背景
某环境客户部署了一个kubernetes集群,发现flannel的pod一直重启,始终处于CrashLoopBackOff状态。

排查
-
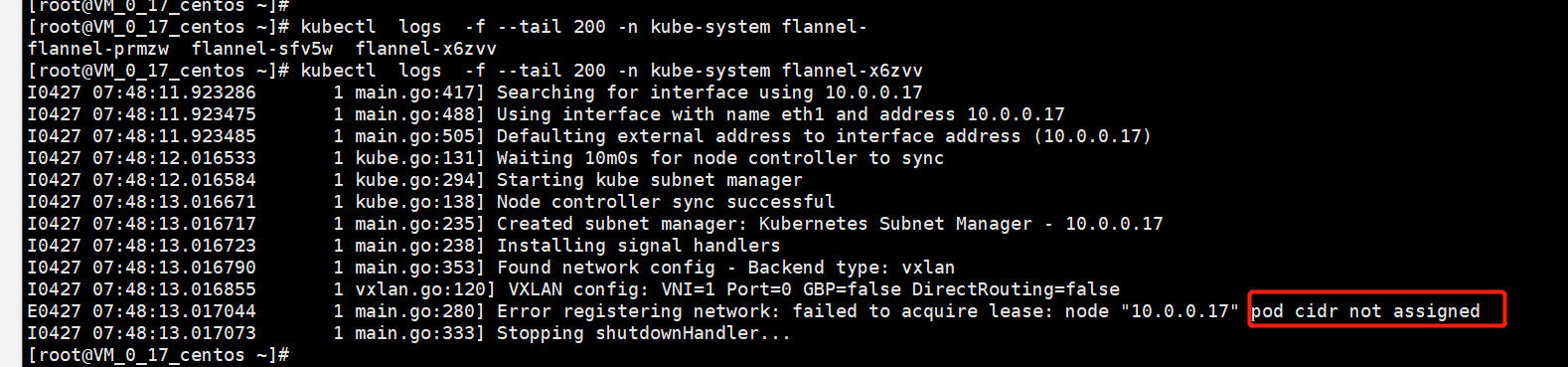
对于始终CrashLoopBackOff的pod,一般是应用本身的问题,需要查看具体pod的日志,通过
kubectl logs -f --tail -n kube-system flannel-xxx显示,“pod cidr not assigned”,然后flannel退出
-
检查日志显示的节点10.0.0.17的cidr,发现确实为空,而正常的环境却是正常的。


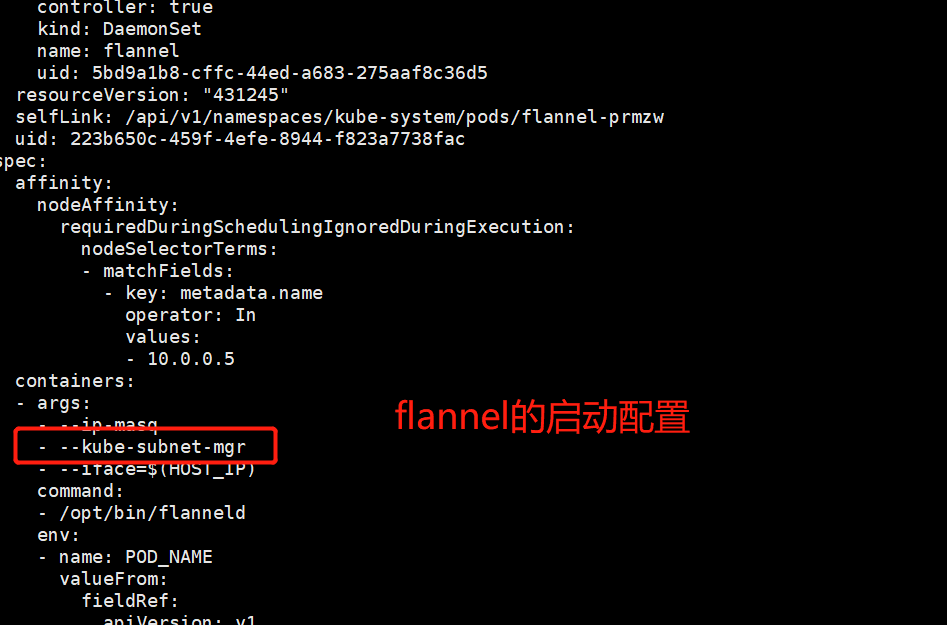
- 检查flannel的启动参数,发现为
--kube-subnet-mgr,–kube-subnet-mgr代表其使用kube类型的subnet-manager。该类型有别于使用etcd的local-subnet-mgr类型,使用kube类型后,flannel上各Node的IP子网分配均基于K8S Node的spec.podCIDR属性—"contact the Kubernetes API for subnet assignment instead of etcd.",而在第2步,我们已经发现节点的podcidr为空。
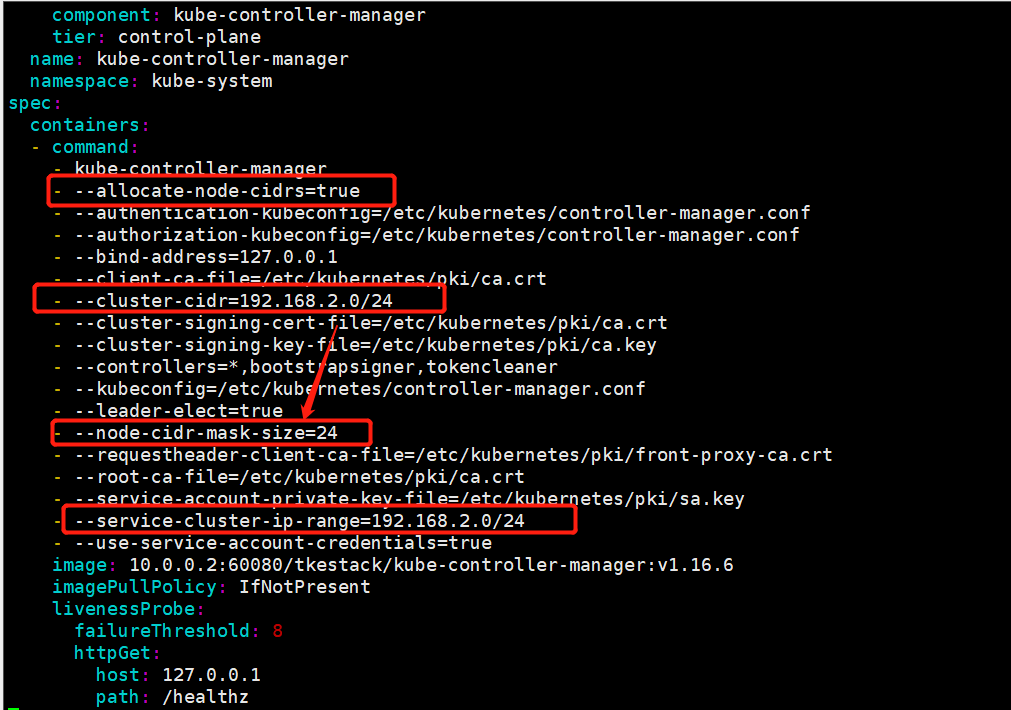
- node节点分配podCIDR,需要kube-controller-manager开启
allocate-node-cidrs为true,它和cluster-cidr参数共同使用的时候,controller-manager会为所有的Node资源分配容器IP段, 并将结果写入到PodCIDR字段.检查环境kube-controller-manager的配置文件,发现问题所在。如下图,环境设置了cluster-cidr为192.168.2.0/24,同时设置了node-cidr-mask-size为24,node-cidr-mask-size参数,用来表示kubernetes管理集群中节点的cidr掩码长度,默认是24位,需要从cluster-cidr里面分配地址段,而设置的cluster-cidr显然无法满足这个掩码要求,导致kube-controller-manager为节点分配地址失败。
后记
综上,可以修改node-cidr-mask-size参数为24以上的数解决node没法分配podcidr问题,但是同时发现环境部署使用的kubernetes自动化工具分配集群的service-cluster-ip-range也是从cluster-cidr里面取一段,分配不满足竟然使用了和cluster-cidr一样的地址,造成网段冲突。最终,让客户重新规划了网段,修改cluster-cidr掩码从24位改为16位,后续flannel均启动正常。
来源:oschina
链接:https://my.oschina.net/u/4393036/blog/4286806