测试环境centos7 ,内核版本4.20
内核使用cgroup对进程进行分组,并限制进程资源和对进程进行跟踪。内核通过名为cgroupfs类型的虚拟文件系统来提供cgroup功能接口。cgroup有如下2个概念:
- subsystem:用于控制cgroup中的进程行为的内核组件,可以在/proc/cgroups查看所有支持的subsystem,subsystem也别称为resource controller;第二列为croup id;第三列为cgroup中进程数目。
# cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 8 6 1
cpu 7 105 1
cpuacct 7 105 1
blkio 5 105 1
memory 3 327 1
devices 6 106 1
freezer 4 6 1
net_cls 2 6 1
perf_event 11 6 1
net_prio 2 6 1
hugetlb 9 6 1
pids 12 106 1
rdma 10 1 1- hierarchy:由cgroup组成的层级树,每个hierarchy都对应一个cgroup虚拟文件系统,每个hierarchy都有系统上的所有task,此外低level的hierarchy不能超过高level设定的资源上限
系统默认会挂载cgroup,路径为/sys/fs/cgroup,查看当前系统挂载的cgroup,可以看到在默认路径下挂载了所有的子系统。后续可以直接使用下述hierarchy作为父hierarchy。进程的cgroup可以在/proc/$pid/cgroup文件中查看。
# mount|grep cgroup
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,hugetlb)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,rdma)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpu,cpuacct)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,net_cls,net_prio)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,blkio)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,freezer)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,memory)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,devices)cgroup有如下4个规则:
-
- 一个hierarchy可以有一个或多个subsystem,这个从/sys/fs/cgroup中可以看出来cpu和cpuacct可以同属于一个hierarchy,而memory则仅属于一个hierarchy;
- 一个subsystem不能挂载到一个已经挂载了不同subsystem的hierarchy上(下面讲);
- 一个task不能同时存在于同一个hierarchy下的两个cgoup中,但可以存在于不同类型的hierarchy中;如下例中,在hierarchy memory中创建2个cgroup mem1和mem2,可以看到将当前bash进程写入到mem2/tasks之后,mem1/tasks中的内容就会被清空。注:删除cgroup之前需要退出所有attach到该cgroup的进程,如下面的进程为bash,exit退出即可
[root@ memory]# echo $$
9439
[root@ memory]# echo $$ > mem1/tasks
[root@ memory]# cat mem1/tasks
9439
9680
[root@ memory]# echo $$ > mem2/tasks
[root@ memory]# cat mem2/tasks
9439
9693
[root@ memory]# cat mem1/tasks
[root@ memory]# 相同类型subsystem的hierarchy为同一个hierarchy,如下例中创建一个包含memory subsystem的hierarchy,它与/sys/fs/cgroup下面的memory是一致的,在cgrp1中创建一个名为mem1的cgroup。在/sys/fs/cgroup/memory下可以看到新创建的mem1
[root@ cgroup]# mount -t cgroup -o memory mem cgrp1/
[root@ cgroup]# cd cgrp1/
[root@ cgrp1]# mkdir mem1-
- 子进程会继承父进程的hierarchy,但可以将子进程调整到其他cgroup。下例中可以看到子进程同样受到父进程hierarchy的限制
[root@ mem1]# echo $$
10928
[root@ mem1]# echo $$>tasks
[root@ mem1]# cat /proc/10928/cgroup
11:devices:/user.slice
10:perf_event:/
9:pids:/user.slice
8:freezer:/
7:cpuacct,cpu:/
6:hugetlb:/
5:memory:/mem1
4:cpuset:/
3:net_prio,net_cls:/
2:blkio:/
1:name=systemd:/user.slice/user-1000.slice/session-1.scope
[root@ mem1]# bash #创建一个子进程
[root@ mem1]# echo $$
11402
[root@ mem1]# cat /proc/11402/cgroup
11:devices:/user.slice
10:perf_event:/
9:pids:/user.slice
8:freezer:/
7:cpuacct,cpu:/
6:hugetlb:/
5:memory:/mem1
4:cpuset:/
3:net_prio,net_cls:/
2:blkio:/
1:name=systemd:/user.slice/user-1000.slice/session-1.scope从上面可以看到,subsystem相同的hierarchy是被重复使用的;当创建一个新的hierarchy时,如果使用的subsystem被其他hierarchy使用,则会返回EBUSY错误。如/sys/fs/cgroup中已经在cpuset和memory中单独使用了名为cpuset和memory的subsystem,则重新创建一个包含了它们的hierarchy会返回错误
[root@ cgroup]# mount -t cgroup -o cpuset,memory mem1 cgrp1/
mount: mem1 is already mounted or /cgroup/cgrp1 busy可以创建没有subsystem的hierarchy,默认包含如下文件:
- tasks:包含了attach到该cgoup的pid。如上述例子中所示,将进程pid写入到该文件会将进程转移到该cgroup。(cgroupv2中移除了该文件,使用cgroup.procs)
- cgroup.procs:包含了线程的group id。将一个线程的group id写入该文件,会将该group下的所有线程转移到该cgroup。(cgroupv2中该文件的定义与cgroupv1中tasks文件的意义类似)
- notify_on_release:flag文件,用来判断是否执行release_agent
- release_agent:如果cgroup中使能notify_on_release,cgroup中的最后一个进程被移除,最后一个子cgroup也被删除时,cgroup会主动通知kernel。接收到消息的kernel会执行release_agent文件中指定的程序
[root@ cgroup]# mount -t cgroup -onone,name=cgrp1 mycgroup cgrp1/
[root@ cgroup]# cd cgrp1/
[root@ cgrp1]# ll
total 0
-rw-r--r--. 1 root root 0 Jan 2 23:54 cgroup.clone_children
--w--w--w-. 1 root root 0 Jan 2 23:54 cgroup.event_control
-rw-r--r--. 1 root root 0 Jan 2 23:54 cgroup.procs
-r--r--r--. 1 root root 0 Jan 2 23:54 cgroup.sane_behavior
-rw-r--r--. 1 root root 0 Jan 2 23:54 notify_on_release
-rw-r--r--. 1 root root 0 Jan 2 23:54 release_agent
-rw-r--r--. 1 root root 0 Jan 2 23:54 tasks
上面为cgroup使用的一般规则,下面讲解memory cgroup
linux memory基础知识
以32位系统为例讲解下linux内存分布。linux内存分为用户空间和内核空间,用户空间占用0~3G的内存,内核空间占用3~4G的内存。从下图中可以看到用户空间的进程地址均为动态映射(即虚拟地址和物理地址的映射,如使用malloc申请到的内存为虚拟内存,只有对该内存进行访问时才会进行虚拟内存到物理内存的映射查找),而内核空间主要分为了2种内存区域,物理页面映射区和内核地址空间,前者可以直接访问物理地址且不会触发缺页异常(物理页面直接映射),而后者与用户空间用法一样,为动态映射。
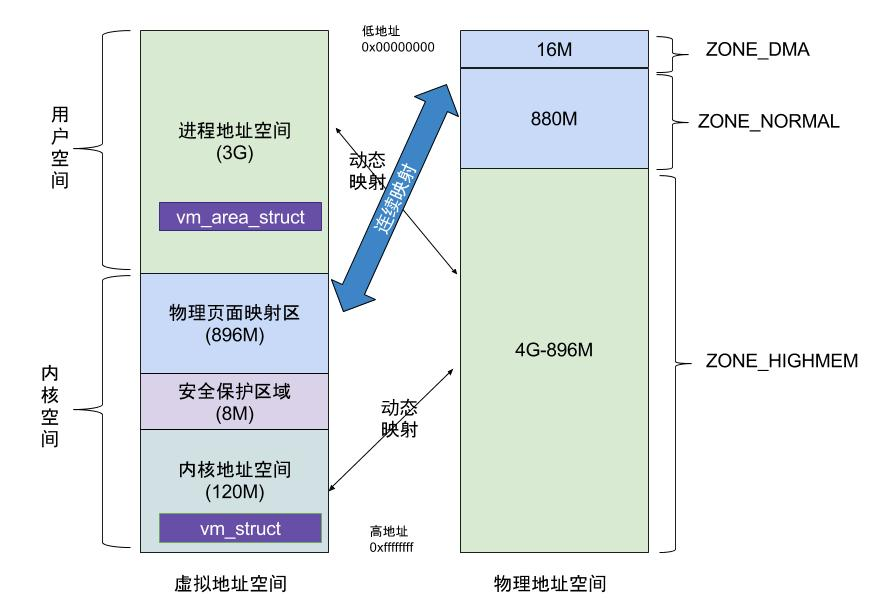
当用户空间使用malloc等系统调用申请内存时,内核会检查线性地址对应的物理地址,如果没有找到会触发一个缺页异常,进而调用brk或do_map申请物理内存(brk申请的内存通常小于128k)。而对于内核空间来说,它有2种申请内存的方式,slab(也有slob和slub)和vmalloc:
- slab用于管理内存块比较小的数据,可以在/proc/slabinfo下查看当前slab的使用情况,该文件下的slab主要分为3种:模块特定的slab,如UDPv6;为kmalloc使用的slab,如kmalloc-32(32代表32b);申请ZONE-DMA区域的slab,如dma-kmalloc-32。kmalloc和dma-kmalloc都属于普通的slab。可以看到kmalloc申请的内存为物理内存,且是连续内存,一般用于处理小内存(一般小于128 K)申请的场景;
- vmalloc操作的内存空间为VMALLOC_START~4GB,它与kmalloc操作的内存空间不存在冲突。vlmalloc申请的内存在物理上可能是不连续的,主要用于解决内存碎片化的问题,因为可能存在缺页异常且内存分布比较散,因此适用于申请内存比较大且效率要求不高的场景。可以在/proc/vmallocinfo中查看vmalloc的内存分布情况。
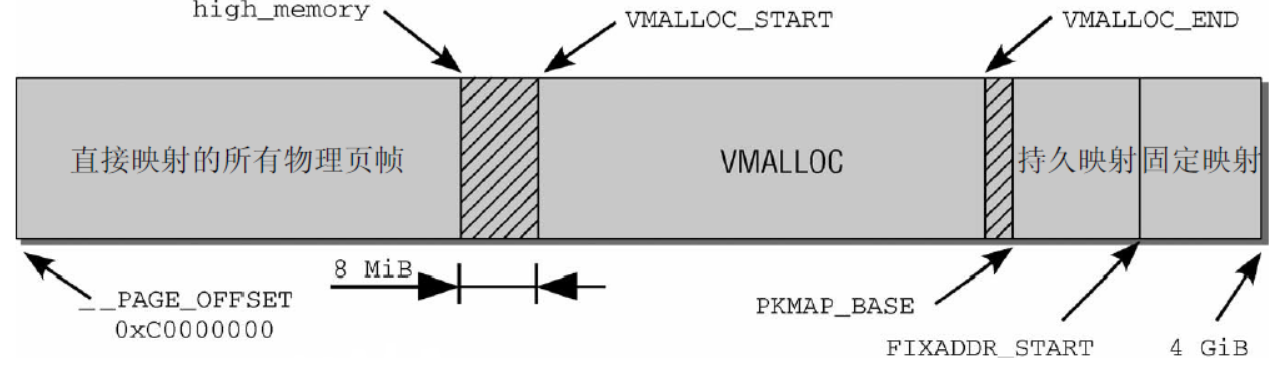
用户空间和内核空间申请内存的方式如下:
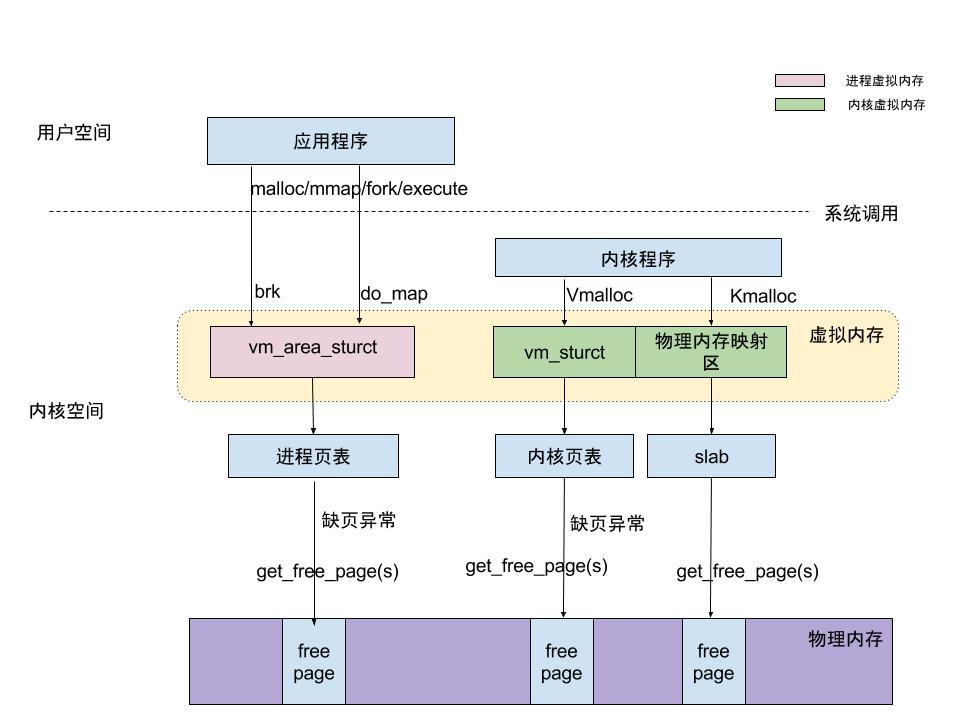
linux使用"伙伴关系"算法来管理空闲的内存资源,可以在/proc/buddyinfo中查看当前空闲的内存分布情况,注意到slab申请物理内存时并没有缺页异常。(Linux使用分页机制管理物理内存,将物理内存划分为4k大小的页面(使用getconf PAGESIZE查看当前系统页大小),当用户使用malloc申请内存时可以以kb为单位指定内存大小,但内核在申请内存时是以页为单位申请实际的物理内存。linux系统的针对大内存分配通过“伙伴关系”算法进行维护,可以在/proc/buddyinfo文件中查看当前空闲内存的划分。buddyinfo使用list保存了连续的物理内存,申请内存时会遍历该list,找到合适的内存并将其从该list上移除,将其注册到内存的tables上。
linux 内存回收
linux使用LRU(least recently used)来回收内存页面,LRU维护2个list,active和inactive,每个list上维护了2种类型的内存映射:文件映射(file)和匿名映射(anon),所以LRU上的内存也就分为了Active(anon)、Inactive(anon)、Active(file)和Inactive(file)4种类型,对应memory.stat中的inactive_anon,active_anon,inactive_file,active_file。匿名映射包含使用malloc或mmap(MAP_ANONYMOUS方式)申请的内存以及swap cache和shmem(见下),其内存不对应具体的文件,故称为匿名映射;文件映射对应的内存又称为file-backed pages,包含进程的代码、映射的文件,在运行一个新的程序时该内存会增加。
当系统出现内存不足时,首先会想到使用free命令查看当前系统的内存情况,如下例中,系统free内存为65M,available为85M,多出的20M为buff/cache中可以释放的部分。swap用于在内存不足时将数据从内存swap到硬盘上。
# free -m
total used free shared buff/cache available
Mem: 972 660 65 28 246 85
Swap: 2047 51 1996使用free命令可以看到内存的大致情况,如果需要更详细的信息,就需要结合/proc/meminfo文件。/proc/meminfo文件中一般只要关注与LRU相关的内存即可,即Active(anon)、Inactive(anon)、Active(file)和Inactive(file)。需要注意的是,内核在统计内存时,只统计产生了缺页异常的内存(即实际的物理内存),如果只是申请了内存,而没有对内存进行访问,则不会加入统计。
其中Active(file)+Inactive(file)+Shmem=Cached+Buffers(如果内存没有指定mlock),Buffers主要用于块设备的存储缓存,该值通常比较小,所以Active(file)+Inactive(file)+Shmem通常也可以认为是Cached,Cached表示了当前的文件缓存。Shmem表示share memory和tmpfs+devtmpfs占用内存空间的总和(由于share memory就是tmpfs实现的,实际上shemem就是各种tmpfs实现的内存的总和。可以使用ipcs查看共享内存大小,使用df -k查看挂载的tmpfs文件系统),该值与free命令的shared相同。所有tmpfs类型的文件系统占用的空间都计入共享内存。注:ipc中共享内存,消息队列和信号量的底层实现就是基于tmpfs的。
下面创建一个200M的tmpfs的文件系统,可以看到在创建前后内存并没有变化,原因是此时并没有访问内存,/tmp/tmpfs的空间利用率为0%
# mkdir /tmp/tmpfs
# free -m
total used free shared buff/cache available
Mem: 972 673 63 29 235 70
Swap: 2047 58 1989
# mount -t tmpfs -o size=200M none /tmp/tmpfs/
# free -m
total used free shared buff/cache available
Mem: 972 674 62 29 235 70
Swap: 2047 58 1989
# df -k
Filesystem 1K-blocks Used Available Use% Mounted on
...
none 204800 0 204800 0% /tmp/tmpfs在上述文件系统下创建一个100M的文件,再次查看内存,可以看到shared增加了100M。查看/proc/meminfo,可以看到Shmem和Cached都增加了100M
# echo 3 > /proc/sys/vm/drop_caches
# free -m
total used free shared buff/cache available
Mem: 972 574 253 28 144 212
Swap: 2047 157 1890
[root@ tmpfs]# dd if=/dev/zero of=/tmp/tmpfs/testfile bs=100M count=1
[root@ tmpfs]# free -m
total used free shared buff/cache available
Mem: 972 568 162 128 241 119
Swap: 2047 162 1885在/proc/meminfo中还有一个Mapped值,用于统计映射的文件的大小。下面使用mmap映射上面生成的100M大小的testfile,注意mmap的选项为MAP_ANONYMOUS|MAP_SHARED,它会创建一个匿名映射,实际上也是tmpfs的实现。下面需要有一个memset操作,否则这块内存不会被统计进去
#include <stdlib.h>
#include <stdio.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <fcntl.h>
int main()
{
void *ptr;
int fd;
fd = open("testfile", O_RDWR);
if (fd < 0) {
perror("open()");
exit(1);
}
ptr = mmap(NULL, 1024*1024*100, PROT_READ|PROT_WRITE, MAP_ANONYMOUS|MAP_SHARED, fd, 0);
if (fd < 0) {
perror("open()");
exit(1);
}
memset(ptr,0,1024*1024*100);
getchar();
return 0;
}执行前查看当前的内存
# free -m
total used free shared buff/cache available
Mem: 972 538 174 128 260 140
Swap: 2047 192 1855
# ./mmap
在另外一个shell界面查看内存,可以看到shared增加了100M,对比/proc/meminfo前后差距,可以看到Mapped增加了100M,Shmem增加了100M,Inactive(anon)也增加了100M。结束进程后,申请的内存会被释放。
# free -m
total used free shared buff/cache available
Mem: 972 536 65 228 370 37
Swap: 2047 194 1853但Mapped并不是Shmem的子集,上述代码的mmap仅使用MAP_SHARED时不会增加Shmem大小,仅表示映射的文件大小。
AnonPages表示不包含Shmem的匿名映射,AnonPages=Active(anon)+Inactive(anon)-Shmem
“Mlocked”统计的是被mlock()系统调用锁定的内存大小。被锁定的内存因为不能pageout/swapout,会从Active/Inactive LRU list移到Unevictable LRU list上。也就是说,当”Mlocked”增时,”Unevictable”也同步增加,而”Active”或”Inactive”同时减小;当”Mlocked”减小的时候,”Unevictable”也同步减小,而”Active”或”Inactive”同时增加。由于swap会影响进程处理内存的效率,对内存进行锁定可以避免这段进程被交换到硬盘,增加数据处理效率
linux进程内存空间
32位系统下,linux中所有进程使用的内存布局如下:
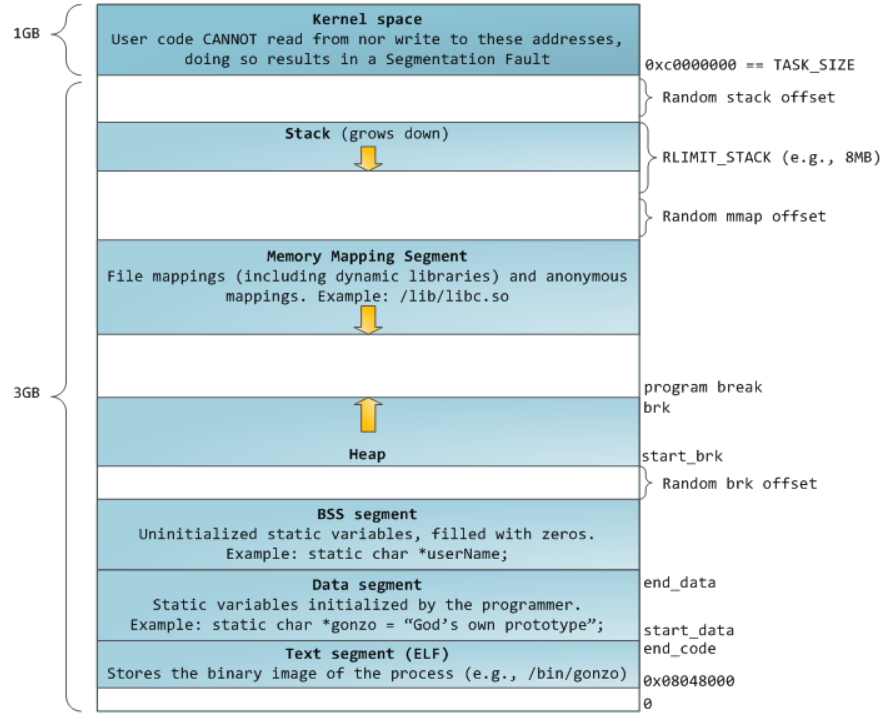
使用pmap可以查看进程内存段的简要信息,借此可以初步判定是否存在内存泄漏或内存占用过大的地方。pmap命令主要从/proc/$pid/smaps中获取数值。如下代码创建并使用100M内存
#include<stdlib.h>
#include<stdio.h>
int main()
{
int i=0;
char *p = malloc(1024*1024*100);
memset(p,1,1024);
getchar();
return 0;
}编译并执行上述代码,使用pmap查看该进程的内存分布如下,可以看到有一个100M(102404K)大小的匿名内存占用,即malloc申请的内存,此外也可以看到动态库libc占用的内存,以及该进程的栈大小(栈默认8M,可以使用ulimit -a查看)。更多参见Linux进程内存布局
# pmap -x 52218
52218: ./test
Address Kbytes RSS Dirty Mode Mapping
0000000000400000 4 4 0 r-x-- test
0000000000600000 4 4 4 r---- test
0000000000601000 4 4 4 rw--- test
00007f4b47564000 102404 4 4 rw--- [ anon ]
00007f4b4d965000 1800 256 0 r-x-- libc-2.17.so
00007f4b4db27000 2048 0 0 ----- libc-2.17.so
00007f4b4dd27000 16 16 16 r---- libc-2.17.so
00007f4b4dd2b000 8 8 8 rw--- libc-2.17.so
00007f4b4dd2d000 20 12 12 rw--- [ anon ]
00007f4b4dd32000 136 112 0 r-x-- ld-2.17.so
00007f4b4df39000 12 12 12 rw--- [ anon ]
00007f4b4df51000 8 4 4 rw--- [ anon ]
00007f4b4df53000 4 4 4 r---- ld-2.17.so
00007f4b4df54000 4 4 4 rw--- ld-2.17.so
00007f4b4df55000 4 4 4 rw--- [ anon ]
00007ffc73bf9000 132 16 16 rw--- [ stack ]
00007ffc73cd5000 8 4 0 r-x-- [ anon ]
ffffffffff600000 4 0 0 r-x-- [ anon ]
---------------- ------- ------- -------
total kB 106620 468 92
linux可以使用如下3种方式回收LRU上的内存:
- 使用kswapd 进行周期性检查,由上面图可以看到,linux的内存被分为不同的zone,每个zone中都有3个字段:page_min,page_low,page_high(参见/proc/zoneinfo),kswapd依据这3个值进行内存回收(参见min_free_kbytes),需要注意的是,/proc/zoneinfo的值类型为pages,而/proc/sys/vm/min_free_kbytes的类型为kb,如下例中,计算公式为:
(8+1485+15402)*4=16895,基本等于67584
# cat min_free_kbytes
67584
# cat /proc/zoneinfo |grep -E "zone|min"
Node 0, zone DMA
min 8
Node 0, zone DMA32
min 1485
Node 0, zone Normal
min 15402linux 32位和64位定义的zone是不同的,可以在/proc/zoneinfo中查看zone的具体信息;注:numa场景下每个内存被划分到不同的node,每个node含独立的zone,关系如下:
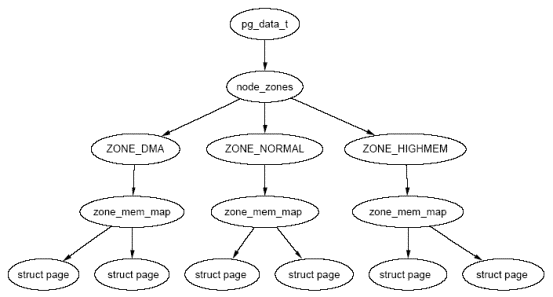
如下可以查看Node0 包含的zone(本机器只有一个node)
# cat zoneinfo |grep Node
Node 0, zone DMA
Node 0, zone DMA32- 内存严重不足时触发OOM-killer,当kswapd回收后仍然不满足需求时才会触发该机制;
- 使用/proc/sys/vm/drop_caches手动释放内存。
用户进程的内存页分为两种:file-backed pages(与文件对应的内存页),和anonymous pages(匿名页),比如进程的代码、映射的文件都是file-backed,而进程的堆、栈都是不与文件相对应的、就属于匿名页。file-backed pages在内存不足的时候可以直接写回对应的硬盘文件里,称为page-out,不需要用到交换区(swap)。/proc/meminfo中有一个dirty字段(所有的drity=Dirty+NFS_Unstable+Writeback),为了维护数据的一致性,内核在清空内存前会对内存中的数据进行写回操作,此时内存中的数据也被称为脏数据,如果需要清空的内存比较大,可能会消耗大量系统io资源;而anonymous pages在内存不足时就只能写到硬盘上的交换区(swap)里,称为swap-out,匿名页即将被swap-out时会先被放进swap cache,在数据写入硬盘后,swap cache才会被free。下面为swap-out和swap-in的流程.。注:tmpfs也可以被swap-out;cached不包含swap cache。swap 和file-backed可以参见该文档
[swap-out]
Make a page as swapcache → unmap → write out → free
[swap-in]
Alloc page → make it as swapcache → read from disk → map it.更多linux内存的信息可以参见这里
memory cgroup 对内存的限制
内核扩展
cgroup内存的回收与上述linux系统的回收机制类似,每个cgroup都有对应的LRU,当内存cgroup的内存达到限定值时会触发LRU上的内存回收。需要注意的是cgroup无法控制全局LRU的内存回收,因此在系统内存匮乏的时候,会触发全局LRU上内存的swap操作,此时cgroup无法限制这种行为(如cgroup限制了swap的大小为1G,但此时可能会超过1G)。下图可以看出cgoup的LRU控制的内存也在全局LRU所控制的范围内。

memory cgroup的主要作用如下:
-
- 限制memory(含匿名和文件映射,swap cache)
- 限制swap+memory
- 显示cgroup的内存信息
- 为每个cgroup设置softlimit
memory cgroup中以 memory.kmem.开头的文件用于设置cgroup的内核参数,这些功能被称为内核内存扩展(CONFIG_MEMCG_KMEM),用于限制cgroup中进程占用的内核内存资源,一般用的比较少。内核内存不会使用swap。系统默认会开启这些功能,可以使用如下命令查看是否打开:
# cat /boot/config-`uname -r`|grep CONFIG_MEMCG
CONFIG_MEMCG=y
CONFIG_MEMCG_SWAP=y
CONFIG_MEMCG_SWAP_ENABLED=y
CONFIG_MEMCG_KMEM=ycgroup中内核内存和用户内存有如下限制关系(U表示用户内存,K表示内核内存):
- U != 0,K > ulimited:这是典型的memory cgroup方式,仅对用户内存进行限制
- U !=0,K<U: 当内核内存低于内存时,当前实现下不会触发内存回收机制,一般不会采用这种使用方式
- U !=0,K>=U: 这种情况下会触发内存回收,主要用于系统管理员对内核内存的限制和跟踪
cgroup设置用户内存
cgoup对用户内存的限制主要是memory.limit_in_bytes和memory.memsw.limit_in_bytes。后者用于限制swap+memory的大小,前者则不限制swap。后者的值要不小于前者,因此在设置的时候优先设置memory.limit_in_bytes的值,当memory.limit_in_bytes==memory.memsw.limit_in_bytes时表示cgroup不使用swap
当新创建一个cgroup的时候,memory.limit_in_bytes和memory.memsw.limit_in_bytes默认不会对内存进行限制,使用所有的系统内存。
- 首先设置memory.limit_in_bytes和memory.memsw.limit_in_bytes的限定值为4M,此时不会使用swap
# echo 50M > memory.limit_in_bytes
# cat memory.limit_in_bytes
52428800
# echo 50M > memory.memsw.limit_in_bytes
# cat memory.memsw.limit_in_bytes
52428800- 将当前bash设置到tasks中,并尝试使用dd命令创建一个100M的文件,此时会触发OOM-killer机制,查看memory.max_usage_in_bytes和memory.max_usage_in_bytes,均为52428800(即50M)
# echo $$ > tasks
# dd if=/dev/zero of=/home/testfile bs=100M count=1
Killed- 将memory.memsw.limit_in_bytes设置为系统默认值(可以在root cgroup的memory.memsw.limit_in_bytes中查看),此时可以看到创建成功。memory.max_usage_in_bytes中显示的内存使用最大值为50M,而memory.memsw.max_usage_in_bytes中的内存使用最大值大于100M
# echo 9223372036854771712 > memory.memsw.limit_in_bytes
# dd if=/dev/zero of=/home/testfile bs=100M count=1
1+0 records in
1+0 records out
104857600 bytes (105 MB) copied, 0.740223 s, 142 MB/s
# cat memory.max_usage_in_bytes
52428800
# cat memory.memsw.max_usage_in_bytes
113299456memory.force_empty主要用于在执行rmdir删除cgroup时尽量清空cgroup占用的内存。类似echo 3 > /proc/sys/vm/drop_caches
# cat memory.usage_in_bytes
86016
# echo 1 > memory.force_empty
# cat memory.usage_in_bytes
0memory.stat中的字段解析如下:
# per-memory cgroup local status
cache - # of bytes of page cache memory.
rss - # of bytes of anonymous and swap cache memory (includes transparent hugepages). #非正真的进程rss
rss_huge - # of bytes of anonymous transparent hugepages.
mapped_file - # of bytes of mapped file (includes tmpfs/shmem)
pgpgin - # of charging events to the memory cgroup. The charging event happens each time a page is accounted as either mapped anon page(RSS) or cache page(Page Cache) to the cgroup.
pgpgout - # of uncharging events to the memory cgroup. The uncharging event happens each time a page is unaccounted from the cgroup.
swap - # of bytes of swap usage
dirty - # of bytes that are waiting to get written back to the disk.
writeback - # of bytes of file/anon cache that are queued for syncing to disk.
inactive_anon - # of bytes of anonymous and swap cache memory on inactive LRU list.
active_anon - # of bytes of anonymous and swap cache memory on active LRU list.
inactive_file - # of bytes of file-backed memory on inactive LRU list.
active_file - # of bytes of file-backed memory on active LRU list.
unevictable - # of bytes of memory that cannot be reclaimed (mlocked etc).
# status considering hierarchy (see memory.use_hierarchy settings)
hierarchical_memory_limit - # of bytes of memory limit with regard to hierarchy under which the memory cgroup is
hierarchical_memsw_limit - # of bytes of memory+swap limit with regard to hierarchy under which memory cgroup is.memory.swappiness用于设置发生swap时内存的比例,设置值为[0,100],100表示积极使用swap,0表示优先使用内存。cgroup中的swappiness作用与全局swappiness大体类似,用于限制本group中的swap使用。但cgroup中的swappiness在设置为0时完全禁止swap,而全局在内存不足时依然会使用swap,因此当cgroup中swappiness设置为0时更容易发生OOM-kill。root cgroup中的swappiness设置对应全局swappiness。注:swappiness用于设置发生swap的内存比例,如设置为60,表示内存在%(100-60)时开始发生swap。swappiness的设置建议如下
vm.swappiness = 0 :仅在内存不足的情况下--当剩余空闲内存低于vm.min_free_kbytes limit时,使用交换空间。
vm.swappiness = 1 :进行最少量的交换,而不禁用交换。
vm.swappiness = 10:当系统存在足够内存时,推荐设置为该值以提高性能。
vm.swappiness = 60:系统默认值。这样回收内存时,对file-backed的文件cache内存的清空比例会更大,内核将会更倾向于进行缓存清空而不是交换
vm.swappiness = 100:内核将积极的使用交换空间。memory.failcnt 和memory.memsw.failcnt用于内存达到上限的次数,分别对应memory.limit_in_bytes和memory.memsw.limit_in_bytes。可以使用echo 0>memory.failcnt重置。
memory.use_hierarchy用于设置cgroup内存的继承管理,如下图在设置了memory.use_hierarchy=1后,e group的内存会累计到它的祖先c和root。如果某个祖先的内存使用达到上限,则会在该祖先和它的子group中发生内存回收
root
/ | \
/ | \
a b c| \
d e如下图在root cgroup下面创建一个子cgroup test1,在test1下面创建test2 和test3
root
|
|
test1
/ \
/ \
test2 test3在test1中设置不适用swap,且内存上限为100M,查看当前内存使用为0
# echo 100M > memory.limit_in_bytes
# echo 100M > memory.memsw.limit_in_bytes
# cat memory.usage_in_bytes
0使用如下命令创建一个可执行文件,用于申请30M的内存,执行该程序,并将进程添加到test2 cgroup(注:进程只有在添加到cgroup之后的内存申请才受croup的限制,因此在t2进程添加到test 2 cgroup之后,回到t2进程执行界面,执行回车以执行malloc操作),可以看到test2 cgroup的内存使用为30M
#include<stdlib.h>
#include<stdio.h>
int main(int argc,char **argv)
{
getchar();
void *mem=malloc(30*1024*1024);
memset(mem,0,30*1024*1024);
getchar();
return 0;
}# echo 15570 > tasks
# cat tasks
15570
# cat memory.usage_in_bytes
31588352在test1 cgroup中查看内存使用,约30M
# cat memory.usage_in_bytes
31465472创建t3进程,用于申请50M内存,操作同t2进程,在test1 cgroup下查看内存消耗,约80M
# cat memory.usage_in_bytes
83902464修改t3进程申请内存的大小=100M,此时test1 cgroup的子cgrou总内存消耗超过了它的上限100M,在t3加入到test3的cgroup之后,在申请内存时会被oom-kill掉
# ./t3
Killedmemory.use_hierarchy可以限制一个cgroup的总内存大小。当有子cgroup或父cgroup的use_hierarchy enabled时,无法修改该值
memory.soft_limit_in_bytes用于调节内存的使用,该值不能大于memory.limit_in_bytes。当系统发现内存不足时,系统会尽量将cgroup中的内存回退到memory.soft_limit_in_bytes设定的内存值以下。
memory.move_charge_at_immigrate用于控制线程在不同cgroup间移动时对内存charge的动作。当设置为1时,当线程移动到另一个cgroup时,其申请的内存页也会移动到另一个cgroup。默认不会。需要注意的是,转移的线程必须是该线程组的主线程,且目标内存充足时才能迁移成功,否则会失败,同时需要在目的cgroup中设置memory.move_charge_at_immigrate。设置该值会影响效率,如果内存过大,可能会消耗过长时间。
使用上面的代码进行测试。创建一个新的cgroup test4且设置其memory.move_charge_at_immigrate=1。test1,test2和test3启用use_hierarchy功能,限定内存上限为100M
# cat memory.use_hierarchy
1
# cat memory.limit_in_bytes
104857600
# cat memory.memsw.limit_in_bytes
104857600新的cgroup组织如下:
root
/ \
/ \
test1 test4
/ \
/ \
test2 test3使用程序t2申请30M内存,将其加入test2 tasks中,此时在test1 cgroup中可以看到其使用的内存约30M;使用t3申请80M内存,当然此时t3无法加入test3的tasks中。将t2迁移到test4 cgroup中,查看test1 cgroup的内存使用,其变为了0
# cat memory.usage_in_bytes
0此时将t3加入test3 cgroup,加入成功,查看test1 cgroup的内存使用,使用约80M,而test4 cgroup的内存使用约30M
# cat memory.usage_in_bytes
83894272memory.oom_control用于控制oom-kill的行为,默认启动oom-kill,当内存不足时,oom-kill可能会进行内存回收。设置memory.oom_control=1时disable oom-kill,此时当进程监测到内存不足时会进入挂起或睡眠状态
仍然使用上述代码创建t1,申请100M内存,同时设置memory.oom_control=1,将其加入test1 cgroup,在t1申请内存之前,可以看到其进程状态为S+
# ps -aux|grep test1
...
root 21382 0.0 0.0 4212 356 pts/11 S+ 23:24 0:00 ./test1t1申请内存,可以看到其进程状态变为了D+。可以通过释放test1 cgroup的内存(杀死或转移其他进程)或扩大内存上限(如echo 200M > memory.memsw.limit_in_bytes)来重新激活t1进程
# ps -aux|grep test1
...
root 21382 0.1 10.2 116856 102520 pts/11 D+ 23:24 0:00 ./test1cgroup.event_control用来与memory.oom_control配合,在触发oom-kill的时候给出事件通知。事件级别有low,medium和critical三种,事件传递有default,hierarchy,local三种示例代码可以参考memory_example-usage,该代码运行时,当cgroup的内存触发oom-kill的时候会给出"mem_cgroup oom event received"的提示。
TIPs:
- 可以使用ps -aux,在RSS一列中查看进程占用的物理内存空间,RSS定义可以查看内存耗用:VSS/RSS/PSS/USS 的介绍。ps -aux显示的进程的RSS与/proc/$pid/status中的RSS值相同,等于/proc/$pid/smap的所有RSS的和,RSS包含进程memory-mapped(使用lsof查看)文件,不包含打开的文件(/proc/$pid/fd)cache。
- 使用top命令可以查看进程正在使用的swap的大小,执行top命令,按F,选择SWAP回车即可
- 在手动drop cache前可以执行sync,让脏数据直接写回到文件中,这样可以释放更多内存
- 由于无法设置root cgroup的限制,因此内存回收机制在root cgroup中是不起作用的。
- 当一个task从一个cgroup迁移到另一个cgroup的时候,它的charge(匿名页,文件cache和swap cache)默认是不会随之迁移的。因此当一个cgroup中没有任何task的时候,不代表其不占用任何内存(memory.move_charge_at_immigrate)。
- 将一个一般的 pid 写入到 tasks 中,只有这个 pid 对应的线程,以及由它产生的其他进程、线程会属于这个控制组。而把 pid 写入 cgroups.procs,操作系统则会把找到其所属进程的所有线程,把它们统统加入到当前控制组。
参考:
https://segmentfault.com/a/1190000006917884
http://man7.org/linux/man-pages/man7/cgroups.7.html
http://www.haifux.org/lectures/299/netLec7.pdf
https://files-cdn.cnblogs.com/files/lisperl/cgroups%E4%BB%8B%E7%BB%8D.pdf
https://www.cnblogs.com/AlwaysOnLines/p/5639713.html
https://www.cnblogs.com/wuchanming/p/4465155.html
https://github.com/digoal/blog/blob/master/201701/20170111_02.md
http://linuxperf.com/?cat=7
来源:oschina
链接:https://my.oschina.net/u/4383176/blog/4492993