在讲io操作的时候,先回忆一下冯诺依曼体系的计算机组成,分为五大构造,输入设备,存储器,输出设备,运算器和控制器。运算器和控制器合起来就是cpu。所有的数据都要先加载到内存。内存要多用,O要少用,要知道数据是在内存中怎么玩的,才能提高效率。
运算器:完成各种算数运算,逻辑运算,数据传输等数据加工处理。
控制器:控制程序的执行
存储器:用于记忆程序和数据,例如内存。
输入设备:将数据或者程序输入到计算机中,例如键盘,鼠标等。
输出设备:将数据或者程序的处理结果展示给用户,例如显示器,打印机等。
我们一般所说的IO操作,指的是文件IO,如果指的是网络IO,都会直接说网络IO。
使用Python来读写文件是一件非常简单的操作,使用open()函数来打开一个文件,获取到一个文件句柄,然后通过文件句柄就可以进行各种各样的操作。当然根据打开方式的不同能够执行的操作也会有响应的差异。
文件IO常用操作包括:open(打开),read(读取),write(写入),close(关闭),readline(行读取),Readlines(多行读取),seek(文件指针操作),tell(指针位置)
而打开文件的方式:r,w,a,r+,w+,a+,rb,wb,ab,r+b,w+b,a+b,默认使用的是r(只读)模式。只读(r,rb),只写(w,wb),追加(a,ab)而+是读原模式的补充。
打开操作
open(file,mode="r",buffering = -1,encoding = None,errors=None,newline = None,closefd = True,opener = True),这个函数是打开一个文件,然后返回一个文件对象(流对象)和文件描述符。打开文件失败的话,则返回异常。前面四个参数经常使用。
在liunux中,一切皆文件,所以打开的不仅仅是我们所说的文件。
基本的使用:
创建一个文件test,然后打开它,用完再关闭。
f = open("test.txt") #先在当前工作文件路径下创建一个txt文件,不能忘记了文件后面的txt,不然会出错。file对象。
#windows<_io.TextIOWrapper name = "test" mode = "r" encoding= "cp936">#cp936可以认为是gbk.
#Linux<_io.TextIOWrapper name = "test" mode = "r" encoding= "UTF-8">#所以window的程序直接在Linux下运行,不注意编码会出错。
#中文中,常用的字符编码有gb2312,gbk,gbk可以认为是超集,而gb2312可以认为是子集。window默认是gbk编码。
print(f.read())#读取文件
f.close()#关闭文件结果为:
abcbde bde
文件操作中,最常用的操作就是读和写,文件访问的模式有两种,一种文本模式,一种二进制模式,不同模式下,操作函数不尽相同,表现的结果也不一样。
open函数的参数
file:打开或者是要创建的文件名,如果不指定路径的话,默认就是当前路径。这个时候需要明白绝对路径和相对路径。file也可以是一个文件描述符(012)。
绝对路径就是从磁盘根目录开始一直到文件名,而相对路径则是同一个文件夹下的文件,相对于当前这个程序所在的文件夹而言,如果在同一个文件夹中,则相对路径就是这个文件名,如果在上一层文件夹,则要../。
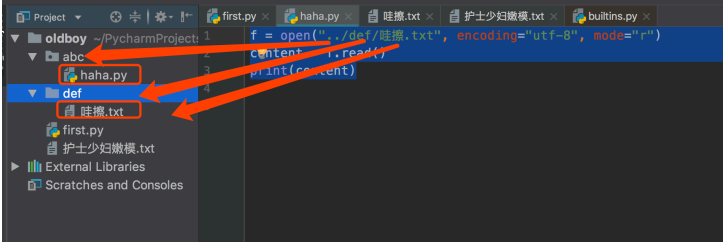
文件操作推荐使用相对路径,这样把程序拷走的时候,直接把项目拷走就能直接运行。
encoding表示编码集. 根据文件的实际保存编码进行获取数据, 一般来说,更多的是多的是utf-8.但是应该注意的是,rb读取出来的数据是bytes类型,所以在rb模式下,不能选择encoding字符集。不然会报错。
f = open("test1.txt",mode = "rb",encoding = "utf-8")
print(f.read())
f.close()
结果为:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-216-de94656245a0> in <module>
----> 1 f = open("test1.txt",mode = "rb",encoding = "utf-8")
2 print(f.read())
3 f.close()
ValueError: binary mode doesn't take an encoding argument
f = open("test1.txt",mode = "rb")
print(f.read())
f.close()
结果为:
b'xpc'
rb的作用是在读取非文本文件的时候有用,比如读取mp3、图像、视频等信息的时候需要用到。因为这种数据是没办法直接显示出来的。
mode
mode模式分为很多种:
- r(只读模式,它是缺省的,默认就是只读打开),open默认的就是只读模式r打开已经存在的文件,如果使用了write方法,会抛异常。如果文件不存在的话,也会抛异常,抛出的是filenotfounderror异常。
- w,表示只写打开,如果读取的话则会抛异常,如果文件不存在的话,则直接创建文件,如果文件存在,则清空文件内容。
- x,文件不存在的话,创建文件,并只写模式打开,而如果文件存在的话,则会抛出fileexistserror错误。
- a,文件存在,只写打开,然后追加内容。而如果文件不存在的话,则创建后,只写打开,追加内容。
- b,二进制模式,字节流,它是将文件按照字节理解,与字符编码无关,二进制模式操作时,字节操作使用bytes类型。
- t,缺省的,文本模式。它是字符流,将文件的字节按照某种字符编码理解,按照字符来操作,默认就是rt。
- +,读写打开一个文件,给原来只读,只写方式打开缺失的读或者写能力。
上面的那个例子中,可以看到默认是文本打开模式,且是只读的。
f = open("test.txt")
print(f.read())#读取文件
f.write("abc")#只读模式下,写入的话,就会报错。
f.close()#关闭文件
结果为:
abcbde
bde
---------------------------------------------------------------------------
UnsupportedOperation Traceback (most recent call last)
<ipython-input-45-224cc7b51825> in <module>
1 f = open("test.txt")
2 print(f.read())#读取文件
----> 3 f.write("abc")
4 f.close()#关闭文件
UnsupportedOperation: not writable
而在只写模式下读取,也会报错。
f = open("test.txt",mode = "w")
print(f.read())
f.close()
结果为:
UnsupportedOperation Traceback (most recent call last)
<ipython-input-48-ebbae1182d79> in <module>
1 f = open("test.txt",mode = "w")
----> 2 print(f.read())
3 f.close()
UnsupportedOperation: not readable
在w模式下,如果文件不存在,则直接创建文件,如下:
f = open("test1.txt",mode = "w")
f.write("abcnd")#创建并写如新的内容
f.close()
f = open("test1.txt",mode = "r") #读取前面创建的内容
a = f.read()
print(a)
f.close()
结果为:
abcnd
在w模式下,如果文件存在,则会清空文件内容。
f = open("test.txt",mode = "r") #读取内容
a = f.read()
print(a)
f.close()
f = open("test.txt",mode = "w")
f.write("hahahaha")#创建并写如新的内容
f.close()
f = open("test.txt",mode = "r") #读取内容
a = f.read()
print(a)
f.close()
结果为:
1234567890
hahahaha
要是只写打开已经存在的文件,不做任何操作,文件里面的内容也会被清空。
f = open("test.txt",mode = "r") #读取内容
a = f.read()
print(a)
f.close()
f = open("test.txt",mode = "w")
f.close()
f = open("test.txt",mode = "r") #读取内容,内容为空。
a = f.read()
print(a)
f.close()
结果为:
hahahaha
f = open("test.txt",mode = "x") #文件已存在,报错
a = f.read()
print(a)
f.close()结果为:
---------------------------------------------------------------------------
FileExistsError Traceback (most recent call last)
<ipython-input-64-73ddf96bc2ce> in <module>
----> 1 f = open("test.txt",mode = "x") #文件已存在,报错
2 a = f.read()
3 print(a)
4 f.close()
FileExistsError: [Errno 17] File exists: 'test.txt'
上面的例子可以看到,x模式下打开一个已经存在的文件,会抛异常。而不存在,创建后,只能是只写模式打开。读的话出错。
f = open("test2.txt",mode = "x") #文件不存存在,创建
a = f.read()
print(a)
f.close()
结果为:
---------------------------------------------------------------------------
UnsupportedOperation Traceback (most recent call last)
<ipython-input-65-610a021c0d76> in <module>
1 f = open("test2.txt",mode = "x") #文件不可读
----> 2 a = f.read()
3 print(a)
4 f.close()
UnsupportedOperation: not readable
f = open("test4.txt",mode = "x") #文件不存存在,创建
f.write("abcdefg")
f.close()
f = open("test4.txt",mode = "r") #读取内容,内容为上面创建的内容。
a = f.read()
print(a)
f.close()
结果为:
abcdefg
在a模式下,如果文件存在的话,只写打开,然后在后面追加内容。如果读的话,会报错。
f = open("test1.txt",mode = "r")
a = f.read()
print(a)
f.close()
f = open("test1.txt",mode = "a")
f.write("hahahahha")
f.close()
f = open("test1.txt",mode = "r")
a = f.read()
print(a)
f.close()
结果为:
abcnd
abcndhahahahha
而在a模式下,如果文件不存在,则创建后,只写打开,追交内容。
f = open("test5.txt",mode = "a")
f.write("hahahahha")
f.close()
f = open("test5.txt",mode = "r")
a = f.read()
print(a)
f.close()
结果为:
hahahahha
由上面的例子可以看到,r是只读,而w、x、a都是只写,而且wxa都可以产生新文件,w不管文件存在与否,都会生成全新的内容的文件,a不管文件是否存在,都能在打开的文件尾部追加,而x必须要求文件事先不存在,自己创建一个新文件。
f = open("test5.txt",mode = "rb")
s = f.read()
print(type(s))#bytes
print(s)
f.close()
结果为:
<class 'bytes'>
b'hahahahhahahahahha'
二进制模式,字节流,它是将文件按照字节理解,与字符编码无关,二进制模式操作时,字节操作使用bytes类型。
f = open("test5.txt",mode = "rb")
s = f.read()
print(type(s))#bytes
print(s)
f.close()
#encode() 方法以 encoding 指定的编码格式编码字符串。
#用法:str.encode(encoding='UTF-8',errors='strict')
f = open("test5.txt",mode = "wb")
s = f.write("许鹏".encode())#返回了两个字符的字节数6
print(s)
f.close()
f = open("test5.txt",mode = "rb")
s = f.read()
print(type(s))#bytes
print(s)
f.close()
结果为:
<class 'bytes'>
b'123456'
6
<class 'bytes'>
b'\xe8\xae\xb8\xe9\xb9\x8f'
encode默认是按照utf-8进行编码的。也可以直接在前面加一个b。
print("许鹏程".encode())
"许鹏程".encode("utf-8")
结果为:
b'\xe8\xae\xb8\xe9\xb9\x8f\xe7\xa8\x8b'
b'\xe8\xae\xb8\xe9\xb9\x8f\xe7\xa8\x8b'
+是为r、w、a、x提供缺失的读写功能,但是,获取文件对象依旧按照rwax自己的特征。+是不能自己单独使用的,可以认为它是为前面的模式字符做增强功能的。
f = open("test1.txt",mode = "r+",encoding = "utf-8")
s= f.read()
print(s)
f.write("哈")
print(f.read())#文件指针在写到了最后,所以什么都读不出来。
f.close()
f = open("test1.txt",mode = "r",encoding = "utf-8")
s= f.read()
print(s)
f.close()
结果为:
abcndhahahahhabacbac哈哈
abcndhahahahhabacbac哈哈哈
f = open("test.txt",mode = "r",encoding = "utf-8")
s= f.read()
print(s)
f.close()
f = open("test.txt",mode = "r+",encoding = "utf-8")
f.write("哈")
print(f.read())
f.close()
f = open("test.txt",mode = "r",encoding = "utf-8")
s= f.read()
print(s)
f.close()结果为:
12345 12345 哈12345
f = open("test.txt",mode = "r",encoding = "utf-8")
s= f.read()
print(s)
f.close()
f = open("test.txt",mode = "w+",encoding = "utf-8")
f.write("哈")
print(f.read())
f.close()
f = open("test.txt",mode = "r",encoding = "utf-8")
s= f.read()
print(s)
f.close()结果为:
哈12345 哈
f = open("test.txt",mode = "r",encoding = "utf-8")
s= f.read()
print(s)
f.close()
f = open("test.txt",mode = "a+",encoding = "utf-8")
f.write("wangbadan")
print(f.read())#文件指针在最后,所以读不出来什么。
f.close()
f = open("test.txt",mode = "r",encoding = "utf-8")
s= f.read()
print(s)
f.close()
结果为:
哈
哈wangbadan
f = open("test.txt",mode = "r",encoding = "utf-8")
s= f.read()
print(s)
f.close()
f = open("test.txt",mode = "x+",encoding = "utf-8")
f.write("wangbadan")
print(f.read())#文件指针在最后,所以读不出来什么。
f.close()
f = open("test.txt",mode = "r",encoding = "utf-8")
s= f.read()
print(s)
f.close()
结果为:
哈wangbadanwangbadan
---------------------------------------------------------------------------
FileExistsError Traceback (most recent call last)
<ipython-input-141-f7b6cdaceca5> in <module>
4 f.close()
5
----> 6 f = open("test.txt",mode = "x+",encoding = "utf-8")
7 f.write("wangbadan")
8 print(f.read())#文件指针在最后,所以读不出来什么。
FileExistsError: [Errno 17] File exists: 'test.txt'
f = open("test7.txt",mode = "x+",encoding = "utf-8")#文件不存在,创建
f.write("wangbadan")
f.close()
f = open("test7.txt",mode = "r",encoding = "utf-8")
s= f.read()
print(s)
f.close()
结果为:
wangbadan
上面的例子,可以说明存在一个文件指针。
文件指针
mode = r的时候,指针的起始位置为0,mode = a的时候,文件指针在EOF结束的位置。
tell()显示指针当前的位置(应该特别注意很多时候在前面写入的话,是覆盖,这样改变了源文件,不好。),seek(offset,whence)则是移动文件指针的位置,offset表示偏移多少个字节。whence表示从哪里开始。很多时候中文用seek不太好。
在文本模式下,whence 0 是缺省值,表示从头开始,offset只能是正整数。比如seek(0)表示从开始位置向右偏移0,也就是还是起始位置,seek(2)也就是从开始位置向右偏移2个字符。这个用的最多。
whence1表示从当前位置,offset只接受0.
whence2表示从EOF开始,offset只接受0。
#有问题
f = open("test1.txt",mode = "r",encoding = "utf-8")
print(f.read())
f.close()
f = open("test1.txt",mode = "r+",encoding = "utf-8")
f.tell()#起始位置
print(f.read())#指针移动到最后
f.tell()#指针已经到结束位置了。
f.seek(0)#指针移动到起始位置
print(f.read())
f.seek(2,0)#文件从起始位置偏移2个字节
print(f.read())#读取从2个字节到最后的字节。
f.seek(2,1)#offset必须为0
f.seek(2,2)#offset必须为0
f.close()结果为:
#中文
f = open("test2.txt",mode = "r",encoding = "utf-8")
print(f.read())
f.close()
f = open("test2.txt",mode = "w+",encoding = "utf-8")
f.write("许鹏大坏蛋")
f.tell()#文件指针到最后了,
print(f.read())#指针移动到最后,读不到了
f.close()
f = open("test2.txt",mode = "r+",encoding = "utf-8")
print(f.read(3))#从头开始读三个字符
f.seek(3)#从开始位置向右移3个字节
print(f.tell())
print(f.read())
f.seek(3)#f.seek(3)
print(f.read())
f.close()
结果为:
许鹏大坏蛋
许鹏大
3
鹏大坏蛋
鹏大坏蛋
所以在文本模式下,支持从开始位置向后偏移的方式,whence为1表示从当前位置开始偏移,但是只支持偏移0,相当于原地不动,所以没什么用,whence为2表示从eof开始,只支持偏移0,相当于移动文件指针到EOF。
而在二进制模式下,whence 0 缺省值,表示从头开始,offset只能是正整数。
whence 1 表示从当前位置开始,offset可正可负。
whence2 表示从eof开始,offset可正可负。
f = open("test3.txt",mode = "r",encoding = "utf-8")
print(f.read())
f.close()
f = open("test3.txt",mode = "rb+")
f.tell()#文件指针在开始位置
print(f.read())#从头开始读
f.tell()#文件指针到最后了
f.write(b"abc")
f.seek(0)#起始
print(f.read())#从头开始读
f.seek(0)
f.seek(2,1)#从当前指针开始,向后2
print(f.read())
f.seek(-2,1)#从当前指针开始,向前2
print(f.read())
f.seek(2,2)#从eof开始,向后2
print(f.read())
f.seek(-2,2)#从eof开始,向前2
f.read()
print(f.read())
f.close()
结果为:
许鹏大坏蛋abc
b'\xef\xbb\xbf\xe8\xae\xb8\xe9\xb9\x8f\xe5\xa4\xa7\xe5\x9d\x8f\xe8\x9b\x8babc'
b'\xef\xbb\xbf\xe8\xae\xb8\xe9\xb9\x8f\xe5\xa4\xa7\xe5\x9d\x8f\xe8\x9b\x8babcabc'
b'\xbf\xe8\xae\xb8\xe9\xb9\x8f\xe5\xa4\xa7\xe5\x9d\x8f\xe8\x9b\x8babcabc'
b'bc'
b''
b''
所以,二进制模式支持任意起点的偏移,从头,从尾,从中间位置开始。向后seek可以超界,但是向前seek的时候,不能超界,否则会抛异常。
buffering:缓冲区
-1表示使用缺省大小的buffer,如果是二进制模式,使用io.DEFAULT_BUFFER_SIZE值,默认是4096或者8192.如果是文本模式,如果是终端设备,是行缓存方式,如果不是,则使用二进制模式下的策略。
- 0只在二进制模式使用,表示关buffer
- 1只在文本模式使用,表示使用行缓冲,意思就是见到换行符就flush.
- 大于1用于指定的buffer大小
buffer缓冲区
缓冲区是一个内存空间,一般来说就是一个FIFO队列,到缓冲区满了或者达到阈值,数据才会flush到磁盘。
flush()将缓冲区数据写入磁盘
close()关闭前会调用flush()
io.DEFAULT_BUFFER_SIZE缺省缓冲区大小,字节。
import io
f = open("test10.txt","w+b")#w+b表示二进制下的写读操作
print(io.DEFAULT_BUFFER_SIZE)
f.write("xpc.zs".encode())
f.seek(0)
f.write("abcd".encode())#覆盖了前面的xpc.
print(f.read())
f.flush()
f.seek(0)
print(f.read())
f.close()
结果为:
8192
b'zs'
b'abcdzs'
#有些问题import io
f = open("test11.txt",mode = "w+b",buffering= 5)#二进制模式下的写读操作
print(io.DEFAULT_BUFFER_SIZE)
f.write(b"xpc.zs")
print(f.read())
f.flush()
f.seek(0)
print(f.read())
f.close()
结果为:
8192
b''
b'xpc.zs'
文本模式下当buffering= 1的时候,使用的是行缓冲,设置成大于1的时候,一般都没有什么用处。因为在jupyter中,例子没有试验成功。但是在命令环境下可以。

上面的打开文件,然后写入,每次写入,都在jupyter中读,直到最后写入了一个换行符,jupyter才读出来,也就是换行的时候才刷新一次,写入磁盘。如下图。

buffering = 0这是一种特殊的二进制模式,不需要内存的buffering,可以看做是一个fifo的文件。在交互命令下,如下图,每写一个,不刷新,直接读都可以。写一个就可以读一个。
所以,buffering = -1,不管是t,还是b,缓冲大小都是默认值。
buffering = 0,b是关闭缓冲区,t不支持。
buffering = 1,b就是一个字节,t则是行缓冲,遇到换行符才flush.
buffering >1,b模式下表示行缓冲大小,缓冲区的值可以超过io.DEFAULT_BUFFER_SIZE,直到设定的值超出后才把缓冲区flush。t模式下,是io.DEFAULT_BUFFER_SIZE,flush完后把当前字符串也写入磁盘。
似乎看起来很麻烦,一般来说,记住以下几点就好了。
- 文本模式,一般都用默认缓冲区大小。
- 二进制模式下,是一个个字节的操作,可以指定buffer的大小
- 一般来说,默认缓冲区大小是个比较好的选择,除非明确知道,否则不调整它。
- 一般编程中,明确知道需要写磁盘了,都会手动调用一次flush,而不是等到自动flush或者close的时候。
encoding
编码代表的是怎么来理解二进制,是一个字节一个字节的来,还是几个字节几个字节的来。none表示使用缺省编码,这依赖于操作系统,window下默认是gbk,linux默认是utf-8,utf-8是Unicode的网络传输码,gbk和utf-8类似于映射关系,他们不是一一对应的。一个中文utf—8一般来说占用3个字节,但并不是绝对的。有时候会有4个。ASCII码常用的要记住。
其他参数
errors:什么样的 编码错误将被捕获,none和strict表示有编码错误将被抛valueerror错误,ignore表示忽略。
newline:文本模式中,换行的转换,可以为none,“,’“\r”,"\n","\r\n",读的时候none表示前面的都被转换为“\n”,"(空字符串)表示不会自动转换通用换行符,其他合法字符表示换行符就是指定字符,就会按照指定字符分行。
写时,none表示"\n"都会被替换为系统缺省行分隔符os.linesep,"\n"或”表示“\n”不替换,其他合法字符表示"\n"会被替换为指定的字符。
closefd:关闭文件描述符,true表示关闭它,false会在文件关闭后保持这个描述符。fileobj.fileno()查看。文件描述符有缓存,关闭了再看,还是那个文件描述符,文件描述符是唯一对应到文件的。
read()方法
read(siez = -1)表示读取的多少个字符或者字节,当里面的值为负数或者None时,则表示读到结尾。
f= open(file= "zss",encoding = "utf-8",mode = "w+")
f.write("xpc-xpc-xpc-xpc")
f.write("\n")
f.write("zss")
f.seek(0)
print(f.read(7))#读七个字符
f.seek(0)
print(f.read(-1))#读到结尾
f.seek(0)
print(f.read())#读到结尾
f.close()
结果为:
xpc-xpc
xpc-xpc-xpc-xpc
zss
xpc-xpc-xpc-xpc
zss
#二进制模式
f = open(file = "xpc",mode = "wb+")
f.write("许鹏xpcxpcxpc".encode())
f.seek(0)
print(f.read(6))
f.seek(0)
print(f.read(-1))
f.seek(0)
print(f.read())
f.close()
结果为:
b'\xe8\xae\xb8\xe9\xb9\x8f'
b'\xe8\xae\xb8\xe9\xb9\x8fxpcxpcxpc'
b'\xe8\xae\xb8\xe9\xb9\x8fxpcxpcxpc'
所以read()是将文件中的所有内容全部读取出来,这样有弊端,如果文件过大,很容易崩溃。而read(n)表示读取几个字节或字符,当需要再次读取的时候,指针会从当前位置继续去读,而不是从头开始,也就是要看文件指针的位置。
行读取
readline(size=-1)表示一行行读取文件内容,size设置一次能读取行内几个字符或字节。
readlines(hint=-1)读取所有行的列表,也就是将每一行形成一个元素,放入列表,返回的是个列表。指定hint则返回指定的行数。
f = open(file = "abc.txt",mode = "r") print(f.readline())#中间空了一行,是因为本身有换行符,然后print默认一个换行符,要去掉的话,可以用strip去掉一个。 print(f.readline().strip()) print(f.readline(5))#读取第三行的前5个字符 f.seek(0) print(f.readlines()) f.seek(0) print(f.readlines(2))#这里设置几都只有第一行? f.close() 结果为: xpc.zs 123444 asjaw ['xpc.zs\n', '123444\n', 'asjawdfoafma\n', "sfaw'pawkaw\\\n", "waw'fdawkf\\aw\n"] ['xpc.zs\n']
文件句柄还是一个可迭代对象,可以一行行迭代。
#按行迭代
f = open(file = "abc.txt",mode = "r")#返回可迭代对象
for i in f:
print(i.strip())
f.close()结果为:
xpc.zs 123444 asjawdfoafma sfaw'pawkaw\ waw'fdawkf\aw
write
write(s),是把字符串s写入到文件中并返回字符的个数。而writelines(lines),是将字符串列表写入文件中。写的时候要注意编码。
f = open(file = "abc.txt",mode = "w+") lines = ["abc","123\n","abc"]#提供换行符 f.writelines(lines) f.seek(0) print(f.read()) f.close()结果为:
abc123 abc
close
flush并关闭文件对象,如果文件已经关闭,再次关闭的话,没有任何效果。
其他的操作
seekable()是否可seek
readable()是否可读
writable()是否可写
closed是否已经关闭。
上下文管理
上下文管理是一种特殊的语法,当打开文件后,不需要自己去关闭,交给解释器去释放文件对象。它使用with……as关键字,同时,上下文管理的语句块并不会开启新的作用域,而当with语句块执行完的时候,会自动关闭文件对象。
with open("test.txt") as f:
f.write("abc")
结果为:
---------------------------------------------------------------------------
UnsupportedOperation Traceback (most recent call last)
<ipython-input-3-5e8b5c83866d> in <module>
1 with open("test.txt") as f:
----> 2 f.write("abc")
3 f.closed
UnsupportedOperation: not writable
f.closed
结果为:
true
上面的例子可以看到,使用上下文管理语法,当出现错误,抛异常后,文件没有关闭的情况下,解释器自动帮助我们关闭了。
它还有另外的一种写法。
f1 = open("test1.txt",mode = "r")
with f1:
f1.write("abc")
结果为:
---------------------------------------------------------------------------
UnsupportedOperation Traceback (most recent call last)
<ipython-input-5-40ef8ccf9294> in <module>
1 f1 = open("test1.txt",mode = "r")
2 with f1:
----> 3 f1.write("abc")
UnsupportedOperation: not writable
f1.closed
结果为:
true
所以,对于类似与文件对象的io对象,一般来说都需要在不使用的时候关闭,注销,以释放资源。io被打开的时候,会获得一个文件描述符,计算机资源是有限的,所以操作系统都会做出限制,就是为了保护计算机的资源不要被完全耗尽,计算资源是共享的,不是独占的。所以,一般情况下,除非特别明确的知道资源情况,否则不要提高资源的限制值来解决问题。
练习1:指定一个源文件,实现copy到目标目录。
with open("test",mode = "w+",encoding = "utf-8") as f:
lines = ["xpc","pxc","line"]
f.writelines("\n".join(lines))
f.seek(0)
print(f.read())
结果为:
xpc
pxc
line
def copyfile(src,dest):
with open(src) as f1:
with open(dest,"w") as f2:
f2.write(f1.read())
filename = "test1"
filename = "test2"
copyfile(filename1,filenae2)
结果为:
练习2,有一个文件,对其进行单词统计,不区分大小写,并显示单词重复最多的10个单词。
来源:https://www.cnblogs.com/xpc51/p/11727143.html