在日常运维工作中,对于系统和业务日志的处理尤为重要。今天,在这里分享一下自己部署的ELK(+Redis)-开源实时日志分析平台的记录过程(仅依据本人的实际操作为例说明,如有误述,敬请指出)~
概念介绍
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散在储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
通过我们需要对日志进行集中化管理,将所有机器上的日志信息收集、汇总到一起。完整的日志数据具有非常重要的作用:
1)信息查找。通过检索日志信息,定位相应的bug,找出解决方案。
2)服务诊断。通过对日志信息进行统计、分析,了解服务器的负荷和服务运行状态,找出耗时请求进行优化等等。
3)数据分析。如果是格式化的log,可以做进一步的数据分析,统计、聚合出有意义的信息,比如根据请求中的商品id,找出TOP10用户感兴趣商品。
开源实时日志分析ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成:
1)ElasticSearch是一个基于Lucene的开源分布式搜索服务器。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
在elasticsearch中,所有节点的数据是均等的。
2)Logstash是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
3)Kibana 是一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
为什么要用到ELK?
一般我们需要进行日志分析场景是:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
1)收集-能够采集多种来源的日志数据
2)传输-能够稳定的把日志数据传输到中央系统
3)存储-如何存储日志数据
4)分析-可以支持 UI 分析
5)警告-能够提供错误报告,监控机制
ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。目前主流的一种日志系统。
ELK工作原理展示图:

如上图:Logstash收集AppServer产生的Log,并存放到ElasticSearch集群中,而Kibana则从ES集群中查询数据生成图表,再返回给Browser。
Logstash工作原理:
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。

Input:输入数据到logstash。
一些常用的输入为:
file:从文件系统的文件中读取,类似于tial -f命令
syslog:在514端口上监听系统日志消息,并根据RFC3164标准进行解析
redis:从redis service中读取
beats:从filebeat中读取
Filters:数据中间处理,对数据进行操作。
一些常用的过滤器为:
grok:解析任意文本数据,Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。内置120多个解析语法。
mutate:对字段进行转换。例如对字段进行删除、替换、修改、重命名等。
drop:丢弃一部分events不进行处理。
clone:拷贝 event,这个过程中也可以添加或移除字段。
geoip:添加地理信息(为前台kibana图形化展示使用)
Outputs:outputs是logstash处理管道的最末端组件。一个event可以在处理过程中经过多重输出,但是一旦所有的outputs都执行结束,这个event也就完成生命周期。
一些常见的outputs为:
elasticsearch:可以高效的保存数据,并且能够方便和简单的进行查询。
file:将event数据保存到文件中。
graphite:将event数据发送到图形化组件中,一个很流行的开源存储图形化展示的组件。
Codecs:codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。
一些常见的codecs:
json:使用json格式对数据进行编码/解码。
multiline:将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息。
ELK整体方案=
ELK中的三个系统分别扮演不同的角色,组成了一个整体的解决方案。Logstash是一个ETL工具,负责从每台机器抓取日志数据,对数据进行格式转换和处理后,输出到Elasticsearch中存储。Elasticsearch是一个分布式搜索引擎和分析引擎,用于数据存储,可提供实时的数据查询。Kibana是一个数据可视化服务,根据用户的操作从Elasticsearch中查询数据,形成相应的分析结果,以图表的形式展现给用户。
ELK的安装很简单,可以按照"下载->修改配置文件->启动"方法分别部署三个系统,也可以使用docker来快速部署。具体的安装方法这里不详细介绍,下面来看一个常见的部署方案,如下图所示,部署思路是:
1)在每台生成日志文件的机器上,部署Logstash,作为Shipper的角色,负责从日志文件中提取数据,但是不做任何处理,直接将数据输出到Redis队列(list)中;
2)需要一台机器部署Logstash,作为Indexer的角色,负责从Redis中取出数据,对数据进行格式化和相关处理后,输出到Elasticsearch中存储;
3)部署Elasticsearch集群,当然取决于你的数据量了,数据量小的话可以使用单台服务,如果做集群的话,最好是有3个以上节点,同时还需要部署相关的监控插件;
4)部署Kibana服务,提供Web服务。

在前期部署阶段,主要工作是Logstash节点和Elasticsearch集群的部署,而在后期使用阶段,主要工作就是Elasticsearch集群的监控和使用Kibana来检索、分析日志数据了,当然也可以直接编写程序来消费Elasticsearch中的数据。
在上面的部署方案中,我们将Logstash分为Shipper和Indexer两种角色来完成不同的工作,中间通过Redis做数据管道,为什么要这样做?为什么不是直接在每台机器上使用Logstash提取数据、处理、存入Elasticsearch?
首先,采用这样的架构部署,有三点优势:第一,降低对日志所在机器的影响,这些机器上一般都部署着反向代理或应用服务,本身负载就很重了,所以尽可能的在这些机器上少做事;第二,如果有很多台机器需要做日志收集,那么让每台机器都向Elasticsearch持续写入数据,必然会对Elasticsearch造成压力,因此需要对数据进行缓冲,同时,这样的缓冲也可以一定程度的保护数据不丢失;第三,将日志数据的格式化与处理放到Indexer中统一做,可以在一处修改代码、部署,避免需要到多台机器上去修改配置。
其次,我们需要做的是将数据放入一个消息队列中进行缓冲,所以Redis只是其中一个选择,也可以是RabbitMQ、Kafka等等,在实际生产中,Redis与Kafka用的比较多。由于Redis集群一般都是通过key来做分片,无法对list类型做集群,在数据量大的时候必然不合适了,而Kafka天生就是分布式的消息队列系统。

1)配置nginx日志格式
首先需要将nginx日志格式规范化,便于做解析处理。在nginx.conf文件中设置:
log_format main '$remote_addr "$time_iso8601" "$request" $status $body_bytes_sent "$http_user_agent" "$http_referer" "$http_x_forwarded_for" "$request_time" "$upstream_response_time" "$http_cookie" "$http_Authorization" "$http_token"'; access_log /var/log/nginx/example.access.log main; 2)nginx日志–>>Logstash–>>消息队列
这部分是Logstash Shipper的工作,涉及input和output两种插件。input部分,由于需要提取的是日志文件,一般使用file插件,该插件常用的几个参数是:
path:指定日志文件路径。
type:指定一个名称,设置type后,可以在后面的filter和output中对不同的type做不同的处理,适用于需要消费多个日志文件的场景。
start_position:指定起始读取位置,“beginning”表示从文件头开始,“end”表示从文件尾开始(类似tail -f)。
sincedb_path:与Logstash的一个坑有关。通常Logstash会记录每个文件已经被读取到的位置,保存在sincedb中,如果Logstash重启,那么对于同一个文件,会继续从上次记录的位置开始读取。如果想重新从头读取文件,需要删除sincedb文件,sincedb_path则是指定了该文件的路径。为了方便,我们可以根据需要将其设置为“/dev/null”,即不保存位置信息。
input { file { type => "example_nginx_access" path => ["/var/log/nginx/example.access.log"] start_position => "beginning" sincedb_path => "/dev/null" } } output部分,将数据输出到消息队列,以redis为例,需要指定redis server和list key名称。另外,在测试阶段,可以使用stdout来查看输出信息。
# 输出到redis output { if [type] == "example_nginx_access" { redis { host => "127.0.0.1" port => "6379" data_type => "list" key => "logstash:example_nginx_access" } # stdout {codec => rubydebug} } } 3)消息队列–>>Logstash–>>Elasticsearch
这部分是Logstash Indexer的工作,涉及input、filter和output三种插件。在input部分,我们通过redis插件将数据从消息队列中取出来。在output部分,我们通过elasticsearch插件将数据写入Elasticsearch。
# 从redis输入数据 input { redis { host => "127.0.0.1" port => "6379" data_type => "list" key => "logstash:example_nginx_access" } } output { elasticsearch { index => "logstash-example-nginx-%{+YYYY.MM}" hosts => ["127.0.0.1:9200"] } } 这里,需要重点关注filter部分,下面列举几个常用的插件,实际使用中根据自身需求从官方文档中查找适合自己业务的插件并使用即可,当然也可以编写自己的插件。
grok:是Logstash最重要的一个插件,用于将非结构化的文本数据转化为结构化的数据。grok内部使用正则语法对文本数据进行匹配,为了降低使用复杂度,其提供了一组pattern,我们可以直接调用pattern而不需要自己写正则表达式,参考源码grok-patterns。grok解析文本的语法格式是%{SYNTAX:SEMANTIC},SYNTAX是pattern名称,SEMANTIC是需要生成的字段名称,使用工具Grok Debugger可以对解析语法进行调试。例如,在下面的配置中,我们先使用grok对输入的原始nginx日志信息(默认以message作为字段名)进行解析,并添加新的字段request_path_with_verb(该字段的值是verb和request_path的组合),然后对request_path字段做进一步解析。
kv:用于将某个字段的值进行分解,类似于编程语言中的字符串Split。在下面的配置中,我们将request_args字段值按照“&”进行分解,分解后的字段名称以“request_args_”作为前缀,并且丢弃重复的字段。
geoip:用于根据IP信息生成地理位置信息,默认使用自带的一份GeoLiteCity database,也可以自己更换为最新的数据库,但是需要数据格式需要遵循Maxmind的格式(参考GeoLite),似乎目前只能支持legacy database,数据类型必须是.dat。下载GeoLiteCity.dat.gz后解压, 并将文件路径配置到source中即可。
translate:用于检测某字段的值是否符合条件,如果符合条件则将其翻译成新的值,写入一个新的字段,匹配pattern可以通过YAML文件来配置。例如,在下面的配置中,我们对request_api字段翻译成更加易懂的文字描述。
filter { grok { match => {"message" => "%{IPORHOST:client_ip} \"%{TIMESTAMP_ISO8601:timestamp}\" \"%{WORD:verb} %{NOTSPACE:request_path} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response_status:int} %{NUMBER:response_body_bytes:int} \"%{DATA:user_agent}\" \"%{DATA:http_referer}\" \"%{NOTSPACE:http_x_forwarder_for}\" \"%{NUMBER:request_time:float}\" \"%{DATA:upstream_resopnse_time}\" \"%{DATA:http_cookie}\" \"%{DATA:http_authorization}\" \"%{DATA:http_token}\""} add_field => {"request_path_with_verb" => "%{verb} %{request_path}"} } grok { match => {"request_path" => "%{URIPATH:request_api}(?:\?%{NOTSPACE:request_args}|)"} add_field => {"request_annotation" => "%{request_api}"} } kv { prefix => "request_args_" field_split => "&" source => "request_args" allow_duplicate_values => false } geoip { source => "client_ip" database => "/home/elktest/geoip_data/GeoLiteCity.dat" } translate { field => request_path destination => request_annotation regex => true exact => true dictionary_path => "/home/elktest/api_annotation.yaml" override => true } } Elasticsearch
Elasticsearch承载了数据存储和查询的功能,其基础概念和使用方法可以参考另一篇博文Elasticsearch使用总结,这里主要介绍些实际生产中的问题和方法:
1)关于集群配置,重点关注三个参数:第一,discovery.zen.ping.unicast.hosts,Elasticsearch默认使用Zen Discovery来做节点发现机制,推荐使用unicast来做通信方式,在该配置项中列举出Master节点。第二,discovery.zen.minimum_master_nodes,该参数表示集群中可工作的具有Master节点资格的最小数量,默认值是1。为了提高集群的可用性,避免脑裂现象(所谓脑裂,就是同一个集群中的不同节点,对集群的状态有不一致的理解。),官方推荐设置为(N/2)+1,其中N是具有Master资格的节点的数量。第三,discovery.zen.ping_timeout,表示节点在发现过程中的等待时间,默认值是3秒,可以根据自身网络环境进行调整,一定程度上提供可用性。
discovery.zen.ping.unicast.hosts: ["master1", "master2", "master3"] discovery.zen.minimum_master_nodes: 2 discovery.zen.ping_timeout: 10 2)关于集群节点,第一,节点类型包括:候选Master节点、数据节点和Client节点。通过设置两个配置项node.master和node.data为true或false,来决定将一个节点分配为什么类型的节点。第二,尽量将候选Master节点和Data节点分离开,通常Data节点负载较重,需要考虑单独部署。
3)关于内存,Elasticsearch默认设置的内存是1GB,对于任何一个业务部署来说,这个都太小了。通过指定ES_HEAP_SIZE环境变量,可以修改其堆内存大小,服务进程在启动时候会读取这个变量,并相应的设置堆的大小。建议设置系统内存的一半给Elasticsearch,但是不要超过32GB。参考官方文档。
4)关于硬盘空间,Elasticsearch默认将数据存储在/var/lib/elasticsearch路径下,随着数据的增长,一定会出现硬盘空间不够用的情形,此时就需要给机器挂载新的硬盘,并将Elasticsearch的路径配置到新硬盘的路径下。通过“path.data”配置项来进行设置,比如“path.data: /data1,/var/lib/elasticsearch,/data”。需要注意的是,同一分片下的数据只能写入到一个路径下,因此还是需要合理的规划和监控硬盘的使用。
5)关于Index的划分和分片的个数,这个需要根据数据量来做权衡了,Index可以按时间划分,比如每月一个或者每天一个,在Logstash输出时进行配置,shard的数量也需要做好控制。
6)关于监控,笔者使用过head和marvel两个监控插件,head免费,功能相对有限,marvel现在需要收费了。另外,不要在数据节点开启监控插件。
Kibana
Kibana提供的是数据查询和显示的Web服务,有丰富的图表样板,能满足大部分的数据可视化需求,这也是很多人选择ELK的主要原因之一。UI的操作没有什么特别需要介绍的,经常使用就会熟练,这里主要介绍经常遇到的三个问题。
a)查询语法
在Kibana的Discover页面中,可以输入一个查询条件来查询所需的数据。查询条件的写法使用的是Elasticsearch的Query String语法,而不是Query DSL,参考官方文档query-string-syntax,这里列举其中部分常用的:
.单字段的全文检索,比如搜索args字段中包含first的文档,写作 args:first;
.单字段的精确检索,比如搜索args字段值为first的文档,写作 args: “first”;
.多个检索条件的组合,使用 NOT, AND 和 OR 来组合,注意必须是大写,比如 args:(“first” OR “second”) AND NOT agent: “third”;
.字段是否存在,exists:agent表示要求agent字段存在,missing:agent表示要求agent字段不存在;
.通配符:用 ? 表示单字母,* 表示任意个字母。
b)错误“Discover: Request Timeout after 30000ms”
这个错误经常发生在要查询的数据量比较大的情况下,此时Elasticsearch需要较长时间才能返回,导致Kibana发生Timeout报错。解决这个问题的方法,就是在Kibana的配置文件中修改elasticsearch.requestTimeout一项的值,然后重启Kibana服务即可,注意单位是ms。
c)疑惑“字符串被分解了”
经常碰到这样一个问题:为什么查询结果的字段值是正确的,可是做图表时却发现字段值被分解了,不是想要的结果?如下图所示的client_agent_info字段。

得到这样一个不正确结果的原因是使用了Analyzed字段来做图表分析,默认情况下Elasticsearch会对字符串数据进行分析,建立倒排索引,所以如果对这么一个字段进行terms聚合,必然会得到上面所示的错误结果了。那么应该怎么做才对?默认情况下,Elasticsearch还会创建一个相对应的没有被Analyzed的字段,即带“.raw”后缀的字段,在这样的字段上做聚合分析即可。
又会有很多人问这样的问题:为什么我的Elasticsearch没有自动创建带“.raw”后缀的字段?然而在Logstash中输出数据时,设置index名称前缀为“logstash-”就有了这个字段。这个问题的根源是Elasticsearch的dynamic template在捣鬼,dynamic temlate用于指导Elasticsearch如何为插入的数据自动建立Schema映射关系,默认情况下,Logstash会在Elasticsearch中建立一个名为“logstash”的模板,所有前缀为“logstash-”的index都会参照这个模板来建立映射关系,在该模板中申明了要为每个字符串数据建立一个额外的带“.raw”后缀的字段。可以向Elasticsearch来查询你的模板,使用API:GET http://localhost:9200/_template。
以上便是对ELK日志系统的总结介绍,还有一个重要的功能没有提到,就是如何将日志数据与自身产品业务的数据融合起来。举个例子,在nginx日志中,通常会包含API请求访问时携带的用户Token信息,由于Token是有时效性的,我们需要及时将这些Token转换成真实的用户信息存储下来。这样的需求通常有两种实现方式,一种是自己写一个Logstash filter,然后在Logstash处理数据时调用;另一种是将Logstash Indexer产生的数据再次输出到消息队列中,由我们自己的脚本程序从消息队列中取出数据,做相应的业务处理后,输出到Elasticsearch中。
ELK环境部署
(0)基础环境介绍
系统: Centos7.1
防火墙: 关闭
Sellinux: 关闭
机器环境: 两台
elk-node1: 192.168.1.160 #master机器
elk-node2:192.168.1.161 #slave机器
注明:
master-slave模式:
master收集到日志后,会把一部分数据碎片到salve上(随机的一部分数据);同时,master和slave又都会各自做副本,并把副本放到对方机器上,这样就保证了数据不会丢失。
如果master宕机了,那么客户端在日志采集配置中将elasticsearch主机指向改为slave,就可以保证ELK日志的正常采集和web展示。
==========================================================================
由于elk-node1和elk-node2两台是虚拟机,没有外网ip,所以访问需要通过宿主机进行代理转发实现。
有以下两种转发设置:(任选其一)
通过访问宿主机的19200,19201端口分别转发到elk-node1,elk-node2的9200端口
通过访问宿主机的15601端口转发到elk-node1的5601端口
宿主机:112.110.115.10(内网ip为192.168.1.7) (为了不让线上的真实ip暴露,这里任意给了一个ip做记录)
a)通过宿主机的haproxy服务进行代理转发,如下是宿主机上的代理配置:
[root@kvm-server conf]# pwd /usr/local/haproxy/conf [root@kvm-server conf]# cat haproxy.cfg .......... .......... listen node1-9200 0.0.0.0:19200 mode tcp option tcplog balance roundrobin server 192.168.1.160 192.168.1.160:9200 weight 1 check inter 1s rise 2 fall 2 listen node2-9200 0.0.0.0:19201 mode tcp option tcplog balance roundrobin server 192.168.1.161 192.168.1.161:9200 weight 1 check inter 1s rise 2 fall 2 listen node1-5601 0.0.0.0:15601 mode tcp option tcplog balance roundrobin server 192.168.1.160 192.168.1.160:5601 weight 1 check inter 1s rise 2 fall 2 重启haproxy服务 [root@kvm-server conf]# /etc/init.d/haproxy restart 设置宿主机防火墙 [root@kvm-server conf]# cat /etc/sysconfig/iptables ......... -A INPUT -p tcp -m state --state NEW -m tcp --dport 19200 -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 19201 -j ACCEPT -A INPUT -p tcp -m state --state NEW -m tcp --dport 15601 -j ACCEPT [root@kvm-server conf]# /etc/init.d/iptables restart b)通过宿主机的NAT端口转发实现 [root@kvm-server conf]# iptables -t nat -A PREROUTING -p tcp -m tcp --dport 19200 -j DNAT --to-destination 192.168.1.160:9200 [root@kvm-server conf]# iptables -t nat -A POSTROUTING -d 192.168.1.160/32 -p tcp -m tcp --sport 9200 -j SNAT --to-source 192.168.1.7 [root@kvm-server conf]# iptables -t filter -A INPUT -p tcp -m state --state NEW -m tcp --dport 19200 -j ACCEPT [root@kvm-server conf]# iptables -t nat -A PREROUTING -p tcp -m tcp --dport 19201 -j DNAT --to-destination 192.168.1.161:9200 [root@kvm-server conf]# iptables -t nat -A POSTROUTING -d 192.168.1.161/32 -p tcp -m tcp --sport 9200 -j SNAT --to-source 192.168.1.7 [root@kvm-server conf]# iptables -t filter -A INPUT -p tcp -m state --state NEW -m tcp --dport 19201 -j ACCEPT [root@kvm-server conf]# iptables -t nat -A PREROUTING -p tcp -m tcp --dport 15601 -j DNAT --to-destination 192.168.1.160:5601 [root@kvm-server conf]# iptables -t nat -A POSTROUTING -d 192.168.1.160/32 -p tcp -m tcp --sport 5601 -j SNAT --to-source 192.168.1.7 [root@kvm-server conf]# iptables -t filter -A INPUT -p tcp -m state --state NEW -m tcp --dport 15601 -j ACCEPT [root@kvm-server conf]# service iptables save [root@kvm-server conf]# service iptables restart 提醒一点:
nat端口转发设置成功后,/etc/sysconfig/iptables文件里要注释掉下面两行!不然nat转发会有问题!一般如上面在nat转发规则设置好并save和restart防火墙之后就会自动在/etc/sysconfig/iptables文件里删除掉下面两行内容了。
[root@kvm-server conf]# vim /etc/sysconfig/iptables .......... #-A INPUT -j REJECT --reject-with icmp-host-prohibited #-A FORWARD -j REJECT --reject-with icmp-host-prohibited [root@linux-node1 ~]# service iptables restart =============================================================
(1)Elasticsearch安装配置
基础环境安装(elk-node1和elk-node2同时操作)
1)下载并安装GPG Key
[root@elk-node1 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch 2)添加yum仓库
[root@elk-node1 ~]# vim /etc/yum.repos.d/elasticsearch.repo [elasticsearch-2.x] name=Elasticsearch repository for 2.x packages baseurl=http://packages.elastic.co/elasticsearch/2.x/centos gpgcheck=1 gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch enabled=1 3)安装elasticsearch
[root@elk-node1 ~]# yum install -y elasticsearch 4)安装相关测试软件
#提前先下载安装epel源:epel-release-latest-7.noarch.rpm,否则yum会报错:No Package..... [root@elk-node1 ~]# wget http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm [root@elk-node1 ~]# rpm -ivh epel-release-latest-7.noarch.rpm #安装Redis [root@elk-node1 ~]# yum install -y redis #安装Nginx [root@elk-node1 ~]# yum install -y nginx #安装java [root@elk-node1 ~]# yum install -y java 安装完java后,检测 [root@elk-node1 ~]# java -version openjdk version "1.8.0_102" OpenJDK Runtime Environment (build 1.8.0_102-b14) OpenJDK 64-Bit Server VM (build 25.102-b14, mixed mode) 配置部署(下面先进行elk-node1的配置)
1)配置修改配置文件
[root@elk-node1 ~]# mkdir -p /data/es-data [root@elk-node1 ~]# vim /etc/elasticsearch/elasticsearch.yml 【将里面内容情况,配置下面内容】
cluster.name: huanqiu # 组名(同一个组,组名必须一致) node.name: elk-node1 # 节点名称,建议和主机名一致 path.data: /data/es-data # 数据存放的路径 path.logs: /var/log/elasticsearch/ # 日志存放的路径 bootstrap.mlockall: true # 锁住内存,不被使用到交换分区去 network.host: 0.0.0.0 # 网络设置 http.port: 9200 # 端口 2)启动并查看
[root@elk-node1 ~]# chown -R elasticsearch.elasticsearch /data/
[root@elk-node1 ~]# systemctl start elasticsearch
[root@elk-node1 ~]# systemctl status elasticsearch
CGroup: /system.slice/elasticsearch.service
└─3005 /bin/java -Xms256m -Xmx1g -Djava.awt.headless=true -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSI…
注意:上面可以看出elasticsearch设置的内存最小256m,最大1g
===温馨提示: Elasticsearch启动出现"could not find java"=
yum方法安装elasticsearch, 使用"systemctl start elasticsearch"启动服务失败. "systemctl status elasticsearch"查看, 发现报错说could not find java 但是"java -version" 查看发现java已经安装了 这是因为elasticsearch在启动过程中, 引用的java路径找不到 解决办法: 在elasticsearch配置文件中定义java全路径 [root@elk-node01 ~]# java -version java version "1.8.0_131" Java(TM) SE Runtime Environment (build 1.8.0_131-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode [root@elk-node01 ~]# find / -name java /var/lib/alternatives/java /usr/share/swig/2.0.10/java /usr/java /usr/java/jdk1.8.0_131/bin/java /usr/java/jdk1.8.0_131/jre/bin/java /usr/bin/java /etc/pki/java /etc/pki/ca-trust/extracted/java /etc/alternatives/java [root@elk-node01 ~]# vim /etc/sysconfig/elasticsearch 添加JAVA_HOME环境变量的配置 JAVA_HOME=/usr/java/jdk1.8.0_131 [root@linux-node1 src]# netstat -antlp |egrep "9200|9300" tcp6 0 0 :::9200 :::* LISTEN 3005/java tcp6 0 0 :::9300 :::* LISTEN 3005/java 然后通过web访问(访问的浏览器最好用google浏览器)
http://112.110.115.10:19200/

3)通过命令的方式查看数据(在112.110.115.10宿主机或其他外网服务器上查看,如下)
[root@kvm-server src]# curl -i -XGET 'http://192.168.1.160:9200/_count?pretty' -d '{"query":{"match_all":{}}}' HTTP/1.1 200 OK Content-Type: application/json; charset=UTF-8 Content-Length: 95 { "count" : 0, "_shards" : { "total" : 0, "successful" : 0, "failed" : 0 } } 这样感觉用命令来查看,特别的不爽。
4)接下来安装插件,使用插件进行查看~ (下面两个插件要在elk-node1和elk-node2上都要安装)
4.1)安装head插件
a)插件安装方法一
[root@elk-node1 src]# /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head b)插件安装方法二
首先下载head插件,下载到/usr/loca/src目录下
下载地址:https://github.com/mobz/elasticsearch-head
======================================================
head插件包百度云盘下载:https://pan.baidu.com/s/1boBE0qj
提取密码:ifj7
[root@elk-node1 src]# unzip elasticsearch-head-master.zip [root@elk-node1 src]# ls elasticsearch-head-master elasticsearch-head-master.zip 在/usr/share/elasticsearch/plugins目录下创建head目录
然后将上面下载的elasticsearch-head-master.zip解压后的文件都移到/usr/share/elasticsearch/plugins/head下
接着重启elasticsearch服务即可!
[root@elk-node1 src]# cd /usr/share/elasticsearch/plugins/ [root@elk-node1 plugins]# mkdir head [root@elk-node1 plugins]# ls head [root@elk-node1 plugins]# cd head [root@elk-node1 head]# cp -r /usr/local/src/elasticsearch-head-master/* ./ [root@elk-node1 head]# pwd /usr/share/elasticsearch/plugins/head [root@elk-node1 head]# chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/plugins [root@elk-node1 head]# ll total 40 -rw-r--r--. 1 elasticsearch elasticsearch 104 Sep 28 01:57 elasticsearch-head.sublime-project -rw-r--r--. 1 elasticsearch elasticsearch 2171 Sep 28 01:57 Gruntfile.js -rw-r--r--. 1 elasticsearch elasticsearch 3482 Sep 28 01:57 grunt_fileSets.js -rw-r--r--. 1 elasticsearch elasticsearch 1085 Sep 28 01:57 index.html -rw-r--r--. 1 elasticsearch elasticsearch 559 Sep 28 01:57 LICENCE -rw-r--r--. 1 elasticsearch elasticsearch 795 Sep 28 01:57 package.json -rw-r--r--. 1 elasticsearch elasticsearch 100 Sep 28 01:57 plugin-descriptor.properties -rw-r--r--. 1 elasticsearch elasticsearch 5211 Sep 28 01:57 README.textile drwxr-xr-x. 5 elasticsearch elasticsearch 4096 Sep 28 01:57 _site drwxr-xr-x. 4 elasticsearch elasticsearch 29 Sep 28 01:57 src drwxr-xr-x. 4 elasticsearch elasticsearch 66 Sep 28 01:57 test [root@elk-node1 _site]# systemctl restart elasticsearch =========================================================================
插件访问(最好提前将elk-node2节点的配置和插件都安装后,再来进行访问和数据插入测试)
http://112.110.115.10:19200/_plugin/head/

先插入数据实例,测试下
如下:打开”复合查询“,在POST选项下,任意输入如/index-demo/test,然后在下面输入数据(注意内容之间换行的逗号不要漏掉);
数据输入好之后(如下输入wangshibo;hello world内容),下面点击”验证JSON“->”提交请求“,提交成功后,观察右栏里出现的信息:有index,type,version等信息,failed:0(成功消息)

再查看测试实例,如下:
“复合查询"下,选择GET选项,在/index-demo/test/后面输入上面POST结果中的id号,不输入内容,即{}括号里为空!
然后点击”验证JSON“->“提交请求”,观察右栏内就有了上面插入的数据了(即wangshibo,hello world)

打开"基本查询”,查看下数据,如下,即可查询到上面插入的数据:

打开“数据浏览”,也能查看到插入的数据:

如下:一定要提前在elk-node2节点上也完成配置(配置内容在下面提到),否则上面插入数据后,集群状态会呈现黄色yellow状态,elk-node2完成配置加入到集群里后就会恢复到正常的绿色状态。

4.2)安装kopf监控插件
a)监控插件安装方法一
[root@elk-node1 src]# /usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf
b)监控插件安装方法二
首先下载监控插件kopf,下载到/usr/loca/src目录下
下载地址:https://github.com/lmenezes/elasticsearch-kopf
====================================================
kopf插件包百度云盘下载:https://pan.baidu.com/s/1qYixSL2
提取密码:ya4t
[root@elk-node1 src]# unzip elasticsearch-kopf-master.zip [root@elk-node1 src]# ls elasticsearch-kopf-master elasticsearch-kopf-master.zip 在/usr/share/elasticsearch/plugins目录下创建kopf目录
然后将上面下载的elasticsearch-kopf-master.zip解压后的文件都移到/usr/share/elasticsearch/plugins/kopf下
接着重启elasticsearch服务即可!
[root@elk-node1 src]# cd /usr/share/elasticsearch/plugins/ [root@elk-node1 plugins]# mkdir kopf [root@elk-node1 plugins]# cd kopf [root@elk-node1 kopf]# cp -r /usr/local/src/elasticsearch-kopf-master/* ./ [root@elk-node1 kopf]# pwd /usr/share/elasticsearch/plugins/kopf [root@elk-node1 kopf]# chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/plugins [root@elk-node1 kopf]# ll total 40 -rw-r--r--. 1 elasticsearch elasticsearch 237 Sep 28 16:28 CHANGELOG.md drwxr-xr-x. 2 elasticsearch elasticsearch 22 Sep 28 16:28 dataset drwxr-xr-x. 2 elasticsearch elasticsearch 73 Sep 28 16:28 docker -rw-r--r--. 1 elasticsearch elasticsearch 4315 Sep 28 16:28 Gruntfile.js drwxr-xr-x. 2 elasticsearch elasticsearch 4096 Sep 28 16:28 imgs -rw-r--r--. 1 elasticsearch elasticsearch 1083 Sep 28 16:28 LICENSE -rw-r--r--. 1 elasticsearch elasticsearch 1276 Sep 28 16:28 package.json -rw-r--r--. 1 elasticsearch elasticsearch 102 Sep 28 16:28 plugin-descriptor.properties -rw-r--r--. 1 elasticsearch elasticsearch 3165 Sep 28 16:28 README.md drwxr-xr-x. 6 elasticsearch elasticsearch 4096 Sep 28 16:28 _site drwxr-xr-x. 4 elasticsearch elasticsearch 27 Sep 28 16:28 src drwxr-xr-x. 4 elasticsearch elasticsearch 4096 Sep 28 16:28 tests [root@elk-node1 _site]# systemctl restart elasticsearch ============================================================================
访问插件:(如下,同样要提前安装好elk-node2节点上的插件,否则访问时会出现集群节点为黄色的yellow告警状态)
http://112.110.115.10:19200/_plugin/kopf/#!/cluster

下面进行节点elk-node2的配置 (如上的两个插件也在elk-node2上同样安装)
注释:其实两个的安装配置基本上是一样的。
[root@elk-node2 src]# mkdir -p /data/es-data [root@elk-node2 ~]# cat /etc/elasticsearch/elasticsearch.yml cluster.name: huanqiu node.name: elk-node2 path.data: /data/es-data path.logs: /var/log/elasticsearch/ bootstrap.mlockall: true network.host: 0.0.0.0 http.port: 9200 discovery.zen.ping.multicast.enabled: false discovery.zen.ping.unicast.hosts: ["192.168.1.160", "192.168.1.161"] 修改权限配置
[root@elk-node2 src]# chown -R elasticsearch.elasticsearch /data/ 启动服务
[root@elk-node2 src]# systemctl start elasticsearch [root@elk-node2 src]# systemctl status elasticsearch ● elasticsearch.service - Elasticsearch Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2016-09-28 16:49:41 CST; 1 weeks 3 days ago Docs: http://www.elastic.co Process: 17798 ExecStartPre=/usr/share/elasticsearch/bin/elasticsearch-systemd-pre-exec (code=exited, status=0/SUCCESS) Main PID: 17800 (java) CGroup: /system.slice/elasticsearch.service └─17800 /bin/java -Xms256m -Xmx1g -Djava.awt.headless=true -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFra... Oct 09 13:42:22 elk-node2 elasticsearch[17800]: [2016-10-09 13:42:22,295][WARN ][transport ] [elk-node2] Transport res...943817] Oct 09 13:42:23 elk-node2 elasticsearch[17800]: [2016-10-09 13:42:23,111][WARN ][transport ] [elk-node2] Transport res...943846] …
…
查看端口
[root@elk-node2 src]# netstat -antlp|egrep "9200|9300" tcp6 0 0 :::9200 :::* LISTEN 2928/java tcp6 0 0 :::9300 :::* LISTEN 2928/java tcp6 0 0 127.0.0.1:48200 127.0.0.1:9300 TIME_WAIT - tcp6 0 0 ::1:41892 ::1:9300 TIME_WAIT - 通过命令的方式查看elk-node2数据(在112.110.115.10宿主机或其他外网服务器上查看,如下)
[root@kvm-server ~]# curl -i -XGET 'http://192.168.1.161:9200/_count?pretty' -d '{"query":{"match_all":{}}}' HTTP/1.1 200 OK Content-Type: application/json; charset=UTF-8 Content-Length: 95 { "count" : 1, "_shards" : { "total" : 5, "successful" : 5, "failed" : 0 } 然后通过web访问elk-node2
http://112.110.115.10:19201/

访问两个插件:
http://112.110.115.10:19201/_plugin/head/
http://112.110.115.10:19201/_plugin/kopf/#!/cluster


(2)Logstash安装配置(这个在客户机上是要安装的。elk-node1和elk-node2都安装)
基础环境安装(客户端安装logstash,收集到的数据写入到elasticsearch里,就可以登陆logstash界面查看到了)
1)下载并安装GPG Key
[root@elk-node1 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch 2)添加yum仓库
[root@hadoop-node1 ~]# vim /etc/yum.repos.d/logstash.repo [logstash-2.1] name=Logstash repository for 2.1.x packages baseurl=http://packages.elastic.co/logstash/2.1/centos gpgcheck=1 gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch enabled=1 3)安装logstash
[root@elk-node1 ~]# yum install -y logstash 4)logstash启动
[root@elk-node1 ~]# systemctl start elasticsearch [root@elk-node1 ~]# systemctl status elasticsearch ● elasticsearch.service - Elasticsearch Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; disabled; vendor preset: disabled) Active: active (running) since Mon 2016-11-07 18:33:28 CST; 3 days ago Docs: http://www.elastic.co Main PID: 8275 (java) CGroup: /system.slice/elasticsearch.service └─8275 /bin/java -Xms256m -Xmx1g -Djava.awt.headless=true -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFrac... …
…
数据的测试
1)基本的输入输出
[root@elk-node1 ~]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { stdout{} }' Settings: Default filter workers: 1 Logstash startup completed hello #输入这个 2016-11-11T06:41:07.690Z elk-node1 hello #输出这个 wangshibo #输入这个 2016-11-11T06:41:10.608Z elk-node1 wangshibo #输出这个 2)使用rubydebug详细输出
[root@elk-node1 ~]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { stdout{ codec => rubydebug} }' Settings: Default filter workers: 1 Logstash startup completed hello #输入这个 { #输出下面信息 "message" => "hello", "@version" => "1", "@timestamp" => "2016-11-11T06:44:06.711Z", "host" => "elk-node1" } wangshibo #输入这个 { #输出下面信息 "message" => "wangshibo", "@version" => "1", "@timestamp" => "2016-11-11T06:44:11.270Z", "host" => "elk-node1" } - 把内容写到elasticsearch中
[root@elk-node1 ~]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["192.168.1.160:9200"]} }' Settings: Default filter workers: 1 Logstash startup completed #输入下面的测试数据 123456 wangshibo huanqiu hahaha 使用rubydebug和写到elasticsearch中的区别:其实就在于后面标准输出的区别,前者使用codec;后者使用elasticsearch
写到elasticsearch中在logstash中查看,如下图:
注意:
master收集到日志后,会把一部分数据碎片到salve上(随机的一部分数据),master和slave又都会各自做副本,并把副本放到对方机器上,这样就保证了数据不会丢失。
如下,master收集到的数据放到了自己的第1,3分片上,其他的放到了slave的第0,2,4分片上。



4)即写到elasticsearch中又写在文件中一份
[root@elk-node1 ~]# /opt/logstash/bin/logstash -e 'input { stdin{} } output { elasticsearch { hosts => ["192.168.1.160:9200"]} stdout{ codec => rubydebug}}' Settings: Default filter workers: 1 Logstash startup completed huanqiupc { "message" => "huanqiupc", "@version" => "1", "@timestamp" => "2016-11-11T07:27:42.012Z", "host" => "elk-node1" } wangshiboqun { "message" => "wangshiboqun", "@version" => "1", "@timestamp" => "2016-11-11T07:27:55.396Z", "host" => "elk-node1" } 以上文本可以长期保留、操作简单、压缩比大。下面登陆elasticsearch界面中查看;

logstash的配置和文件的编写
1)logstash的配置
简单的配置方式:
[root@elk-node1 ~]# vim /etc/logstash/conf.d/01-logstash.conf
input { stdin { } }
output {
elasticsearch { hosts => [“192.168.1.160:9200”]}
stdout { codec => rubydebug }
}
它的执行:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f /etc/logstash/conf.d/01-logstash.conf
Settings: Default filter workers: 1
Logstash startup completed
beijing #输入内容
{ #输出下面信息
“message” => “beijing”,
“@version” => “1”,
“@timestamp” => “2016-11-11T07:41:48.401Z”,
“host” => “elk-node1”
}
===============================================================
参考内容:
https://www.elastic.co/guide/en/logstash/current/configuration.html
https://www.elastic.co/guide/en/logstash/current/configuration-file-structure.html

2)收集系统日志
[root@elk-node1 ~]# vim file.conf input { file { path => "/var/log/messages" type => "system" start_position => "beginning" } } output { elasticsearch { hosts => ["192.168.1.160:9200"] index => "system-%{+YYYY.MM.dd}" } } 执行上面日志信息的收集,如下,这个命令会一直在执行中,表示日志在监控收集中;如果中断,就表示日志不在收集!所以需要放在后台执行~
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f file.conf & 登陆elasticsearch界面,查看本机系统日志的信息:



参考内容:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html
3)收集java日志,其中包含上面讲到的日志收集
[root@elk-node1 ~]# vim file.conf
input {
file {
path => “/var/log/messages”
type => “system”
start_position => “beginning”
}
}
input {
file {
path => “/var/log/elasticsearch/huanqiu.log”
type => “es-error”
start_position => “beginning”
}
}
output {
if [type] == "system"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "system-%{+YYYY.MM.dd}" } } if [type] == "es-error"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "es-error-%{+YYYY.MM.dd}" } } }
注意:
如果你的日志中有type字段 那你就不能在conf文件中使用type
执行如下命令收集:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f file.conf &
登陆elasticsearch界面,查看数据:


参考内容:
https://www.elastic.co/guide/en/logstash/current/event-dependent-configuration.html
有个问题:
每个报错都给收集成一行了,不是按照一个报错,一个事件模块收集的。
下面将行换成事件的方式展示:
[root@elk-node1 ~]# vim multiline.conf input { stdin { codec => multiline { pattern => "^\[" negate => true what => "previous" } } } output { stdout { codec => "rubydebug" } } 执行命令:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f multiline.conf Settings: Default filter workers: 1 Logstash startup completed 123 456 [123 { "@timestamp" => "2016-11-11T09:28:56.824Z", "message" => "123\n456", "@version" => "1", "tags" => [ [0] "multiline" ], "host" => "elk-node1" } 123] [456] { "@timestamp" => "2016-11-11T09:29:09.043Z", "message" => "[123\n123]", "@version" => "1", "tags" => [ [0] "multiline" ], "host" => "elk-node1" } 在没有遇到[的时候,系统不会收集,只有遇见[的时候,才算是一个事件,才收集起来。
参考内容
https://www.elastic.co/guide/en/logstash/current/plugins-codecs-multiline.html
(3)Kibana安装配置
1)kibana的安装:
[root@elk-node1 ~]# cd /usr/local/src [root@elk-node1 src]# wget https://download.elastic.co/kibana/kibana/kibana-4.3.1-linux-x64.tar.gz [root@elk-node1 src]# tar zxf kibana-4.3.1-linux-x64.tar.gz [root@elk-node1 src]# mv kibana-4.3.1-linux-x64 /usr/local/ [root@elk-node1 src]# ln -s /usr/local/kibana-4.3.1-linux-x64/ /usr/local/kibana 2)修改配置文件:
[root@elk-node1 config]# pwd /usr/local/kibana/config [root@elk-node1 config]# cp kibana.yml kibana.yml.bak [root@elk-node1 config]# vim kibana.yml server.port: 5601 server.host: "0.0.0.0" elasticsearch.url: "http://192.168.1.160:9200" kibana.index: ".kibana" #注意这个.Kibana索引用来存储数据,千万不要删除了它。它是将es数据通过kibana进行web展示的关键。这个配置后,在es的web界面里就会看到这个.kibana索引。 因为他一直运行在前台,要么选择开一个窗口,要么选择使用screen。 安装并使用screen启动kibana: [root@elk-node1 ~]# yum -y install screen
[root@elk-node1 ~]# screen #这样就另开启了一个终端窗口
[root@elk-node1 ~]# /usr/local/kibana/bin/kibana
log [18:23:19.867] [info][status][plugin:kibana] Status changed from uninitialized to green - Ready
log [18:23:19.911] [info][status][plugin:elasticsearch] Status changed from uninitialized to yellow - Waiting for Elasticsearch
log [18:23:19.941] [info][status][plugin:kbn_vislib_vis_types] Status changed from uninitialized to green - Ready
log [18:23:19.953] [info][status][plugin:markdown_vis] Status changed from uninitialized to green - Ready
log [18:23:19.963] [info][status][plugin:metric_vis] Status changed from uninitialized to green - Ready
log [18:23:19.995] [info][status][plugin:spyModes] Status changed from uninitialized to green - Ready
log [18:23:20.004] [info][status][plugin:statusPage] Status changed from uninitialized to green - Ready
log [18:23:20.010] [info][status][plugin:table_vis] Status changed from uninitialized to green - Ready然后按ctrl+a+d组合键,这样在上面另启的screen屏里启动的kibana服务就一直运行在前台了…
[root@elk-node1 ~]# screen -ls There is a screen on: 15041.pts-0.elk-node1 (Detached) 1 Socket in /var/run/screen/S-root. (3)访问kibana:http://112.110.115.10:15601/
如下,如果是添加上面设置的java日志收集信息,则在下面填写es-error*;如果是添加上面设置的系统日志信息system*,以此类型(可以从logstash界面看到日志收集项)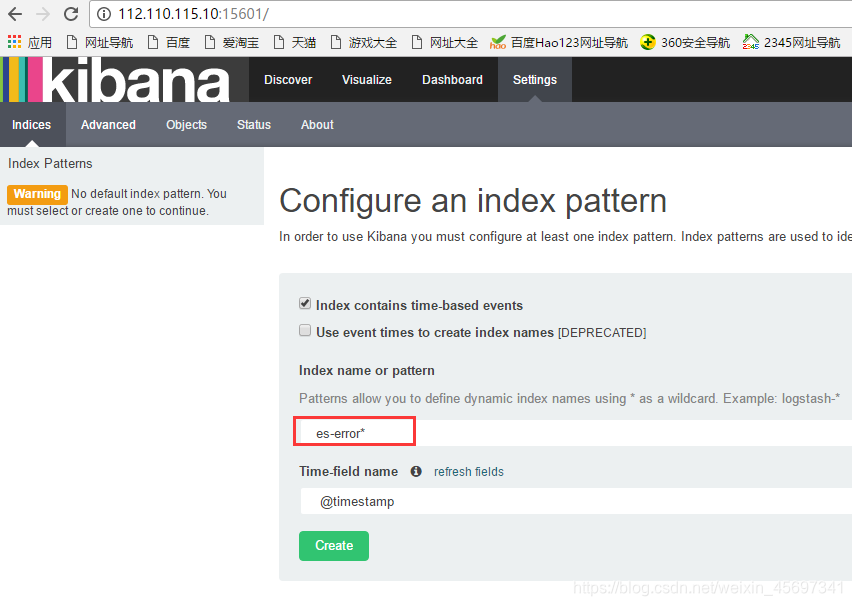
然后点击上面的Discover,在Discover中查看:

查看日志登陆,需要点击“Discover”–>“message”,点击它后面的“add”
注意:
需要右边查看日志内容时带什么属性,就在左边点击相应属性后面的“add”
如下图,添加了message和path的属性:


这样,右边显示的日志内容的属性就带了message和path

点击右边日志内容属性后面隐藏的<<,就可将内容向前缩进


添加新的日志采集项,点击Settings->+Add New,比如添加system系统日志。注意后面的*不要忘了。





删除kibana里的日志采集项,如下,点击删除图标即可。

如果打开kibana查看日志,发现没有日志内容,出现“No results found”,如下图所示,这说明要查看的日志在当前时间没有日志信息输出,可以点击右上角的时间钟来调试日志信息的查看。




4)收集nginx的访问日志
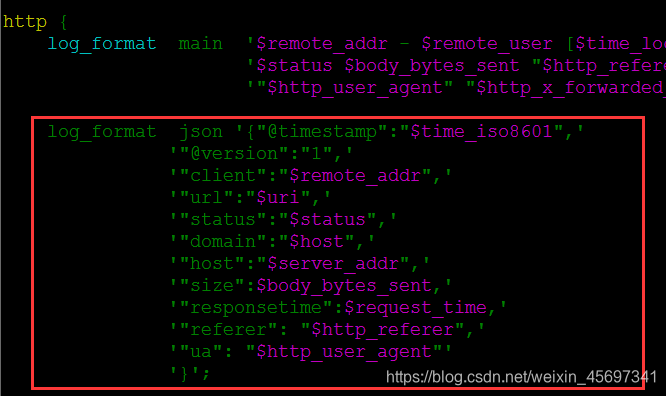
修改nginx的配置文件,分别在nginx.conf的http和server配置区域添加下面内容:
http 标签中
log_format json '{"@timestamp":"$time_iso8601",' '"@version":"1",' '"client":"$remote_addr",' '"url":"$uri",' '"status":"$status",' '"domain":"$host",' '"host":"$server_addr",' '"size":$body_bytes_sent,' '"responsetime":$request_time,' '"referer": "$http_referer",' '"ua": "$http_user_agent"' '}'; server标签中
 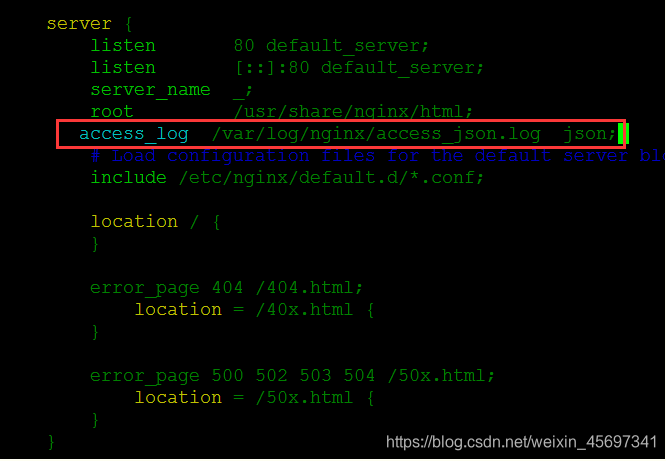 启动nginx服务: [root@elk-node1 ~]# systemctl start nginx [root@elk-node1 ~]# systemctl status nginx ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor preset: disabled) Active: active (running) since Fri 2016-11-11 19:06:55 CST; 3s ago Process: 15119 ExecStart=/usr/sbin/nginx (code=exited, status=0/SUCCESS) Process: 15116 ExecStartPre=/usr/sbin/nginx -t (code=exited, status=0/SUCCESS) Process: 15114 ExecStartPre=/usr/bin/rm -f /run/nginx.pid (code=exited, status=0/SUCCESS) Main PID: 15122 (nginx) CGroup: /system.slice/nginx.service ├─15122 nginx: master process /usr/sbin/nginx ├─15123 nginx: worker process └─15124 nginx: worker process Nov 11 19:06:54 elk-node1 systemd[1]: Starting The nginx HTTP and reverse proxy server... Nov 11 19:06:55 elk-node1 nginx[15116]: nginx: the configuration file /etc/nginx/nginx.conf syntax is ok Nov 11 19:06:55 elk-node1 nginx[15116]: nginx: configuration file /etc/nginx/nginx.conf test is successful Nov 11 19:06:55 elk-node1 systemd[1]: Started The nginx HTTP and reverse proxy server. 编写收集文件
这次使用json的方式收集:
[root@elk-node1 ~]# vim json.conf input { file { path => "/var/log/nginx/access_json.log" codec => "json" } } output { stdout { codec => "rubydebug" } } 启动日志收集程序:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f json.conf #或加个&放在后台执行
访问nginx页面(在elk-node1的宿主机上执行访问页面的命令:curl http://192.168.1.160)就会出现以下内容:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f json.conf Settings: Default filter workers: 1 Logstash startup completed { "@timestamp" => "2016-11-11T11:10:53.000Z", "@version" => "1", "client" => "192.168.1.7", "url" => "/index.html", "status" => "200", "domain" => "192.168.1.160", "host" => "192.168.1.160", "size" => 3700, "responsetime" => 0.0, "referer" => "-", "ua" => "curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.14.0.0 zlib/1.2.3 libidn/1.18 libssh2/1.4.2", "path" => "/var/log/nginx/access_json.log" 注意:
上面的json.conf配置只是将nginx日志输出,还没有输入到elasticsearch里,所以这个时候在elasticsearch界面里是采集不到nginx日志的。
需要配置一下,将nginx日志输入到elasticsearch中,将其汇总到总文件file.conf里,如下也将nginx-log日志输入到elasticserach里:(后续就可以只用这个汇总文件,把要追加的日志汇总到这个总文件里即可)
[root@elk-node1 ~]# cat file.conf input { file { path => "/var/log/messages" type => "system" start_position => "beginning" } file { path => "/var/log/elasticsearch/huanqiu.log" type => "es-error" start_position => "beginning" codec => multiline { pattern => "^\[" negate => true what => "previous" } } file { path => "/var/log/nginx/access_json.log" codec => json start_position => "beginning" type => "nginx-log" } } output { if [type] == "system"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "system-%{+YYYY.MM.dd}" } } if [type] == "es-error"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "es-error-%{+YYYY.MM.dd}" } } if [type] == "nginx-log"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "nignx-log-%{+YYYY.MM.dd}" } } } 可以加上–configtest参数,测试下配置文件是否有语法错误或配置不当的地方,这个很重要!!
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f file.conf --configtest Configuration OK 然后接着执行logstash命令(由于上面已经将这个执行命令放到了后台,所以这里其实不用执行,也可以先kill之前的,再放后台执行),然后可以再访问nginx界面测试下
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f file.conf &
登陆elasticsearch界面查看:

将nginx日志整合到kibana界面里,如下:


5)收集系统日志
编写收集文件并执行。
[root@elk-node1 ~]# cat syslog.conf input { syslog { type => "system-syslog" host => "192.168.1.160" port => "514" } } output { stdout { codec => "rubydebug" } } 对上面的采集文件进行执行:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f syslog.conf 重新开启一个窗口,查看服务是否启动:
[root@elk-node1 ~]# netstat -ntlp|grep 514 tcp6 0 0 192.168.1.160:514 :::* LISTEN 17842/java [root@elk-node1 ~]# vim /etc/rsyslog.conf #*.* @@remote-host:514 【在此行下面添加如下内容】 . @@192.168.1.160:514
[root@elk-node1 ~]# systemctl restart rsyslog 回到原来的窗口(即上面采集文件的执行终端),就会出现数据:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f syslog.conf Settings: Default filter workers: 1 Logstash startup completed { "message" => "Stopping System Logging Service...\n", "@version" => "1", "@timestamp" => "2016-11-13T10:35:30.000Z", "type" => "system-syslog", "host" => "192.168.1.160", "priority" => 30, "timestamp" => "Nov 13 18:35:30", "logsource" => "elk-node1", "program" => "systemd", "severity" => 6, "facility" => 3, "facility_label" => "system", "severity_label" => "Informational" } ........ ........ 再次添加到总文件file.conf中:
[root@elk-node1 ~]# cat file.conf input { file { path => "/var/log/messages" type => "system" start_position => "beginning" } file { path => "/var/log/elasticsearch/huanqiu.log" type => "es-error" start_position => "beginning" codec => multiline { pattern => "^\[" negate => true what => "previous" } } file { path => "/var/log/nginx/access_json.log" codec => json start_position => "beginning" type => "nginx-log" } syslog { type => "system-syslog" host => "192.168.1.160" port => "514" } } output { if [type] == "system"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "system-%{+YYYY.MM.dd}" } } if [type] == "es-error"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "es-error-%{+YYYY.MM.dd}" } } if [type] == "nginx-log"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "nignx-log-%{+YYYY.MM.dd}" } } if [type] == "system-syslog"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "system-syslog-%{+YYYY.MM.dd}" } } } 执行总文件(先测试下总文件配置是否有误,然后先kill之前在后台启动的file.conf文件,再次执行):
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f file.conf --configtest Configuration OK [root@elk-node1 ~]# /opt/logstash/bin/logstash -f file.conf & 测试:
向日志中添加数据,看elasticsearch和kibana的变化:
[root@elk-node1 ~]# logger "hehehehehehe1" [root@elk-node1 ~]# logger "hehehehehehe2" [root@elk-node1 ~]# logger "hehehehehehe3" [root@elk-node1 ~]# logger "hehehehehehe4" [root@elk-node1 ~]# logger "hehehehehehe5" 
添加到kibana界面中:

6)TCP日志的收集
编写日志收集文件,并执行:(有需要的话,可以将下面收集文件的配置汇总到上面的总文件file.conf里,进而输入到elasticsearch界面里和kibana里查看)
[root@elk-node1 ~]# cat tcp.conf input { tcp { host => "192.168.1.160" port => "6666" } } output { stdout { codec => "rubydebug" } } [root@elk-node1 ~]# /opt/logstash/bin/logstash -f tcp.conf 开启另外一个窗口,测试一(安装nc命令:yum install -y nc):
[root@elk-node1 ~]# nc 192.168.1.160 6666 </etc/resolv.conf 回到原来的窗口(即上面采集文件的执行终端),就会出现数据:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f tcp.conf Settings: Default filter workers: 1 Logstash startup completed { "message" => "", "@version" => "1", "@timestamp" => "2016-11-13T11:01:15.280Z", "host" => "192.168.1.160", "port" => 49743 } 测试二:
[root@elk-node1 ~]# echo "hehe" | nc 192.168.1.160 6666 [root@elk-node1 ~]# echo "hehe" > /dev/tcp/192.168.1.160/6666 回到之前的执行端口,在去查看,就会显示出来:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f tcp.conf Settings: Default filter workers: 1 Logstash startup completed<br>....... { "message" => "hehe", "@version" => "1", "@timestamp" => "2016-11-13T11:39:58.263Z", "host" => "192.168.1.160", "port" => 53432 } { "message" => "hehe", "@version" => "1", "@timestamp" => "2016-11-13T11:40:13.458Z", "host" => "192.168.1.160", "port" => 53457 } 7)使用filter
编写文件:
[root@elk-node1 ~]# cat grok.conf input { stdin{} } filter { grok { match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" } } } output { stdout{ codec => "rubydebug" } } 执行检测:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f grok.conf Settings: Default filter workers: 1 Logstash startup completed 55.3.244.1 GET /index.html 15824 0.043 #输入这个,下面就会自动形成字典的形式 { "message" => "55.3.244.1 GET /index.html 15824 0.043", "@version" => "1", "@timestamp" => "2016-11-13T11:45:47.882Z", "host" => "elk-node1", "client" => "55.3.244.1", "method" => "GET", "request" => "/index.html", "bytes" => "15824", "duration" => "0.043" } 其实上面使用的那些变量在程序中都有定义:
[root@elk-node1 ~]# cd /opt/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.2/patterns/ [root@elk-node1 patterns]# ls aws bro firewalls haproxy junos mcollective mongodb postgresql redis bacula exim grok-patterns java linux-syslog mcollective-patterns nagios rails ruby [root@elk-node1 patterns]# cat grok-patterns filter { # drop sleep events grok { match => { "message" =>"SELECT SLEEP" } add_tag => [ "sleep_drop" ] tag_on_failure => [] # prevent default _grokparsefailure tag on real records } if "sleep_drop" in [tags] { drop {} } grok { match => [ "message", "(?m)^# User@Host: %{USER:user}\[[^\]]+\] @ (?:(?<clienthost>\S*) )?\[(?:%{IP:clientip})?\]\s+Id: %{NUMBER:row_id:int}\s*# Query_time: %{NUMBER:query_time:float}\s+Lock_time: %{NUMBER:lock_time:float}\s+Rows_sent: %{NUMBER:rows_sent:int}\s+Rows_examined: %{NUMBER:rows_examined:int}\s*(?:use %{DATA:database};\s*)?SET timestamp=%{NUMBER:timestamp};\s*(?<query>(?<action>\w+)\s+.*)\n#\s*" ] } date { match => [ "timestamp", "UNIX" ] remove_field => [ "timestamp" ] } } 8)mysql慢查询
收集文件:
[root@elk-node1 ~]# cat mysql-slow.conf input { file { path => "/root/slow.log" type => "mysql-slowlog" codec => multiline { pattern => "^# User@Host" negate => true what => "previous" } } } filter { # drop sleep events grok { match => { "message" =>"SELECT SLEEP" } add_tag => [ "sleep_drop" ] tag_on_failure => [] # prevent default _grokparsefailure tag on real records } if "sleep_drop" in [tags] { drop {} } grok { match => [ "message", "(?m)^# User@Host: %{USER:user}\[[^\]]+\] @ (?:(?<clienthost>\S*) )?\[(?:%{IP:clientip})?\]\s+Id: %{NUMBER:row_id:int}\s*# Query_time: %{NUMBER:query_time:float}\s+Lock_time: %{NUMBER:lock_time:float}\s+Rows_sent: %{NUMBER:rows_sent:int}\s+Rows_examined: %{NUMBER:rows_examined:int}\s*(?:use %{DATA:database};\s*)?SET timestamp=%{NUMBER:timestamp};\s*(?<query>(?<action>\w+)\s+.*)\n#\s*" ] } date { match => [ "timestamp", "UNIX" ] remove_field => [ "timestamp" ] } } output { stdout { codec =>"rubydebug" } } 执行检测:
上面需要的/root/slow.log是自己上传的,然后自己插入数据保存后,会显示:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f mysql-slow.conf Settings: Default filter workers: 1 Logstash startup completed { "@timestamp" => "2016-11-14T06:53:54.100Z", "message" => "# Time: 161114 11:05:18", "@version" => "1", "path" => "/root/slow.log", "host" => "elk-node1", "type" => "mysql-slowlog", "tags" => [ [0] "_grokparsefailure" ] } { "@timestamp" => "2016-11-14T06:53:54.105Z", "message" => "# User@Host: test[test] @ [124.65.197.154]\n# Query_time: 1.725889 Lock_time: 0.000430 Rows_sent: 0 Rows_examined: 0\nuse test_zh_o2o_db;\nSET timestamp=1479092718;\nSELECT trigger_name, event_manipulation, event_object_table, action_statement, action_timing, DEFINER FROM information_schema.triggers WHERE BINARY event_object_schema='test_zh_o2o_db' AND BINARY event_object_table='customer';\n# Time: 161114 12:10:30", "@version" => "1", "tags" => [ [0] "multiline", [1] "_grokparsefailure" ], "path" => "/root/slow.log", "host" => "elk-node1", "type" => "mysql-slowlog" } ======================================================================
接下来描述会遇见到的一个问题:
一旦我们的elasticsearch出现问题,就不能进行日志采集处理了!
这种情况下该怎么办呢?
解决方案;
可以在client和elasticsearch之间添加一个中间件作为缓存,先将采集到的日志内容写到中间件上,然后再从中间件输入到elasticsearch中。
这就完美的解决了上述的问题了。
(4)ELK中使用redis作为中间件,缓存日志采集内容
1)redis的配置和启动
[root@elk-node1 ~]# vim /etc/redis.conf #修改下面两行内容 daemonize yes bind 192.168.1.160 [root@elk-node1 ~]# systemctl start redis [root@elk-node1 ~]# lsof -i:6379 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME redis-ser 19474 redis 4u IPv4 1344465 0t0 TCP elk-node1:6379 (LISTEN) [root@elk-node1 ~]# redis-cli -h 192.168.1.160 192.168.1.160:6379> info # Server redis_version:2.8.19 ....... 2)编写从Client端收集数据的文件
[root@elk-node1 ~]# vim redis-out.conf input { stdin {} } output { redis { host => "192.168.1.160" port => "6379" db => "6" data_type => "list" key => "demo" } } 3)执行收集数据的文件,并输入数据hello redis
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f redis-out.conf Settings: Default filter workers: 1 Logstash startup completed #下面输入数据hello redis hello redis 4)在redis中查看数据
[root@elk-node1 ~]# redis-cli -h 192.168.1.160 192.168.1.160:6379> info # Server ....... ....... # Keyspace db6:keys=1,expires=0,avg_ttl=0 #在最下面一行,显示是db6 192.168.1.160:6379> select 6 OK 192.168.1.160:6379[6]> keys * 1) "demo" 192.168.1.160:6379[6]> LINDEX demo -1 "{\"message\":\"hello redis\",\"@version\":\"1\",\"@timestamp\":\"2016-11-14T08:04:25.981Z\",\"host\":\"elk-node1\"}" 5)继续随便写点数据
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f redis-out.conf Settings: Default filter workers: 1 Logstash startup completed hello redis 123456 asdf ert wang shi bo guohuihui as we r g asdfjkdfsak 5423wer 34rt3 6y 7uj u io9 sdjfhsdk890 huanqiu huanqiuchain hqsb asda 6)在redis中查看
在redis中查看长度:
[root@elk-node1 ~]# redis-cli -h 192.168.1.160 192.168.1.160:6379> info # Server redis_version:2.8.19 # Keyspace db6:keys=1,expires=0,avg_ttl=0 #显示是db6 192.168.1.160:6379> select 6 OK 192.168.1.160:6379[6]> keys * 1) "demo" 192.168.1.160:6379[6]> LLEN demo (integer) 24 7)将redis中的内容写到ES中
[root@elk-node1 ~]# vim redis-in.conf input { redis { host => "192.168.1.160" port => "6379" db => "6" data_type => "list" key => "demo" } } output { elasticsearch { hosts => ["192.168.1.160:9200"] index => "redis-in-%{+YYYY.MM.dd}" } } 执行:
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f redis-in.conf --configtest Configuration OK [root@elk-node1 ~]# /opt/logstash/bin/logstash -f redis-in.conf & 在redis中查看,发现数据已被读出:
192.168.1.160:6379[6]> LLEN demo (integer) 0
===温馨提示=
redis默认只有16个数据库, 也就是说最多只能有16个db, 即db01-db15 但是key值可以设置不同, 也就是针对不同日志的key前缀可以设置不同. 比如: key => "nginx.log"的值最多可以设置16个db, 即db01-db15 key => "mysql.log"的值最多可以设置16个db, 即db01-db15 key => "tomcat.log"的值最多可以设置16个db, 即db01-db15 登陆elasticsearch界面查看:


8)接着,将收集到的所有日志写入到redis中。这了重新定义一个添加redis缓存后的总文件shipper.conf。(可以将之前执行的总文件file.conf停掉)
[root@elk-node1 ~]# vim shipper.conf
input {
file {
path => “/var/log/messages”
type => “system”
start_position => “beginning”
}
file { path => "/var/log/elasticsearch/huanqiu.log" type => "es-error" start_position => "beginning" codec => multiline { pattern => "^\[" negate => true what => "previous" } } file { path => "/var/log/nginx/access_json.log" codec => json start_position => "beginning" type => "nginx-log" } syslog { type => "system-syslog" host => "192.168.1.160" port => "514" } }
output {
if [type] == “system”{
redis {
host => “192.168.1.160”
port => “6379”
db => “6”
data_type => “list”
key => “system”
}
}
if [type] == "es-error"{ redis { host => "192.168.1.160" port => "6379" db => "6" data_type => "list" key => "demo" } } if [type] == "nginx-log"{ redis { host => "192.168.1.160" port => "6379" db => "6" data_type => "list" key => "nginx-log" } } if [type] == "system-syslog"{ redis { host => "192.168.1.160" port => "6379" db => "6" data_type => "list" key => "system-syslog" } } }
执行上面的文件(提前将上面之前启动的file.conf文件的执行给结束掉!)
[root@elk-node1 ~]# /opt/logstash/bin/logstash -f shipper.conf --configtest Configuration OK [root@elk-node1 ~]# /opt/logstash/bin/logstash -f shipper.conf Settings: Default filter workers: 1 Logstash startup completed 在redis中查看:
[root@elk-node1 ~]# redis-cli -h 192.168.1.160 192.168.1.160:6379> info # Server redis_version:2.8.19 # Keyspace db6:keys=1,expires=0,avg_ttl=0 #显示是db6 192.168.1.160:6379> select 6 OK 192.168.1.160:6379[6]> keys * 1) "demo" 2) "system" 192.168.1.160:6379[6]> keys * 1) "nginx-log" 2) "demo" 3) "system" 另开一个窗口,添加点日志:
[root@elk-node1 ~]# logger "12325423" [root@elk-node1 ~]# logger "12325423" [root@elk-node1 ~]# logger "12325423" [root@elk-node1 ~]# logger "12325423" [root@elk-node1 ~]# logger "12325423" [root@elk-node1 ~]# logger "12325423" 又会增加日志:
192.168.1.160:6379[6]> keys * 1) "system-syslog" 2) "nginx-log" 3) "demo" 4) "system" 其实可以在任意的一台ES中将数据从redis读取到ES中。
下面咱们在elk-node2节点,将数据从redis读取到ES中:
编写文件:
[root@elk-node2 ~]# cat file.conf
input {
redis {
type => “system”
host => “192.168.1.160”
port => “6379”
db => “6”
data_type => “list”
key => “system”
}
redis { type => "es-error" host => "192.168.1.160" port => "6379" db => "6" data_type => "list" key => "es-error" } redis { type => "nginx-log" host => "192.168.1.160" port => "6379" db => "6" data_type => "list" key => "nginx-log" } redis { type => "system-syslog" host => "192.168.1.160" port => "6379" db => "6" data_type => "list" key => "system-syslog" } }
output {
if [type] == "system"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "system-%{+YYYY.MM.dd}" } } if [type] == "es-error"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "es-error-%{+YYYY.MM.dd}" } } if [type] == "nginx-log"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "nignx-log-%{+YYYY.MM.dd}" } } if [type] == "system-syslog"{ elasticsearch { hosts => ["192.168.1.160:9200"] index => "system-syslog-%{+YYYY.MM.dd}" } } }
执行:
[root@elk-node2 ~]# /opt/logstash/bin/logstash -f file.conf --configtest Configuration OK [root@elk-node2 ~]# /opt/logstash/bin/logstash -f file.conf & 去redis中检查,发现数据已经被读出到elasticsearch中了。
192.168.1.160:6379[6]> keys *
(empty list or set)
同时登陆logstash和kibana看,发现可以正常收集到日志了。
可以执行这个 去查看nginx日志
[root@elk-node1 ~]# ab -n10000 -c1 http://192.168.1.160/ 也可以启动多个redis写到ES中,具体根据自己的实际情况而定。
logstash配置java环境=
由于新版的ELK环境要求java1.8,但是有些服务器由于业务代码自身限制只能用java6或java7。
这种情况下,要安装Logstash,就只能单独配置Logstas自己使用的java环境了。
操作如下: 0) 使用rpm包安装logstash 1)安装java8,参考:http://www.cnblogs.com/kevingrace/p/7607442.html 2)在/etc/sysconfig/logstash文件结尾添加下面两行内容: [root@cx-app01 ~]# vim /etc/sysconfig/logstash ....... JAVA_CMD=/usr/local/jdk1.8.0_172/bin JAVA_HOME=/usr/local/jdk1.8.0_172 3)在/opt/logstash/bin/logstash.lib.sh文件添加下面一行内容: [root@cx-app02 ~]# vim /opt/logstash/bin/logstash.lib.sh ....... export JAVA_HOME=/usr/local/jdk1.8.0_172 4) 然后使用logstash收集日志,就不会报java环境错误了。 配置范例=
如下的配置范例: 192.168.10.44为elk的master节点,同时也是redis节点 [root@client-node01 opt]# pwd /opt [root@client-node01 opt]# cat redis-in.conf input { file { path => "/usr/local/tomcat8/logs/catalina.out" type => "tomcat8-logs" start_position => "beginning" codec => multiline { pattern => "^\[" //表示收集以"["开头的日志信息 negate => true what => "previous" } } } output { if [type] == "tomcat8-logs"{ redis { host => "192.168.10.44" port => "6379" db => "1" data_type => "list" key => "tomcat8-logs" } } } [root@client-node01 opt]# cat redis-input.conf input { file { path => "/var/log/messages" type => "systemlog" start_position => "beginning" stat_interval => "2" } } output { if [type] == "systemlog" { redis { data_type => "list" host => "192.168.10.44" db => "2" port => "6379" key => "systemlog" } } } [root@client-node01 opt]# cat file.conf input { redis { type => "tomcat8-logs" host => "192.168.10.44" port => "6379" db => "1" data_type => "list" key => "tomcat8-logs" } redis { type => "systemlog" host => "192.168.10.44" port => "6379" db => "2" data_type => "list" key => "systemlog" } } output { if [type] == "tomcat8-logs"{ elasticsearch { hosts => ["192.168.10.44:9200"] index => "elk-node2-tomcat8-logs-%{+YYYY.MM.dd}" } } if [type] == "systemlog"{ elasticsearch { hosts => ["192.168.10.44:9200"] index => "elk-node2-systemlog-%{+YYYY.MM.dd}" } } } [root@client-node01 opt]# /opt/logstash/bin/logstash -f /opt/redis-in.conf --configtest Configuration OK [root@client-node01 opt]# /opt/logstash/bin/logstash -f /opt/redis-input.conf --configtest Configuration OK [root@client-node01 opt]# /opt/logstash/bin/logstash -f /opt/file.conf --configtest Configuration OK 启动logstash [root@client-node01 opt]# /opt/logstash/bin/logstash -f /opt/redis-in.conf & [root@client-node01 opt]# /opt/logstash/bin/logstash -f /opt/redis-input.conf & [root@client-node01 opt]# /opt/logstash/bin/logstash -f /opt/file.conf & 这时候,当/usr/local/tomcat8/logs/catalina.out和/var/log/messages文件里有新日志信息写入时,就会触发动作, 在redis里就能查看到相关信息,并查看写入到es里。 ========================================================================================================= 温馨提示: 当客户机的日志信息收集后,经过redis刚读到es数据库里后,如果没有新数据写入,则默认在es的访问界面里是看不到 数据的,只有当日志文件里有新的日志写入后才会触发数据展示的动作,即es的访问界面(http://192.168.10.44:9200/_plugin/head/) 里才能看到日志数据的展示效果。 ========================================================================================================== 假设想上面两个文件里写入测试数据 [root@client-node01 opt]# echo "hellohellohellohello" >> /var/log/messages [root@client-node01 opt]# echo "[hahahahahahhahahahahahahahahahahahah]" >> /usr/local/tomcat8/logs/catalina.out 到redis里发现有相关的key,很快就会读到es里。可以配置到kibana里观察。 可以先测试下日志信息是否写到redis里?然后再测试下数据是否从redis读到es里?一步步确定数据去向。 注意上面redis-in.conf文件中的下面设置,使用正则匹配,收集以哪些字符开头的日志信息: pattern => "^\[" 表示收集以"["开头的日志信息 pattern => "^2018" 表示收集以"2018"开头的日志信息 pattern => "^[a-zA-Z0-9]" 表示收集以字母(大小写)或数字开头的日志信息 pattern => "^[a-zA-Z0-9]|[^ ]+" 表示收集以字母(大小写)或数字或空格的日志信息 当你发现自己的才华撑不起野心时,就请安静下来学习吧
来源:CSDN
作者:weixin_wang996111
链接:https://blog.csdn.net/weixin_45697341/article/details/103238783