。由于我们的目标是在这些不平衡的学习论文中发现详细的主题,一些一般性的和经常出现的单词也被删除了。图4显示了一些用于不平衡数据分类的具体技术:重新采样方法(“过采样”、“采样”、“欠采样”等)、机器学习方法(“成本感知”、“支持向量机”、“神经网络”、“集成”等)和专家系统(“规则”、“系统”、“模糊”等)。然而,一些具体的应用领域也显示在word cloud中。典型的聚类词涵盖了“patient”、“fraud detection”、“telecommunications”、“credit card”等多个领域,这意味着申请论文的主要类别可能在财务管理、医学诊断、电信等领域。
Imbalanced data classification approaches 不平衡数据分类方法
在过去的十年中,人们提出了数百种算法来解决不平衡的数据分类问题。在本节中,我们将概述最先进的不平衡学习技术。这些技术将在基本的机器学习模型框架下进行讨论。在3.1节中,介绍了两种解决不平衡学习的基本策略,即预处理和代价敏感学习。预处理方法包括在样本空间中进行重采样的方法和优化特征空间的特征选择方法。然后将3.1节中介绍的策略集成到3.2节中描述的分类模型中。分类器又分为集成分类器和算法改进分类器。3.3节将多类分类作为一种特殊的不平衡学习问题进行讨论,阐明了将这些二元分类算法扩展到多类情况。在第3.4节中,介绍了评估和选择模型的度量标准。
Basic strategies for dealing with imbalanced learning 处理不平衡学习的基本方法
Preprocessing techniques 预处理技术
为了获得更好的输入数据,通常在建立学习模型之前进行预处理。考虑到数据的表示空间,通常采用两种经典的预处理技术:
resampling 重采样
采用重采样技术对不平衡数据集的样本空间进行重新平衡,以减轻学习过程中类分布的不均匀性。重采样方法更加通用,因为它们独立于所选分类器(Lopez et al., 2013)。根据平衡类分布的方法,重采样技术可以分为三组:
- 过采样技术:通过创建新的少数类别样本,消除了偏态分布的危害。两种广泛使用的创建合成少数样本的方法是随机复制少数样本和SMOTE (Chawla et al., 2002)。
- 欠采样技术:通过丢弃大多数类中的固有样本,消除了偏态分布的危害。最简单但最有效的方法是随机欠采样(Random Under- Sampling, RUS),它涉及随机消除大多数类的例子(Tahir et al., 2009)。
- 混合方法:这是过采样法和欠采样法的结合。
我们发现156篇被评审的论文采用了重采样技术,占所有被评审论文的29.6%。这表明重采样是处理不平衡数据的一种流行策略。欠采样法39次,过采样法84次;采用混合抽样的方法进行了33次。52篇论文采用现有的重采样方法,开发了新的重采样方法。基于聚类的方法(如k-means)、基于距离的方法(如nearest neighbour)和进化的方法(如generic algorithm)是最常用的生成或消除例子的策略,如表1所示。对于没有采用上述策略的方法,我们在最后一篇专栏文章中做了简要的介绍。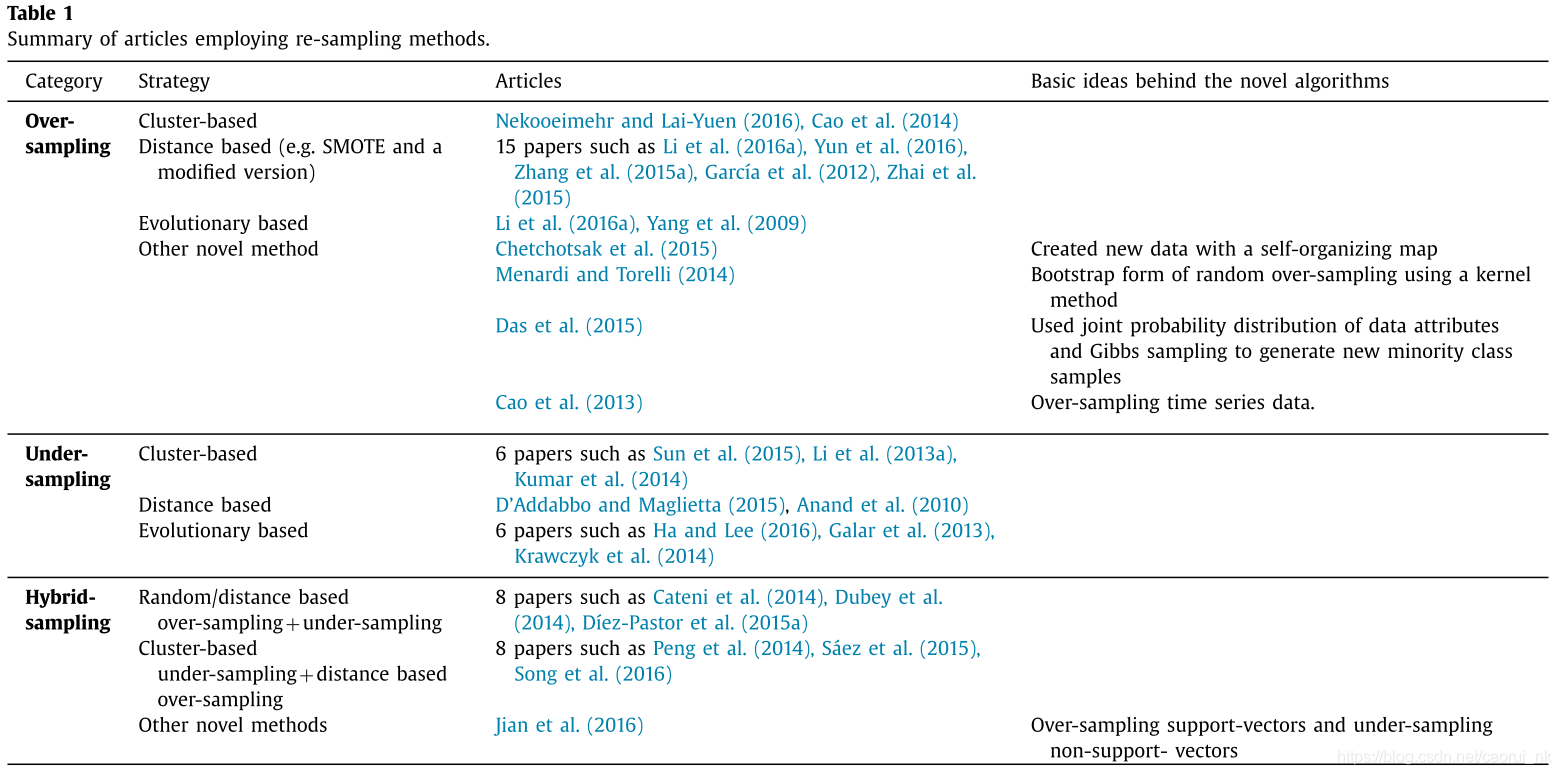
应该注意的是,所有的重新抽样方法都允许重新抽样到任何期望的比例,而准确地平衡多数类和少数类的数量是没有必要的。Zhou(2013)针对不同的数据大小推荐了不同的样本比例,Napierala和Stefanowski(2015)研究了少数类别例子的类型及其对从不平衡数据中学习的分类器的影响。一些论文试图针对不同的不平衡比(IR)和问题设置自动确定最佳采样率(Lu et al., 2016;Moreo等,2016;任等,2016a;Tomek, 1976;Yun等,2016;叶等,2016;张等,2016a)。
三篇论文研究了不同再采样方法的性能(Loyola-Gonzalez et al., 2016;Napierala和Stefanowski, 2015;周2013)。研究结果表明:
- 当数据集中有数百个少数观测值时,欠采样方法在计算时间上优于过采样方法。
- 当少数情况只有几十个时,我们发现SMOTE是更好的选择。
- 如果训练样本量过大,建议采用SMOTE和欠采样相结合的方法。
- SMOTE在识别异常值方面稍微更有效一些。
Feature selection and extraction 特征选择和抽取
与重采样方法的研究进展相比,考虑特征选择的论文明显减少。在不平衡的情况下,少数类样本容易作为噪声丢弃;但是,如果去除特征空间中不相关的特征,则可以降低这种风险(Li et al., 2016c)。
通常,特征选择的目标是从整个特征空间中选择k个特征的子集,这样分类器就可以获得最佳性能,其中k是用户指定的或自适应选择的参数。特征选择可以分为过滤器、包装器和嵌入方法(Guyon和Elisseeff, 2003)。这些方法的优点和缺点可以在Saeys等人(2007)中找到。
另一种处理维数的方法是特征提取。特征提取与降维有关,降维是将数据转化为低维空间。但是,应该注意的是,特征选择技术与特征提取不同。特征提取使用功能映射从原始特征创建新特征,而特征选择返回原始特征的子集(Motoda和Liu, 2002)。特征提取的技术多种多样,如主成分分析(PCA)、奇异值分解(SVD)和f非负矩阵分解(NMF)(见Hartmann, 2004)。对于图像、文本和语音等非结构化数据,特征提取方法的使用往往更为频繁。
表2显示了31篇使用特征选择或特征提取的综述文章。研究发现,过滤和包装器的特征选择方法是最常用的。对于过滤器方法,使用各种指标对特征进行排序,对于包装器方法,启发式搜索是常见的选择。另一个有趣的发现是,特征选择和提取经常用于解决现实世界的问题,如疾病诊断(Casanola-Martin et al., 2016;Dubey等,2014;社,2010;杨等,2016a;张,2016),文本情感分析(Lane et al., 2012;(Zhang et al., 2015a),欺诈检测(Li et al., 2013a;Lima and Pereira, 2015 Moepya et al., 2014;Wei等,2013b)等罕见事件检测问题(al - ghraibah等,2015;Bae和Yoon, 2015;龚和黄,2012;郭等,2016;Vong et al., 2015)等。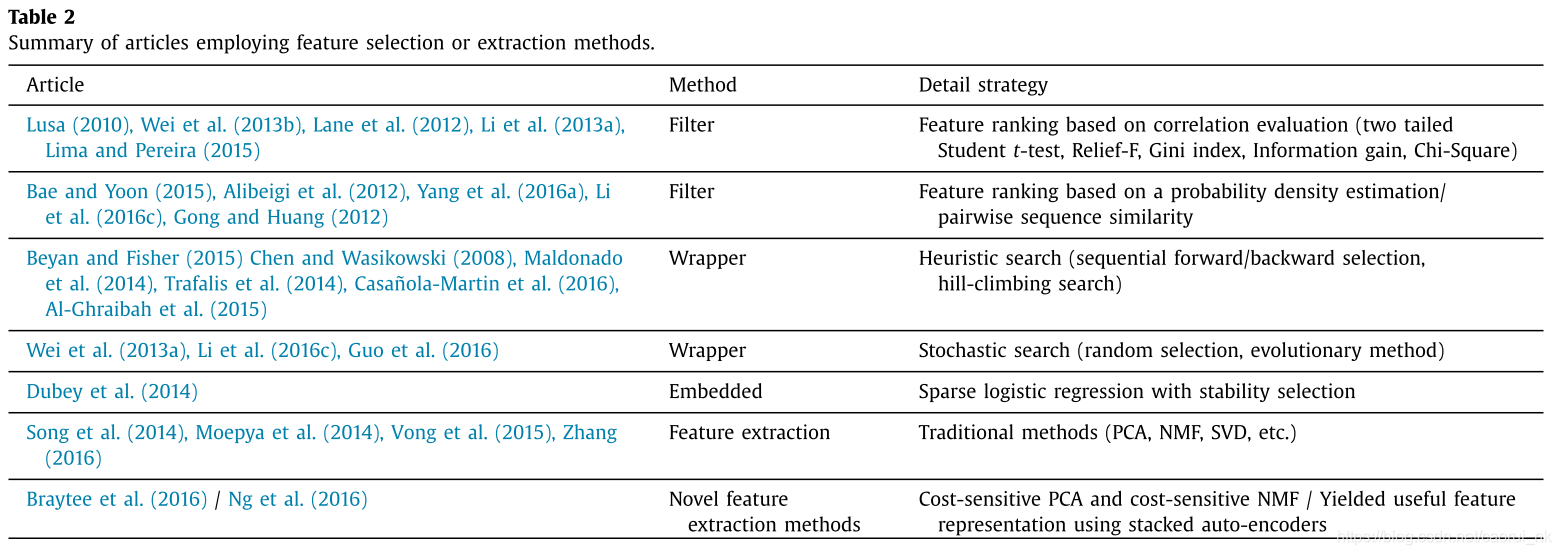
Cost-sensitive learning 代价敏感学习
通过假设少数类样本相对于多数类样本的误分类代价更高,可以在数据级(例如重新采样和特征选择)和算法级(参见3.2节,Lopez et al., 2012, 2013)纳入代价敏感学习。成本通常指定为成本矩阵,其中C ij表示将属于类i的示例分配给类j的错误分类成本。给定一个特定的领域,成本矩阵可以使用专家意见来确定,或者在数据流场景中,它们可以为每个记录而变化,或者在动态不平衡状态下变化(Ghazikhani et al.,2013 b)。与重采样方法相比,代价敏感学习具有更高的计算效率,因此可能更适合大数据流。然而,这一方法仅被39篇文献采用,远没有重新抽样方法受欢迎。可能有两个潜在的原因,一个是如Krawczyk等人(2014)所述,很难在设置成本矩阵值。在大多数情况下,由于错误分类的成本从数据中是未知的,不能由专家给出。然而,解决这一困难的另一种方法是,将多数阶级误分类成本设置为1,同时将惩罚少数阶级的价值设置为等于IR (Castro and Braga, 2013;洛佩兹等,2015)。另一个原因是,对于那些不擅长机器学习的研究人员来说,重新采样是一种实际中常见的选择,这可能对这个观察结果更合理。与通常需要修改学习算法的代价敏感学习不同,重采样方法更容易在单个模型和集成模型中直接实现。在我们的研究过程中,大多数的申请论文使用了重新抽样的方法,而不是成本敏感的学习。
处理费用敏感问题的三种主要方法见表3所列的39份有关文件。
Classification algorithms for imbalanced learning 针对不平衡学习的分类算法
不平衡学习试图建立一种分类算法,能够比传统的分类器如SVM、KNN、决策树和神经网络更好地解决类别不平衡问题。文献报道了两种解决学习不平衡问题的方法;集成方法和算法分类器的修改。在3.2.1节和3.2.2节中,我们回顾了过去十年提出的不平衡数据分类算法。虽然这些方法大多针对二元类问题,但多类问题在机械故障检测和疾病诊断等许多罕见的事件检测领域中较为常见。因此,第3.2.3节将多类不平衡学习作为一个特殊问题进行讨论,并简要介绍了目前的解决方案。
Ensemble methods 集成方法
基于ensemble的分类器,也被称为多分类器系统(Krawczyk和Schaefer, 2013),通过组合几个性能优于每个独立分类器的基分类器来提高单个分类器的性能(Lopez et al., 2013)。分类器集成已成为解决类不平衡问题的一种常用方法。在527篇综述论文中,218篇论文提出了新的集成模型或应用现有的ensem- ble模型来解决实际任务。Galar等(2012)采用集成方法对不平衡数据学习进行了全面的调查,其中集成方法分为成本敏感集成和数据预处理集成。然而,由于本研究只考虑了bagging、boosting和混合系统,因此该领域还没有完全覆盖。例如,Sun et al.(2015)和Tian et al.(2011)提出了两种集成模型,通过平衡使用重新采样方法创建的不同数据集来训练多个基本分类器,而不需要打包或增强算法。
注意,基于重采样的集成和装袋的训练过程可以并行进行,而boost和一些基于进化的集成方法只能使用迭代过程进行训练。因此,在本研究中,我们将集成模型分为两类,即基于迭代的集成和基于并行的集成。
Iterative based ensemble 基于迭代的集成
boosting是集成学习中最常见、最有效的方法。我们发现63篇重新浏览的论文在其集成框架中使用了增强,其中大多数是基于Freund和Schapire(1996)提出的第一个适用的增强算法Adaboost。Adaboost的优点是,没有被分配到正确类别的样本被赋予了更高的权重,这迫使未来的分类器更多地关注于学习这些失败的分类样本。Adaboost有几个扩展:Adaboost.M1,Ad- aBoost.M2, AdaBoost.MR and AdaBoost.MH (Freund and Schapire, 1997;Schapire and Singer, 1999);它是为解决多类多标签问题而设计的。其他典型的迭代集成方法包括梯度增强决策树(GBDT) (Friedman, 2001)和一些基于en-semble算法的进化算法(EA)。
如Galar等人(2012)所述,增强算法通常与代价敏感的学习和重新采样技术相结合。表4列出了一些提出了新的基于迭代的集成算法的技术文章。可以看出,Adaboost和Adaboost.M2是最流行的基于迭代的集成方案。大多数集成模型都考虑了成本敏感和重新采样策略。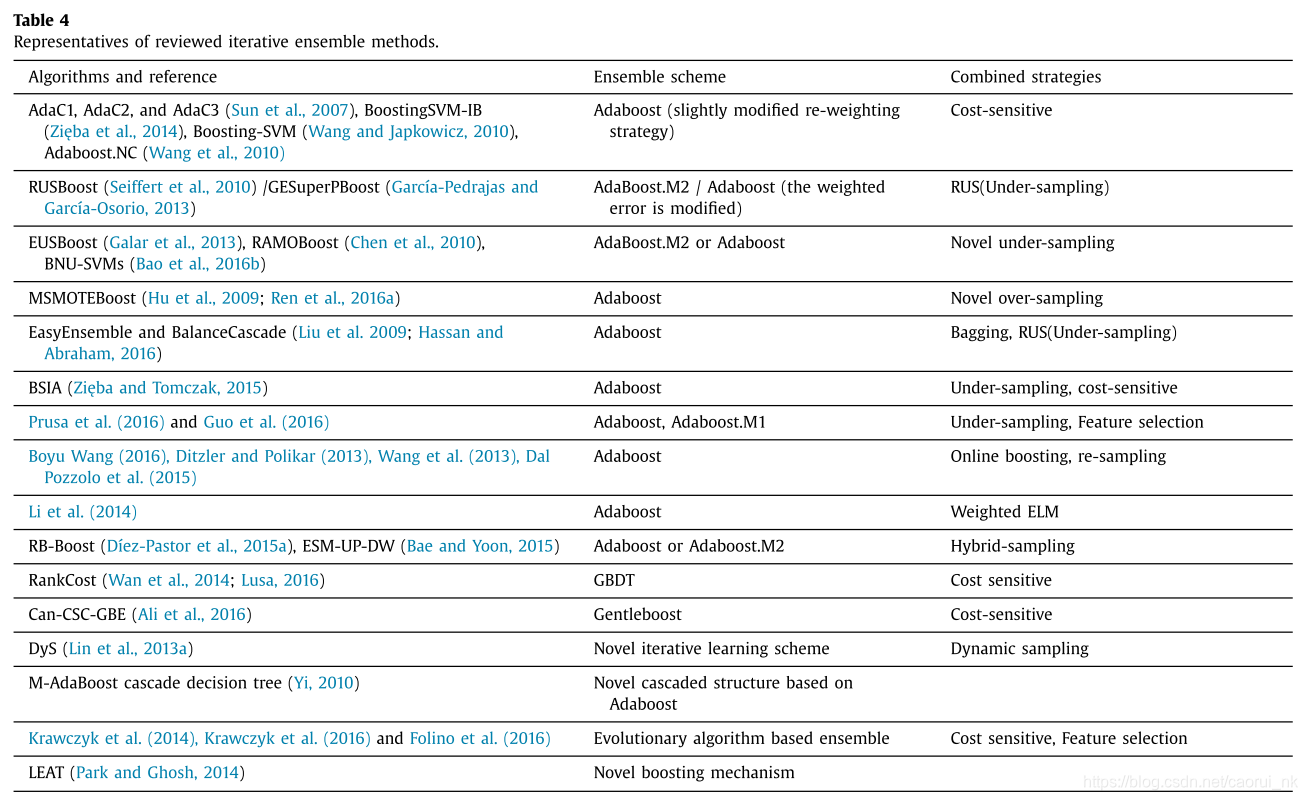
Parallel based ensembles 基于并行的集成
在本研究中,基于并行的集成是指每个基分类器都可以并行训练的集成模型。基于并行的集成方案包括基于袋装的集成、基于重采样的集成和基于特征选择的集成。并行集成方法的基本框架如图5所示,其中虚线框和线表示可选流程。Galar et al.(2012)和Lopez et al.(2013)认为,与boost相比,套袋和与数据预处理技术相关的杂交已经取得了较好的效果。通过我们的研究,发现两种类型的论文都采用了并行ensemble方法。首先,在面向应用的论文中基于并行集成方法更受欢迎比迭代集成(比如在郝et al ., 2014年,魏et al ., 2013 b,戴,2015年,等等),和最新的重采样方法通常是结合基于并行的整体方案(比如在彭et al ., 2014年,太阳et al ., 2015年,李et al ., 2013 a,等等)。由于并行集成具有节省时间和易于开发的优点,因此推荐使用它们来解决实际问题。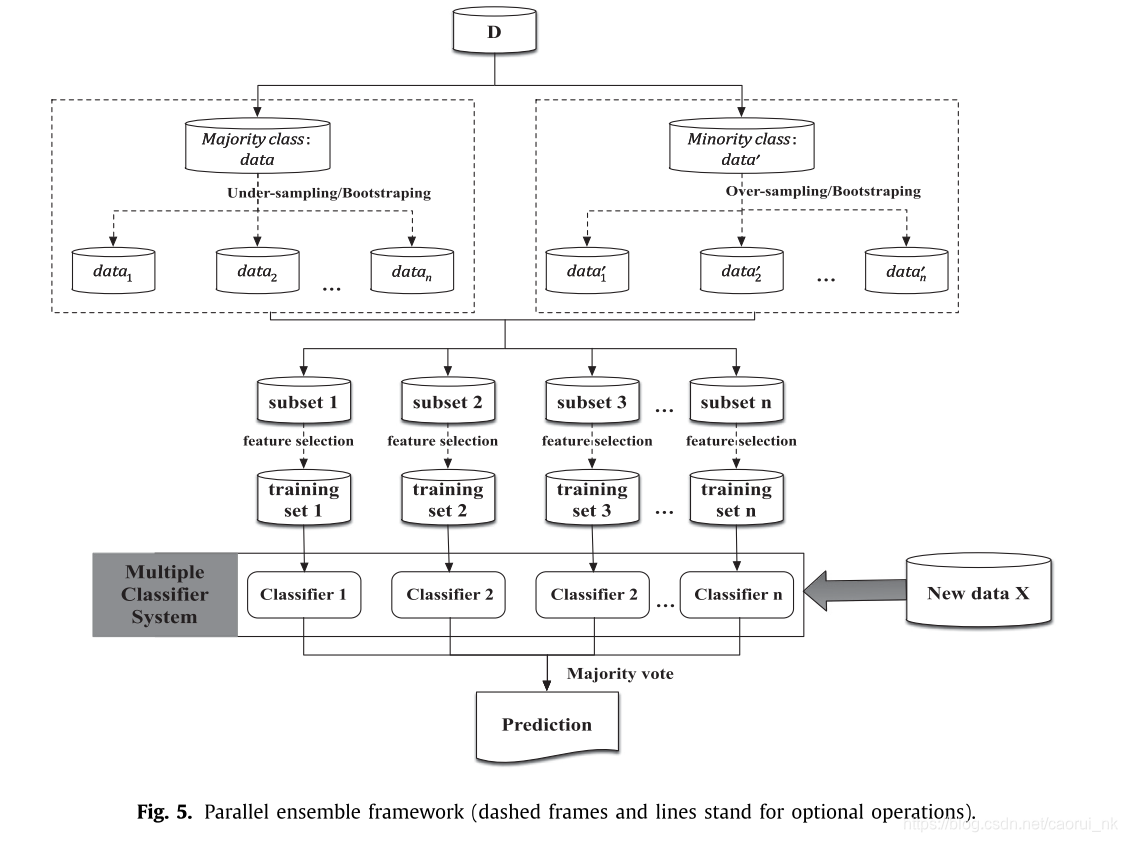
Base classifier choice in ensemble models 集成模型的基分类器选择
在实现迭代或并行集成方法时,需要一个基本分类器,它可以是支持向量机和神经网络等任何经典模型。图6总结了被提出的集成学习算法所影响的主要基分类器。注意,有些论文研究了多个基本分类器。结果表明,SVM、NN(神经网络)、NB(朴素贝叶斯)、基于规则的分类器、基于决策树的分类器(包括C4.5、CART、random forest等新型树分类器)在分类器中选择最多。Sun等(2009)总结了一些基础分类器在从不平衡的数据中学习时遇到的困难,指出机器学习的分类器有几十种,每种分类器都有自己的优缺点。用户需要根据实际情况选择合适的基分类器。例如,支持向量机具有鲁棒性和精确性,但对缺失值敏感,难以对大规模数据进行训练。相反,决策树擅长处理缺失值的情况,但可能无法对小尺寸数据建模(Li et al., 2016c)。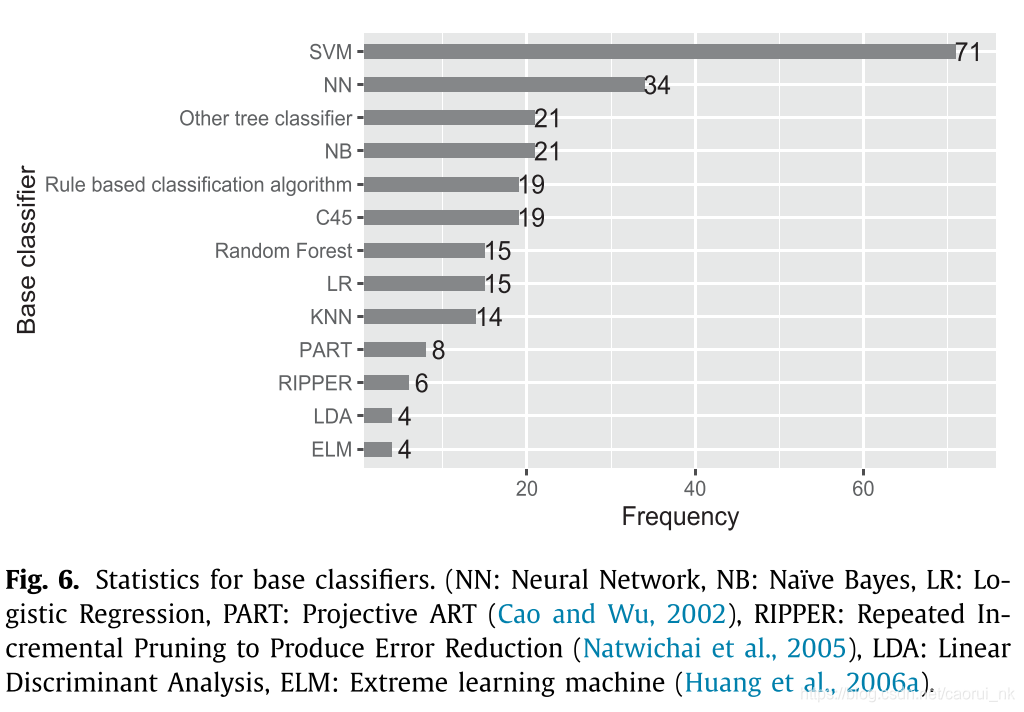
Algorithmic classifier modification 分类器算法修改
提高现有分类算法的学习能力,提高不平衡数据的分类性能是另一个主要的不平衡学习研究方向。近几十年来,在班级不平衡学习和罕见事件检测领域,已有160多个新的改进分类器被提出。支持向量机,决策树,神经网络,KNN, ELM,基于规则的分类器,朴素贝叶斯修分别有54篇、33篇、24篇、15篇、13篇、11篇和9篇论文。表5总结了一些常用的技术来改进这6个分类器。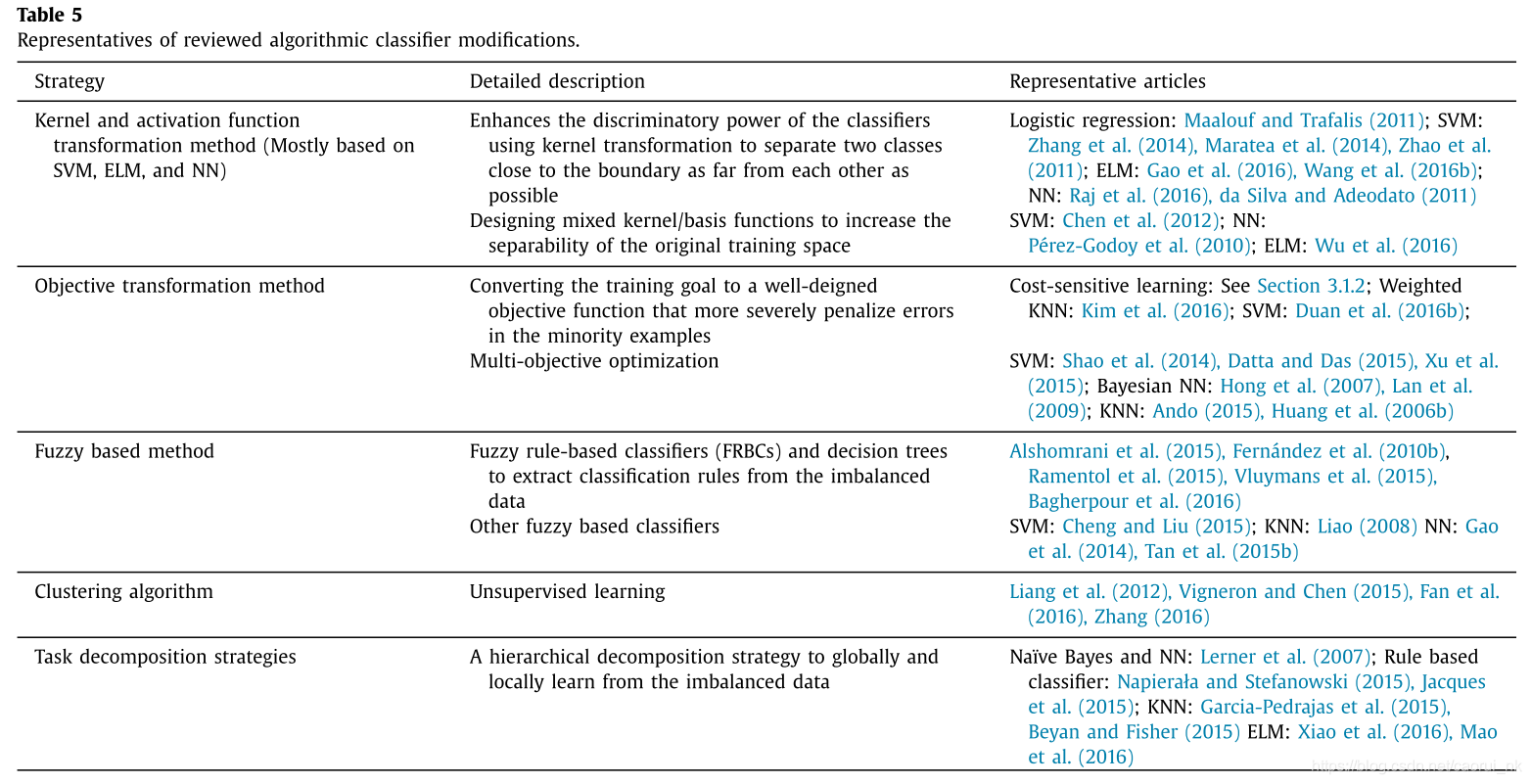
Multi-class imbalanced learning 多类别不平衡学习
多类学习一直被认为是分类算法的难点,因为多类分类的性能明显低于二进制分类。当面对不平衡的数据时,这个问题变得更加复杂,因为类之间的边界可能严重重叠(Fernandez et al., 2013)。近年来,多类不平衡学习引起了人们的广泛关注。综述的32篇论文将二元类不平衡解推广到多类情形。两种通用化方法似乎是最常用的;一种方法(OVO)和一种方法(OVA)都基于分解技术。OVO和OVA分解方案如图7 (Zhou, 2016)所示,其中C i表示所有标记为i的例子,f j是分类器j生成的假设。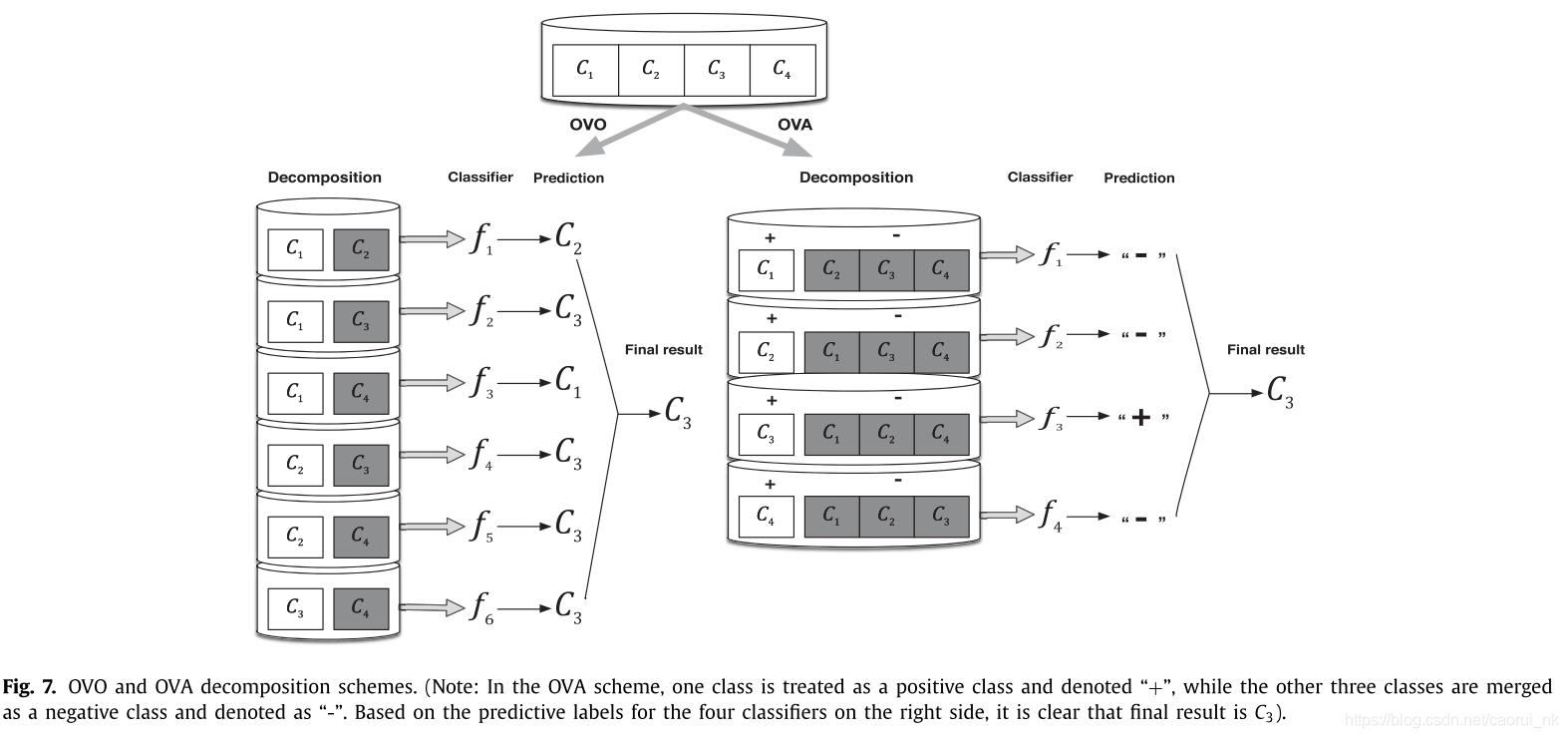
Fernandez等人(2013)研究了OVO和OVA分解,以及ad-hoc学习算法,这些算法对于解决多个班级学习问题是很自然的。实验结果表明,OVO的性能优于OVA。然而,分解方法和stan- dard自组织学习算法之间没有显著差异。王和姚(2012)也得出了类似的结论。他们认为没有必要使用类分解,而直接从整个数据集中学习就足以进行多类不平衡分类。他们的结论是,将类别分解与类别不平衡技术结合起来,而不考虑类别的全局分布是不明智的。
虽然上面的文章表明OVA不是最好的可用工具,但它仍然很受欢迎,因为它需要更少的分解,因此是时间效率。与OVA相比,OVO的数量较少。表6显示了OVO、OVA和ad-hoc相关文章的摘要。
Model evaluation in the presence of rare classes 罕见类模型评估
模型选择和模型评价是机器学习的两个关键过程。因此,性能度量是评价分类器有效性和指导学习的关键指标。精度是最常用的分类评价指标。然而,在不平衡的情况下,由于偏向于多数类,准确性可能不是一个好的选择。适应于不平衡数据问题的性能指标,如**(ROC)、g -均值(GM)和F-measure(F m),由于考虑了类分布,因此不太可能出现分布不平衡。由于这些测量方法广泛应用于不平衡学习领域,其详细公式可以在大多数不平衡学习相关论文中找到(如Branco et al., 2016, Lopez et al., 2013),所以我们只在附录中介绍这些测量方法(见补充资料)。也有一些工作致力于提出新的不平衡数据的评价指标,如调整后的F-measure** (Maratea et al., 2014)和概率阈值法(Su and Hsiao, 2007)。
最常用的指标包括准确度、AUC/ROC、F-Measure、G-mean、精密度、灵敏度、特异性、平衡accuracy和Matthews相关系数(MCC)。两篇论文研究了这些指标对不平衡学习的有效性,并提出了一些建议(Gu et al., 2009;(Jeni et al., 2013)。图8给出了所有度量的使用总结。请注意,尽管基于准确性的度量标准已经被证明偏向于大多数类,但它们仍然经常用于研究中,因为它们是用于分类任务的最普遍和最直观的度量标准。AUC、g -均值和F-测度也常被用作模型比较和模型选择的评价指标。
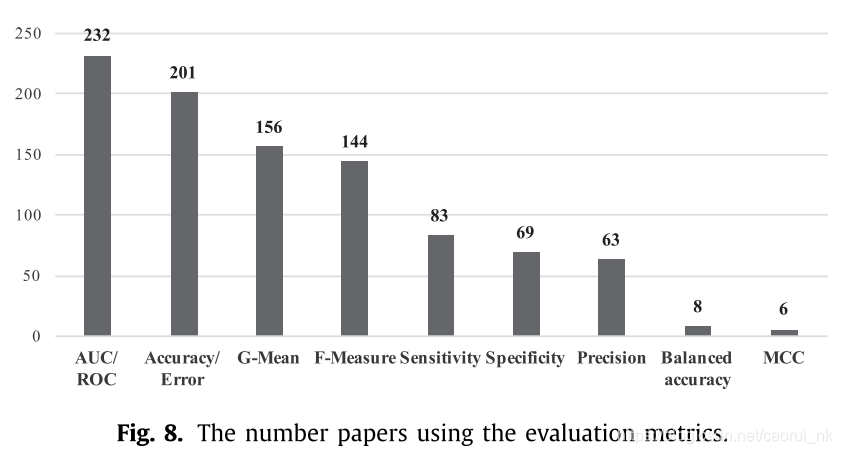
值得注意的是AUC/ROC曾被Hand(2009)质疑,他认为ROC依赖于模型生成的截止点,当只考虑最优阈值时,截止点与误分类代价相关,因此模型的ROC是不一致的。然而,对于这一解释也有一些反对意见(Ferri et al., 2011)。一般来说,AUC/ROC被认为是衡量排名绩效的一个有用指标。
上述度量只适用于二进制分类问题。将这些度量扩展到多类情况的一种自然方法是使用分解方法(3.2.3中描述的OVA和OVA方案),并取每个成对度量的平均值(Cerf et al., 2013)。MAUC (Hand and Till, 2001)是AUC均值的一个例子,在Guo et al.(2016)和Li et al.(2016)中,使用了AUC的一个推导。Phoungphol等(2012)采用了另一种基于AUC的多类度量,ROC下的体积(VUC), Sun等(2006)采用了g均值的扩展。对于F-measure, Phoungphol等人(2012)引入了微观平均和宏观平均两种类型的平均值。
Imbalanced data classification application domains 不平衡学习应用领域
目前,人们对利用自动化方法——尤其是数据挖掘和机器学习方法——来分析常规收集的大量数据非常感兴趣。一类重要的问题涉及基于过去事件预测未来事件。事件预测通常包括预测罕见事件(Weiss和Hirsh, 20 0 0)。罕见事件是发生频率较低但可能造成深远影响和扰乱社会的事件(King and Zeng, 2001)。罕见事件以多种形式潜伏着,包括自然灾害(如地震、太阳耀斑、龙卷风)、人为危害(如金融欺诈、工业事故、暴力冲突)和疾病。由于这类数据通常是不平衡的,许多研究都是在不平衡学习方法的帮助下构建罕见事件检测系统。在文献中,我们发现162篇文章是面向应用的,从管理到工程。在第4.1节中,我们开发了一个分类法方案,将这162篇文章分类为13个罕见事件检测应用领域。在第4.2 -4.14节中,描述了每个类别及其子类别,并给出了一些例子。
本节的主要目的是向来自不同领域的研究人员展示如何应用不平衡学习来检测他们研究领域中的罕见模式/事件。由于在第3节中已经介绍了学习技术,所以我们试图在这一节中省略技术细节,以避免重叠,并在这一节中更多地关注于描述特定的问题以及相应的数据收集和特征工程过程。此外,通过我们的研究,我们还发现了一些有趣的现象,关于哪些方法在不同的领域得到了广泛的应用。
Taxonomy of application domains 应用领域的分类
不包括UCI和KEEL等流行基准测试,我们将实际应用程序分为13类。每个类别包含几个主题。我们将管理应用分为六大类:金融、能源、安全、应急、环境和企业管理。其余类别涉及工程和人文领域,分为:化学、生物和医学工程;信息技术;电子和通信;基础设施和工业制造业;警方,社会和教育;农业和园艺;其他领域。表7显示了论文的分类和频率分布。注意,有些应用程序可能是跨学科的,我们只是简单地将它们分为最能描述其领域的组。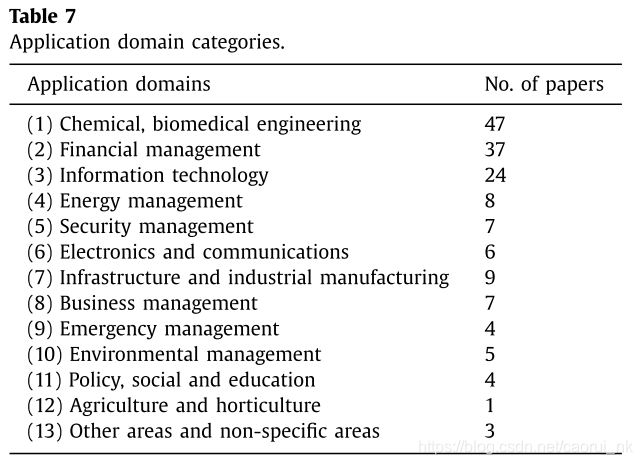
Chemical and biomedical engineering Biomedical 化学和生物医学工程生物医学
生物医学工程将工程原理和设计理念应用于医学和生物保健目的(如诊断、监测和治疗),而化学工程则试图将化学材料或细胞转化为有用的形式和产品。生物医学和化学工程都采用物理和生命科学以及应用数学、计算机科学和经济学。应用通常包括建立一个决策支持系统来检测和预测化学过程和生物医学活动中的异常结构。这些包括疾病诊断、疾病早期预警、蛋白质检测、化学排斥和耐药性。相关研究问题及参考文献见表8。
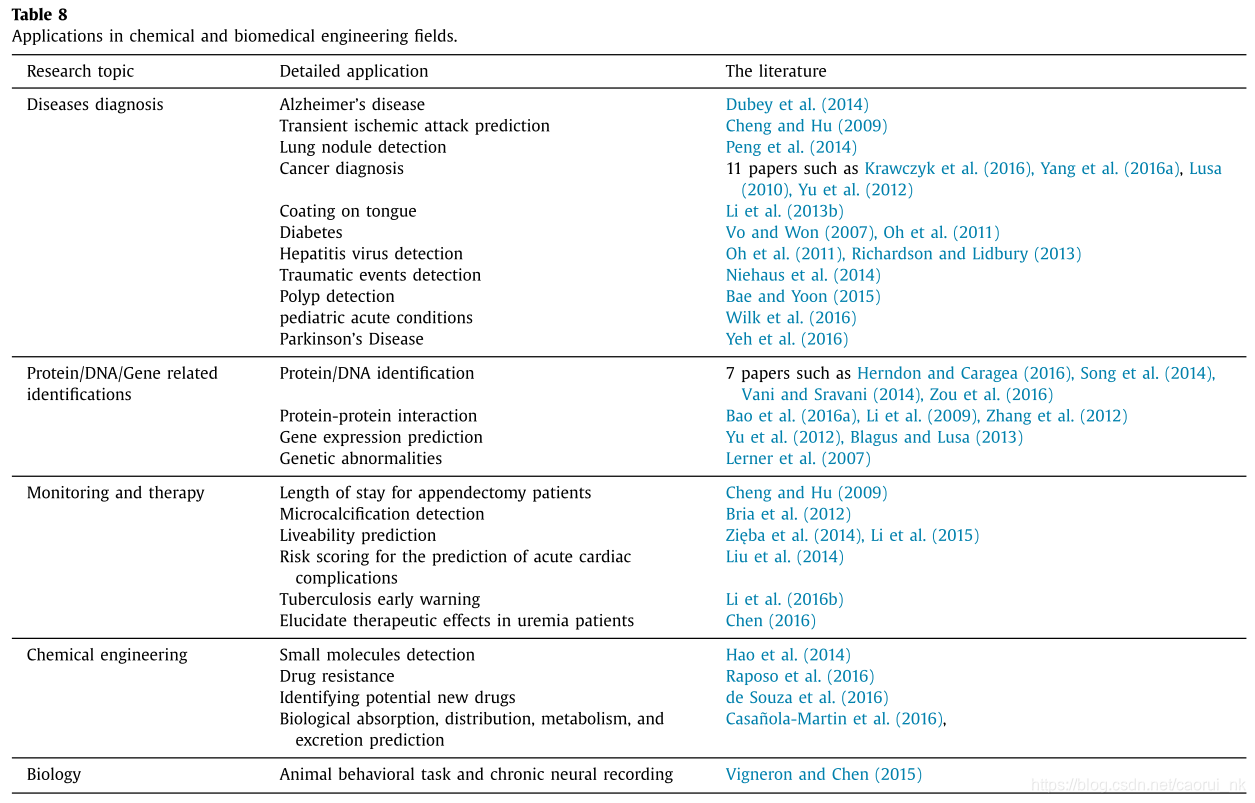
蛋白质检测、基因表达预测和疾病诊断是目前化学和生物医学数据分类中研究最多的问题。蛋白质数据集通常是不平衡的数据集,蛋白质检测试图根据其序列表达来识别蛋白质的结构和功能(Dai, 2015)。在蛋白质检测任务中,将序列中的非数值属性转换为数值属性时,特征提取是必不可少的(Vani和Sravani, 2014;Wasikowski和Chen, 2010)。类似的性质可以在基因表达鉴定(Yu et al., 2012)和DNA鉴定(Song et al., 2014)中发现。图像数据也经常用于分析异常生物医学事件:Bria等(2012)使用198幅图像检测数字乳腺x线照片上的微钙化;Lerner等(2007)使用鱼信号图像分析异常基因;Bae和Yoon(2015)专注于在内镜或结肠镜图像中寻找息肉的位置和大小。
financial management 金融管理
财务管理是企业管理的一个分支。我们的评论发现有37篇论文解决了财务问题;因此,我们将财务管理从业务管理中分离出来。财务管理是企业财务资源的规划、获取和控制的管理活动。Sanz等(2015)对股票市场预测、信用卡/贷款审批申请系统、欺诈检测等11个财务问题进行了不平衡数据分类方法的测试。其他论文及其应用设置见表9。
这类论文多集中在财务舞弊的侦查方面,包括电子支付诈骗、信用卡和信用卡诈骗、公司活动诈骗、保险诈骗、公司财务报表诈骗等。Krivko(2010)强调了构建有效的欺诈检测系统的几个挑战;日常交易记录量大,欺诈发生频率低,信息延迟。检测欺诈事件是一个典型的不平衡学习问题,因为交易记录高度倾斜。通常,用于培训欺诈检测系统的数据集包括客户简介和交易记录(交易类型、日期、位置、金额等)。Kim等(2012)描述了信用卡和贷款欺诈检测中使用的违约信息的一些代表性特征。其他有趣的研究课题也被研究。龚和黄(2012)基于圣地亚哥房地产信息,收集了37个关于房产状况以及是否进行再融资的变量来预测房产再融资。Alfaro et al.(2008)和Zhou(2013)利用各种特征作为判断企业生命周期阶段甚至预测企业破产的因素:股息支付率、销售增长、资本支出、企业年龄以及其他企业档案,如记录的负债、资产、销售、法律结构和税务信息。文献中还利用了网络行为信息、社交网络信息等其他数据来源(Abeysinghe et al., 2016)。
Information technology 信息技术
信息技术是计算机存储、检索、传输和操作数据的应用。随着web数据的爆炸式增长,从信息设备和平台检测有趣的事件对于业务决策和策略形成至关重要。传统的软件缺陷检测、网络入侵检测等异常检测方法都是在不平衡的情况下实现的。本领域内收集的文献根据研究对象分为三个部分,如表10所示。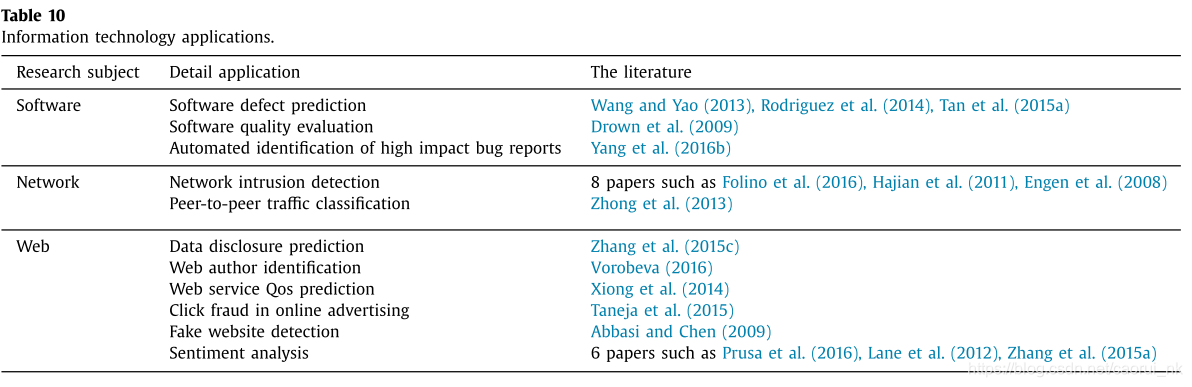
软件缺陷和质量预测是软件工程中的两个主要研究课题。模块属性通常用于预测缺陷或评估软件的质量。另一方面,网络入侵检测往往需要在线进行预测,导致在线学习不平衡,Wang等(2013)介绍了详细的技术。随着internet技术的飞速发展,web数据已经成为分析客户偏好的重要资源。Vorobeva(2016)使用web-post来识别web作者,情感分析已经成为一个热门话题,它从web上的用户生成内容(UserGenerated Content, UGC)来处理和分析用户的偏好。由于用户对特定话题的看法往往是一致的,因此用于情绪分析的UGC数据通常是不平衡的。由于情感分析等web数据挖掘模型往往是从文本、图像、数值等异构数据源构建的,在设计不平衡学习模型之前,需要使用特征工程技术来生成特征。例如,单词嵌入(Mikolov et al., 2013)是一种为文本构建单词表示的有效技术,卷积神经网络(CNN,或ConvNet)在从原始图像生成特征方面很受欢迎(Razavian et al., 2014)。
Energy management 能源管理
能源管理包括能源生产和能源消费单位的规划和运行。与这一领域相关的论文有8篇。Guo等(2016)和Li等(2016c)利用油井测井数据识别井中各层含油地层。Xu等人(2007a, b)重点研究配电中断识别,以提高配电系统的可用性和可靠性。利用历史配电中断数据和环境属性提取树木、动物和闪电引起的故障模式。Ashkezari等(2013)建立了状态评估模型,对电力变压器的健康(适应度)水平进行评估。利用溶解气体分析和绝缘油试验数据对模型进行了训练。Qing(2015)专注于预测电力系统库存物资消耗需求。他们发现,电力系统中基于项目的需求和基于运营/维护的需求具有扭曲的频率;因此,建立一个能够预测可能的材料消费需求的不平衡学习模型,可以比传统的机器学习模型得到更好的结果。欺诈检测技术也应用于能源领域。尤其是电力欺诈,即不诚实或非法使用电力设备或服务,以避免计费(Fabris et al., 2009;Nagi等,2008)。由于电力客户消费数据是由时间序列记录组成的,因此需要对这些属性进行特殊处理,以提取所有相关信息(Fabris et al., 2009)。
Security management 安全管理
为了实施有效的控制,组织使用安全管理程序,如潜在的风险检测、风险评估和风险分析来识别威胁、犯罪和其他异常。侵犯知识产权和恶意破坏等内部威胁是安全部门需要发现的重要事件。Azaria等(2014)分析了内部威胁行为。使用Amazon Mechanical Turk (AMT)进行的实验旨在区分正常行为和那些打算泄露组织隐私数据的人。安全管理的另一个常见应用是检测监控视频中的威胁和异常事件(Mandadi和Sethi, 2013;王等,2016a;王等,2015b;文等,2015;徐等,2016)。基于监控视频的事件自动检测系统通常包含特征提取和模式分类组件(Xu et al., 2016)。在特征提取方面,离散光流描述符、基于轨迹的方法(Xu et al., 2014)和稀疏时空角描述符(稀疏时空角描述符)等方法是目前广泛使用的从局部图像区域和视频剪辑中提取特征的方法(Mandadi和Sethi, 2013)。在模式分类阶段,可以使用不平衡数据分类算法来识别异常动作和事件。
Electronics and communications 电子与通信
在我们的研究中,有五篇论文是关于电子和电信的,其中四篇是关于检测电信欺诈的。简而言之,电信欺诈可以简单地定义为在没有任何支付意图的情况下获得电信服务的任何活动(Hilas和Mastorocostas, 2008)。Hilas和Mastorocostas(2008)研究了几个电信欺诈类别,如技术欺诈、合同欺诈、黑客欺诈和程序欺诈。同样,Farvaresh和Sepehri(2011)发现了订阅欺诈、拨号欺诈、免费电话欺诈、费率服务欺诈、手机盗窃和漫游欺诈,并试图基于通话详细记录和账单数据来检测住宅和商业订阅欺诈。其他研究,如Olszewski(2012)和Subudhi和Panigrahi(2015)根据用户资料区分正常和欺诈行为。Kwak et al.(2015)和Tan et al. (2015b)这两篇论文都研究了电子和电子器件晶圆中电路缺陷或其他异常的检测。Tan等人(2015b)在一个加密的数据集上训练了一个机器学习模型,该数据集由三个主要的半导体制造操作过程(etest、sort和class test)生成。
Infrastructure and industrial manufacturing 基建及工业制造业
在这一类别中,有8篇论文采用了不平衡学习方法来解决工业制造问题。Cateni etal .(2014)对两个金属行业问题采用了重采样方法。第一个问题是生产过程中产品表面缺陷的自动检测系统。炼钢领域的另一个工业应用是确定喷嘴以确定最终产品质量。Sun等人(2010)重点研究了在制造中广泛使用的纳米cmos电路中变化的检测过程。该方法在6个仪器指标上进行了测试,并在45纳米CMOS器件上实现。廖(2008)提出了一种多类不平衡数据分类算法来识别可能分布不均匀的不同类型焊缝缺陷。在他们的实验中,每个焊缝缺陷样本都有12个特征描述形状、尺寸、位置和强度信息,这些特征都是从射线图像中提取出来的。他们研究的目的是对焊缝缺陷进行分类,以确定是否存在熔合、未焊透、气孔、气孔或裂纹。塔吉克等(2015)提出了一种工业燃气轮机故障检测系统。近年来,将不平衡学习应用于机械故障诊断研究:Duan等(2016a)和Mao等(2017)对滚子轴承可能发生的多种故障进行了分类;Jin et al.(2014)和Zhang et al. (2015b)构建了几个特征来表示机器的不同健康状况,以检测潜在的机器故障。还有一篇论文是关于建筑建模的。Xin等(2011)认为,从激光雷达数据中检测建筑物的足点是基础,也是建筑物建模和边缘检测应用的难点之一。因此,他们试图从非地面点数据集中检测建筑点,该数据集由两个不平衡的数据集组成,分别来自建成区(密集的建筑和小树林)和农村地区(密集的树木和低矮的房屋)。
Business management 商业管理
企业管理是一个广泛的概念,包括计划、组织、人员配备、领导和控制一个组织来实现一个目标。由于财务管理是在4.3节中介绍的,这一类别中只讨论了7篇关注其他业务功能的论文,其中大部分与客户关系管理(CRM)相关。数据挖掘是一个重要的组成部分,CRM分析大型数据流和洞察客户行为、需求和偏好(Lessmann Voß,2009)。Sultana(2012)利用一家保险公司的客户数据来识别那些更愿意购买大篷车保险的潜在客户。感兴趣的特征是来自客户邮政编码的社会人口统计变量,以及关于其他保单所有权的变量。Chen et al. (2012), Verbeke et al. (2012), Wu and孟(2016),Yi(2010)选择购买时间、购买金额、折扣、买家信用评级、支付积分和人口统计信息作为特征来检测客户流失行为。Chang and Chang(2012)采用不平衡学习模型对在线拍卖进行监控,利用评级密度、时间信息和历史记录等属性来检测重大异常和欺诈行为。Bogina等人(2016)利用会话和在会话中单击的条目的时间特性来预测是否以购买结束。
Emergency management 紧急情况管理
令我们惊讶的是,很少有评论文章关注预测紧急事件。紧急情况是指对健康、生命、财产或环境构成直接风险的情况(Anderson and Adey, 2012)。考虑到紧急事件的不常见性,它们通常是非常罕见的事件。由于突发事件的突发性和破坏性,预测突发事件是一个有价值而又困难的研究课题。现有的应急事件检测研究主要集中在自然灾害方面。Maalouf and Trafalis(2011)、Maalouf and Siddiqi(2014)和Trafalis等人(2014)建立了不平衡学习模型来预测龙卷风。龙卷风数据集有83个属性,包括雷达导出的描述中气旋各方面的速度参数、月属性、描述风暴前环境的特征以及大气在特定高度爆炸抬升空气的倾向。金正日et al .(2016)应用不平衡学习模型来检测一些紧急情况如地震、火灾、洪水、滑坡、核事件,火山使用文本文档收集来自匈牙利国家无线电Distress-Signaling Infocommunications协会(RSOE,显示器非凡的风险事件发生在世界各地,每天24小时)。
Environmental management Environmental 环境管理
环境资源管理是人类社会对环境的相互作用和影响的管理。Vong等(2015)认为空气污染指数预测是一个时间序列问题。在他们的研究中,使用在线顺序学习方法来预测pm10水平(好、中、重度)。选取澳门政府气象中心收集的大气污染数据(包括气压、气温、平均相对湿度、风速等)作为案例研究。Topouzelis(2008)专注于海洋石油泄漏,这可能严重影响海洋生态系统。利用污染物排放量及其对海洋环境的影响对海水水质进行了评价。同样,为了监测石油泄漏事件,Brekke和Solberg(2008)使用合成孔径雷达图像(SAR)来区分石油泄漏与其他自然现象。另外两篇论文专注于预测污染阈值超标。Lu和Wang(2008)采用成本敏感SVM算法预测臭氧阈值超标(污染物日),Tsai等(2009)采用成本敏感神经网络方法预测某一时段的臭氧。两项研究都证明了代价敏感算法能够有效地解决数据不平衡问题,并在环境应用中获得较好的稀有样本(污染天数)预测。然而,重新取样或综合方法在环境管理方面的应用尚未得到研究。
Policy, social and education
与公共事业有关的三个关键概念被纳入这一类目,但只有四篇论文集中讨论社会和教育问题。Marquez-Vera等人(2013)认为,检测学生的失败是更好地理解为什么如此多的年轻人未能完成学业的有效方法。这是一项艰巨的任务,因为有许多可能影响学业失败的因素;此外,大多数学生通过了考试。因此,该故障被认为是一个高维、不平衡数据的预测问题。在他们的研究中,有77个属性(例如社会经济因素;个人、社会、家庭和学校因素;选择以前的和现在的分数),建立不平衡数据分类模型,预测学生高中是否及格。其他有趣的研究包括:Huang等人(2016)分析视频数据预测人群计数;Ren等人(2016b)设计了一个综合的特征工程流程来预测潜在的实时红灯运行,他们使用的特征包括占用时间、时间间隔、使用黄时间、车辆通过等。Gao等(2016)从可穿戴设备中生成传感器数据,用于监测秋季事故的发生。
Agriculture and horticulture
农业和园艺是科学的一个重要领域。然而,我们在这组中只找到了一篇论文。D’este等人(2014)通过基于水质信息预测所需的最短关闭时间,解决了贝类养殖场的关闭问题。所使用的数据集是18692个手工水样本,由澳大利亚塔斯马尼亚贝类质量保证项目从38个生长区域采集。
Other areas and non-specific applications Applications
不符合12个类别中的任何一个的应用程序被分配到这个类别。详细地,我们发现了两篇与天文学研究有关的论文。例如,Voigt等人(2014)研究了伽马射线天文探测问题,其中强子观测比伽马事件常见100到10倍。从天文学的魔术实验数据收集,以选择一个最佳阈值的信号背景分离。al - ghraibah等人(2015)试图通过太阳磁场的定量测量来预测耀斑活动来探测太阳耀斑。最后,Vajda and Fink(2010)和Alsulaiman等人(2012)提出了一种不平衡场景下的手写识别系统,用于识别验证。
Future research directions of imbalanced learning
在这一部分,我们提出了可能的研究方向的不平衡学习基于我们的调查。特别地,我们认为仍然需要考虑的不平衡技术在第5.1节中提出。第5.2节指出了一些应用领域的数据经常出现不平衡,但没有得到很好的研究。
At the technical level
Diversity within ensembles
在这一部分,我们提出了可能的研究方向的不平衡学习基于我们的调查。基于集成的学习算法作为提高弱学习者分类性能的一种有效方法,已被广泛应用于解决许多学习任务的不平衡问题。Wang and Yao(2009)认为集成模型的性能取决于单个分类器的准确性和所有分类器之间的多样性。多样性是分类器对一个问题做出不同决策的程度。多样性允许投票的准确性大于单一分类器。他们展示了多样性如何影响分类性能,尤其是在少数族裔班级。他们的实证研究表明,多样性越大,少数人的记忆能力越强,但对多数人的记忆能力却有害,因为当准确率不够高的时候,多样性会增加将例子归类为少数人的可能性。此外,当在集成模型中增加多样性时,多类更加灵活和有益。类似的研究中可以找到Błaszczy´nski和Lango (2016)。在构建集成模型时,已有Diez-Pastor等人(2015b)、Krawczyk和Schaefer等人(2013)、Lin等人(2013a)等人将多样性考虑在内,在集成模型中使用多样性测度或进化方法对分类器进行修剪,以保持多样性。然而,多样性问题仍然需要仔细研究,因为大多数现有的应用程序倾向于首先学习精确的基分类器,然后将其集成到集成中。Wang and Yao(2009)认为,在中等精度和中等多样性的集成模型中,状态可以导致更好的性能,但是精度和多样性之间的权衡仍然不清楚。此外,与此相关的是,虽然剪枝分类器在增加集成多样性和避免过度拟合方面具有强大的功能,但是在剪枝过程之前,仍然需要对许多基分类器进行训练和评估,这是非常耗时的。在未来的研究中,需要建立一个能够更有效地整合多样化和精确的弱学习者的集成模型。特别地,我们认为仍然需要考虑的不平衡技术在第5.1节中提出。第5.2节指出了一些应用领域的数据经常出现不平衡,但没有得到很好的研究。
Adaptive learning
在这一部分,我们提出了可能的研究方向的不平衡学习基于我们的调查。基于集成的学习算法作为提高弱学习者分类性能的一种有效方法,已被广泛应用于解决许多学习任务的不平衡问题。Wang and Yao(2009)认为集成模型的性能取决于单个分类器的准确性和所有分类器之间的多样性。多样性是分类器对一个问题做出不同决策的程度。多样性允许投票的准确性大于单一分类器。他们展示了多样性如何影响分类性能,尤其是在少数族裔班级。他们的实证研究表明,多样性越大,少数人的记忆能力越强,但对多数人的记忆能力却有害,因为当准确率不够高的时候,多样性会增加将例子归类为少数人的可能性。此外,当在集成模型中增加多样性时,多类更加灵活和有益。针对不平衡数据分类问题,提出了数百种算法,并证明了它们在某些方面优于其他算法。然而,从技术论文中,我们没有发现任何特定的算法在所有的基准测试中都是优越的。大多数提出的算法一致地处理所有不平衡的数据,并使用一个通用的算法来处理它。然而,由于不平衡数据在不平衡比、特征个数、类数等方面存在差异,不同类型数据集学习时的分类器性能也不同。当构建集成模型时,学习模型中的这种不确定性变得更加明显。Li等(2016c)认为使用特定的集成分类器来处理各种不平衡的数据是低效的。训练样本的选取方式、基分类器的选择以及最终的集成规则都会影响模型的学习质量。在过去的十年中,虽然对构建统一的集成框架进行了深入的研究,但是集成框架中的每个组件通常都是由用户决定的。这就提出了另一个问题,即如何自适应地选择一个详细的算法,使集成框架中的每个组件都适合不同类型的不平衡数据。除了对集成模型进行自适应学习外,其他论文还研究了自适应选择信息实例进行重采样的方法,并自动学习最佳采样率(Lu et al., 2016;Moreo等,2016;任等,2016a;Yun等,2016;叶等,2016;张等,2016a)。此外,Krawczyk等(2014)尝试从数据中学习成本敏感学习的成本矩阵。注意到这些都是最近的研究,也支持适应性学习可能是不平衡学习的另一个研究主题。类似的研究中可以找到Błaszczy´nski和Lango (2016)。在构建集成模型时,已有Diez-Pastor等人(2015b)、Krawczyk和Schaefer等人(2013)、Lin等人(2013a)等人将多样性考虑在内,在集成模型中使用多样性测度或进化方法对分类器进行修剪,以保持多样性。然而,多样性问题仍然需要仔细研究,因为大多数现有的应用程序倾向于首先学习精确的基分类器,然后将其集成到集成中。Wang and Yao(2009)认为,在中等精度和中等多样性的集成模型中,状态可以导致更好的性能,但是精度和多样性之间的权衡仍然不清楚。此外,与此相关的是,虽然剪枝分类器在增加集成多样性和避免过度拟合方面具有强大的功能,但是在剪枝过程之前,仍然需要对许多基分类器进行训练和评估,这是非常耗时的。在未来的研究中,需要建立一个能够更有效地整合多样化和精确的弱学习者的集成模型。特别地,我们认为仍然需要考虑的不平衡技术在第5.1节中提出。第5.2节指出了一些应用领域的数据经常出现不平衡,但没有得到很好的研究。
Online learning for imbalanced data stream classificatio
数据的巨大容量和可访问性极大地吸引了人们对大数据分析的热情;它的挑战之一是处理和响应流和快速移动的输入数据。在线学习的目的是一次处理一个实例,因此在数据挖掘社区中得到了越来越多的关注。首先,它接收一个示例,然后进行预测。如果预测错误,它将遭受损失并更新其参数(Maurya et al., 2015)。在很多数据流应用中都可以看到倾斜的类分布,例如在控制监控系统的故障诊断和网络和垃圾邮件识别中的入侵检测(Hoens et al., 2012)。当在线学习数据流时,可能会出现三个主要困难:a).底层数据分布往往随着时间的推移而发生较大的变化,这被称为概念漂移(或非平稳)学习(Ghazikhani et al., 2014)。b).网络课堂学习的不平衡存在显著的困难,因为对于哪些数据类应该被视为少数,哪些数据类应该被视为多数,以及不确定性不平衡状态,缺乏先验知识(Wang et al., 2014b, 2015a)。c).数据稀疏问题普遍存在于数据流中(Maurya et al., 2016)。这鼓励研究动态确定数据流中的班级不平衡状态,并有效地使在线学习者适应班级不平衡(Ghazikhani et al., 2013a)。Wang Boyu (2016), Dal Pozzolo et al. (2015), Ditzler and Polikar (2013), Wang et al.(2013)设计了用于学习不平衡数据流的重采样集成模型。然而,在现有文献中,对成本敏感的文献并不多见,Ghazikhani et al. (2013b)、Maurya et al.(2016)和Wang et al. (2014a)只发现了三种模型。在对大数据流进行分类时,对成本敏感的学习在计算上比数据采样技术更高效。因此,我们建议研究人员更多地关注对成本敏感的在线学习。此外,基于ELM的在线学习算法也得到了普及,ELM的效率满足实时预测的要求(Mao et al., 2017;Mirza等。2015a,b)。“随着大数据时代对随时可能到来的任何数据的快速、准确响应的要求越来越高,动态、不平衡情境下的在线学习可能成为一个热门的新研究课题。
Semi-supervised learning and active learning
在一些数据分析领域,海量数据的收集成本较低;然而,获得带标记的示例来训练分类器是很昂贵的。在大数据中,具有少量标记实例(通常是少数)和大量未标记实例的大型语料库是常见的。半监督学习技术试图利用未标记实例中的内在信息来改进分类模型(Zhu和Goldberg, 2009);然而,这些技术假定标记的实例涵盖所有的学习类,而事实往往并非如此。此外,当存在不平衡的类分布时,从少数类中提取带标记的实例可能非常昂贵。收集更多标记示例的一种方法是请专家或用户进行广泛的标记,这可能导致一种特殊的半监督学习方法,称为主动学习。主动学习允许专家根据标准对新实例进行标记,从而减少标记工作(Frasca et al., 2013)。主动学习的基本思想是估计标记一个未标记实例的价值。根据分类任务的目标,最有价值的查询是通过学习算法来选择的,而不是像被动监督学习那样随机选择(Escudeiro and Jorge, 2012)。针对不平衡数据提出的主动学习算法很少(Dong et al., 2016;傅和李,2013;Oh et al., 2011)。当存在不平衡的数据分布时,需要花费更多的精力来研究信息示例的选择和使用。
At a practical level
回顾第4节总结的应用分布,与管理科学和决策密切相关的两个研究领域很少采用不平衡学习技术。首先是应急管理。研究发现,由于自然灾害是典型的罕见事件,有四篇文献试图在分布不平衡的数据下预测自然灾害。然而,其他类型的紧急事件,包括事故(如森林火灾)、公共卫生事件(如霍乱、埃博拉和疟疾等疾病的暴发)和社会安全事件(如恐怖主义袭击)很少在不平衡的学习领域讨论。随着物联网的发展,研究人员和科学家可以使用传感器收集到丰富的监测数据。由于大规模多源、异构数据可以很容易地收集在大数据时代,它可能是可能的开发特性工程技术融合多源传感器数据等数据,文本和监控视频在互联网上构建机器学习系统来检测其它类型的紧急事件。当设计学习模型时,不平衡的学习技术是至关重要的,因为收集到的与紧急事件相关的数据可能是不平衡的。在我们看来,另一个有价值的研究方向是使不平衡学习适应安全管理问题。特别是近年来,随着社交网络的迅速发展,互联网安全管理受到了越来越多的关注。人们倾向于在社交媒体上表达他们的爱和恨,从电影到政治策略,这也使得极端分子有可能触犯公共秩序。情绪分析和谣言检测可能是监测社交网络和防止风险事件发生的强大方法。在海量用户生成内容中挖掘风险报表是一个罕见的事件检测问题,可以通过不平衡学习技术来解决。
Conclusions
本文试图对罕见事件检测技术及其应用进行全面的综述。特别是采用数据挖掘和机器学习的观点,将罕见事件检测看作是一类不平衡的数据分类问题。我们收集了527篇关于学习不平衡和罕见事件检测的论文。不像其他在不平衡学习领域发表的调查,我们从技术和实践的角度回顾了所有的论文。通过我们的回顾,我们也发现了一些关于一些领域中常用方法的见解:
- 在化学和生物医学工程领域,基于重采样的集成分类器得到了广泛的应用。由于这些领域使用的数据通常是具有固定结构的临床数据,因此很少考虑特征工程。然而,对于那些高维数据(如蛋白质数据),特征选择是一种流行的选择。
- 复杂的特征工程过程对于财务管理、业务管理等管理任务非常重要。用于处理特定任务的特征通常由专家精心设计。与其他领域不同的是,此类领域的预测目标往往是利润驱动,而不是准确性驱动。因此,经常使用成本敏感学习,错误分类的成本可以由专家或管理人员决定。在管理领域中广泛使用的分类器是基于规则的分类器,如决策树和专家系统等,其中经常引入模糊理论。这可能是因为,除了做出明智的决策外,了解决策的标准对公司来说也是至关重要的。
- IT中罕见事件检测的主要挑战是数据的复杂性。网络日志和非结构化数据(如文本和图像)通常需要数据清理和特征工程处理。此外,数据流在IT领域广泛存在,需要在线学习而不是传统的线下学习。
在本文的最后,我们结合了一些未来的研究建议和我们的想法,提出了一些未来的研究方向,不平衡学习和罕见事件检测,这也将是我们未来研究项目的重点。
来源:https://blog.csdn.net/caorui_nk/article/details/98479453