前言
在对数据库进行优化前,我们先要思考一下数据库系统可能存在的瓶颈所在之外。数据库服务是运行在不同的硬件设备上的,优化即通过参数配置(不考虑应用客户端程序的情况下),而实现硬件资源的最大利用化。那么硬件资源有哪些呢,那就无外乎CPU,内存,磁盘,网络这些资源。
作为常用单机数据库(如MySQL,PostgreSQL),最常见的性能瓶颈在哪呢?
根据我的经验,绝大部分出现在磁盘性能。那我们如何来对它进行优化呢,那就是把磁盘的读写转化为内存的读写(增大数据缓存),或是采用数据压缩,转化为CPU的资源消耗。
对于TIDB,它是网络数据库,可能情况略有不同。我们也需要把网络因素加以考虑。
TIDB原理
要优化一个数据库,首先要对于它进行了解,特别是内部原理。这样我们才能在问题出现时,如何对它进行定位和优化。
TIDB相对传统数据库有很大的不同。
TIDB的整体架构:

官网上关于TIDB的核心见如下文章
三篇文章了解 TiDB 技术内幕:
TIDB可能的性能瓶颈
通过TIDB的实现原理分析,个人认为瓶颈可能存在于如下方面
1)PD的授时开销,以及GC的抖动
2)raft模块性能问题
3)Region的热点问题
4)TiKV的性能问题
如SST compation,读放大,压缩,Block cache命中率等
TIDB优化之Grafana查看指标
TIDB监控指标由如下几个面板组成
正常人的第一印象肯定就是,面板内的监控项如此之多,该如何看起呢?可能看了很多天,也没有进展,因为实在弄不清楚每个监控参数的意义。或是被太多的参数给搅乱了头脑,不知从何入手。这些都是人之常情。因为我其实也是一个TiDB初学者,我就尝试一下带领大家去繁就简。那通过什么方法来进行呢?
道理很简单(话说简单的道理,也花了我几周时间才想清楚),那就是先只关注最关键的监控指标。
那现在的问题就简单了,那就是哪些指标是最关键的呢?
问题就在我写的“TIDB可能的性能瓶颈”一章,即硬件相关,以及TSO,raft,Region热点等。
Overview面板
查看硬件相关的,即CPU的利用率,内存的使用情况(TiDB在内存使用超限的时候,会引起OOM错误),网络流量。
还有就是TSO授时,raft store CPU等。
通过这些指标,我们可以看到系统的总体运行情况,看哪个地方有资源或性能问题。
TiDB面板
TiDB架构图:

通常80%以上的性能问题,都是由于应用程序SQL的问题。所以我们关注的重点除了CPU,内存,还有就是slow query。
还有就是GC相关(Go语言本身的问题),TSO授时等。
因为TiDB是网络数据库,数据的存取都需要通过网络来进行访问,所以通常来说,TiDB不会成为性能的瓶颈。
关于SQL优化,还可以查看
Statement Summary Tables
还可使用如下命令,查看执行计划
EXPLAIN
EXPLAIN ANALYZE
PD面板
PD的架构图:

要明白哪些指标对于PD比较重要,那首先需要明确PD的作用。
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:
一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);
二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);
三是分配全局唯一且递增的事务 ID(即TSO授时)。
PD元数据持久化是通过etcd。调试和负载均衡是防止热点数据。所以,我们关注的重点有如下几个。
1)etcd相关性能
PD 需要将 Region Meta 信息持久化在 etcd 上,以保证切换 PD Leader 节点后 PD 能快速继续提供 Region 路由服务。
随着 Region 数量的增加,etcd 出现性能问题,使得 PD 在切换 Leader 时从 etcd 获取 Region Meta 信息的速度较慢。在百万 Region 量级时,从 etcd 获取信息的时间可能需要十几秒甚至几十秒。
可以开启配置项 use-region-storage,将 Region Meta 信息存在本地的 LevelDB 中,并通过其他机制同步 PD 节点间的信息。
如上,我们需要关注的指标为
etcd
Handle transactions count:etcd 的事务个数
99% Handle transactions duration:99% 的情况下,处理 etcd 事务所需花费的时间
99% WAL fsync duration:99% 的情况下,持久化 WAL 所需花费的时间,这个值通常应该小于 1s
99% Peer round trip time seconds:99% 的情况下,etcd 的网络延时,这个值通常应该小于 1s
etcd disk WAL fsync rate:etcd 持久化 WAL 的速率
2)调度及热点问题
如下文档值得一读
PD 调度策略最佳实践
TiDB 高并发写入场景最佳实践
关于调度,我们需要关注的指标为
Operator
99% Operator finish duration:99% 已完成 operator 所花费的最长时间
50% Operator finish duration:50% 已完成 operator 所花费的最长时间
99% Operator step duration:99% 已完成的 operator 步骤所花费的最长时间
50% Operator step duration:50% 已完成的 operator 步骤所花费的最长时
关于热点,我们需要关注的指标为
Statistics - hotspot
Hot write Region's leader distribution:每个 TiKV 实例上是写入热点的 leader 的数量
Hot write Region's peer distribution:每个 TiKV 实例上是写入热点的 peer 的数量
Hot write Region's leader written bytes:每个 TiKV 实例上热点的 leader 的写入大小
Hot write Region's peer written bytes:每个 TiKV 实例上热点的 peer 的写入大小
Hot read Region's leader distribution:每个 TiKV 实例上是读取热点的 leader 的数量
Hot read Region's peer distribution:每个 TiKV 实例上是读取热点的 peer 的数量
3)TSO授时性能问题
PD通过引入etcd解决了单点问题,一旦Leader节点故障,会立刻选举新的Leader继续提供服务;而由于TSO服务只通过PD的Leader提供,所以可能会出现性能瓶颈。
TSO授时相关的指标是在Overview面板的
TiDB
PD TSO OPS:TiDB 从 PD 获取 TSO 的数量
PD TSO Wait Duration:TiDB 从 PD 获取 TS 的时间
TiKV面板
TiKV肯定是优化的重中之重了,因为所有的数据存取都在TiKV,而我在前言中也提到数据库最容易出现瓶颈的就是IO,所以TiKV必然是最重要的优化模块。
TiKV的整体架构


从架构图上看出,TiKV的核心功能是事务控制(Transaction, MVCC),Raft模块保证数据写入多个副本,以及RocksDB进行真正的数据存取。
那么如何查找这些核心功能的性能问题呢?有一点原则始终有记住,性能问题说到底了就是系统资源的瓶颈问题,所以我们的查看重点,还是不外乎CPU,内存,磁盘。
回到Granafa,我们需要关注的关键指标主要有:
1)整体的状态
Cluster
Store size:每个 TiKV 实例的使用的存储空间的大小
Available size:每个 TiKV 实例的可用的存储空间的大小
Capacity size:每个 TiKV 实例的存储容量的大小
CPU:每个 TiKV 实例 CPU 的使用率
Memory:每个 TiKV 实例内存的使用情况
IO utilization:每个 TiKV 实例 IO 的使用率
2)TiDB事务监控
TiDB默认是采用TiDB 乐观事务模型,我们查看的指标主要有锁的占用等待时间
Scheduler - resolve_lock
Scheduler latch wait duration:由于 latch wait 造成的时间开销,正常情况下,应该小于 1s
3)Raft相关
Raft IO
Apply log duration:Raft apply 日志所花费的时间
Apply log duration per server:每个 TiKV 实例上 Raft apply 日志所花费的时间
Append log duration:Raft append 日志所花费的时间
Append log duration per server:每个 TiKV 实例上 Raft append 日志所花费的时间
如Raft apply日志花费时间过长,我们可以查看了TiKV服务器的IO占用情况,是否IO出现了瓶颈。
4)各个模块CPU使用情况
Thread CPU
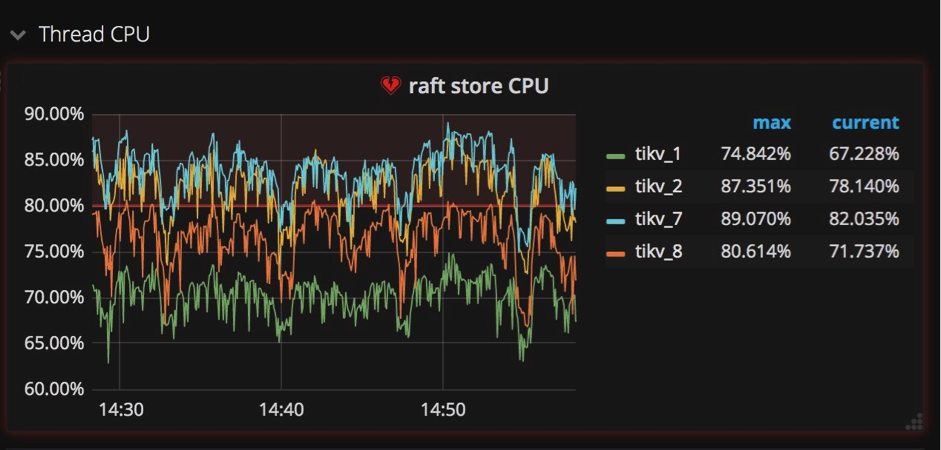
Raft store CPU:raftstore 线程的 CPU 使用率,通常应低于 80%
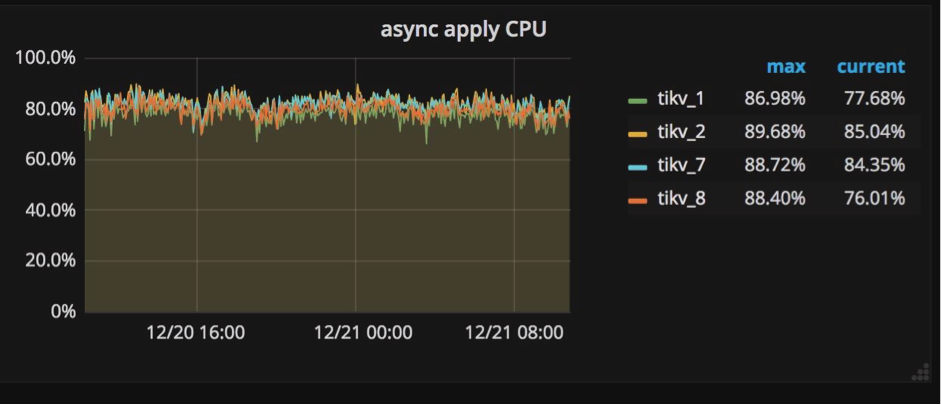
Async apply CPU:async apply 线程的 CPU 使用率,通常应低于 90%
Scheduler CPU:scheduler 线程的 CPU 使用率,通常应低于 80%
Scheduler worker CPU:scheduler worker 线程的 CPU 使用率
Storage ReadPool CPU:Readpool 线程的 CPU 使用率
Coprocessor CPU:coprocessor 线程的 CPU 使用率
Snapshot worker CPU:snapshot worker 线程的 CPU 使用率
Split check CPU:split check 线程的 CPU 使用率
RocksDB CPU:RocksDB 线程的 CPU 使用率
gRPC poll CPU:gRPC 线程的 CPU 使用率,通常应低于 80%
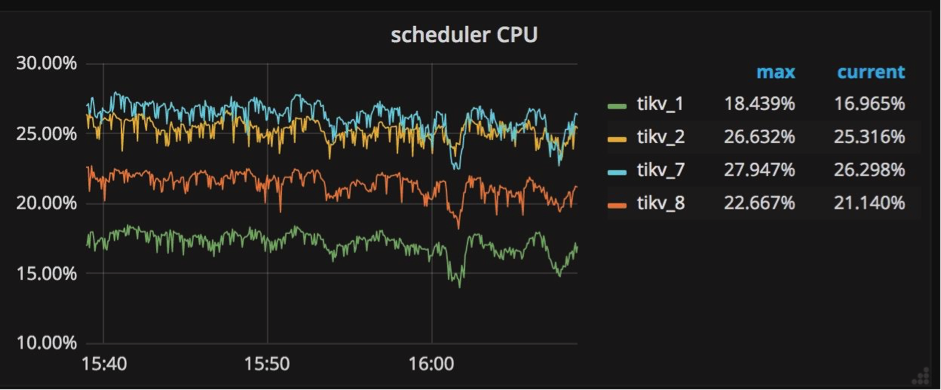
我们需要关注的主要指标有Scheduler Worker CPU, Raft Store CPU & Aysnc apply CPU。
Scheduler Worker CPU: 调度器
所有写入命令都被发送到调度器模型,然后被复制。调度器模型由一个调度线程和几个工作线程组成。为什么需要调度器模型?在向数据库写入数据之前,需要检查是否允许这些写命令,以及这些写命令是否满足事务约束。所有这些检查工作都需要从底层存储引擎读取信息,它们通过调度由工作线程来进行处理。
如果看到所有工作线程的 CPU 使用量总和超过 scheduler-worker-pool-size * 80% 时,就需要通过增加调度工作线程的数理来提高性能。
可以通过修改配置文件中 ‘storage’ 节的 ‘scheduler-worker-pool-size’ 来改变调度工作线程的数量。对于 CPU 核心数目小于 16 的机器,默认情况下配置了 4 个调度工作线程,其它情况下默认值是 8。参阅相关代码部分:scheduler-worker-pool-size = 4

Raft Store CPU & Aysnc apply CPU:raftstore进程与apply进程
像我前边提到的,我们在多节点之间使用Raft实现强一致性。在将一个键值对写入数据库之前,这个键值对首先要被复制成Raft log格式,同时还要被写入各个节点硬盘中保存。在Raft log被提交后,相关的键值对才能被写入数据库。
这样就产生两种写入操作:一个是写Raft log,一个是把键值对写入数据库。为了在TiKV中独立地执行这两种操作,我们创建一个raftstore进程,它的工作是拦截所有Raft信息,并写Raft log到硬盘中;同时我们创建另一个进程apply worker,它的职责是把键值对写到数据库中。在Grafana中,这两个进程显示在TiKV面板的子面板Thread CPU中(如下图所示)。它们都是极其重要的写操作负载,在Grafana中我们很容易就能发现它们相当繁忙。
为什么需要特别关注这两个进程?当一些TiKV服务器的apply或者raftstore进程很繁忙,而另一些机器却很空闲的时候,也就是说写操作负载不均衡的时候,这些比较繁忙的服务器就成了集群中的瓶颈。造成这种情况的一种原因是使用了单调递增的列,比如使用AUTOINCREMENT指定主键,或者在值不断增加的列上创建索引,例如最后一次访问的时间戳。
要优化这样的场景并消除瓶颈,必须避免在单调增加的列上设计主键和索引。
在传统单节点数据库系统上,使用AUTOINCREMENT关键字可以为顺序写入带来极大好处,但是在分布式数据库系统中,使所有组件的负载均衡才是最重要的。
5)RocksDB的情况
RocksDB – kv
RocksDB - kv
Write stall duration:由于 write stall 造成的时间开销,正常情况下应为 0
Memtable size:每个 CF 的 memtable 的大小
Memtable hit:memtable 的命中率
Block cache size:block cache 的大小。如果将
shared block cache禁用,即为每个 CF 的 block cache 的大小Block cache hit:block cache 的命中率
Block cache flow:不同 block cache 操作的流量
Read amplification:每个 TiKV 实例的读放大
Compression ratio:每一层的压缩比
需要关注的指标主要有 “Write Stall Duration”,Write Stall即“flush/compaction赶不上write rate的速度时,rockdb会降低write rate,甚至直接停写”。详细说明请见这里
美团点评 TiDB 深度实践之旅 这篇文章提供了一些解决方法参考,即
减缓 Raft Log Compact 频率(增大 raft-log-gc-size-limit、raft-log-gc-count-limit )
加快 Snapshot 速度(整体性能、包括硬件性能)
max-sub-compactions 调整为 3
max-background-jobs 调整为 12
level 0 的 3 个 Trigger 调整为 16、32、64
Block cache的命中率也是一个非常重要的指标,当block cache命中率过低时,我们可以通过参数调大列族的 block-cache-size 大小。可参考文档
如何对分布式 NewSQL 数据库 TiDB 进行性能调优
更加详细的关于RockDB调优,可参考
RocksDB Tuning Guide
其它优化定位问题方法
还有一个问题定位优化经常会用到的方法,就是查看日志,即相应模块的 log file。很多错误异常等信息都会记录在日志中。
还可以直接通过linux命令查看服务器IO,CPU,内存,系统日志等信息。
总结
学习新东西总是耗时的,本文也算是个人学习历程的一种总结,希望对大家有所帮助。
实际上,我的这些总结只能算是纸上谈兵。因为暂时没有硬件环境,无法进行测试。容器环境,其实只适合简单熟悉基本操作。
肯定文中存在不少错误,如有还请指正。
参考资料:
https://blog.csdn.net/qq_22727355/article/details/78795588
https://pingcap.com/docs-cn/stable/best-practices/massive-regions-best-practices/
https://asktug.com/t/topic/2026
https://blog.csdn.net/jing_flower/article/details/87922742
https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide
https://www.jianshu.com/p/2721da338904
https://www.bbsmax.com/A/gVdnDamEJW/
https://www.oschina.net/translate/how-to-do-performance-tuning-on-tidb
https://www.jianshu.com/p/ddf652aa4882?from=singlemessage
https://www.jianshu.com/p/4680bc2c2c65?utm_source=oschina-app
来源:oschina
链接:https://my.oschina.net/u/4340703/blog/4283434