
估计有人会说小Dream在偷懒。词向量,网上百度一大把的东西,你还要写。在我看来,词向量在自然语言处理中是非常重要的一环,虽然他在一开始就没有受到大家的重视,但是在神经网络再度流行起来之后,就被当作是自然语言处理中奠基式的工作了。另一方面,网上词向量相关的文章,大多是抄来抄去,能够深入浅出,讲的通俗而又不失深度的少之又少。最后,为了这个系列的系统性和完整性,我还是决定好好讲一下词向量,这个非常基础却又重要的工作。
1.文本向量化
首先,我们提出这样一个问题,一个文本,经过分词之后,送入某一个自然语言处理模型之前该如何表示?例如,“人/如果/没用/梦想/,/跟/咸鱼/还有/什么/差别”,向机器学习模型直接输入字符串显然是不明智的,不便于模型进行计算和文本之间的比较。那么,我们需要一种方式来表示一个文本,这种文本表示方式要能够便于进行文本之间的比较,计算等。最容易想到的,就是对文本进行向量化的表示。例如,根据语料库的分词结果,建立一个词典,每个词用一个向量来表示,这样就可以将文本向量化了。
2.词袋模型
要讲词向量,我们首先不得不说的就是词袋模型。词袋模型是把文本看成是由一袋一袋的词构成的。例如,有这样两个文本:
(1)“人/如果/没有/梦想/,/跟/咸鱼/还有/什么/差别”
(2)“人生/短短/几十/年/,差别/不大/,/开心/最/重要”
这两个文本,可以构成这样一个词典:{“人”,“如果”,“没有”, “梦想”, “,”,“跟”, “咸鱼” , “还有”,“什么”, “差别”, “人生”, “短短”, “几十”,“年”, “不大”, “开心”, “最”, “重要”}
字典的长度为18,每个词对应有一个index,所以,
词“人”可以用一个18维的向量表示表示:
{1,0,0,0,····,0}
词“重要”可以用一个18维的向量表示表示:
{0,0,0,0,····,1},
那么,文本该怎么表示呢?词袋模型把文本当成一个由词组成的袋子,记录文本中包含各个词的个数:
文本1:
{1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0, 0}
文本2:
{0,0,0,0,2,0,0,0,0,1,1,1,1,1,1,1,1,1}
我们大概总结一下,词袋模型把文本看成是一个装着词的袋子,以文本2为例,用词袋模型可以这样描述它。文本2里有0个“人”,2个“,”, 1个“差别” 等等。所以词袋模型有以下特点:
(1).文本向量化之后的维度仅与词典的大小相关;
(2).词袋模型没有考虑词语之间的顺序关系。
这只是两个句子,所以词典的大小是18。当语料库很大时,词典的大小可以时几千甚至几万,这样大维度的向量,计算机很难去计算。而且就算是只有一个词的句子,它的维度仍然是几千维,存在很大的浪费。此外,词袋模型忽略了词序信息,对语义理解来讲是一个极大的信息浪费。最后,词袋模型会造成语义鸿沟现象,即两个表达意思很接近的文本,可能其文本向量差距很大。
所以,词袋模型并不是一个好的解决方案。接下来,词向量就“粉墨登场”了。
2.词向量
要说词向量,就得先说一说神经网络语言模型(NNLM)。因为最开始,词向量其实是神经网络语言模型的副产品。
随着互联网的发展,在互联网上堆积了大量的文档、语料数据。在本世纪初,一个NLP界的大牛Yoshua Bengio在其经典论文《A Neural Probabilistic Language Model》中介绍了如何利用互联网上海量的未标注数据来训练一个NNLM,并产生了一个很有用的副产品,词向量。我这里尽量简明的阐述NNLM的原理及其结构。上一节我们讲了语言模型,在语言模型中,最主要的就是构建如下的概率:
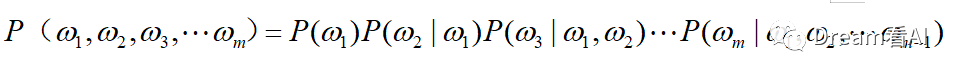
在NNLM中,需要构建如下的概率:
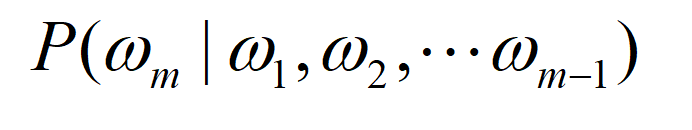
即根据句子的前面m-1个词,预测下一个词。下面我们看看NNLM中用到的神经网络的结构:
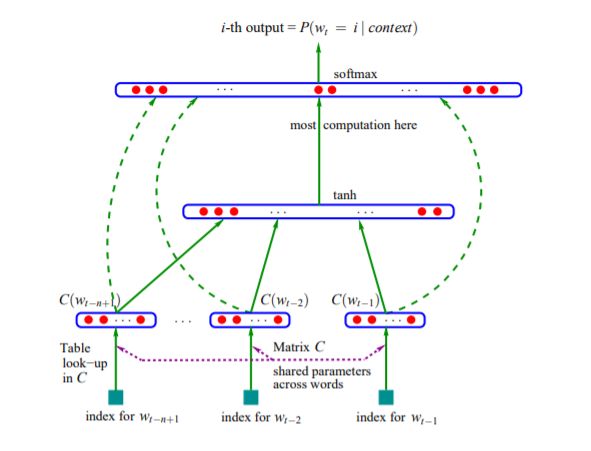
该图来源于Bengio的论文,根据该图,预测下一个词需要进行如下几步的运算:
(1)找到前n-1个词在词典中的index,并根据look-up table获得这n-1个词的词向量(训练之前,词向量是随机初始化的,维度可开发者自己定义),假设维度为d。
(2)将前n-1个词的词向量拼接起来 ,这个时候,得到一个(n-1 ,d)维的矩阵x:
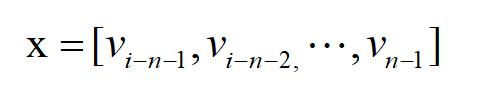
(3)经过一层神经网络,注意这里w的维度维(h, ((n-1)*d)):
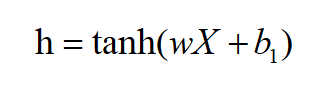
(4)经过一个全连接层,注意这里U的维度为(V, h),其中V为此表的大小,所以这里输出y的尺寸为V*1:
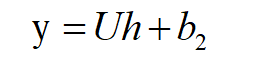
(5)最后,当然是接一层softmax,计算出词表中每一个词是一下个词的概率了。
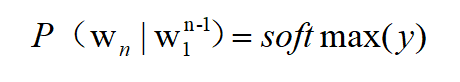
(6)当然,训练的时候,要构造损失函数:
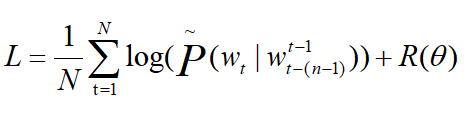
其中,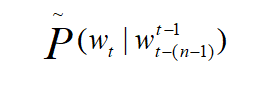 为预测出来的真正下一个词概率,R为正则项,用于训练时减轻过拟合。N代表一次训练输入词的个数。
为预测出来的真正下一个词概率,R为正则项,用于训练时减轻过拟合。N代表一次训练输入词的个数。
最后,通过反向传播更新v,训练结束之后就可以获得词向量了。
讲到这里,其实词向量的基本理论已经讲的差不多,大家应该也基本能够知道词向量是个什么样的东西,以及如何在机器学习中使用它。
其实,这只是词向量早期的工作,后期出来专门用来训练词向量的方法,包括GLOVE和word2Vec,word2vec是google的工作,word2vec有一篇非常好的blog:http://www.cnblogs.com/peghoty/p/3857839.html,大家可以参考,我这里就不再赘述了。
---------------------------------------------------------------------------
有时候,生活最残酷的一点在于,你费劲心思却始终无法把你在乎的人留在身边。愿那些漂泊无依的打拼者们,最后,深夜回家时都有人为你留一掌温暖的灯。

来源:oschina
链接:https://my.oschina.net/u/4309822/blog/3621824