Web全栈~29.MySQL
上一期
MySQL安装

根据自己的需求选择~
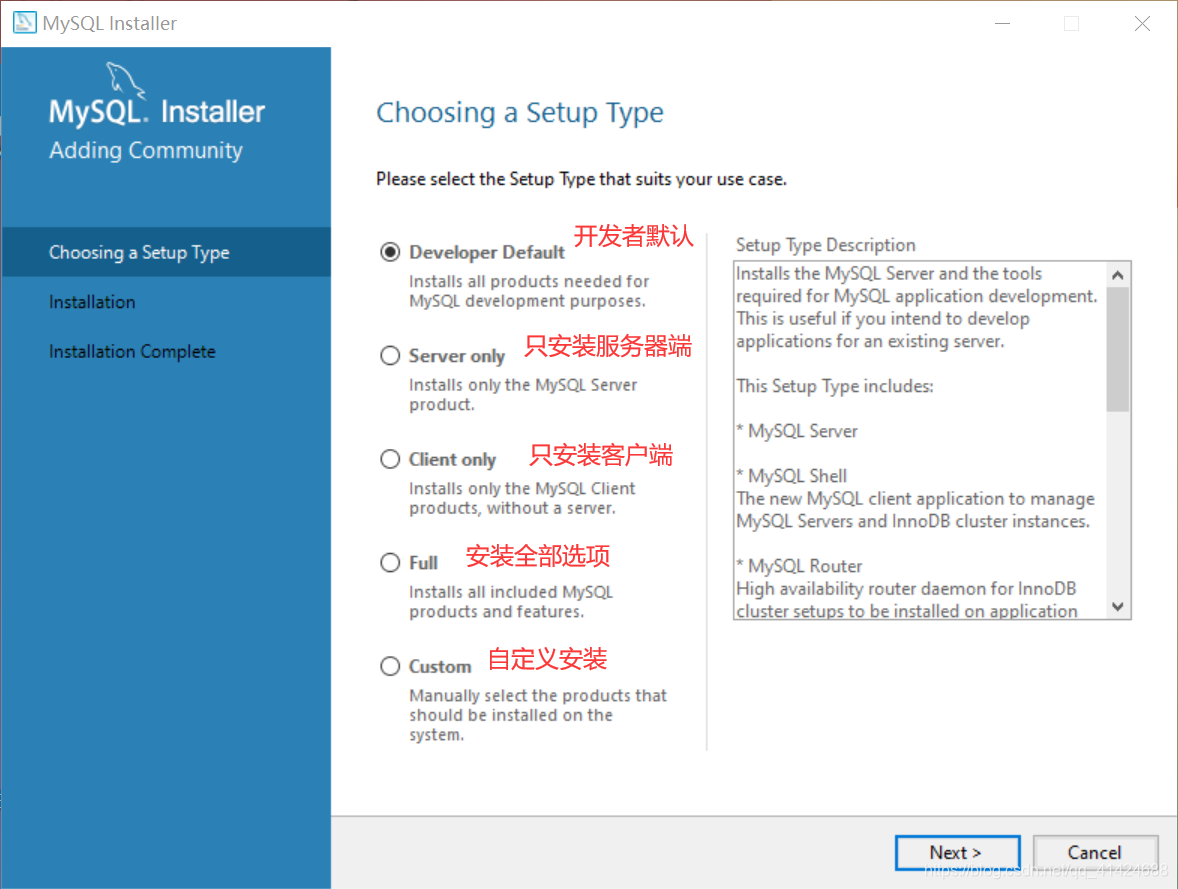
不过本人选了第一个,开发者默认~
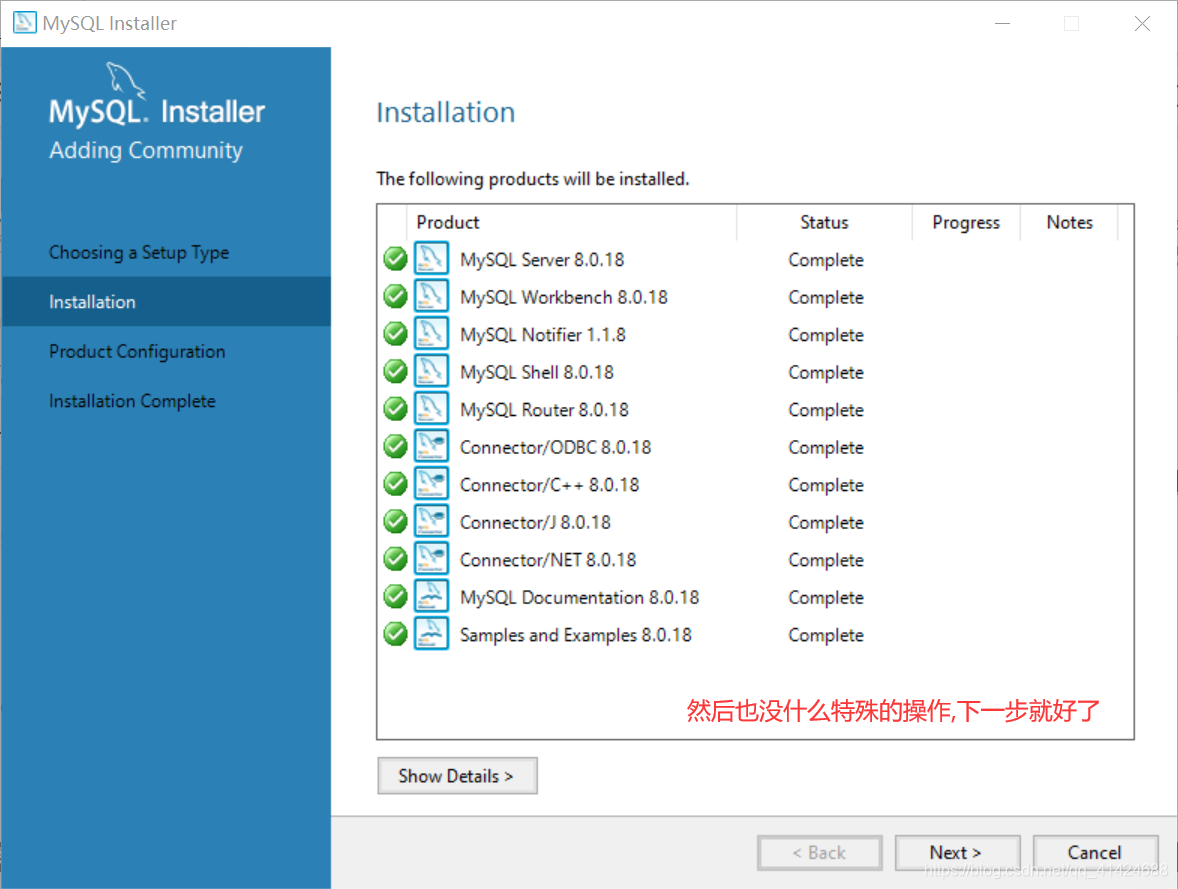
大多数操作,只需要默认下一步就好了,就不一一发截图了~
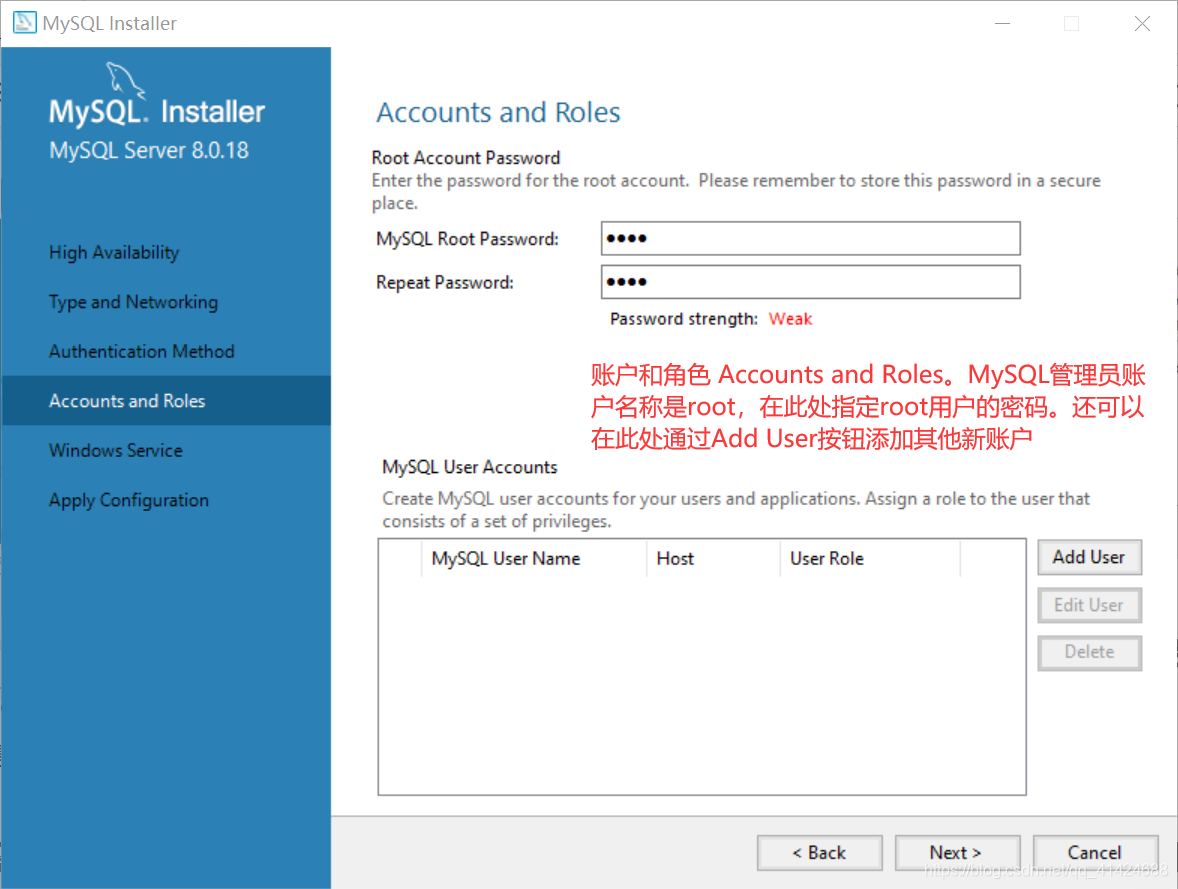

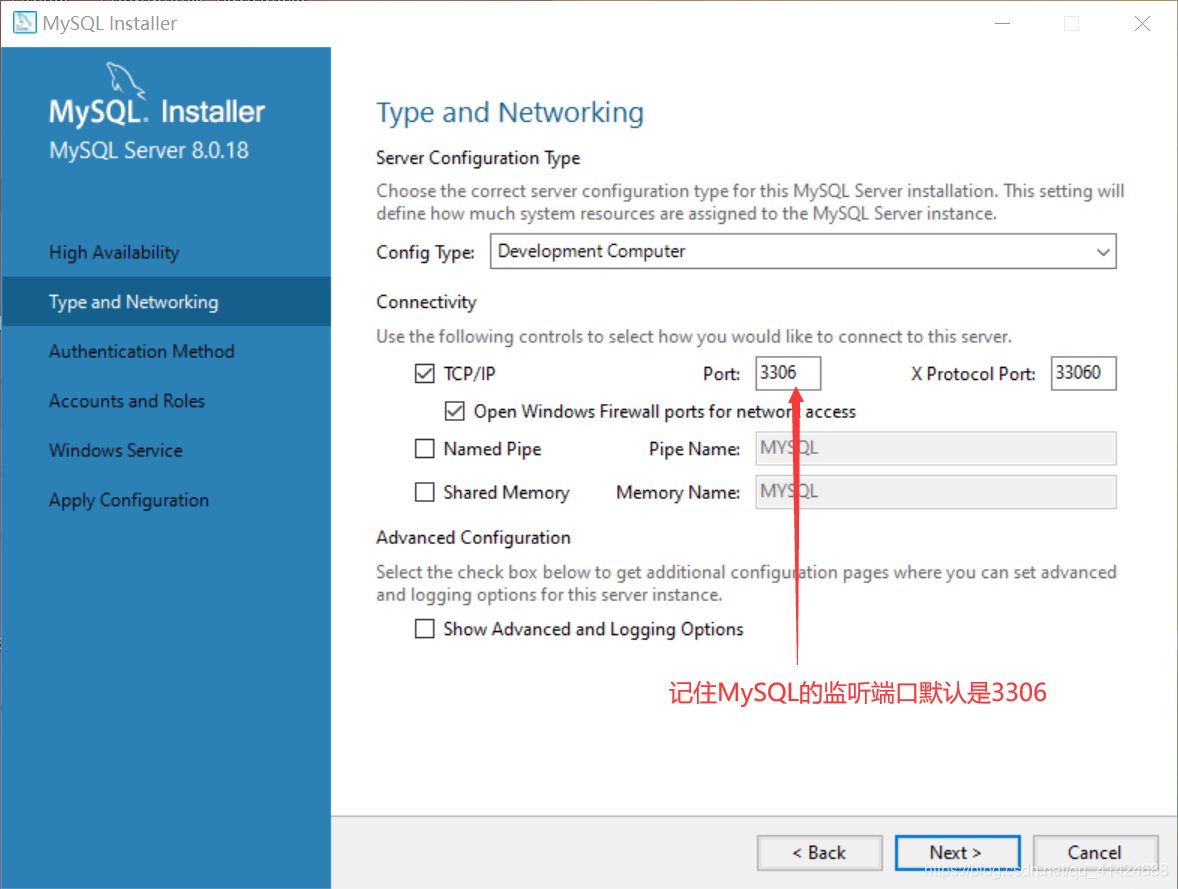
接下来又是一顿next和finish~
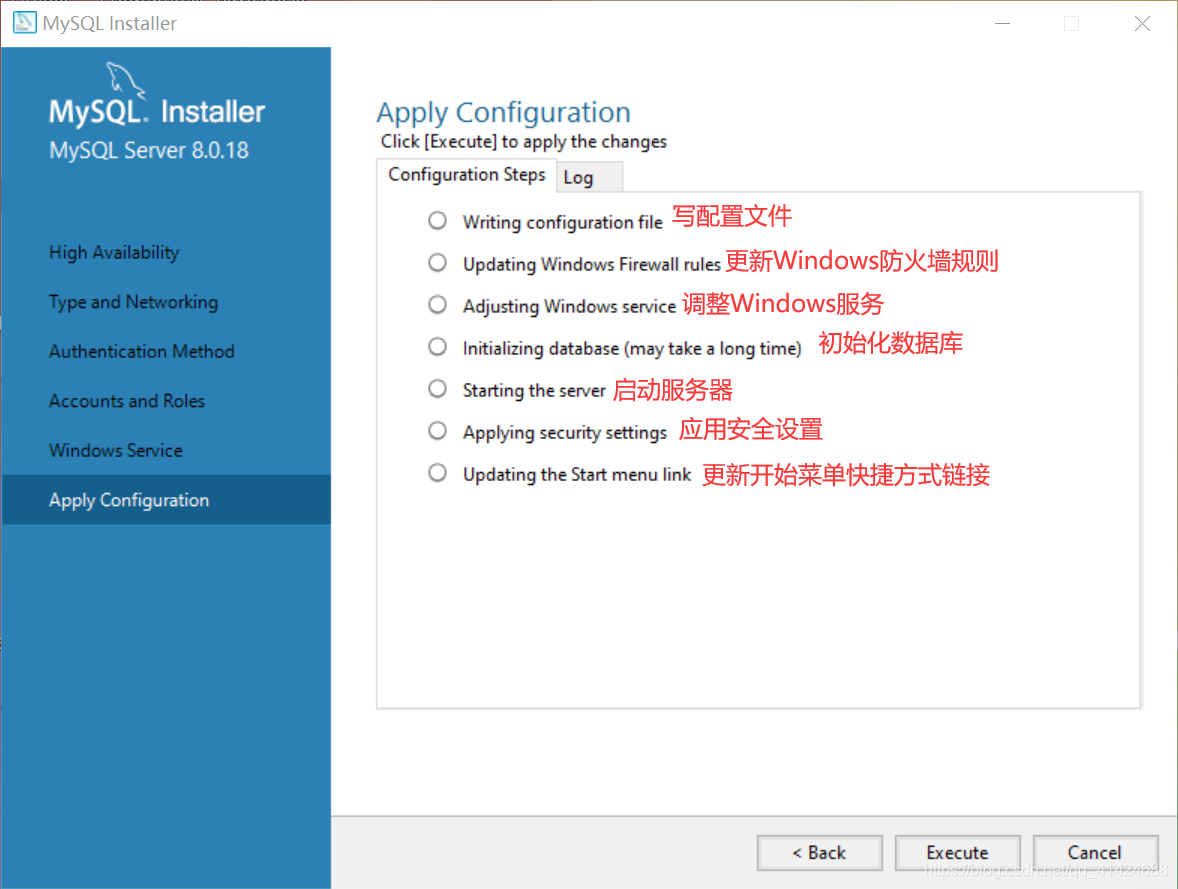
然后还是一顿Next和Finish~最后安装成功…
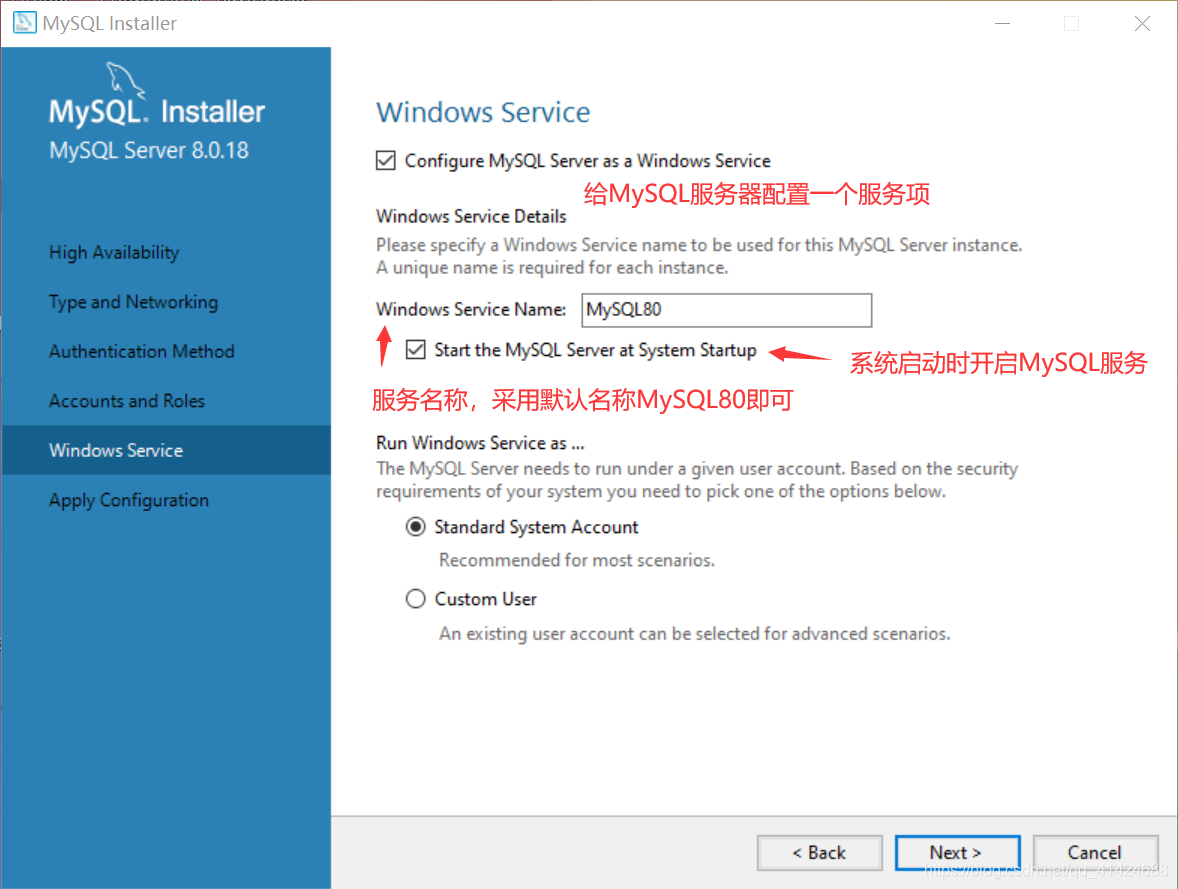
来任务管理器里面的服务看看?
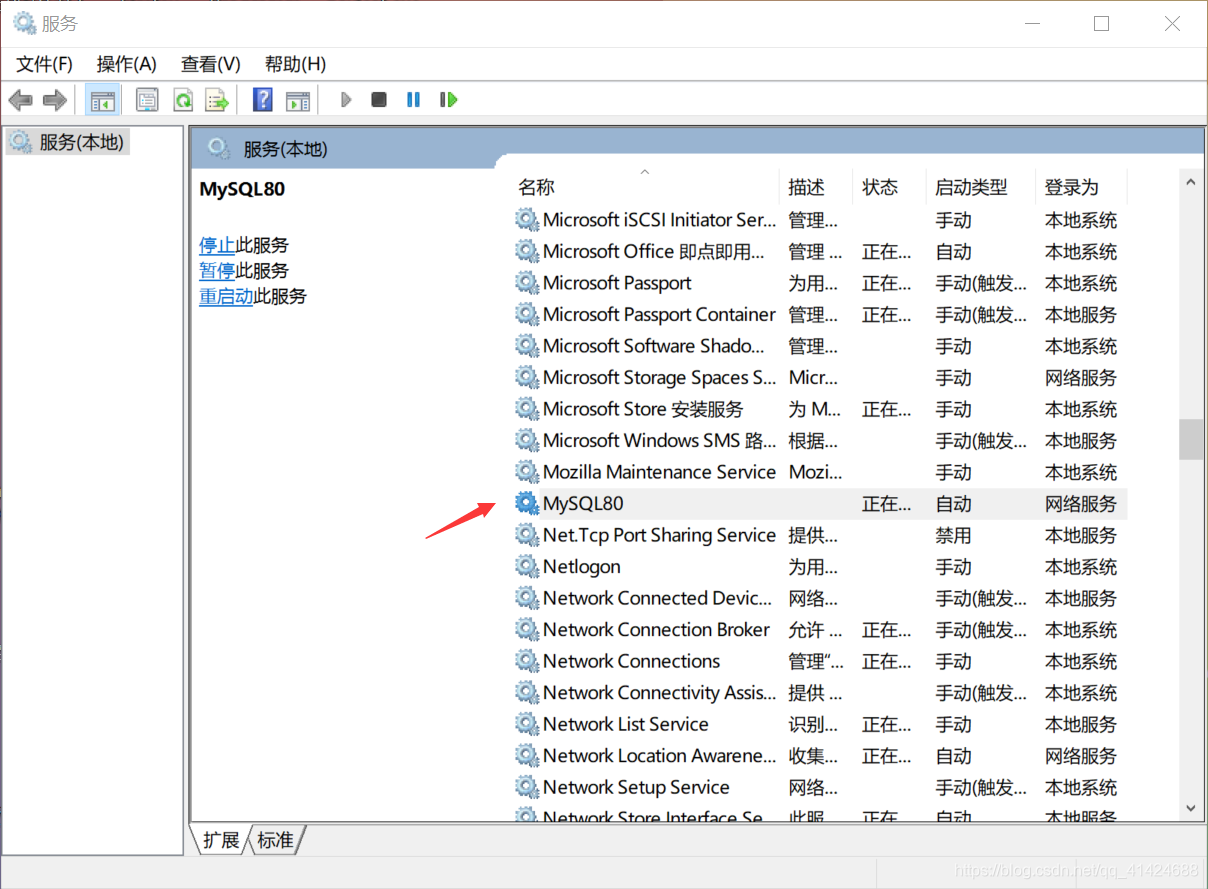
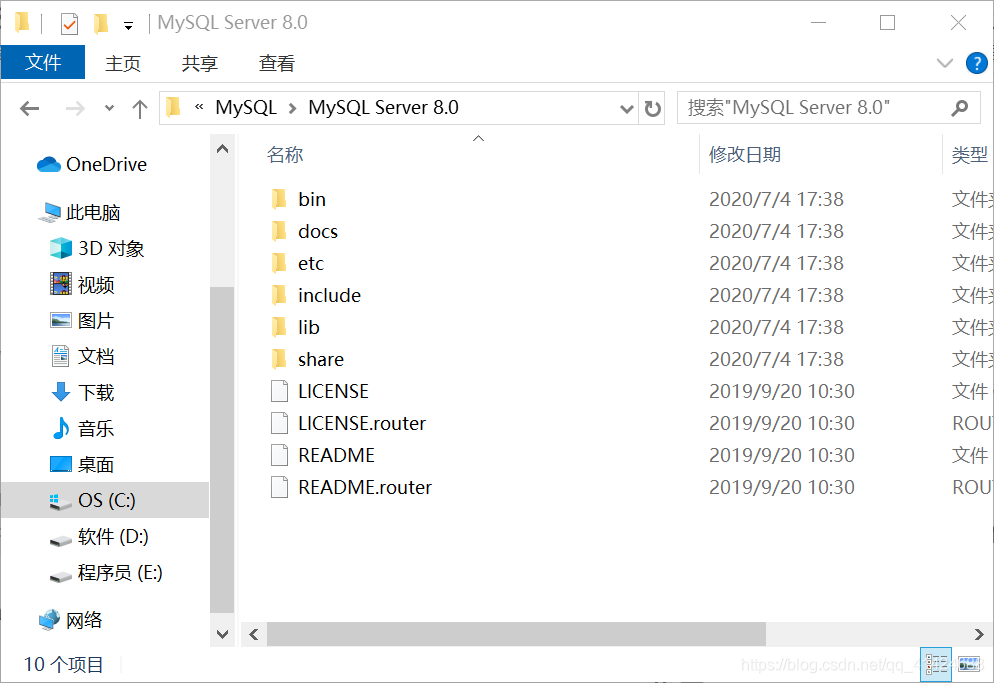
默认路径C:\Program Files\MySQL\MySQL Server 8.0
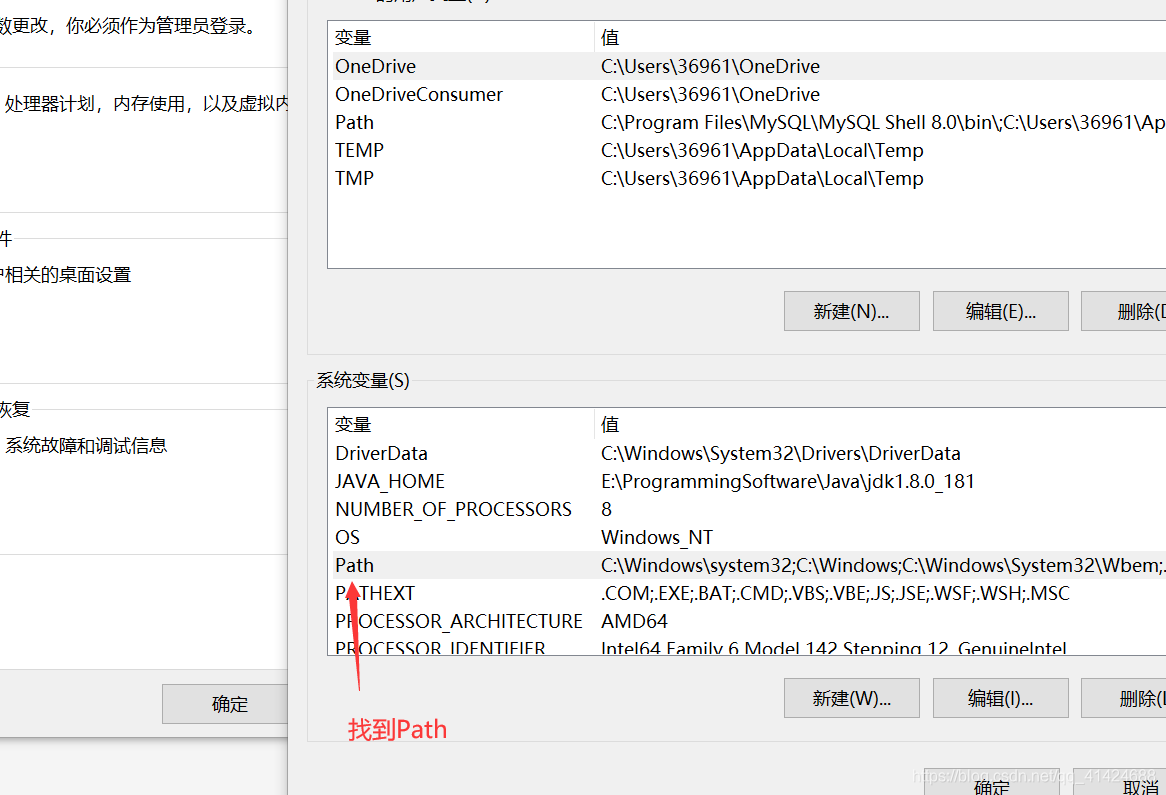
配置path环境变量
计算机,右键,属性,高级系统设置,环境变量
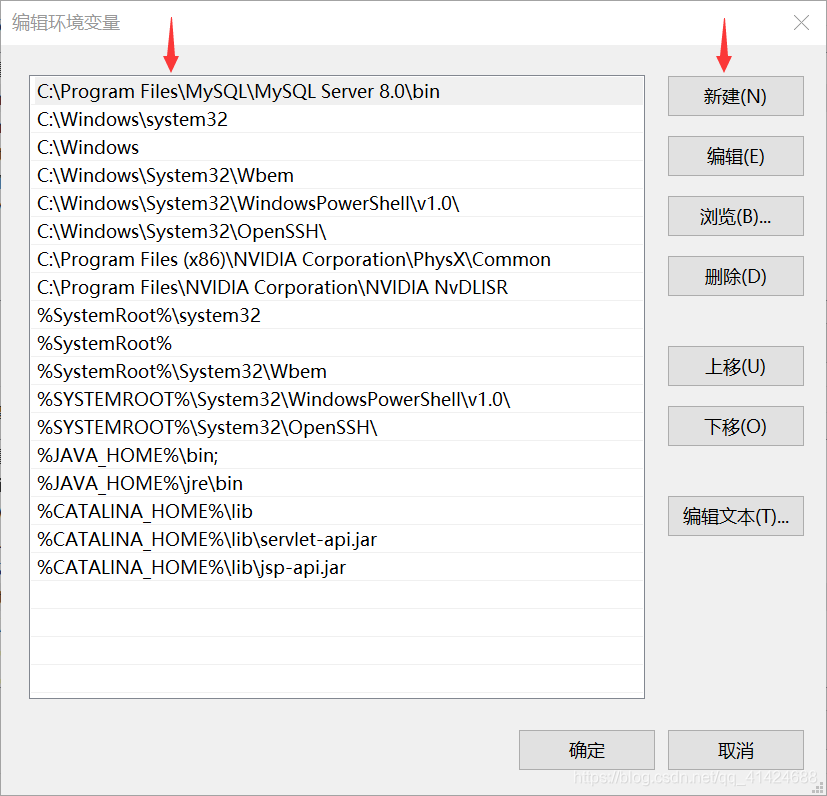
把C:\Program Files\MySQL\MySQL Server 8.0\bin这个路径加到环境变量里面去(放最上面)
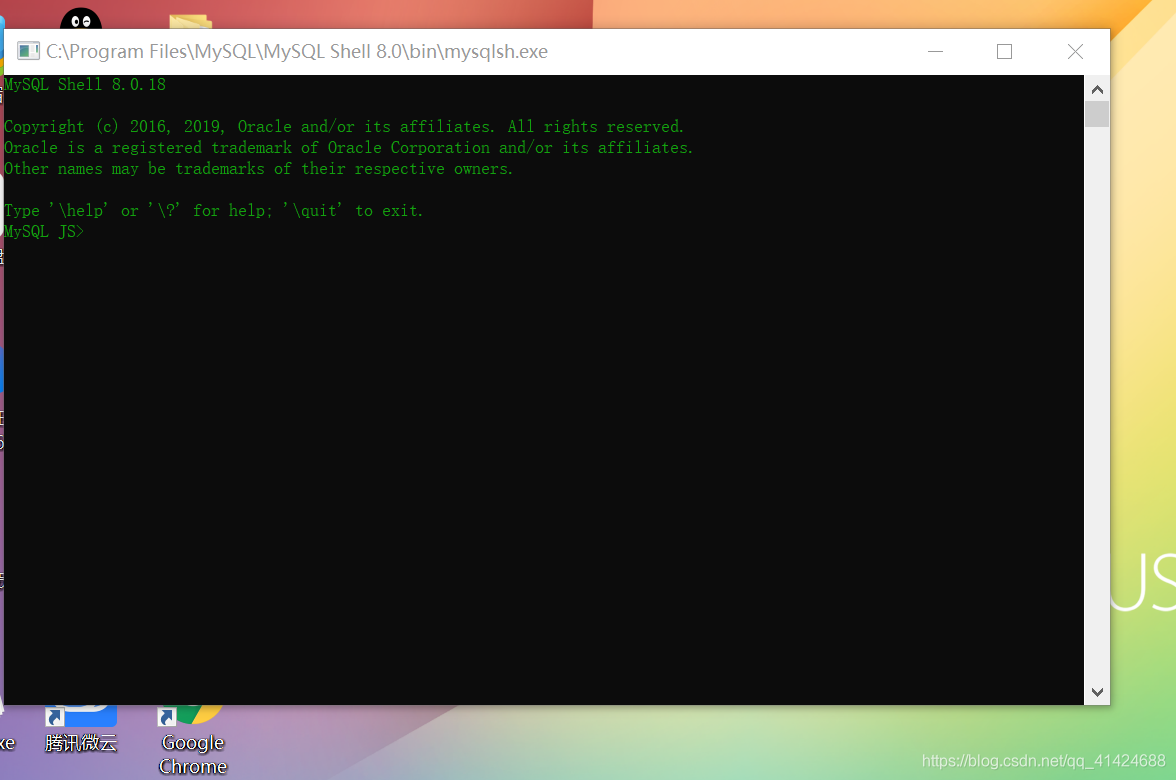
现在就可以用CMD登录MySql了
登录命令: mysql -hlocalhost -uroot -p
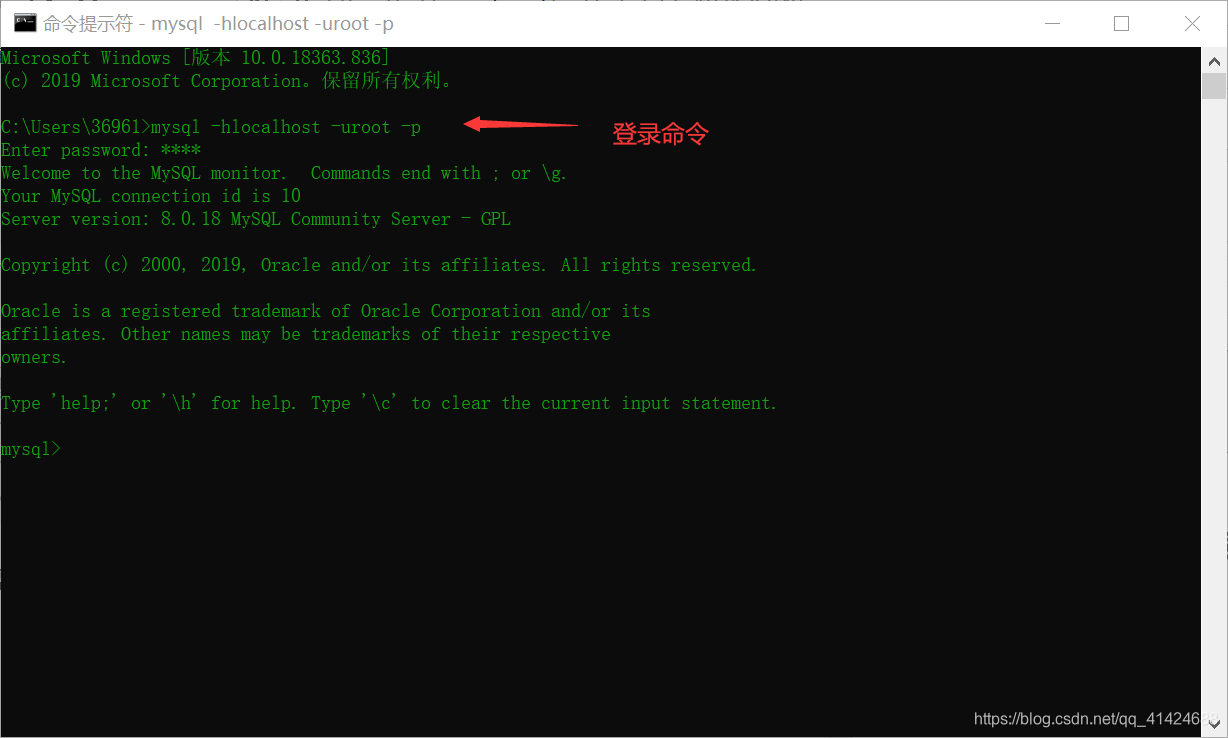
然后我们发现navicat无法连接MySql?
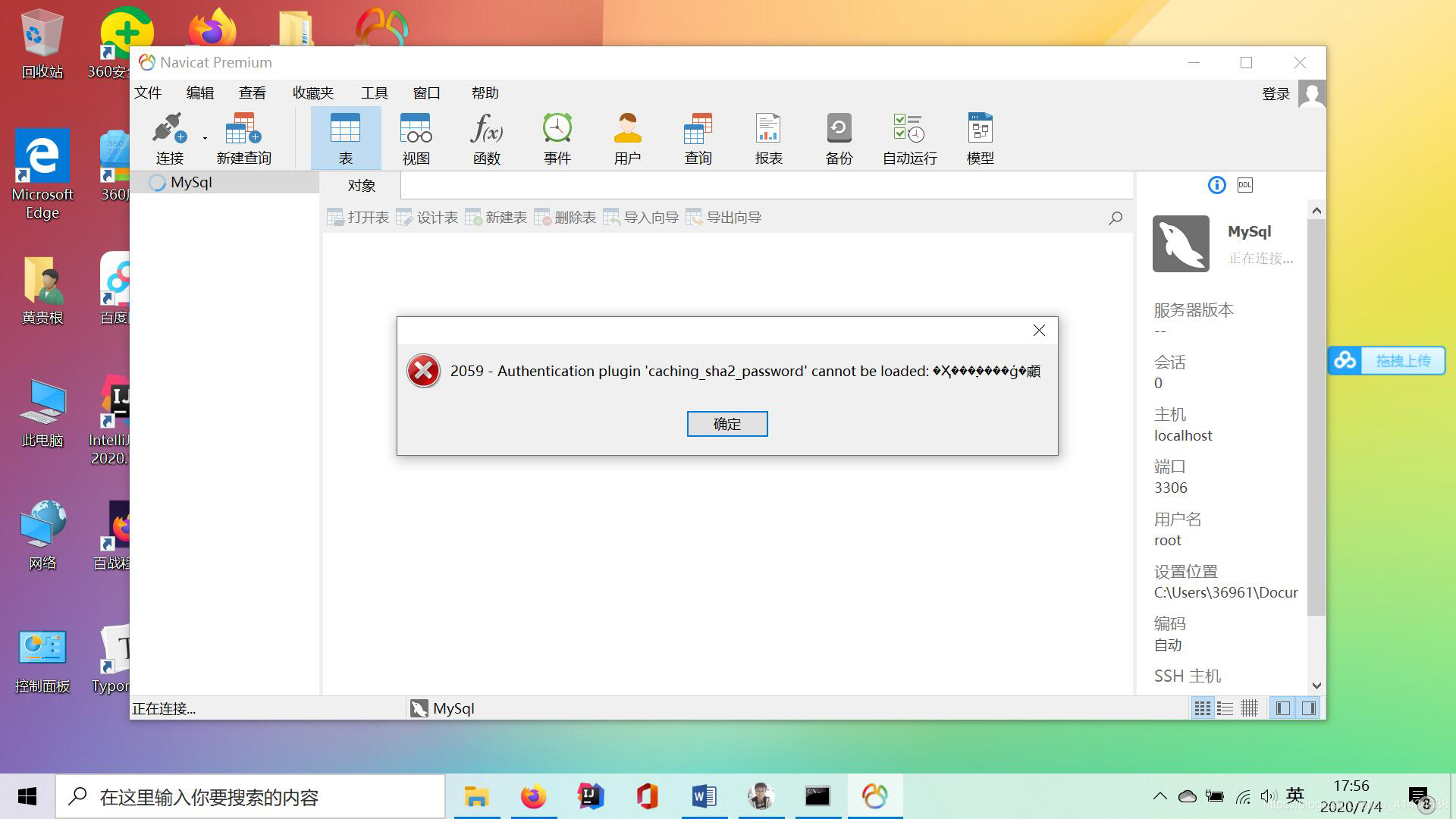
别着急,我们还有操作~
这种错误的原因是在MySQL8之前版本中加密规则mysql_native_password,而在MySQL8以后的加密规则为caching_sha2_password。要么更新navicat驱动来解决此问题,要么就是将mysql用户登录的加密规则修改为mysql_native_password。我的话呢,就用第二种吧~

加上这两行命令就可以了~
设置密码永不过期
alter user 'root'@'localhost' identified by 'root' password expire never;
设置加密规则为mysql_native_password
alter user 'root'@'localhost' identified with mysql_native_password by 'root';
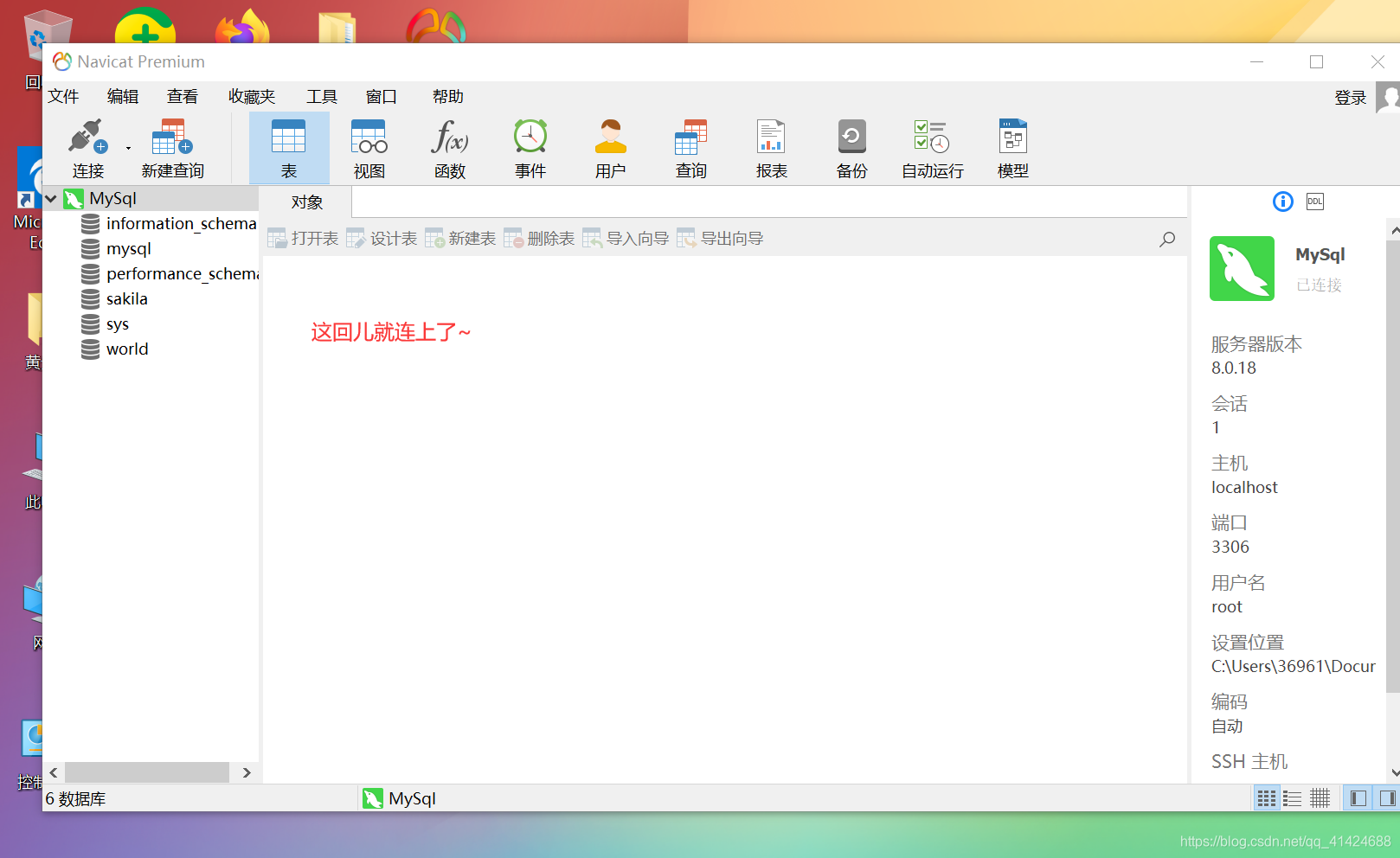
这回儿,就连上了~神奇不!
S Q L语言分类
1.数据库查询语言 (Data Query Language,D Q L)
D Q L主要用于数据的查询,其基本结构是使用SELECT子句,FROM子句和WHERE子句的组合来查询一条或多 条数据。
2.数据库操作语言 (Data Manipulation Language,D M L)
insert 增加数据
update 修改数据
delete 删除数据
3.数据库定义语言(Data Definition Language,D D L)
create 创建数据库
alter 修改数据库对象
drop 删除数据库对象
4.数据控制语言(Data Control Language,D C L)
grant 授予用户权限
revoke 回收用户权限
5.数据库事务语言(Transaction Control Language,T C L)
start transaction 开启事务
commit 提交事务
rollback 回滚事务
set transaction 设置事务属性
D D L 操作
创建数据库和删除数据库
create database mydata; -- 创建数据库
drop database my data; -- 删除数据库
创建数据库表
create table student ( -- 学生表
sno int (6), -- 学号
sname varchar(12), -- 学生姓名
sex char(2), -- 性别
enterdate date , -- 入学时间
classname varchar(12) -- 班级
);
-- 查看表结构
desc student;
修改、删除和查看数据库表 结构
-- 增加一列
alter table student add score double(4,1);
-- 增加一列 改变列位置
alter table student add score1 double(4,1) first; -- 第一个列
alter table student add score2 double(4,1) after age -- 在age 列后面
-- 删除一列
alter table student drop score double(4,1);
-- 修改一列 列名不变
alter table student drop modify score double(5,2);
-- 修改一列 改变列名
alter table student change score score2 double(5,2);
-- 修改表名
alter table student rename to student2;
-- 查看表结构
desc student2
删储数据库 表
drop table student;
D M L操作
插入数据 (insert)
-- 插入一条数据
insert into student values(1,'小白','男','2020-1-1','java001')
-- 插入多条数据
insert into student values
(1,'小白','男','2020-1-1','java001'),
(2,'小张','男','2020-1-1','java001'),
(3,'小李','男','2020-1-1','java001'),
(4,'小刘','男','2020-1-1','java001');
修改数据(update)
update student set sname = '张三' where sno=1;
删除数据(delete)
delete from student where sno=1;
约束
非外键约束
| 约束条件 | 描述 | 关键字 |
|---|---|---|
| 主键约束 | 约束字段的值是唯一的表示对应的记录 | primary key |
| 非空约束 | 约束字段的值不能为空 | not null |
| 唯一约束 | 约束字段的值是唯一的 | unique |
| 检查约束 | 限制某个字段的取值范文 | check |
| 默认值约束 | 约束的字段有默认值 | default |
| 自动增加约束 | 约束的字段是数值,自动递增 | auto_increment |
-- 方式1
create table student ( -- 学生表
sno int (6) primary key auto_increment, -- 学号
sname varchar(12) not null, -- 学生姓名
sex char(2) default '男' check(sex='男'or sex='女'), -- 性别
enterdate date , -- 入学时间
emaill varchar(18) unique,
classname varchar(12) not null -- 班级
);
-- 方式2
create table student(
sno int(6) auto_increment,
sname varchar(12)not null,
sex char(2) default '男' ,
age int(3) ,
classname varchar(12),
enterdate date,
email varchar(20) ,
constraint pk_stu primary key(sno),
constraint ck_stu_sex check(sex ='男' or sex ='女'),
constraint ck_stu_age check(age>=18 and age<=50),
constraint uk_stu_email unique(email)
);
-- 方式3
create table student2 ( -- 学生表
sno int (6), -- 学号
sname varchar(12), -- 学生姓名
sex char(2), -- 性别
enterdate date , -- 入学时间
emaill varchar(18) unique,
classname varchar(12) -- 班级
);
-- 添加约束条件
alter table student2 add constraint pk_stu_sno primary key;
alter table student2 add constraint nn_stu_sname not null;
alter table student2 add constraint ck_stu_sex check(sex='男'or sex='女');
alter table student2 add constraint uq_stu_emaill unique;
alter table student2 modify sno int(6) auto_increment ; -- 修改
-- 删除约束条件
alter table student2 drop nn_stu_sname;
alter table student2 drop uq_stu_emaill;
联合主键
-- 联合主键
create table ta1(
tname varchar(10),
tclas varchar(10),
sal double(8,2),
primary key(tname,tclass)
);
外键约束
外键是指表中某个字段的值依赖于另一张表中某个字段的值,而被依赖的字段必须具有主键约束或者唯一约束
-- 班级表
create table class(
classno int(2) PRIMARY KEY,
classname varchar(10) not null
);
insert into class values(1,'大数据1班'),(2,'java2班'),(3,'前端1班'),(4,'java1班');
-- 学生表
create table student(
stuno int(6) primary key auto_increment,
stuname varchar(5) not null,
sex varchar(2),
sclassno int(2)
);
insert into student values(null,'小白','男',1);
-- 添加外键
alter table student add constraint fk_student_sclassno foreign key(sclassno) references class(classno);
-- 删除外键
alter table student drop foreign key fk_student_sclassno;
外键策略
约束引发的删除和修改问题的处理方案
-- 策略1: 手动修改为null 或者删除 (可省略)
-- 策略2:置空处理 删除/修改被参考表时,被约束的表中的数据同时会被置为null值
alter table student add constraint fk_student_sclassno foreign key(sclassno) references class(classno) on update set null on delete set null;
-- 策略3 级联处理 删除/修改被参考表时,被约束的表中的数据同时也会被删除/修改
alter table student add constraint fk_student_sclassno foreign key(sclassno) references class(classno) on update cascade on delete cascade;
-- 策略4 不允许 restrict(受限)
快速建表和删表操作
-- 要表结构要表数据
create table emp2 select * from emp
-- 只要表结构 不要表数据
create table emp3 as select * from emp where 1=2
-- 只要表结构部分列 不要表数据
create table emp4 as select empno,ename,job from emp where 1=2
-- 只要表结构 部分列部分行
create table emp5 as select empno,ename,job from emp where DEPTNO=20
-- 删表操作
-- 删除整个表 新建一个表结构一样的表 效率高 不可以回滚
truncate table emp3
-- 删除表所有数据 逐条删除 效率低 可以回滚
delete from emp5
-- 回滚
rollback;
查询操作(D Q L)
素材
create table DEPT(
DEPTNO int(2) not null,
DNAME VARCHAR(14),
LOC VARCHAR(13)
);
alter table DEPT
add constraint PK_DEPT primary key (DEPTNO);
create table EMP
(
EMPNO int(4) primary key ,
ENAME VARCHAR(10),
JOB VARCHAR(9),
MGR int(4),
HIREDATE DATE,
SAL double(7,2),
COMM double(7,2),
DEPTNO int(2)
);
alter table EMP
add constraint FK_DEPTNO foreign key (DEPTNO)
references DEPT (DEPTNO);
create table SALGRADE
(
GRADE int primary key,
LOSAL double(7,2),
HISAL double(7,2)
);
create table BONUS
(
ENAME VARCHAR(10),
JOB VARCHAR(9),
SAL double(7,2),
COMM double(7,2)
);
commit;
insert into DEPT (DEPTNO, DNAME, LOC)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into DEPT (DEPTNO, DNAME, LOC)
values (20, 'RESEARCH', 'DALLAS');
insert into DEPT (DEPTNO, DNAME, LOC)
values (30, 'SALES', 'CHICAGO');
insert into DEPT (DEPTNO, DNAME, LOC)
values (40, 'OPERATIONS', 'BOSTON');
commit;
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7844, 'TURNER', 'SALESMAN', 7698, '1981-09-08', 1500, 0, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);
insert into EMP (EMPNO, ENAME, JOB, MGR, HIREDATE, SAL, COMM, DEPTNO)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);
commit;
insert into SALGRADE (GRADE, LOSAL, HISAL)
values (1, 700, 1200);
insert into SALGRADE (GRADE, LOSAL, HISAL)
values (2, 1201, 1400);
insert into SALGRADE (GRADE, LOSAL, HISAL)
values (3, 1401, 2000);
insert into SALGRADE (GRADE, LOSAL, HISAL)
values (4, 2001, 3000);
insert into SALGRADE (GRADE, LOSAL, HISAL)
values (5, 3001, 9999);
commit;
单表查询
-- 最简单的查询语句
select * from dept;
select * from emp;
-- 显示部分列
select empno,ename,sal,comm,deptno from emp;
-- 显示部分行 where
select empno,ename,sal,comm,deptno from emp where sal<2500;
-- 别名
select empno 编号,ename 姓名,sal 工资,comm 补助 ,deptno 部门编号 from emp where sal<2500;
-- 有空格加 引号
select empno '编 号',ename '姓 名',sal SALARY ,comm 补助 ,deptno 部门编号 from emp where sal<2500;
-- 算数运算
select empno,ename,sal*1.1,comm,deptno from emp where sal<2500;
select empno,ename,sal,sal*1.1,comm+sal,deptno from emp where sal<2500;
-- 去重 distinct
select job from emp;
select distinct job from emp;
-- 自动覆盖后面所有列去重
select distinct job,deptno from emp;
-- 排序 order by
select * from emp order by empno -- 默认按照组件排序 升序
select * from emp order by empno asc -- 升序
select * from emp order by sal desc -- 降序
select * from emp order by sal desc ,hiredate -- 先按照sal,在按照日期
where子句
-- 关系运算符
select * from emp;
select * from emp where deptno = 10 -- 等于
select * from emp where deptno < 10 -- 小于
select * from emp where deptno <= 10 -- 小于等于
select * from emp where deptno <> 10 -- 不等
select * from emp where deptno != 10 -- 不等
select * from emp where job= 'CLERK';
select * from emp where job= 'clerk';
select * from emp where binary job= 'clerk';
select * from emp where hiredate <'1981-12-25';
-- 逻辑运算符 and
select * from emp where sal>1500 and sal<3000;
select * from emp where sal>1500 and sal<3000 order by sal;
select * from emp where sal=>1500 and sal<=3000;
select * from emp where between 1500 and 3000;-- [1500,3000]
select * from emp where job = 'CLERK' and deptno = 20
select * from emp where job = 'CLERK' && deptno = 20
-- 逻辑运算符 or
select * from emp where deptno = 10 or deptno = 20
select * from emp where deptno = 10 || deptno = 20
select * from emp where deptno in (10,20)
select * from emp where job in('CLERK','MANAGER','ANALYST')order by job
select * from emp where job = 'CLERK' or deptno = 20
-- 模糊匹配 %
select * from emp where ename like '%A%';-- 包含A
select * from emp where ename like '%__A%';-- _代表任意一个字符
select ename from emp where ename not like '%__A%';
-- null
select * from emp where comm is null -- 为空
select * from emp where comm is not null -- 不为空
-- 小括号
select * from emp where job='SALESMAN' or job='CLERK'and sal>=1280 -- 优先级别 先and 再or
select * from emp where (job='SALESMAN' or job='CLERK')and sal>=1280 -- 改变运算顺序
select * from emp where job='SALESMAN' or (job='CLERK'and sal>=1280)-- 提高可读性
单行函数
1.字符串函数 (String StringBuilder)
| 函数 | 描述 |
|---|---|
| CONCAT(str1, str2,···, strn) | 将str1、str2···strn拼接成一个新的字符串 |
| INSERT(str, index, n, newstr) | 将字符串str从第index位置开始的n个字符替换成字符串newstr |
| LENGTH(str) | 获取字符串str的长度 |
| LOWER(str) | 将字符串str中的每个字符转换为小写 |
| UPPER(str) | 将字符串str中的每个字符转换为大写 |
| LEFT(str, n) | 获取字符串str最左边的n个字符 |
| RIGHT(str, n) | 获取字符串str最右边的n个字符 |
| LPAD(str, n, pad) | 使用字符串pad在str的最左边进行填充,直到长度为n个字符为止 |
| RPAD(str, n, pad) | 使用字符串pad在str的最右边进行填充,直到长度为n个字符为止 |
| LTRIM(str) | 去除字符串str左侧的空格 |
| RTRIM(str) | 去除字符串str右侧的空格 |
| TRIM(str) | 去除字符串str左右两侧的空格 |
| REPLACE(str,oldstr,newstr) | 用字符串newstr替换字符串str中所有的子字符串oldstr |
| REVERSE(str) | 将字符串str中的字符逆序 |
| STRCMP(str1, str2) | 比较字符串str1和str2的大小 |
| SUBSTRING(str,index,n) | 获取从字符串str的index位置开始的n个字符 |
2. 数值数 (Math)
| 函数 | 描述 |
|---|---|
| ABS(num) | 返回num的绝对值 |
| CEIL(num) | 返回大于num的最小整数(向上取整) |
| FLOOR(num) | 返回小于num的最大整数(向下取整) |
| MOD(num1, num2) | 返回num1/num2的余数(取模) |
| PI() | 返回圆周率的值 |
| POW(num,n)/POWER(num, n) | 返回num的n次方 |
| RAND(num) | 返回0~1之间的随机数 |
| ROUND(num, n) | 返回x四舍五入后的值,该值保留到小数点后n位 |
| TRUNCATE(num, n) | 返回num被舍去至小数点后n位的值 |
3. 日期与时间函数
| 函数 | 描述 |
|---|---|
| CURDATE() | 返回当前日期 |
| CURTIME() | 返回当前时间 |
| NOW() | 返回当前日期和时间 |
| SYSDATE() | 返回该函数执行时的日期和时间 |
| DAYOFYEAR(date) | 返回日期date为一年中的第几天 |
| WEEK(date)/WEEKOFYEAR(date) | 返回日期date为一年中的第几周 |
| DATE_FORMAT(date, format) | 返回按字符串format格式化后的日期date |
| DATE_ADD(date, INTERVAL expr unit) /ADDDATE(date, INTERVAL expr unit) | 返回date加上一个时间间隔后的新时间值 |
| DATE_SUB(date, INTERVAL expr unit) UBDATE(date,NTERVAL expr unit) | 返回date减去一个时间间隔后的新时间值 |
| DATEDIFF(date1, date2) | 返回起始日期date1与结束日期date2之间的间隔天数 |
4. 流程函数( IF SWITCH)
| 间隔类型 | 描述 |
|---|---|
| IF(condition, t, f) | 如果条件condition为真,则返回t,否则返回f |
| IFNULL(value1, value2) | 如果value1不为null,则返回value1,否则返回value2 |
| NULLIF(value1, value2) | 如果value1等于value2,则返回null,否则返回value1 |
| CASE value WHEN [value1] THEN result1 [WHEN [value2] THEN result2 …] [ELSE result] END | 如果value等于value1,则返回result1,···,否则返回result |
| CASE WHEN [condition1] THEN result1 [WHEN [condition2] THEN result2 …] [ELSE result] END | 如果条件condition1为真,则返回result1,···,否则返回result |
5.JSON函数
| 函数 | 描述 |
|---|---|
| JSON_APPEND() | 在JSON文档中追加数据 |
| JSON_INSERT () | 在JSON文档中插入数据 |
| JSON_REPLACE () | 替换JSON文档中的数据 |
| JSON_REMOVE () | 从JSON文档的指定位置移除数据 |
| JSON_CONTAINS() | 判断JSON文档中是否包含某个数据 |
| JSON_SEARCH() | 查找JSON文档中给定字符串的路径 |
6.其他函数
| 函数 | 描述 |
|---|---|
| DATABASE() | 返回当前数据库名 |
| VERSION() | 返回当前MySQL的版本号 |
| USER() | 返回当前登录的用户名 |
| INET_ATON(IP) | 返回IP地址的数字表示 |
| INET_NTOA | 返回数字代表的IP地址 |
| PASSWORD(str) | 实现对字符串str的加密操作 |
| FORMAT(num, n) | 实现对数字num的格式化操作,保留n位小数 |
| CONVERT(data, type) | 实现将数据data转换成type类型的操作 |
-- 单行函数
-- 字符串函数 substring() 从所索引1开始
select ename ,length(ename),substring(ename,2,3) from emp;
-- 数值函数 ceil()向上取整 floor()向下取整 round()四舍五入后的值
select abs(-5),ceil(5.4),floor(4.6),round(3.14) from dual
select round(3.5);
select RAND();
select 10/3,10%3,mod(-10,3) from dual; -- dual 伪表
-- 时间和日期函数
select * from student
desc student
select curdate(),curtime()
select now(),sysdate(),sleep(3),now(),sysdate() from dual
insert into student values(null,"xiaohua",'女',18,'java01',sysdate(),'xas@cc.com')
insert into student values(null,"xiaohei",'女',18,'java01',now(),'xas@cc.com')
update student set enterdate = now() where sno=13
-- 流程函数
-- if else
select empno,ename,sal,if(sal>=266,'high','low') as grade from emp ORDER BY grade;
-- if
select empno,ename,sal,comm,sal+ifnull(comm,0) from emp;
-- 如果value1等于value2,则返回null,否则返回value1
select nullif(1,1),nullif(1,2),nullif(3,2)
-- case 等值判断 switch
select * from emp;
select empno,ename,job,
case job
when 'CLERK' then '店员'
when 'SALESMAN' then '销售'
when 'MANAGER' then '经理'
else '其他'
end 职位,sal
from emp;
-- case 判断 if-else if-else if- else
select empno,ename,job,sal,
case
when sal<1000 then 'A'
when sal<=3000 then 'C'
when sal>3000 then 'B'
else 'D'
end 等级
from emp;
多行函数
| 函数 | 描述 |
|---|---|
| COUNT() | 统计表中记录的数目 |
| SUM() | 计算指定字段值的总和 |
| AVG() | 计算指定字段值的平均值 |
| MAX() | 统计指定字段值的最大值 |
| MIN() | 统计指定字段值的最小值 |
-- 多行函数
select max(sal),min(sal),count(sal),sum(sal),avg(sal) from emp;
-- 函数的作用 : 提高 select 查询数据的能力
-- 函数不会修改数据库表的数据
-- 区别1: 是对单行还是多行操,而不是只结果有几行
-- 区别2:除了多行函数(max(sal),min(sal),count(sal),sum(sal),avg(sal)),都是单行函数
select * from emp;
select max(sal),min(sal),count(sal),sum(sal),avg(sal) from emp;
-- 多行函数会自动忽略 null 值
select max(comm),min(comm),count(comm),sum(comm),avg(comm) from emp;
select max(ename),min(ename),count(ename),sum(ename),avg(ename) from emp;
-- 统计记录数
select count(*) from emp
select count(1) from emp;
select 1 from dual -- 伪表
select 1 from emp
group by 和 having 子句
-
select语句的执行顺序:
from–where – group by– select-having- order by
-
where子句和having子句的联系和区别
联系: 都是筛选记录
区别:
where 行级过滤
having 组级过滤
where是group by 之前,having是group by之后 where不能出现多行函数,having中可以出现多行函数
-- 统计各个部门的平均工资(只显示平均工资2000以上的)
select deptno,avg(sal),count(1)
from emp
group by deptno
having avg(sal)>2000
order by max(sal)
select * from emp order by job
多表查询
内连接询
一条SQL语句查询多个表,得到一个结果,包含多个表的数据。效率高。在SQL99中,连接查询需要使用join关键字实现
提供了多种连接查询的类型: cross(交叉连接) natural(自然连接) using on
-- 内连接 inner join
-- 交叉连接 croos join
select *
from emp
join croos dept
-- 迪卡尔积,没有实际意义,有理论意义
select *
from dept
join croos emp
-- 自然连接 natural join
-- 优点:简单强大
-- 特点:自动匹配所有的同名列
-- 自然连接缺点:自动匹配所有的同名列,无法实现只匹配部分同名列
select empno,ename,deptno,dname
from emp
natural join dept
-- 缺点 没有指明字段所属表效率低
-- 解决 指明表
select emp.empno,emp.ename,emp.deptno,dept.deptno,dept.dname
from emp
natural join dept
-- 缺点 表名长
-- 解决 别名
select e.empno,e.ename,e.deptno,d.deptno,d.dname
from emp e
natural join dept d
select e.empno,e.ename,e.deptno,d.deptno,d.dname
from emp as e
natural join dept as d
-- 自然连接缺点:自动匹配所有的同名列,无法实现只匹配部分同名列
-- 解决 using 子句
-- using缺点 : 如果关联列外键字段,但是同名不同
select e.empno,e.ename,e.deptno,d.deptno,d.dname
from emp e
join dept d
using(deptno)
-- on 子句
select e.empno,e.ename,e.deptno,d.deptno,d.dname
from emp e
join dept d
on (d.deptno=e.deptno)
-- 连接查询的类型:cross、natural、using、on
-- 该选择哪一种 ,on子句实用范围最广,可读性更强,建议多使用
-- 条件
-- 筛选条件 where having
-- 连接条件 on using natural
-- SQL99中筛选条件和连接条件分开
外连接查询
左外连接 left outer join 显示匹配的数据和左边表的不匹配的数据
右外连接 right outer join 显示匹配的数据和右边表的不匹配的数据
全外连接 full outer join 显示匹配的数据,和左、右边表的不匹配的数据,MySQL不支持全外连接,所以只能采取关 键字UNION来联合左、右连接的方法
1.外连接和内连接的区别
内连接:只显示匹配的数据
外连接:显示匹配的数据,还显示(部分或者全部)不匹配的数据
-- 外连接 outer join 除了显示匹配的数据之外,还可以显示不匹配的数据
-- 左外连接 left outer join
-- 除了显示匹配的数据 还要显示左表的不匹配数据(显示左表的所有数据)
select *
from emp e
left outer join dept d
on (e.deptno = e.deptno)
-- 右外连接 right outer join
-- 除了显示匹配的数据 还要显示右表的不匹配数据(显示右表的所有数据)
select *
from emp e
right outer join dept d
on (e.deptno=e.deptno )
-- 全外连接 full outer join
-- 除了显示匹配的数据 还要显示左表、右表的不匹配数据(显示左表、右表的所有数据)
-- 目前位置MySQL 不支持 全外连接
select *
from dept d
full join emp e
on (e.deptno = e.deptno)
-- 并集
select *
from emp e
left join dept d
on (e.deptno = e.deptno)
union -- 并集 除去重复
select *
from emp e
right join dept d
on (e.deptno = e.deptno)
select *
from emp e
left join dept d
on (e.deptno = e.deptno)
union all-- 并集 不除去重复
select *
from emp e
right join dept d
on (e.deptno = e.deptno)
-- union all 效率 union 效率低
-- 如果没有去重的要求,建议使用union all
-- MySQL的集合查询功能比较弱
三表查询
-- 查询员工的编号、姓名、薪水、部门编号、部门名称、薪水等级
select e.empno,e.ename,e.sal,d.deptno,d.dname,s.grade
from emp e
left join dept d
on e.deptno = d.deptno
join salgrade s
on e.sal between s.losal and s.hisal;
自连接查询
-- 查询员工的编号、姓名、上级编号,上级的姓名,显示没有上级的员工(董事长)
-- 一个表分为2 个表
select e.empno,e.ename,e.mgr,m.ename 上级
from emp e -- 下级表
join emp m -- 上级表
on e.mgr=m.empno
不相关子查询
一条SQL语句含有多个select,先执行子查询,再执行外查询;子查询可以独立运行。称为不相关子查询
单行子查询
-- 查询[和CLARK同一部门且比他工资低的]雇员名字和工资
select ename,sal,deptno from emp where
deptno = (select deptno from emp where ename ='CLARK') and sal<(select sal from emp where ename='CLARK');
多行子查询
-- 多行子查询
-- 查询[工资低于任意一个“CLERK”的工资的]雇员信息。 -- ANY?
select * from emp where sal<any(select sal from emp where job='CLERK') and job!='CLERK'
select * from emp where sal<any(select max(sal) from emp where job='CLERK') and job!='CLERK'
-- 查询[工资比所有的“SALESMAN”都高的]雇员的编号、名字和工资。-- ALL
select * from emp where sal> all(select sal from emp where job ='SALESMAN')
select * from emp where sal> (select max(sal) from emp where job ='SALESMAN')
-- 查询[部门20中职务同部门10的雇员一样的]雇员信息。 IN
select *from emp where deptno =20 and job in (select job from emp where deptno =10)
select *from emp where deptno =20 and job any (select job from emp where deptno =10)
相关子查询
好处:简单 功能强大(一些使用不相关子查询不能实现或者实现繁琐的子查询,可以使用相关子查询实现)
缺点:稍难理解
-- 查询本部门最高工资的员工
select * from emp e
where sal=(select max(sal)from emp where deptno=e.deptno)
-- 查询[工资高于其所在岗位的平均工资的]那些员工??
select * form emp e where e.job ='CLERK' and sal>(select avg(sal)from emp where job ='CLERK')
select * form emp e where e.job ='SALESMAN' and sal>(select avg(sal)from emp where job ='SALESMAN')
select * form emp e where e.job ='MANAGER' and sal>(select avg(sal)from emp where job ='MANAGER')
select * from emp e where sal>=(select avg(sal)from emp where job = e.job) order by job
-- 查询每个部门平均薪水
select dsa.*,sg.grade
from(select deptno,avg(sal) asl from emp
group by deptno) dsa
join salgrade sg
on (dsa.asl between sg.losal and sg.hisal)
1.相关子查询 和 不相关子查询区别?
不相关的子查询:子查询可以独立运行,先运行子查询,再运行外查询
相关子查询:子查询不可以独立运行,并且先运行外查询,再运行子查询
索引
1.什么是索引
例如汉字词典的查找 需要通过检字法(拼音,部首),加快查找速度
2.索引的作用
提高了查询的速度
3.索引占用空间吗?
占用空间,但是空间小;能够带来速度的明显提升
4.索引是不是越多越好?
不是
索引也占用空间,多个索引就好占用更多的空间;给经常需要用到的内容建立索引,否则会查询建立了索引,占用了 空间,但是很少使用
索引会提高查询的速度,但是会降低添加,更新,删除的速度(不仅操作数据库表,也要操作索引)
5.一般给那些建立索引
经常出现在where子句中的或者order by子句中的列建立索引
来源:oschina
链接:https://my.oschina.net/u/4350591/blog/4946548