一、信息检索概述
1、信息过载
据百度百科介绍,信息过载是指社会信息超过了个人或系统所能接受、处理或有效利用的范围,并导致故障的状况。
信息过载有以下3个特点
2、信息过载的原因
随着互联网、传感器,以及各种数字化终端设备的普及,一个万物互联的世界正在成型。同时,随着数据呈现出爆炸式的指数级增长,数字化已经成为构建现代社会的基础力量,并推动着我们走向一个深度变革的时代。
据IDC发布《数据时代2025》的报告显示,全球每年产生的数据将从2018年的33ZB增长到175ZB,相当于每天产生491EB的数据。那么175ZB的数据到底有多大呢?1ZB相当于1.1万亿GB。如果把175ZB全部存在DVD光盘中,那么DVD叠加起来的高度将是地球和月球距离的23倍(月地最近距离约39.3万公里),或者绕地球222圈(一圈约为四万公里)。目前美国的平均网速为25Mb/秒,一个人要下载完这175ZB的数据,需要18亿年。
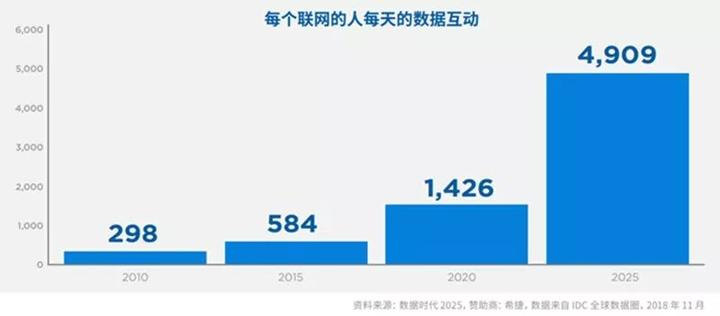
这些飞速增长的数据造成了数据过载的原因,所以我们处在一个数据时代,也是一个数据过载的时代
3、大数据的特点(IBM提出)
大数据的5V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
一、Volume:数据量大,包括采集、存储和计算的量都非常大。大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)。
二、Variety:种类和来源多样化。包括结构化、半结构化和非结构化数据,具体表现为网络日志、音频、视频、图片、地理位置信息等等,多类型的数据对数据的处理能力提出了更高的要求。
三、Value:数据价值密度相对较低,或者说是浪里淘沙却又弥足珍贵。随着互联网以及物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值,是大数据时代最需要解决的问题。
四、Velocity:数据增长速度快,处理速度也快,时效性要求高。比如搜索引擎要求几分钟前的新闻能够被用户查询到,个性化推荐算法尽可能要求实时完成推荐。这是大数据区别于传统数据挖掘的显著特征。
五、Veracity:数据的准确性和可信赖度,即数据的质量。
4、信息检索定义
信息资源总量呈爆炸式增长,在信息的海洋里获取想要的信息变得更加困难。为了解决信息过载的问题,无数科学家和工程师提出了很多天才的解决方案。其中最具代表性的就是分类目录和搜索引擎
分类目录:分类目录是将网站信息系统地整理,提供一个按类别编排的网站目录,在每类中排列着属于这一类别的网站站名、网站链接、内容提要、以及子分类目录,可以在分类目录中逐级浏览寻找相关网站,分类目录中往往还提供交叉索引,从而可以方便地在相关的目录之间跳转和浏览。例如新浪,搜狐,网易等,都是将不同来源的信息以一种整齐划一的形式整理、存储并呈现给客户,用户根据信息来源,信息类型,关键字等方式筛选网站内容。
搜索引擎:搜索引擎是指自动从因特网搜集信息,经过一定整理后,提供给用户进行查询的系统。例如:百度搜索、360搜索、搜狗搜索等
5、信息检索常用术语
信息检索领域有一些常用的术语,深刻理解这些术语对入门信息检索非常有必要
- 用户需求(User Need,简称UN)用户需要获取的信息。用文本描述,如查找与”elasticsearch“相关教程,有时也称为主题(Topic)
- 查询(Query)UN提交给检索系统时称为查询。如”elasticsearch教程“,对同一个UN,不同人不同时候可以构造出不同的Query,上述需求也可表示为”elasticsearch权威指南“
- 文档(Document)文档是信息检索的对象,文档不仅仅可以是文本,也可以是图片,视频,音频语音等多媒体文档
- 文档集(Crps)由若干文档构成的集合称为文档集合。
- 文档编号(DocumentID)文档ID是给文档集中的每个文档赋予的唯一标识符,通过文档ID来区分不同的文档,这样能够便于搜索引擎的内部处理
- 词条化(tokenization)词条化是将给定的字符序列拆分成一系列子序列的过程,拆分的每个子序列称为一个词条
- 输入:Elasticsearch is a distributed RESTful search engine built for the cloud.
- 输出:elasticsearch distributed restful search engine built cloud
- 词项(Term)词项是经过语言学预处理后归一化的词条。词项是索引的最小单位。
- 如下图:从纵向即文档纬度来看,每列代表一个文档包含的词项信息,如果doc1包含term1,doc2包含term2,而doc3都有
- 从横向即词项这个纬度来看,每行代表该词项在文档中的分布信息,比如term3只在doc3中出现一次,其他文档都不存在等。
-
doc1 doc2 doc3 term1 1 0 1 term2 0 1 1 term3 0 0 1
- 词项-文档关联矩阵(Incidence Matrix)词项-文档关联矩阵是表现词项和文档之间所具有的一种包含关系的概念模型
- 词项频率(Term Frequency)同一个单词在某个文档中出现的频率。比如,单词”elasticsearch“在某文档中出现了3次,那么该单词在该文档的词项频率就是3
- 文档频率(Document Frequency)出现某词项的文档的数目。比如,单词”elasticsearch“只出现在文档集合中的文档1和文档5中,那么该单词的文档频率就是2
- 倒排记录表(Postings List)倒排记录表用于记录出现过某个单词的所有文档的文档列表以及单词在该文档出现的位置信息,每条记录称为一个倒排项,通过倒排列表即可获知哪些文档包含哪些单词
- 倒排文件(Inverted File)倒排记录表在磁盘中的物理存储文件称为倒排文件。
6、信息检索系统
一个完整的信息检索系统的基本架构图如下所示。信息检索系统可以分为信息采集、信息整理、和用户查询3部分
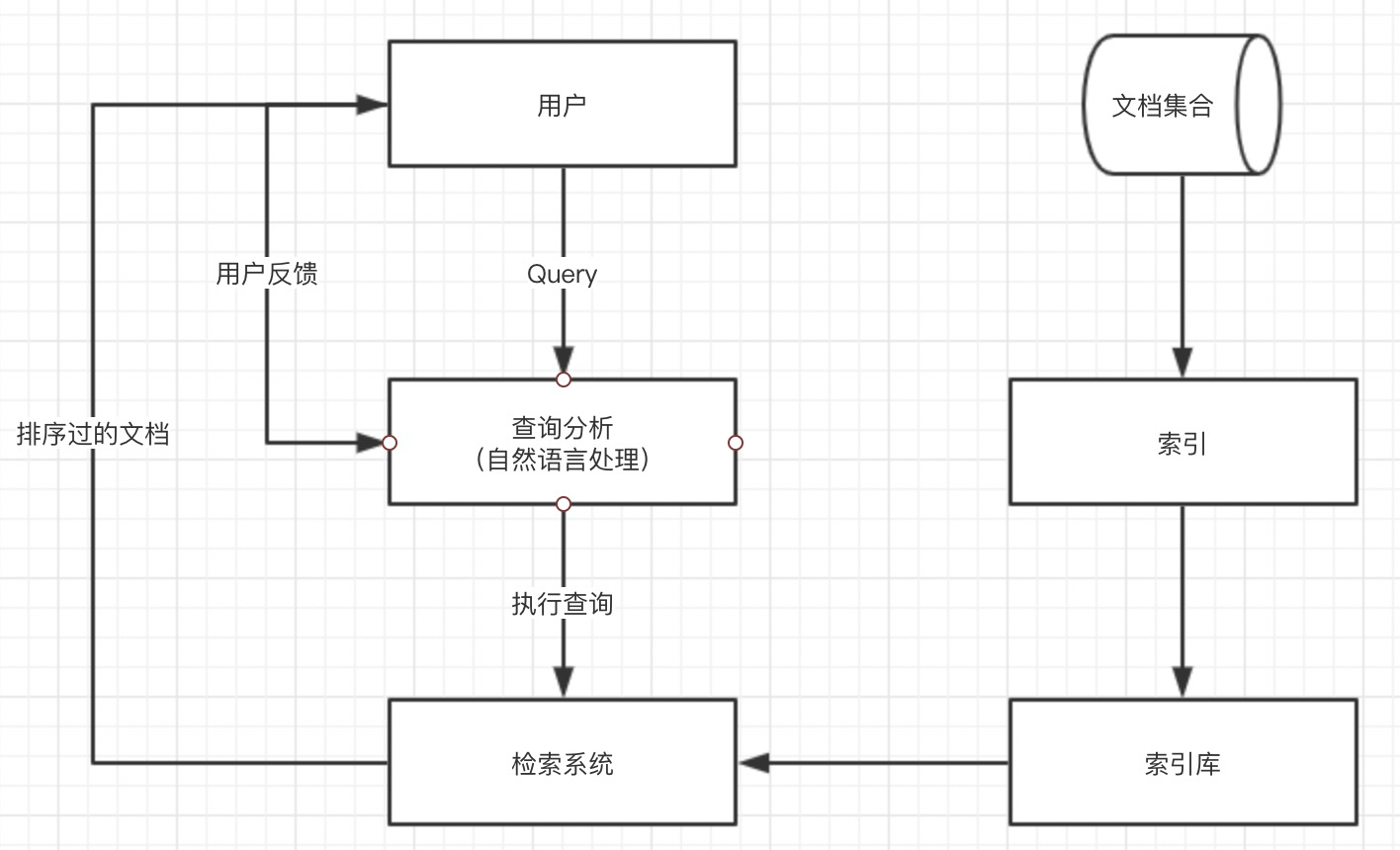
信息采集:信息采集基本都是通过网络爬虫自动完成的。
整理信息:信息检索系统整理信息的过程称为索引构建。
用户查询:用户想信息检索系统发出查询请求,信息检索系统接受查询并向用户返回检索到的文档