Facebook为了解决海量日志数据的分析而开发了hive,后来开源给了Apache基金会组织。 hive是一种用SQL语句来协助读写、管理存储在HDFS上的大数据集的数据仓库软件。
Hive 特点
1 是基于 Hadoop 的一个数据仓库工具;
2 Hive 最大的特点是将 Hive SQL语句转换为 MapReduce、Tez 或者 spark 等任务执行,使得大数据分析更容易。
3 可以将结构化的数据映射为一张数据库表,库和表的元数据信息一般存在关系型数据库上(比如MySQL);
4 底层数据是存储在 HDFS 上,hive本身并不提供数据的存储功能;
5 数据存储方面:他能够存储很大的数据集,并且对数据完整性、格式要求并不严格;
6 数据处理方面:不适用于实时计算和响应,使用于离线分析。
为什么使用Hive
1 直接使用 MapReduce、Tez、Spark学习成本太高,因为需要了解底层具体执行引擎的处理逻辑,而且需要一定的编码基础;而Hive提供直接使用类sql语言即可进行数据查询和处理的平台或接口,只要使用者熟悉sql语言即可;
2 MapReduce、Tez、Spark实现复杂查询逻辑开发难度大,因为需要自己写代码实现整个处理逻辑以及完成对数据处理过程的优化,而hive将很多数据统计逻辑封装成了可直接使用的窗口函数,且支持自定义窗口函数来进行扩展,而且hive有逻辑和物理优化器,会对执行逻辑进行自动优化。
Hive 架构
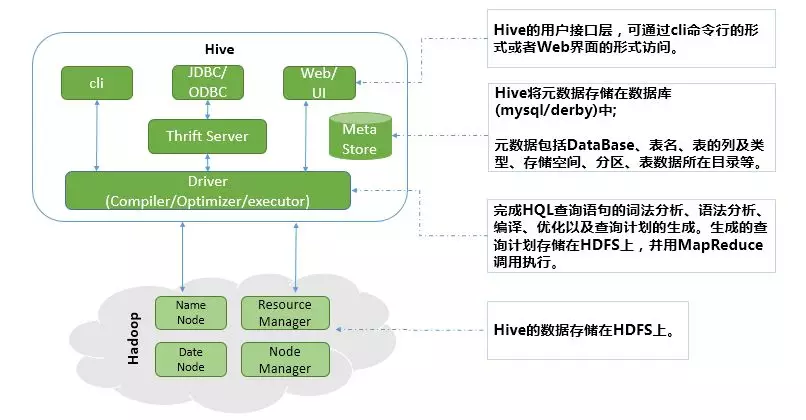
Hive的内部架构总共分为四大部分:
1 用户接口层(cli、JDBC/ODBC、Web UI)
(1) cli (Command Line Interface),shell终端命令行,通过命令行与hive进行交互;
(2) JDBC/ODBC,是 Hive 的基于 JDBC 操作提供的客户端,用户(开发员,运维人员)通过客户端连接至 Hive server 服务;
(3) Web UI,通过浏览器访问hive。
2 元数据存储系统
(1) 元数据 ,通俗的讲,就是存储在 Hive 中的数据的描述信息;
(2) Hive 中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和 外部表),表中数据所在的目录;
(3) Metastore 默认存在自带的 Derby 数据库或者我们自己创建的 MySQL 库中;
(4) Hive 和 MySQL或Derby 之间通过 MetaStore 服务交互。
3 Thrift Server-跨语言服务
Hive集成了Thrift Server,让用户可以使用多种不同语言来操作hive。
4 Driver(Compiler/Optimizer/Executor)
Driver完成HQL查询语句的词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS上,并由MapReduce调用执行。
整个过程的执行步骤如下:
(1) 解释器完成词法、语法和语义的分析以及中间代码生成,最终转换成抽象语法树;
(2) 编译器将语法树编译为逻辑执行计划;
(3) 逻辑层优化器对逻辑执行计划进行优化,由于Hive最终生成的MapReduce任务中,而Map阶段和Reduce阶段均由OperatorTree组成,所以大部分逻辑层优化器通过变换OperatorTree,合并操作符,达到减少MapReduce Job和减少shuffle数据量的目的;
(4) 物理层优化器进行MapReduce任务的变换,生成最终的物理执行计划;
(5) 执行器调用底层的运行框架执行最终的物理执行计划。
Hive 数据组织
1 Hive 的存储结构包括 数据库、表、视图、分区和表数据 等。数据库,表,分区等都对应HDFS上的一个目录。表数据对应 HDFS 对应目录下的文件。
2 Hive 中包含以下数据模型:
database :在 HDFS 中表现为${hive.metastore.warehouse.dir}或者指定的目录下的一个文件夹;
table :在 HDFS 中表现为某个 database 目录下一个文件夹;
external table :与 table 类似,在 HDFS 中也表现为某个 database 目录下一个文件夹;
partition :在 HDFS 中表现为 table 目录下的子目录;
bucket :在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散列之后的多个文件;
view :与传统数据库类似,只读,基于基本表创建。
3 Hive 中的表分为内部表、外部表、分区表和 Bucket 表。
内部表和外部表的区别:
1.内部表数据由Hive自身管理,外部表数据由HDFS管理;
2.删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
分区表和分桶表的区别:
1.分区表,Hive 数据表可以根据某些字段进行分区操作,细化数据管理,让部分查询更快;
2.分桶表:表和分区也可以进一步被划分为桶,分桶表中的数据是按照某些分桶字段进行 hash 散列形成的多个文件。
原文链接:
1. 大数据利器hive https://mp.weixin.qq.com/s/ZhW4n7hldadiFjCGHsz88A