Grid R-CNN
Grid R-CNN这篇论文是刚刚由商汤提出的,其主要是对faster R-CNN框架中定位框回归支路的更改,将以往通过回归方式实现proposal位置修正的方法,更改为通过全卷积网络来实现目标定位框的精确修正。借助卷积层生成的heatmap来确定初始的网格点,并通过这些网格点确定定位框的四条边。之所以做出这样的改变,作者阐述全卷积网络对位置更加具有敏感性,能够更好的实现更加精确的定位,文章中图一比较清楚的表示了这种改变。
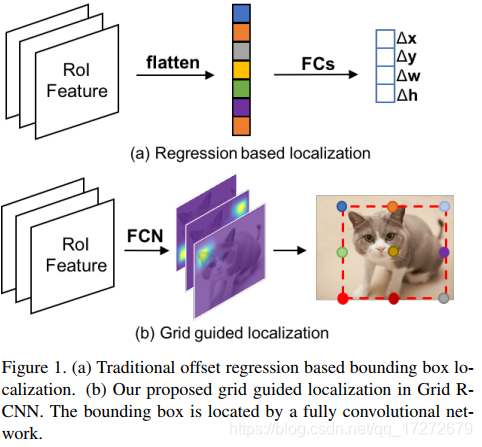
文章对上述过程分为了三个部分进行讲解:
(1)Grid Guided Localization
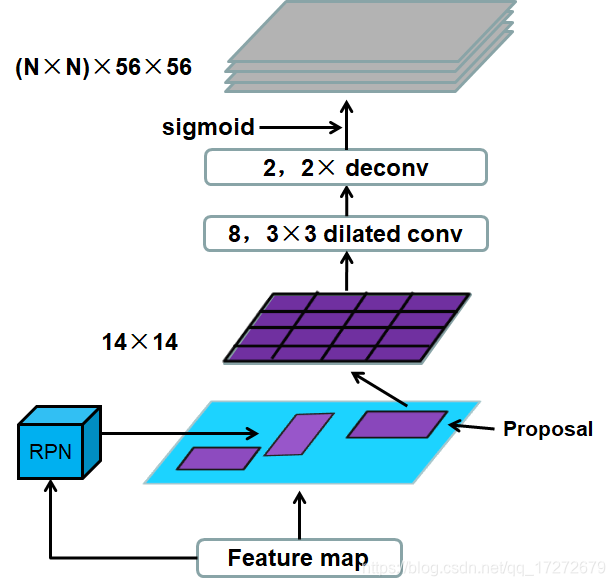
这一部分主要讲解了怎样利用RoIAlign之后的特征图来生成相应的grid points,在faster R-CNN 中RoIAlign之后对其应用7×7的金字塔池化生成固定长度的特征向量,继而通过后续的全连接层实现相应proposal的分类和位置的回归修正。而在本论文中则通过全卷积网络来生成固定分辨率的heatmap。其结构如下图:对每个proposal相应区域的feature map通过14×14的RoIAlign生成分辨率为14×14的feature map,对生成的feature map进行连续的8个扩张卷积,卷积核大小为3×3,之后连接两个2×的反卷积,所以每个proposal生成分辨率为56×56的heatmap,并且每个heatmap经过sigmoid得到最终的输出。在训练中每张heatmap都有相应监督map,以5个十字交叉的像素作为label点,通过二值交叉进行优化,在检测中则选取每个heatmap中最大值点作为相应网格点。
由于所生成的网格点都在heatmap中,所以还要将这些点映射回原始图像中,具体的映射公式为
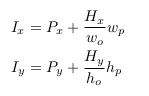
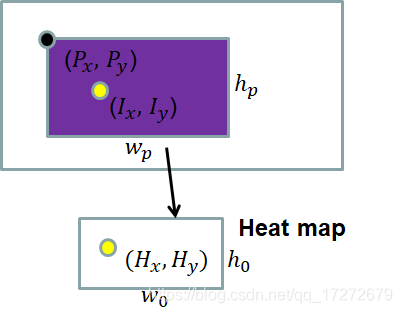
用下图表示更加清晰,上边大框表示输入图像,紫色框表示proposal,下边小框表示相应的heatmap,其中小框的黄色表示heatmap中最大值点(Hx,Hy),紫色框中黄色点表示映射回输入图像的原始点(Ix,Iy),黑点则是proposal的左上角坐标,通过上式可以看出是将heatmap中的坐标做了相应的缩放和平移。
通过上述过程即将N×N个点映射回了输入图像,那么由这些点怎样生成目标物体的坐标框呢,论文中的公式化描述为:
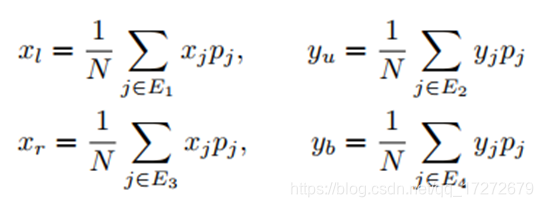
直观一些的表示如下图:以最上边的框边界yu为例,选择最上边的三个点计算其y坐标的加权和,即可得到相应上边界的坐标yu,权重为相应点的heatmap中的概率值。
(2)Grid Points Feature Fusion
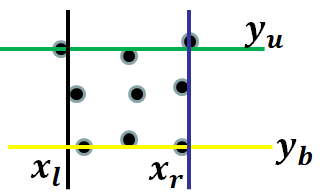
但是这样只利用一个heatmap来生成相应的网格点,还存在问题,假如某个网格点在背景区域,那么该区域获得的信息是不足以精确定位目标物体边界的,如下图中左上角的蓝色点,对于这样的网格点就需要融合周围的网格点对应的heatmap来对其进行校正。
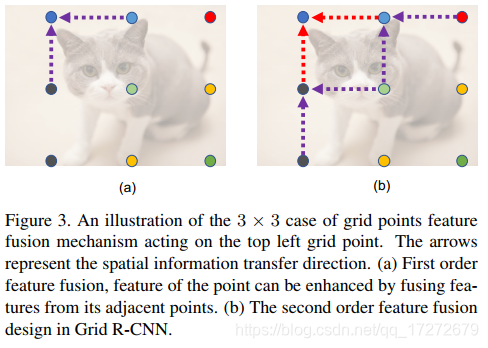
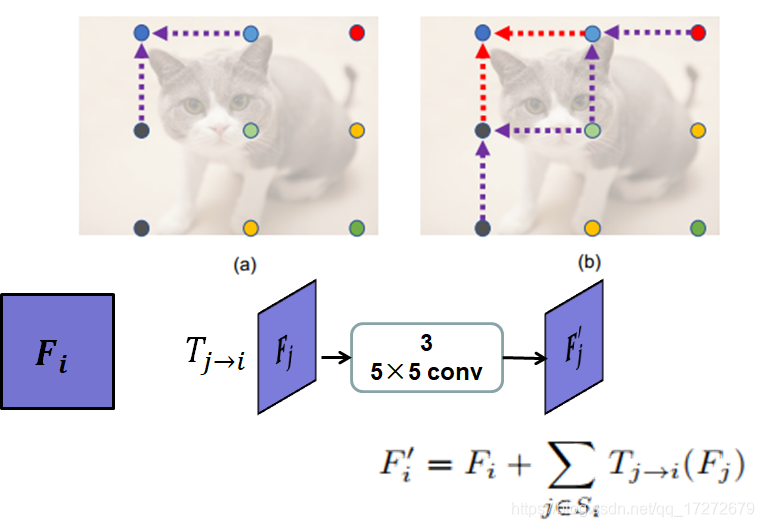
具体的融合方法如下图所示,以左上角的网格点为例,其对应的heatmap为Fi,和左上角单位距离的点称为源点,源点构成的集合设为Si,假设某个源点对应的heatmap为Fj,对Fj进行连续3次的卷积运算,卷积核大小为5×5,得到Fj',然后将源点集合中所有源点对应的heatmap进行上述运算之后与Fi相加得到融合之后的Fi',上述只是采用了单位距离的网格点,称为一阶融合,对所有点进行完一阶融合之后,再进行二阶融合,也即对目标点距离为两倍单位距离的点进行融合,如上图的右图所示。经过这样融合后的heatmap,再通过(1)部分的方法生成对应的边界框。从而提高边界框的定位精度。
(3)Extended Region Mapping
通过上述流程还不足以实现精确的对目标定位,因为有一些proposal覆盖区域比较小,其和groundtruth重合度较小,这使得在网给点的生成中难以对其进行有效的监督训练,如下图中初始生成的proposal即白色框和groundtruth标注框只有两个点重合。

很自然的可以想到能否通过直接扩大proposal来实现较大的重合呢?答案是否定的,如果增大proposal,那么单个proposal中会包含进较多的背景信息,同样不利于后续精确定位的进行。在这里作者通过改变heatmap和输入图像上点的映射关系来克服该问题,即还是利用同样大小的proposal来产生后续的heatmap,并选择出heatmap上相应的点,但是将该点映射回输入图像时,利用改进后的映射关系,如下图
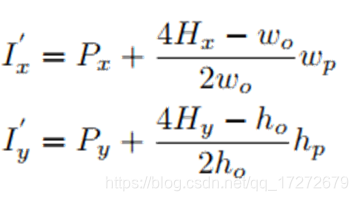
化简一下可得:
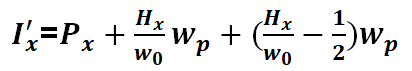
观察上式可知是在原来的映射关系上添加了修正项,即当heatmap中选定的grid point左侧时,映射回输入图像会向左侧移动,在右侧时会向右侧移动,对于y坐标是同样的映射关系。通过映射的修正,即可将相应的heatmap的映射区域加以扩展,如上图中的虚线白框,这样既解决了proposal与groundtruth重合过少难以训练问题,又避免了扩大proposal带来的背景混入的问题。
(4)实验结果
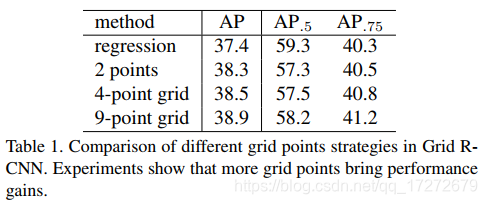
上述过程即为通过FCN实现目标定位的过程,看一下论文结果:下图显示通过选取不同的网格点数所带来的实验效果,可见随着点数的增加效果有进一步的提升。
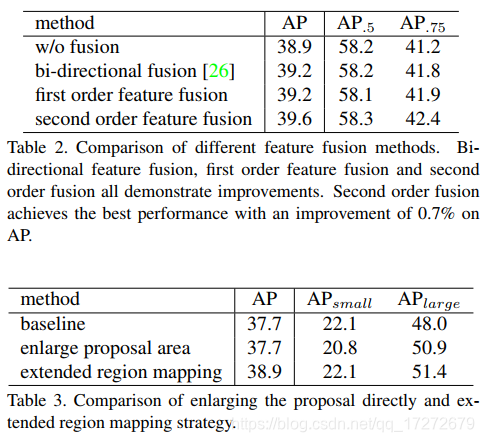
下图显示通过Grid Points Feature Fusion以及Extended Region Mapping所带来的实验结果的改变,可见两种改进方法的加入都带来了相应的提升。
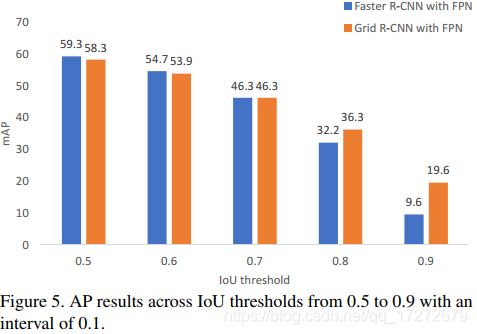
下图很有意思,显示了不同IOU标准下faster R-CNN和Grid R-CNN的输出结果,可以清晰的看出IOU标准越高反而相对效果越好,作者解释这表示Grid R-CNN主要是通过提高定位框精度实现检测效果提升的,但对这里存疑,按照Grid R-CNN的实现流程应该在各个IOU标准上都有所提升才对,作者也没有指出在RPN部分用以区分正负样本的IOU阈值为多少,若阈值为0.7还能对下图的结果有所解释。
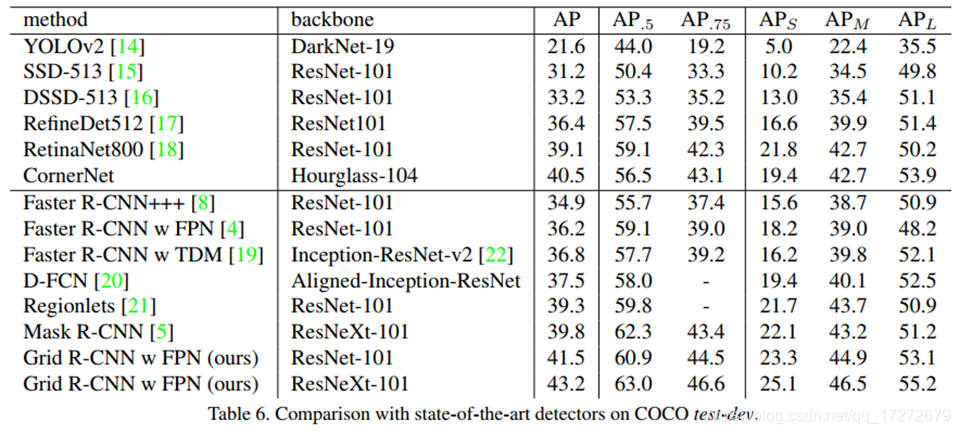
下图则展示了相对于其他检测框架的对比结果,效果还是比较明显的。
以上即为对Grid R-CNN的理解。
来源:CSDN
作者:游离在代码上的灵魂
链接:https://blog.csdn.net/qq_17272679/article/details/85011479