内容简介
- 第一,对某银行某次营销活动受众客户的特征进行了描述性统计,考察了营销活动的总体效果;同时还进行了特征间的相关性分析,筛选掉了与响应行为之间没有显著相关性的特征。
- 第二,分别考察了存款和个贷客户在年龄、年收入等6个特征上的分布情况,分析了存款和个贷客户的自然属性和消费行为特征,并据此构建了存款客户画像和个贷客户画像。
- 第三,运用Apriori关联规则算法分析了各类业务之间的关联,并重点总结出了存款客户中潜在个贷客户的特征。
- 第四,根据以上分析结果尝试为该银行扩大各类业务客户基数,提高获客能力提出建议。
- 最后,根据分析出的个贷客户画像对客户是否办理个贷业务进行建模,得出最优分类器;当有新的客户数据时便可以使用该模型对客户办理个贷业务的可能性进行预测。
关键词:Python,客户画像,二分类,关联分析
一、项目描述
1、项目说明
(1)数据来源:本项目所用数据来源于kaggle平台,该数据集展示了某银行某年一次贷款营销活动的5,000条客户信息记录。
(2)使用工具:本项目的分析和可视化都是使用Python完成的,但相关性分析用到了SPSS。
(3)数据描述:数据字典如下所示:
表1 数据字典

2、业务需求
2.1 业务背景
某银行是一家客户群不断增长的银行,但其贷款业务的客户基数较小,因此该银行希望能够将存款用户转化为贷款用户,扩大贷款业务量,贷部于2016年针对部分客户开展了一次推广个人贷款业务的营销活动,并希望通过数据分析识别出办理个贷业务的潜在客户。
2.2 提出问题
(1)该次营销活动的受众客户中有多少办理了该行的有关业务,各类业务的获客情况如何?
(2)办理了存款和个贷业务的客户分别具备什么样的共性特征。
(3)存款客户到个贷客户的转化率有多少,具备怎样特征的存款客户能够有效转化成个贷客户。
(4)根据个贷客户画像对客户是否办理个贷业务进行建模。
二、数据清洗与预处理
导入库并预览数据
查看字段名的规范性

将字段名修改为中文名

查看各字段类型

修正ID字段的类型
![]()
删除邮编字段
![]()
删除重复记录
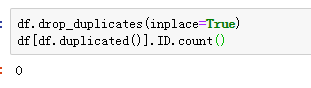
对数值型字段进行描述性统计,并查看异常值
分析:
(1)连续型特征:年龄和工作经验的均值与中值位数比较接近,说明二者分别比较均匀,但它们的标准差不低,说明年龄和工作经验的分布比较广;年收入、月均信用卡消费额和押品价值的均值都比中位数高,说明它们都是呈右偏分布,存在极大值;其中年收入和押品价值标准差非常大,右偏程度很高;尤其是押品价值的中位数为0,可见50%以上的客户没有住房抵押。
(2)类别型特征:从5个二分类字段的均值可以得出,办理了信用卡业务的客户数占抽样所得客户总数的比例约为29.40%;办理了个贷业务的客户占比约为9.60%;办理了证券业务的客户占比约为10.44%;办理了存款业务的客户占比约为6.04%;使用网上银行的客户占比约为59.68%。
现将工作经验字段为负数的记录另存并删除,便于接下来的描述性统计分析
查看各字段的缺失值数量
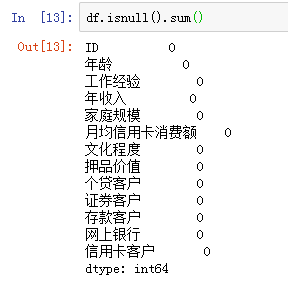
可见不存在缺失值
三、特征总体分析
1、分类型特征
1.1 描述性统计:频数和比例
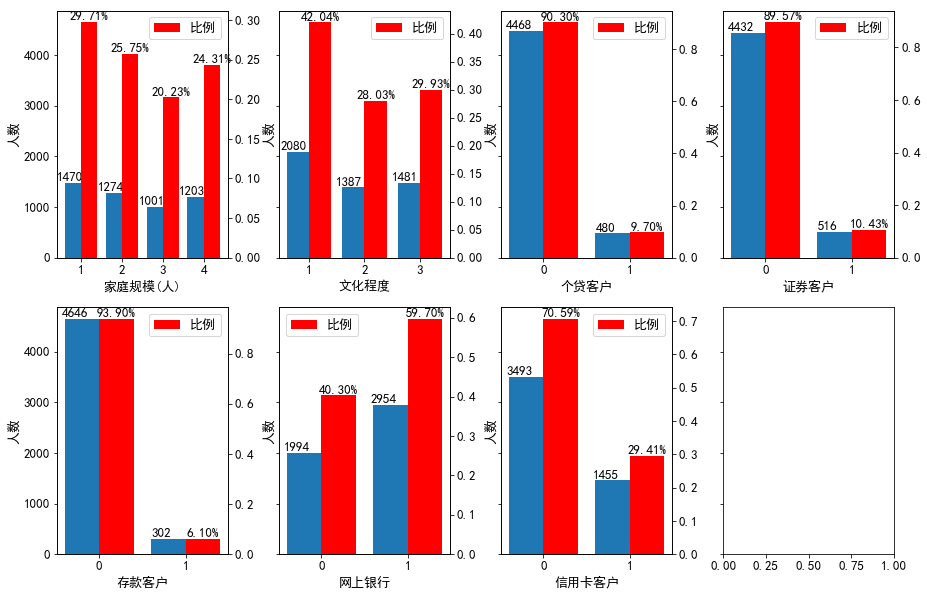
分析:
(1)家庭规模方面:家庭规模为1人,即单身的客户最多;客户次多的家庭规模从高到低依次是2人、4人、3人;但这四种家庭规模的客户数量彼此差异不大,占客户总数的比例都在20%-30%之间,分布比较均匀。
(2)文化程度方面:本科学历以下的客户最多,但文化程度在本科毕业及以上的客户数合计占比超过了一半,可见该行客户以受过大学本科教育的客户为主。
(3)响应行为方面:未办理个贷、证券、存款和信用卡业务的客户要远多于办理了相应业务的客户,可见该次营销活动的受众中只有很少一部分办理过该行的有关业务。
1.2 相关性分析
(1)通过SPSS借助皮尔逊卡方独立性检验对各分类型字段之间的相关性进行分析,得到检验结果的显著水平如下:
表 皮尔逊相关性检验
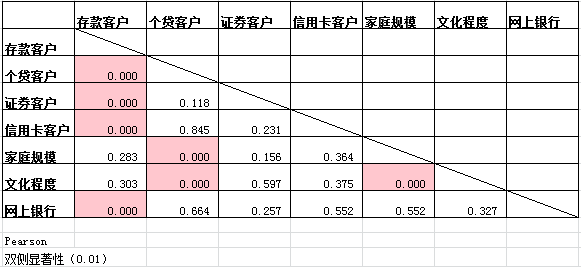
(2)通过皮尔逊相关性检验可以得出,家庭规模和文化程度与是否为存款客户之间没有显著相关性;是否为证券客户、是否为信用卡客户、是否使用网上银行与是否为个贷客户之间没有显著相关性;是否为证券客户与是否为信用卡客户、家庭规模、文化程度和是否使用网上银行之间没有显著相关性;是否为信用卡客户与家庭规模、文化程度、网上银行之间没有显著相关性。
(3)基于上述Pearson相关性检验的结果,在分析客户画像时将不考虑与响应行为之间没有显著相关性的特征,即在分析存款客户画像时,将不考虑”家庭规模“和”文化程度“特征;在分析个贷客户画像时,将不考虑”证券客户“、”信用卡客户“和”网上银行“三个特征。
2、连续型特征:数值分布于相关性分析
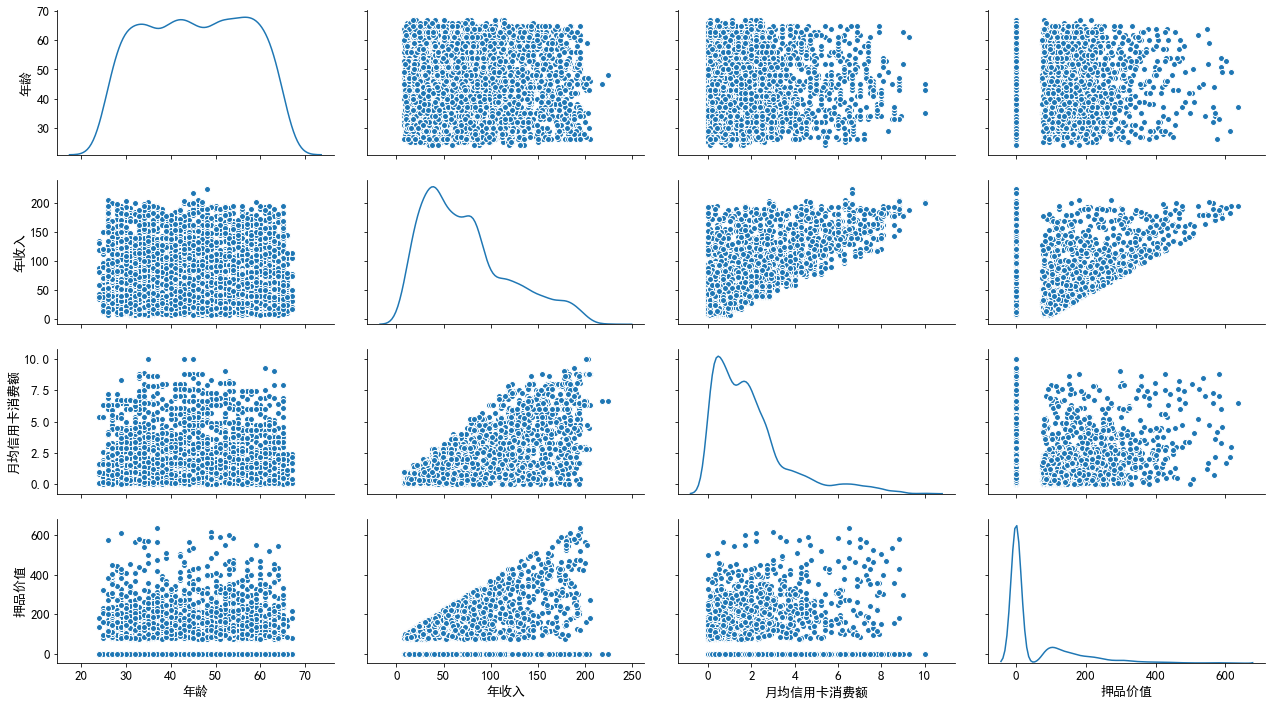
2.1 矩阵散点图

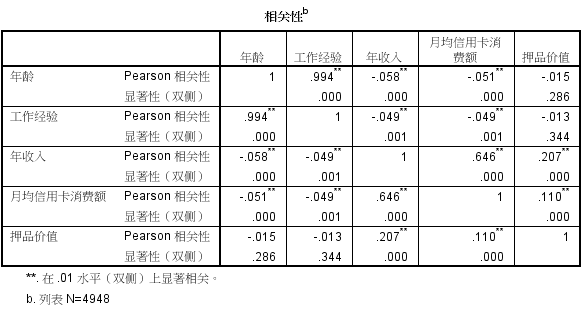
2.2 皮尔逊相关系数矩阵
通过SPSS借助因子分析得到各连续型特征之间的皮尔逊相关系数,如下所示
分析:
(1)数值分布分析:该行客户总体上年龄集中在30岁到60岁之间,但36和46岁的客户要比相邻年龄的客户少一些;工龄集中在7到34年;年收入集中在4万到7.5万美元间;月均信用卡消费额集中在0.5到2千美元间;押品价值集中在0值上,说明绝大部分客户没有住房抵押,但押品价值的核密度在100万美元处有一个极值,说明有住房抵押的客户大部分押品价值都在10万美元左右。
(2)相关性分析:由相关性矩阵和散点图可以看出,年龄与年收入(r=-0.058,p=0.000<0.05)以及月均信用卡消费额(r=-0.051,p=0.000<0.05)之间的相关性较弱;工作经验与年龄具有较高的正相关性(r=0.994,p=0.000<0.05),而与年收入(r=-0.049,p=0.001<0.05)和月均信用卡消费额(r=-0.049,p=0.001<0.05)之间的相关性较弱;年收入越高,月均信用卡消费额(r=0.646,p=0.000<0.05)和押品价值(r=0.207,p=0.000<0.05)的上限越高。
四、存贷款业务客户画像
1、存款客户画像
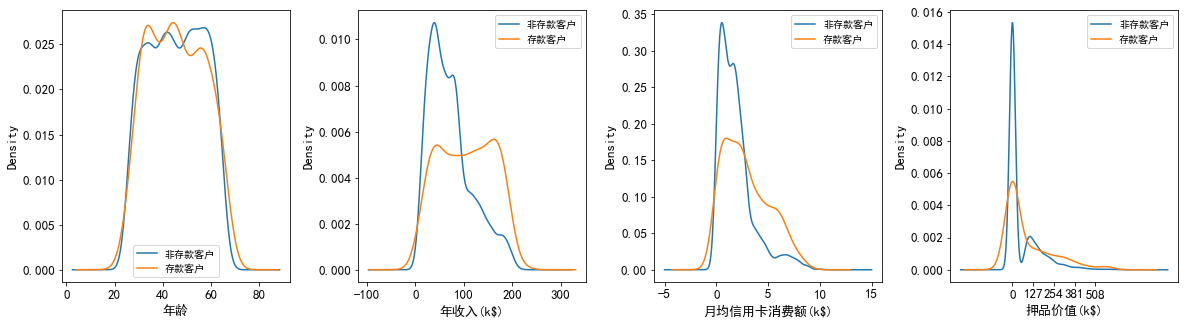
1.1 存款和非存款客户在年龄、年收入、月均信用卡消费额和押品价值上的分布差异

这里对押品价值进行分箱分析
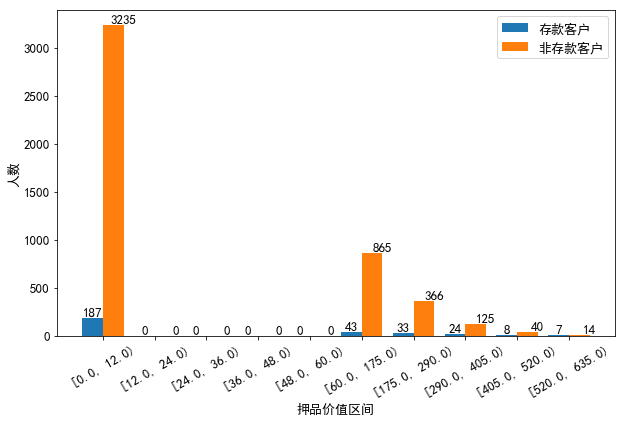
分析:
(1)在年龄的分布上:存款客户的年龄集中在33到55岁之间,这其中年龄在33岁到45岁之间的客户要多于其他年龄段的客户,可见存款客户以青中年为主。
(2)在年收入的分布上:非存款客户的年收入呈右偏分布,但整体集中在4万美元左右,说明非存款客户以中低收入为主;而存款客户的年收入分布相对广泛而均匀,集中在4万美元到16万美元之间。
(3)在月均信用卡消费额的分布上:存款和非存款客户的月均信用卡消费额都集中在1千美元左右,可见两类客户信用卡消费水平整体都不高;但存款客户的月均信用卡消费额呈右偏分布,存在高消费水平的客户。
(4)在押品价值的分布上:存款和非存款客户的押品价值都集中在0值附近,进一步对押品价值分箱处理后发现,存款和非存款客户中绝大多数都没住房抵押(押品价值为0),而有住房抵押的存款客户其押品价值在6万美元到17.5万美元间的最多,有住房抵押的非存款客户其押品价值在10万美元左右的最多(其核密度曲线在10万美元处有一极值),同时随着押品价值的升高存款和非存款客户的数量都越来越少。
1.2 存款和非存款客户在家庭规模上的分布差异
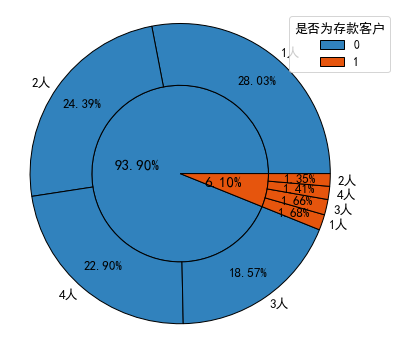
分析:家庭规模为1人,即处于单身或离异状态的客户在存款和非存款客户中的占比都是最大的;但在存款客户中家庭规模为3人和4人,即已婚且有子女的客户占比要高于家庭规模为2人即已婚但未育的客户。
2、个贷客户画像
2.1 个贷和非个贷客户在年龄、年收入、月均信用卡消费额和押品价值上的分布差异
![]()
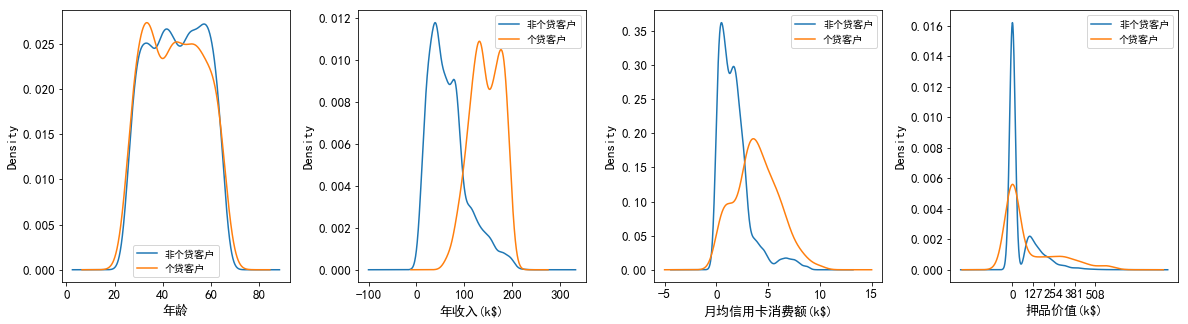
这里对押品价值进行分箱分析

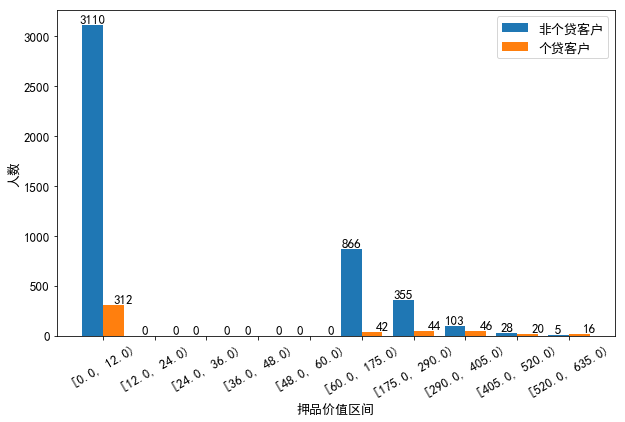
分析:
(1)在年龄的分布上:个贷客户的年龄主要集中在32岁到50岁之间,这其中32岁到38岁的客户要多于其他年龄段的客户,同时40岁左右的客户要比相邻年龄的客户少。
(2)在年收入的分布上:非个贷客户年收入呈右偏分布,但集中在4万到8万美元左右,以中低收入为主;而个贷客户的年收入分布相对均匀,集中在13万到17.5万美元间,以中高收入为主;同时在9.8万美元右侧,个贷客户的核密度曲线呈急剧上升,而非个贷客户的核密度曲线在急剧下降,可见年收入9.8万美元是个分界点,年收入高于该水平的客户更有可能办理个贷业务。
(3)在月均信用卡消费额的分布上:非个贷客户的月均信用卡消费额呈右偏分布,但集中在0.5到1.7千美元之间,消费水平整体偏低;而个贷客户的月均信用卡消费额分布相对均匀,并集中在3.5千美元左右,以中高消费水平为主。同时在2.8千美元右侧,个贷客户的核密度曲线呈急剧上升并很快达到峰值,而非个贷客户的核密度曲线呈急剧下降,可见2.8千美元是一个分界点,月均信用卡消费额高于该水平的客户更有可能办理个贷业务。
(4)在押品价值的分布上:个贷和非个贷客户的押品价值都集中在0值附近,进一步对押品价值分箱处理后发现,个贷和非个贷客户中绝大多数都没有住房抵押(押品价值为0),且个贷客户中有住房抵押的其押品价值在29万到40.5万美元之间的最多,并且当押品价值在6万到40.5万之间时,随着押品价值的升高个贷客户的数量在增多,而非个贷客户的数量在减少。
2.2 个贷和非个贷客户在信用卡还款压力上的分布差异
计算年信用卡消费额占年均收入的比重可以得出客户对信用卡的使用程度,也能反映客户信用卡的还款压力

Text(0,0.5,'核密度')
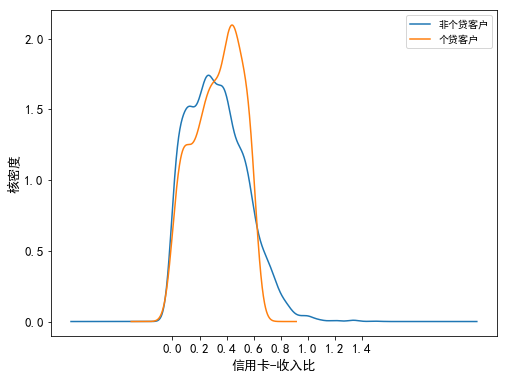
分析:非个贷客户的信用卡消费额占其收入的比重集中在20%左右,而个贷客户的信用卡消费额占其收入的比重集中在40%左右;同时,在20%到40%这一区间内,非个贷客户的核密度曲线急剧下降,而个贷客户的核密度曲线急剧上升并达到峰值,可见信用卡-收入比在30%到40%之间的客户办理个贷业务的倾向最强。但当信用卡消费额占收入的比重超过65%以后,个贷客户数量的下降幅度要大于非个贷客户,可见虽然大部分非个贷客户对信用卡的使用较为保守,但也存在小部分不理性使用信用卡的客户。
2.3 个贷和非个贷客户在家庭规模上的分布差异

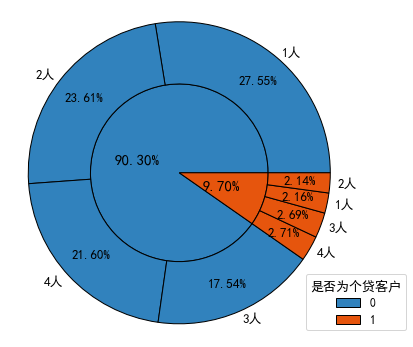
分析:非个贷客户以单身或已婚未育为主,而个贷客户则以已婚有子女为主。
2.4 个贷和非个贷客户在文化程度上的分布差异

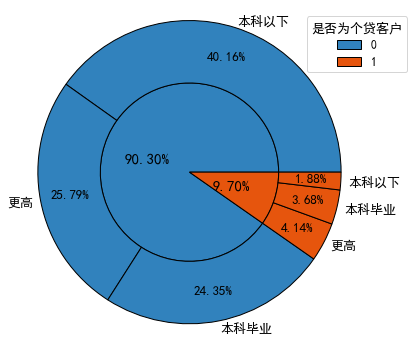
分析:文化程度在本科以下的客户在非个贷客户中占比最高,达到了44.31%(40.16%/90.30%),而在个贷客户中的占比最低,仅为19.37%(1.88%/9.70%),个贷客户中本科毕业及以上学历的客户合计约占其80.63%,可见受过大学本科教育的客户办理个贷业务的意识更强。
五、各响应行为间的关联分析
1、各类业务间的Apriori关联分析

(1)设定最小支持度为0.04,挖掘频繁项集
![]()

分析: 通过上表可知,该行同时办理信用卡和网上银行业务的客户占比约为17.74%;同时办理证券和网上银行业务的客户占比约为6.47%;同时办理个贷和网上银行业务的客户占比约为5.88%;同时办理存款和网上银行业务的客户占比约为5.72%;同时办理存款和信用卡业务的客户占比约为4.85%;同时办理存款、信用卡和网上银行业务的客户占比约为4.53%。
(2)设定最小置信度为0.7,挖掘强关联规则
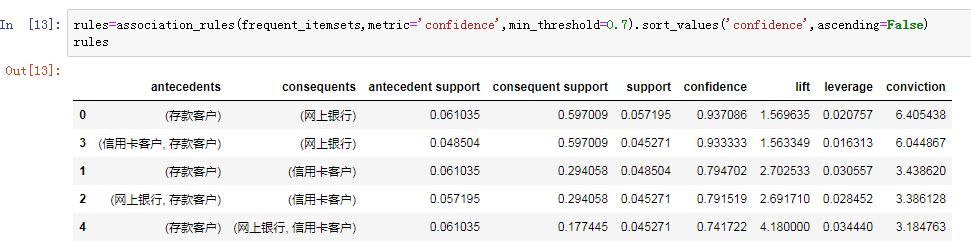
分析:
(1)通过上表可知,客户如果办理了存款业务,那么就有93.71%的概率会开通网上银行,有79.47%的概率会办理信用卡业务,有74.17%的概率会同时办理信用卡和网上银行业务;客户如果同时办理了存款和信用卡业务,那么就有93.33%的概率会开通网上银行;客户如果同时办理了存款和网上银行业务,那么就有79.15%的概率会办理信用卡业务。
(2)通过以上分析可以看出,绝大部分存款客户都会同时办理信用卡或网上银行业务,可见存款业务对这两个业务具有很好的衍生作用,但并未看到存款业务对个贷业务的衍生作用,可见该行并没有把存款客户有效地转化为个贷客户。
(3)查看存款客户中个贷客户的比例
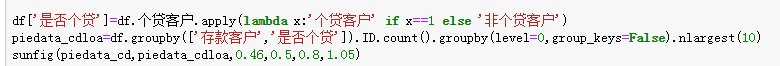
分析:存款客户中办理了个贷业务的客户占比,即该次营销活动的转化率为46.39%(2.83%/6.10%),可见超过一半的存款客户并没有办理个贷业务,因而需要挖掘存款客户中潜在个贷客户的特征,针对这部分客户进行个贷业务的精准营销,以提高存款到个贷客户的转化率。
2、存款客户中的潜在个贷客户特征
(1)既存款又个贷的客户与存款但非个贷客户在年龄、年收入、信用卡消费水平以及押品价值方面的差异

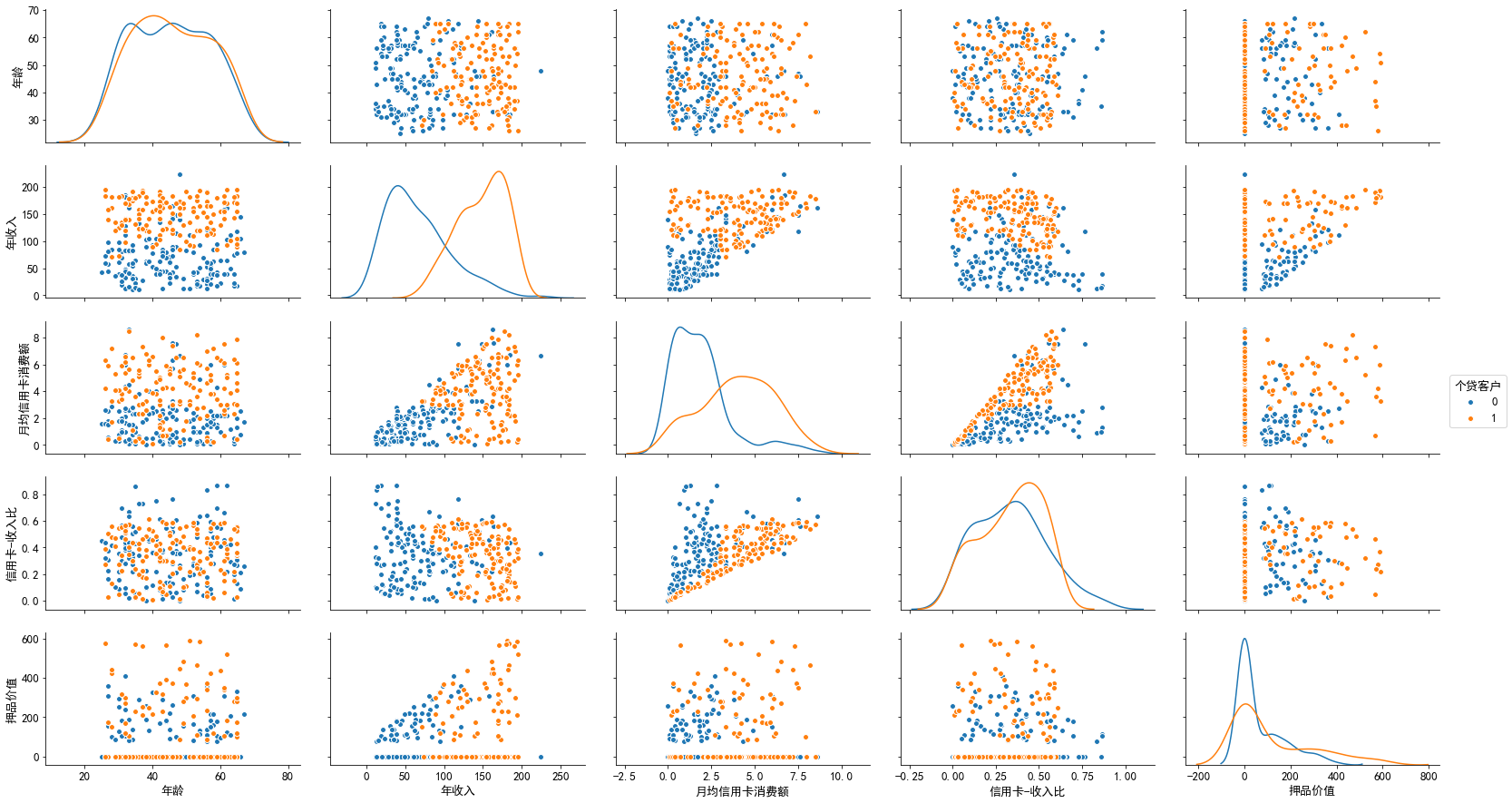
补充:对押品价值的分布进行分箱细化

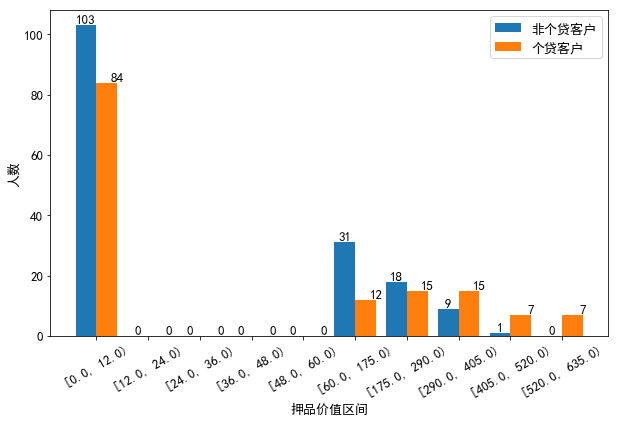
分析:从相关性矩阵散点图可以看出,存款客户中个贷和非个贷客户在年收入和月均信用卡消费额上的区分度比较高,具体来说,年收入在10.2万美元以上且月均信用卡消费额在3千美元以上的存款客户办理个贷业务的倾向非常强;在信用卡收入比方面,在0.65的水平以内二者的区分度不高,但超过0.65的水平后,非个贷的存款客户要多于个贷存款客户;在押品价值方面,存款个贷和存款非个贷客户的押品价值都集中在0值附近,进一步对押品价值分箱处理后发现,存款个贷和存款非个贷客户中绝大多数都没有住房抵押(押品价值为0),同时当押品价值高于40万美元后,存款个贷客户比存款非个贷客户要多。
(2)既存款又个贷的客户与存款但非个贷客户在家庭规模上的分布差异

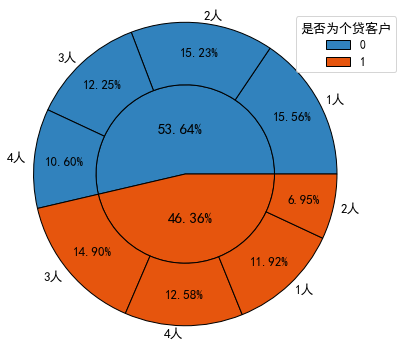
分析:存款非个贷客户以独身或已婚但未育为主,而存款个贷客户以已婚且有子女为主。
(3)既存款又个贷的客户与存款但非个贷客户在文化程度上的分布差异
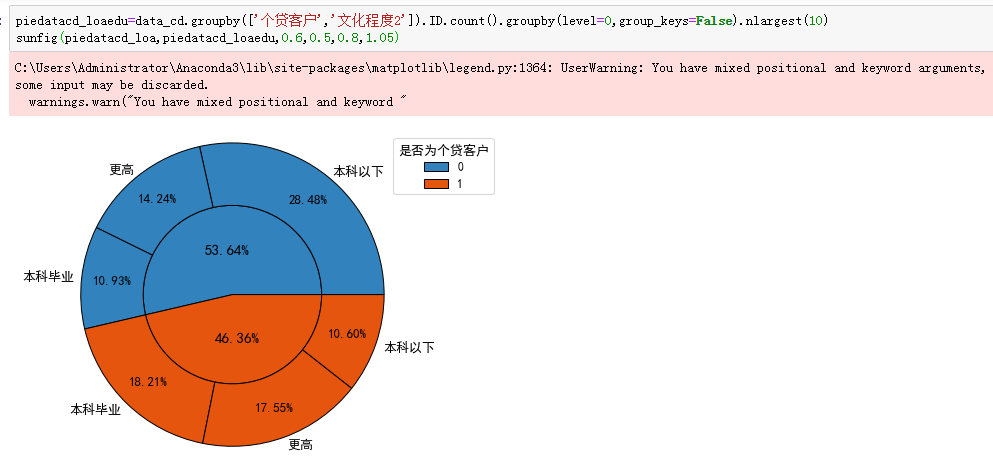
分析:存款非个贷客户的文化程度以本科以下为主,而存款个贷客户的文化程度以本科毕业及以上为主。
六、业务结论及建议
1、结论
1.1客户画像
(1)存款客户画像
1)年龄集中在33到45岁之间,以青中年为主;
2)家庭规模以单身和已婚且有子女为主;
3)年收入分布广泛,集中在4万到16万美元间;
4)信用卡消费以中低水平为主,集中在1千美元左右,但存在部分高消费水平客户;
5)绝大部分没有住房抵押,而有住房抵押的押品价值在6万到17.5万美元的最多。
(2)个贷客户画像
1)年龄集中在32到50岁之间,以青中年为主;
2)文化程度以大学本科及以上为主;
3)家庭规模以已婚且有子女为主;
4)年收入和信用卡消费都以中高水平为主(年收入在9.8万美元以上,月均信用卡消费额在2.8千美元以上);信用卡消费额占其收入比重在30%到40%之间;
5)绝大部分没有住房抵押,而有住房抵押的其押品价值集中在6万到40.5万美元间,且在这一区间内押品价值越高的客户办理个贷业务的倾向越强。
(3)存款客户中的潜在个贷客户画像
1)已婚且有子女;
2)学历在本科及以上;
3)年收入在10.2万美元以上;
4)月均信用卡消费额在3千美元以上;
5)信用卡消费额占其收入比重不超过65%;
6)押品价值高于29万美元。
1.2各类业务间的关联
绝大部分存款客户都会同时办理信用卡或网上银行业务,但同时办理个贷业务的较少,存款客户到个贷客户的转化率不高。
2、建议
(1)存款业务是该行的基础业务,对其他业务具有重要的带动和派生作用;但该次营销活动的受众中只有6.10%的客户在该行开立了存款账户,因而应进一步拓展存款业务的市场份额,扩大存款客户基数。
(2)存款客户中个贷和非个贷客户的区分度非常高,因而应充分利用和盘活存款客户,通过对其加大个贷营销力度、提供个贷优惠等方式促使其向个贷客户转化。
(3)针对绝大部分存款客户使用网上银行的习惯,可以充分利用网上银行作为平台和媒介对存款客户推送个性化的服务,诱导存款客户办理更多的相关业务。
(4)应根据客户画像进行存款和个贷业务的精准营销,以降低营销费用,提高获客效益。
七、对客户是否办理个贷业务进行建模
1、特征工程
(1)先将先前被删除的工作经验为负数的记录补回
![]()
(2)特征选择:根据前面的相关性分析和探索性分析可知,年收入、月均信用卡消费额、押品价值、家庭规模、文化程度和是否为存款客户这六个特征对客户是否办理个贷业务具有显著影响,因而选取这六个特征训练模型。
(3)特征衍生
1)根据前面的分析,年收入在9.8万美元以上、月均信用卡消费额在2.8千美元以上的客户更有可能是个贷客户,据此生成两个哑变量。

2)根据前面对存款客户到个贷客户的转化分析,满足年收入在10.2万美元以上、月均信用卡消费额在3千美元以上、押品价值在40万美元、是存款客户这四个条件中的部分或全部条件的客户更有可能是个贷客户,因而可以生成一个综合性变量,对客户满足这四个条件的程度进行赋分,得分越高的客户越有可能是个贷客户。

(4)特征转换
1)改善特征的分布

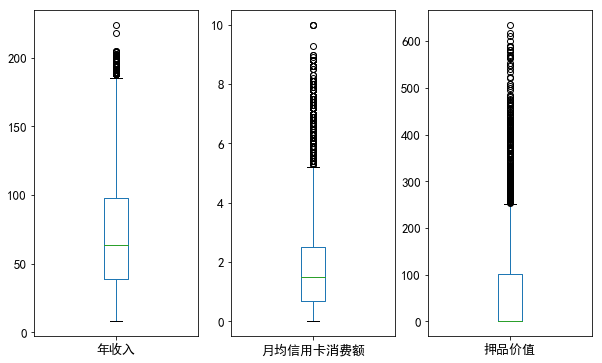
分析:通过箱线图可以看出,年收入、月均信用卡消费额和押品价值这三个字段呈明显的右偏分布,可采用对数变换修正数据倾斜,使其服从类正态分布;但由前面的描述性统计分析可知,押品价值的分布不是连续的,且虽然存在极大值但有住房抵押的客户只占少数,可以预见即使对押品价值进行函数变换也无法得到理想的效果,因而最终只对年收入和月均信用卡消费额进行对数变换,而对押品价值的分布不予处理。

2)对年收入、月均信用卡消费额和押品价值三个连续型特征进行标准化处理,消除量纲的影响,同时提高算法求解的收敛速度。

2、划分输入特征和预测特征,并拆分训练集和测试集

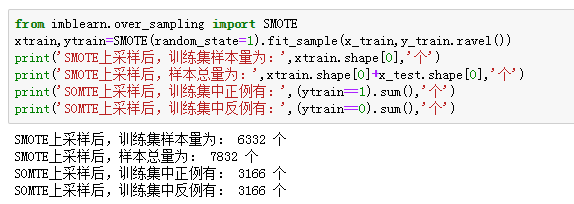
3、处理类别不平衡:数据集中个贷客户占比只有9.70%,可见存在类别不平衡问题,可采用SMOT算法进行过采样处理。
4、建模
(1)导入有关包
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import mean_squared_error,r2_score,precision_score,recall_score,f1_score,accuracy_score,confusion_matrix,roc_curve,auc,roc_auc_score,classification_report(2)定义一个集成建模过程的类
class Modeling():
def __init__(self,alg,params,cvnums):
self.alg=alg
self.name=alg.__class__.__name__
self.params=params
self.cvnums=cvnums
def grid_train_test(self,xtrain,ytrain,x_test,y_test):
grid=GridSearchCV(self.alg,self.params,cv=self.cvnums,scoring='accuracy')
grid.fit(xtrain,ytrain)
self.best_params=grid.best_params_
self.best_estimator=grid.best_estimator_
self.cv_results=grid.cv_results_
self.train_accuracy=grid.best_score_
self.best_estimator.fit(xtrain,ytrain)
self.pred_label=self.best_estimator.predict(x_test)
try:
self.pred_proba=self.best_estimator.decision_function(x_test)
except:
self.pred_proba=self.best_estimator.predict_proba(x_test)[:,1]
self.precision_score=precision_score(y_test,self.pred_label)
self.recall_score=recall_score(y_test,self.pred_label)
self.f1_score=f1_score(y_test,self.pred_label)
self.test_accuracy=accuracy_score(y_test,self.pred_label)
self.auc=round(roc_auc_score(y_test,self.pred_proba),4)
def learningcurve(self,xtrain,ytrain):
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
train_sizes,train_scores,test_scores,fit_times,_=learning_curve(self.alg,xtrain,ytrain,
cv=ShuffleSplit(n_splits=100,test_size=0.2,random_state=2),
return_times=True)
train_scores_mean=np.mean(train_scores,axis=1)
test_scores_mean=np.mean(test_scores,axis=1)
plt.rc('font',size=13)
plt.rcParams['font.sans-serif'] =['SimHei']
fig,axes=plt.subplots(1,2,figsize=(16,4))
axes[0].set_title(self.name)
axes[0].set_xlabel('训练样本数')
axes[0].set_ylabel('准确率')
axes[0].plot(train_sizes,train_scores_mean,'o-',color='r',label='训练集平均准确率')
axes[0].plot(train_sizes,test_scores_mean,'o-',color='g',label='测试集平均准确率')
axes[0].legend(loc='best')
axes[0].grid()
cv_results=pd.DataFrame(self.cv_results)
if len(self.params)==1:
CV_RESULTS=cv_results.pivot_table(values='mean_test_score',index=cv_results.columns[4])
axes[1].set_title(self.name)
axes[1].set_ylabel('准确率')
CV_RESULTS.plot(ax=axes[1],marker='o')
elif len(self.params)==2:
CV_RESULTS=cv_results.pivot_table(values='mean_test_score',index=cv_results.columns[4],columns=cv_results.columns[5])
axes[1].set_title(self.name+'_SCORE')
sns.heatmap(CV_RESULTS,annot=True,ax=axes[1])
else:
heatmap_col=[]
for i in np.arange(len(params)-1):
heatmap_col.append(cv_results.columns[5+i])
CV_RESULTS=cv_results.pivot_table(values='mean_test_score',index=cv_results.columns[4],columns=heatmap_col)
axes[1].set_title(self.name+'_SCORE')
sns.heatmap(CV_RESULTS,annot=True,ax=axes[1])
plt.subplots_adjust(wspace=0.25)(3)选取K近邻分类器、逻辑回归、支持向量机和随机森林分类器这四个模型建模
knn=Modeling(KNeighborsClassifier(),{'n_neighbors':np.linspace(1,10,10).astype('int'),'weights':['uniform','distance']},5)
knn.grid_train_test(xtrain,ytrain,x_test,y_test)
lr=Modeling(LogisticRegression(),{'C':np.linspace(0.6,1.5,10)},5)
lr.grid_train_test(xtrain,ytrain,x_test,y_test)
svm=Modeling(SVC(probability=True),{'C':np.linspace(60,100,5),'gamma':[0.22,0.24,0.26,0.28,0.30]},5)
svm.grid_train_test(xtrain,ytrain,x_test,y_test)
rf=Modeling(RandomForestClassifier(),{'n_estimators':np.linspace(50,200,4).astype('int')},5)
rf.grid_train_test(xtrain,ytrain,x_test,y_test)(4)查看并比较各模型的结果

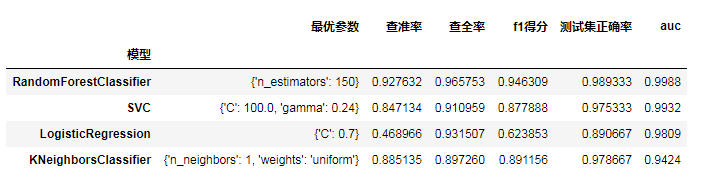
分析:可以看出,逻辑回归、支持向量机和随机森林分类器的auc都达到了0.95以上,但其中逻辑回归的查准率和预测正确率不够理想,不过这并不妨碍该模型的使用价值,因为本业务是要尽可能多得识别出潜在的个贷客户,因而相比于查准率本业务更看重查全率;而k近邻分类器虽然auc低于0.95,但其预测正确率并不低;所有模型中预测性能最好的是随机森林分类器,其f1得分和预测正确率都很高,且auc高达0.9984。
(5)绘制各模型的学习曲线

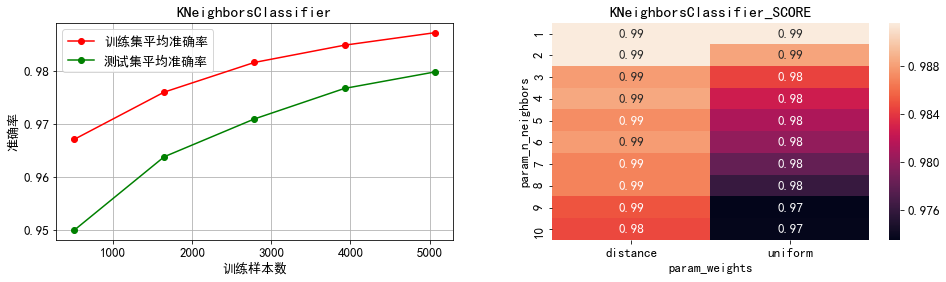
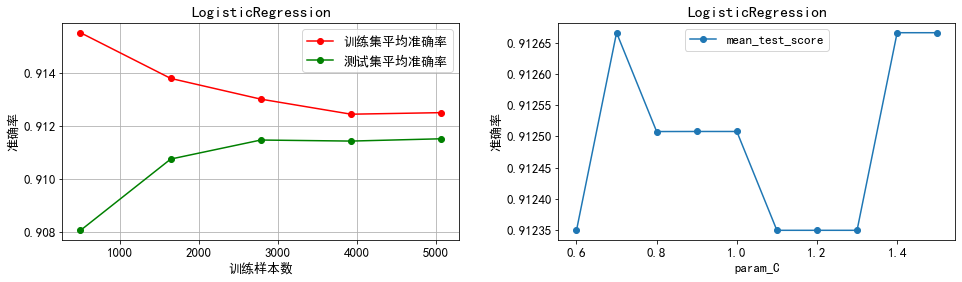
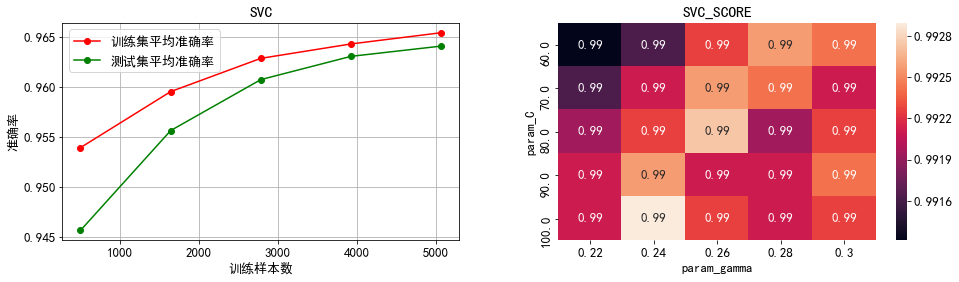
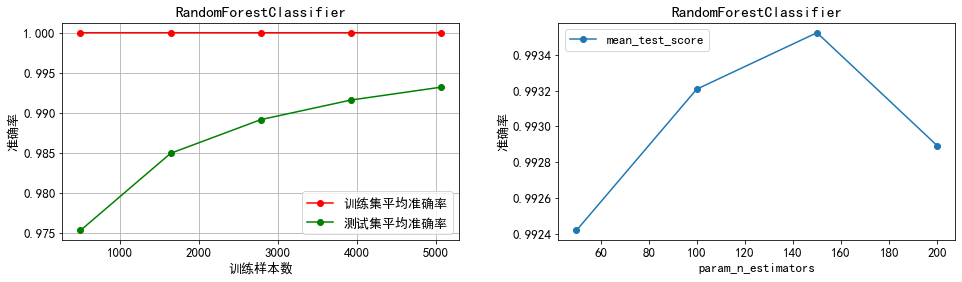
分析:
1)通过左半部分的学习曲线可以看出,在交叉验证过程中除了逻辑回归以外其余三个模型的训练集准确率都处于较高水平,尤其是随机森林模型的准确率一直维持在100%,因而可能存在一定程度的过拟合问题,推测这种过拟合主要是因为在处理类别不均衡问题时进行了过采样造成的;而逻辑回归的训练集准确率随着样本量的增加不断降低,可能存在一定程度的欠拟合问题,推测主要是因为逻辑回归模型不能很好地处理非线性可分问题,从而导致模型的学习难度随着样本量的不断增加而增大,最终造成欠拟合问题。
2)K近邻:最优近邻数为1,且通过热力图可以看出模型准确率随着近邻数的增加而下降,因而不需要再进行调参。
3)逻辑回归:最优正则化系数的倒数为1.3,且通过学习曲线可以看出模型准确率在正则化系数倒数为1.3处取到最值,因而不需要再进行调参。
4)支持向量机:通过热力图可以看出,矩阵中最优系数搭配组合(误分类惩罚系数100,核函数系数0.26)周围看不出明显的能使模型准确率提升的参数变化趋势,因而不再进一步调参。
5)随机森林分类器:最优决策树个数为100,且通过学习曲线可以看出决策树个数向100两侧变化并不能带来模型准确率的提高,因而不再进一步调参。
(6)模型融合:选取预测性能前三的逻辑回归、支持向量机和随机森林分类器采用投票评估器进行融合。

VotingClassifier的auc为:0.9964
分析:可以看出,融合后的auc没有单个模型的auc高,因而采用随机森林分类器作为最终模型。
(7)输出最优分类器
![]()
RandomForestClassifier(n_estimators=150)
本文参考知乎 @蘭珀流 的文章然后亲自验证其分析过程,期间遇到许多问题,有些运行不出结果就直接复制他的结果了。
原文来自:https://zhuanlan.zhihu.com/p/144051813?utm_source=qq&utm_medium=social&utm_oi=997993013217472512
来源:oschina
链接:https://my.oschina.net/u/4487084/blog/4443702