前言
老司机带你去看车,网上的几千条的二手车数据,只需几十行代码,就可以统统获取,保存数据到我们本地电脑上
1.python基础知识
2.函数
3.requests库
4.xpath适合零基础的同学
windows + pycharm + python3
1.目标网址
2. 发送请求,获取响应
3. 解析网页 提取数据
4. 保存数据
加企鹅群695185429即可免费获取,资料全在群文件里。资料可以领取包括不限于Python实战演练、PDF电子文档、面试集锦、学习资料等
1.导入工具
import io
import sys
import requests # pip install requests
from lxml import etree # pip
2.获取汽车详情页面的url,解析网站
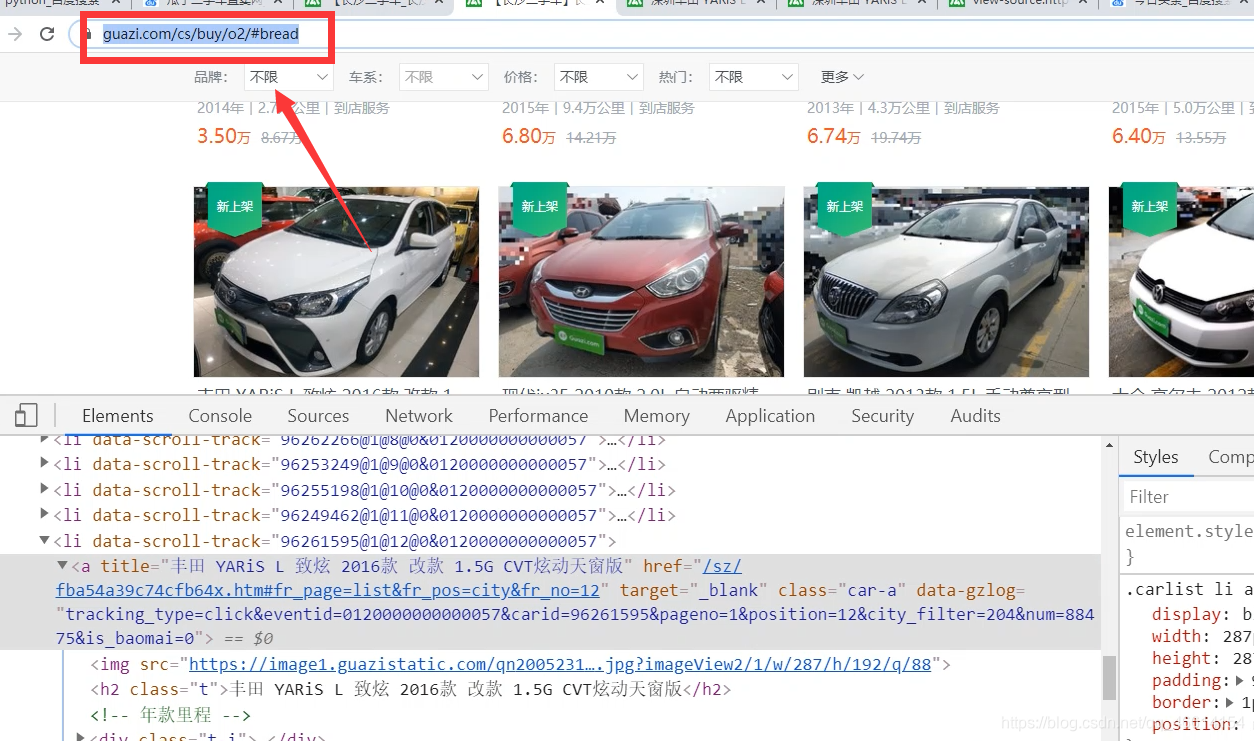
def get_detail_urls(url):
# 目标网址
# url = 'https://www.guazi.com/cs/buy/o3/'
# 发送请求,获取响应
resp = requests.get(url,headers=headers)
text = resp.content.decode('utf-8')
# 解析网页
html = etree.HTML(text)
ul = html.xpath('//ul[@class="carlist clearfix js-top"]')[0]
# print(ul)
lis = ul.xpath('./li')
detail_urls = []
for li in lis:
detail_url = li.xpath('./a/@href')
# print(detail_url)
detail_url = 'https://www.guazi.com' + detail_url[0]
# print(detail_url)
detail_urls.append(detail_url)
return detail_urls
3.添加请求头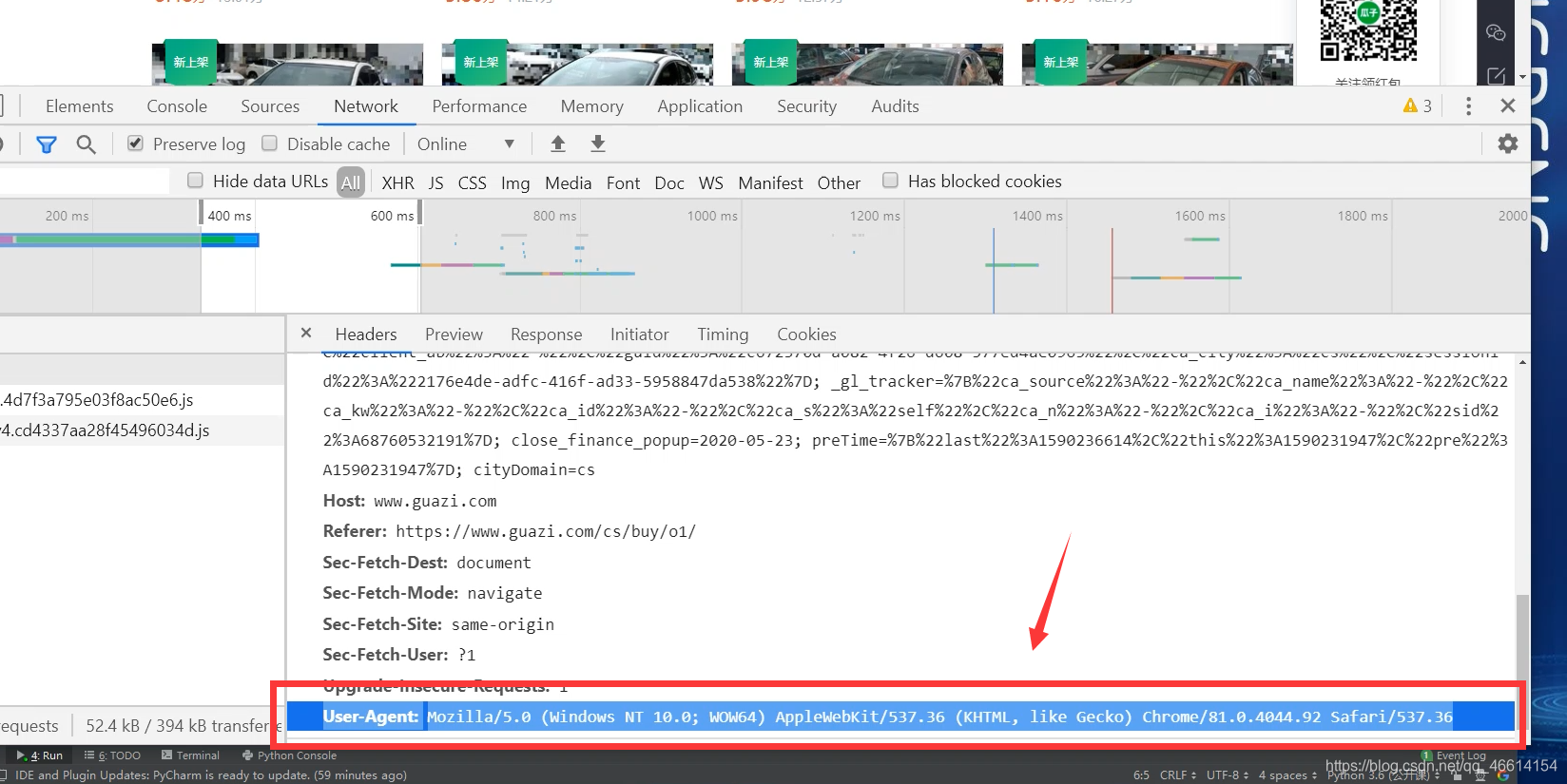
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',
'Cookie':'uuid=5a823c6f-3504-47a9-8360-f9a5040e5f23; ganji_uuid=4238534742401031078259; lg=1; Hm_lvt_936a6d5df3f3d309bda39e92da3dd52f=1590045325; track_id=79952087417704448; antipas=q7222002m3213k0641719; cityDomain=cs; clueSourceCode=%2A%2300; user_city_id=204; sessionid=38afa34e-f972-431b-ce65-010f82a03571; close_finance_popup=2020-05-23; cainfo=%7B%22ca_a%22%3A%22-%22%2C%22ca_b%22%3A%22-%22%2C%22ca_s%22%3A%22pz_baidu%22%2C%22ca_n%22%3A%22pcbiaoti%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22-%22%2C%22ca_content%22%3A%22%22%2C%22ca_campaign%22%3A%22%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22scode%22%3A%22-%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%22-%22%2C%22ca_transid%22%3A%22%22%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22track_id%22%3A%2279952087417704448%22%2C%22display_finance_flag%22%3A%22-%22%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%225a823c6f-3504-47a9-8360-f9a5040e5f23%22%2C%22ca_city%22%3A%22cs%22%2C%22sessionid%22%3A%2238afa34e-f972-431b-ce65-010f82a03571%22%7D; preTime=%7B%22last%22%3A1590217273%2C%22this%22%3A1586866452%2C%22pre%22%3A1586866452%7D',
}
4.提取每辆汽车详情页面的数据
def parse_detail_page(url):
resp = requests.get(url,headers=headers)
text = resp.content.decode('utf-8')
html = etree.HTML(text)
# 标题
title = html.xpath('//div[@class="product-textbox"]/h2/text()')[0]
title = title.strip()
print(title)
# 信息
info = html.xpath('//div[@class="product-textbox"]/ul/li/span/text()')
# print(info)
infos = {}
cardtime = info[0]
km = info[1]
displacement = info[2]
speedbox = info[3]
infos['title'] = title
infos['cardtime'] = cardtime
infos['km'] = km
infos['displacement'] = displacement
infos['speedbox'] = speedbox
print(infos)
return infos
5.保存数据
def save_data(infos, f):
f.write('{},{},{},{},{}\n'.format(infos['title'],infos['cardtime'],infos['km'],infos['displacement'],infos['speedbox']))
if __name__ == '__main__':
base_url = 'https://www.guazi.com/cs/buy/o{}/'
with open('guazi.csv','a',encoding='utf-8') as f:
for x in range(1,51):
url = base_url.format(x)
detail_urls = get_detail_urls(url)
for detail_url in detail_urls:
infos = parse_detail_page(detail_url)
save_data(infos, f)
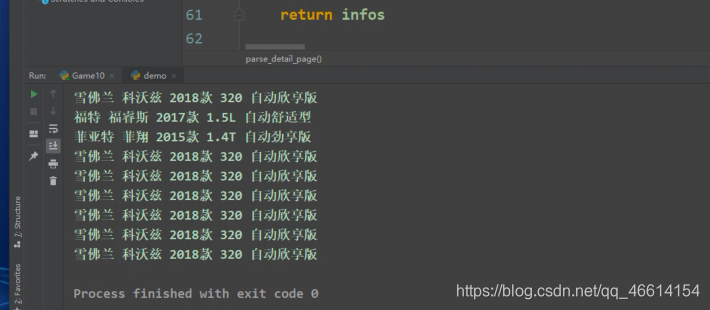
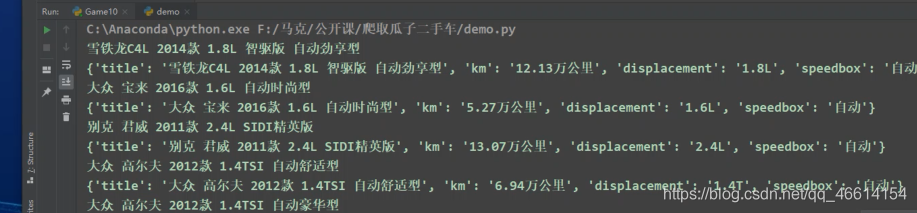
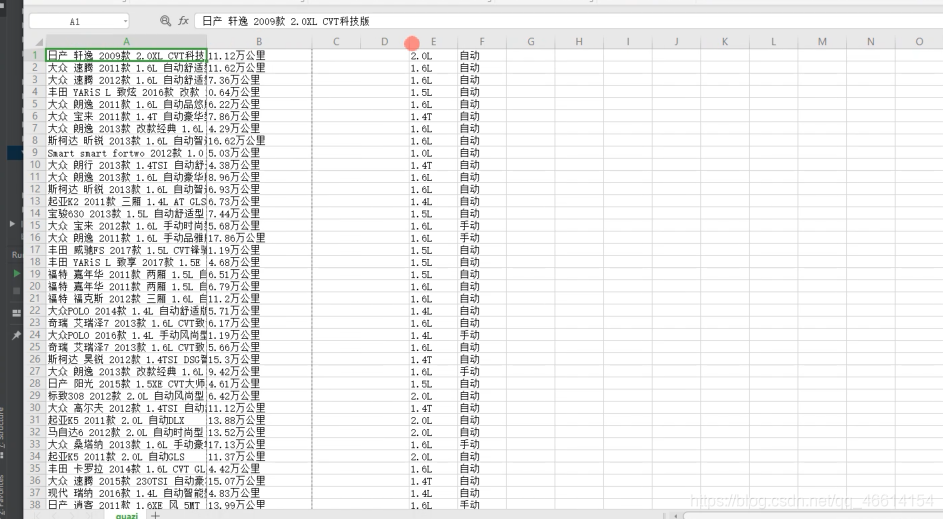
最后运行代码,效果如下图

来源:oschina
链接:https://my.oschina.net/u/4313784/blog/4292011