概况:
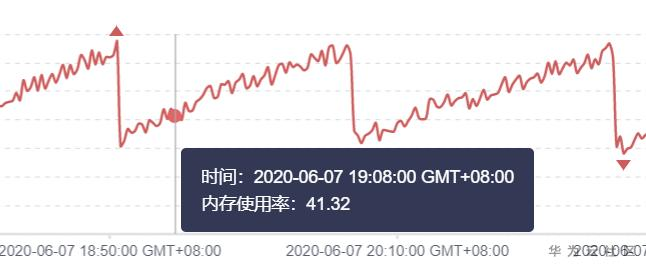
生产环境HBase集群内存经常处于高位(90%),而且GC之后也是内存依然处于高位,经分析内存全部由集群的regionserver进程所持有,,经常重启之后,大概3-4天就会保持在高位。由上述症状,可以判断集群内存有泄露的嫌疑。
分析
1、先熟悉一下HBase的内存模型
HBase系统中有两块大的内存管理模块,一块是MemStore ,一块是BlockCache,前置是用于集群写入所属内存,而后者用于缓存热数据,提供查询速度。这两者均可以通过配置文件进行配置。当前集群均配置了0.4和0.4的比例。而考虑到HBase集群是多写少读的情景,为此而引入了MSLAB机制来优化HBase的MemStore 负担。内存的使用率会呈现很优美的锯齿图形。

2、分析内存使用率和业务关系
起初认为是读写业务量已经超过了集群负载能力,但集群业务也不大,写和读的TPS,带宽吞吐量均未达到集群限定的能力,而且CPU利用率大多半都被GC占用,但内存就是持高不下,即使业务了停了一天,内存还是不怎么下降,很明显和业务量无关。
那么和compaction有关?经观察的确可以看compact时特别消耗时间。此时感觉看到了希望,调整各个参数,把compact操作提升了10+倍之后,内存还是持高不下 。剩下最根治的办法就是分析内存,看一下内存数据都是什么?有无内存泄露问题。
3、分析dunp文件
节点dump下regionserver的内存,分析发现内存中有50个RpcServer.FifoRWQ.default.read.handler线程,每个线程持有了1.2%左右的总内存,那么所有的线程持有的内存占有量大于为50*1.2%=60%。随着查询次数增多,线程持续的内存还会持续增加,如下图。
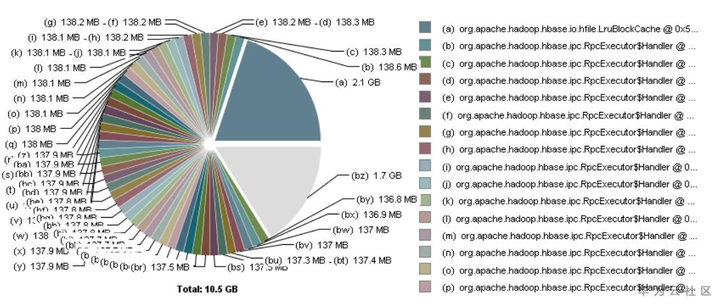
分析每一个线程持有的内存数据,全部都是业务信息。
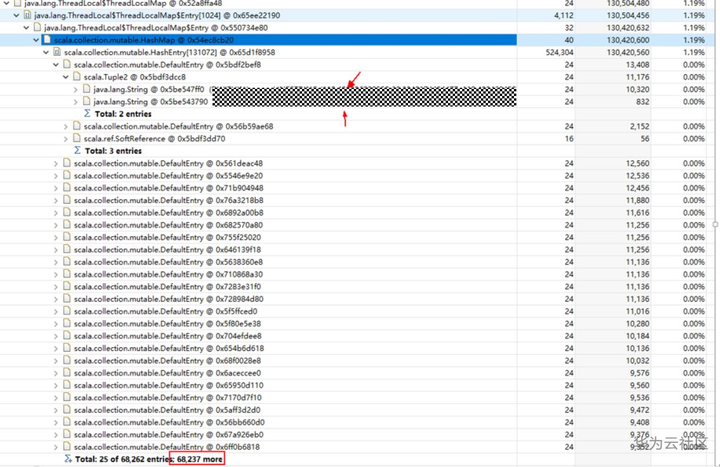
那么继续分析,此业务信息所属对象:org.locationtech.geomesa.filter.factory.FastFilterFactory。而对比同规模的集群,的确是此异常集群开启了GeoMesa特性。找到问题所在,那就看源码分析是唯一出路。
解决方案
经分析GeoMesa源码,缓存数据为GeoMesa的filterCache,全部都是查询的条件及其优化后查询条件。如下代码:
override def getOrElseUpdate(key: K, op: => V): V = {
val cached = caches.get.getIfPresent(key)
if (cached != null) { cached } else {
val value = op
//value=optimize(sft, ECQL.toFilter(ecql))
caches.get.put(key, value)
value
}
}导致集群随着查询次数增多,内存一直持续不下。
能否去掉此处缓存策略呢?为什么缓存此查询信息呢,目的就是为了减少同样的查询再次被优化的步骤。那么我们查询添条件key有没有重复使用,此处有个严格规定,就是key中不仅保证使用相同的GeoMesa函数还有使用相同的参数,基于这个原则,业务上查询条件是没有重复的。
我们配置了可选参数useFilterCache,默认是开启的,没必要缓存此查询条件,应予以删除。
结论
在配置文件中添加了useFilterCache参数,默认是开启的,根据业务需要选择开始和关闭filterCache特效。
经分析我们业务场景没必要缓存此查询条件,,应予以关闭。优化后的集群内存使用率情况就恢复了正常状态。
来源:oschina
链接:https://my.oschina.net/u/4526289/blog/4481708