Abstract
视觉问答(VQA)是一项具有挑战性的任务,已受到计算机视觉和自然语言处理社区的越来越多的关注。给定图像和自然语言的问题,就需要对图像的视觉元素和常识进行推理,以推断出正确的答案。在本调查的第一部分中,我们通过比较解决问题的现代方法来检查最新技术。我们通过它们将视觉和文本模态联系起来的机制对方法进行分类。特别是,我们研究了结合卷积神经网络和递归神经网络将图像和问题映射到公共特征空间的通用方法。我们还将讨论与结构化知识库交互的内存增强型和模块化体系结构。在本调查的第二部分,我们回顾了可用于培训和评估VQA系统的数据集。各种数据集包含不同复杂程度的问题,这些问题需要不同的推理能力和类型。我们深入研究了Visual Genome项目中的问题/答案对,并评估了带有结构图的图像与VQA场景图的注释的相关性。最后,我们讨论了该领域有希望的未来方向,特别是与结构化知识库的连接以及自然语言处理模型的使用。
1. Introduction
视觉问题解答是一项旨在将计算机视觉与自然语言处理(NLP)联系起来,促进研究并推动这两个领域界限的任务。一方面,计算机视觉研究了获取,处理和理解图像的方法。简而言之,其目的是教机器如何看。另一方面,NLP是涉及以自然语言实现计算机与人之间的交互的领域,即教学机器如何阅读以及其他任务。计算机视觉和NLP都属于人工智能领域,它们共享植根于机器学习的相似方法。但是,它们在历史上是分开发展的。在过去的几十年中,这两个领域均朝着各自的目标取得了重大进展,视觉和文本数据的爆炸性增长正推动着这两个领域的共同努力。例如,图像字幕研究,即自动图像描述[15,35,54,77,93,85]产生了强大的方法,可以共同从图像和文本输入中学习以形成更高级别的表示。一种成功的方法是将经过对象识别训练的卷积神经网络(CNN)与经过大文本语料库训练的单词嵌入相结合。
以最常见的视觉问题解答(VQA)形式,向计算机显示图像和有关该图像的文本问题(请参见图3-5中的示例)。然后,它必须确定正确的答案,通常是几个单词或一个简短的短语。变体包括二进制(是/否)[3,98]和多项选择设置[3,100],其中提出了候选答案。一个密切相关的任务是“填空” [95],其中描述图像的确认必须以一个或几个缺失的单词完成。这些肯定实质上等于声明性问题。 VQA和计算机视觉中其他任务之间的主要区别在于,要回答的问题要等到运行时才能确定。在诸如分割或对象检测之类的传统问题中,要由算法回答的单个问题是预先确定的,只有输入图像发生变化。相反,在VQA中,问题的答案形式以及答案所需的操作集都是未知的。从这个意义上讲,它更紧密地反映了一般图像理解的挑战。 VQA与文本问题解答的任务有关,其中答案可以在特定的文本叙述中(即阅读理解)或在大型知识库中(即信息检索)找到。文本质量检查已在NLP社区中进行了很长时间的研究,而VQA是其对其他可视化支持信息的扩展。由于图像的尺寸要高得多,而且通常比纯文本更嘈杂,因此增加了挑战。此外,图像缺乏语言的结构和语法规则,并且没有直接等价于NLP工具的功能,例如语法解析器和正则表达式匹配。最后,图像捕获了更多的现实世界,而自然语言已经代表了更高的抽象水平。例如,将“一顶红色的帽子”一词与人们可以想象到的多种表达方式进行比较,在这种表达方式中,短句无法描述许多样式。
视觉问答比图像字幕要复杂得多,因为它经常需要图像中不存在的信息。这种额外所需信息的类型范围可以从常识到关于图像中特定元素的百科全书知识。在这方面,VQA构成了真正的AI完整任务[3],因为它需要超出单个子域的多模式知识。这可以缓解人们对VQA的兴趣,因为它提供了代理来评估我们在能够将高级推理与深度语言和图像理解相结合的AI系统方面的进展。请注意,原则上可以通过图像标题对图像理解进行同样的评估。但是,实际上,VQA的优点在于易于评估。答案通常只包含几个单词。长地面真相图像字幕更难与预测图像字幕相比较。尽管已经研究了高级评估指标,但这仍然是一个开放的研究问题[43、26、76]。
视觉和语言的最早集成之一是1972年的系统中的“ SHRDLU” [84],它允许用户使用语言来指示计算机在“块状世界”中移动各种对象。 创建对话式机器人代理的最新尝试[39、9、55、64]也扎根于视觉世界。 但是,这些作品通常仅限于特定领域和/或受限语言形式。 相比之下,VQA专门解决自由格式的开放式问题。 对VQA的日益增长的兴趣是由计算机视觉和NLP中成熟技术的存在以及相关大规模数据集的可用性推动的。 因此,最近几年出现了大量有关VQA的文献。 本次调查的目的是对该领域进行全面概述,涵盖模型,数据集,并提出有希望的未来方向。 据我们所知,本文是VQA领域中的第一篇调查。
在本调查的第二部分(第3节)中,我们检查了可用于培训和评估VQA系统的数据集。这些数据集在三个维度上差异很大:(i)它们的大小,即图像,问题和表示的不同概念的数量。 (ii)所需推理的数量,例如检测单个物体是否足够,或者是否需要对多个事实或概念进行推断,以及(iii)实际图像中存在的信息以外,还需要多少信息,无论是常识还是特定于主题的信息。我们的评论指出,现有的数据集倾向于视觉水平的问题,几乎不需要外部知识,只有很少的例外[78,79]。这些特征反映了当前技术水平仍面临着简单的视觉问题的挣扎,但是当将VQA表示为AI完整的评估代理时,不能忘记这些特征。我们得出结论,最终将需要更多不同和复杂的数据集。该调查的另一个重要贡献是对可视基因组数据集(第4节)中提供的问题/答案对的深入分析。它们构成了撰写本文时可用的最大的VQA数据集,而且重要的是,它包括场景图形式的丰富结构化图像注释[41]。通过比较所提供的问题,答案和图像注释中涉及的概念的出现,我们评估了这些注释与VQA的相关性。我们发现,只有大约40%的答案与场景图中的元素直接匹配。我们进一步表明,通过将场景图与外部知识库相关联,可以大大提高这种匹配率。在第5节中,我们将通过讨论更好地与此类知识库建立联系的潜力来结束本文-更好地利用NLP领域中的现有工作。
2. Methods for VQA
Malinowski等人提出了“开放世界”视觉问题解答的最早尝试之一。 [51]。他们描述了一种将贝叶斯公式中的语义文本分析与图像分割相结合的方法,该方法从训练集中的最近邻居中采样。该方法需要人工定义的谓词,这些谓词不可避免地是特定于数据集的,并且难以扩展。它还非常取决于图像分割算法和估计的图像深度信息的准确性。 Tu等人在VQA上的另一项早期尝试。 [74]是基于文本和视频的联合解析图。在[23]中,Geman等人。提出了一种自动的“查询生成器”,其在带注释的图像上进行训练,然后从任何给定的测试图像中生成一系列二进制问题。这些早期方法的共同特征是将问题限制为预定义的形式。本文的其余部分重点介绍旨在回答自由形式的开放式问题的现代方法。我们将通过四个类别介绍方法:联合嵌入方法,注意机制,组成模型和知识库增强方法。如表2所示,大多数方法结合了多种策略,因此属于几类。

2.1 Joint embedding approaches
Motivation:图像和文本联合嵌入的概念首先是为图像字幕的任务而开发的[15,35,54,77,93,85]。它是由计算机视觉和NLP中的深度学习方法的成功所激发的,这些方法允许人们在一个公共的特征空间中学习表示。与图像字幕的任务相比,在VQA中,由于需要对两种模式一起执行进一步推理,因此进一步增强了这一动机。公共空间中的表示允许学习交互作用,并对问题和图像内容进行推理。实际上,图像表示是通过对目标识别进行预训练的卷积神经网络(CNN)获得的。文本表示是通过在大型文本语料库上预训练的单词嵌入来获得的。单词嵌入实际上将单词映射到一个距离,该距离反映了语义上的相似性[56,61]。然后将问题的单个单词的嵌入通常馈送到递归神经网络以捕获语法模式并处理可变长度序列。
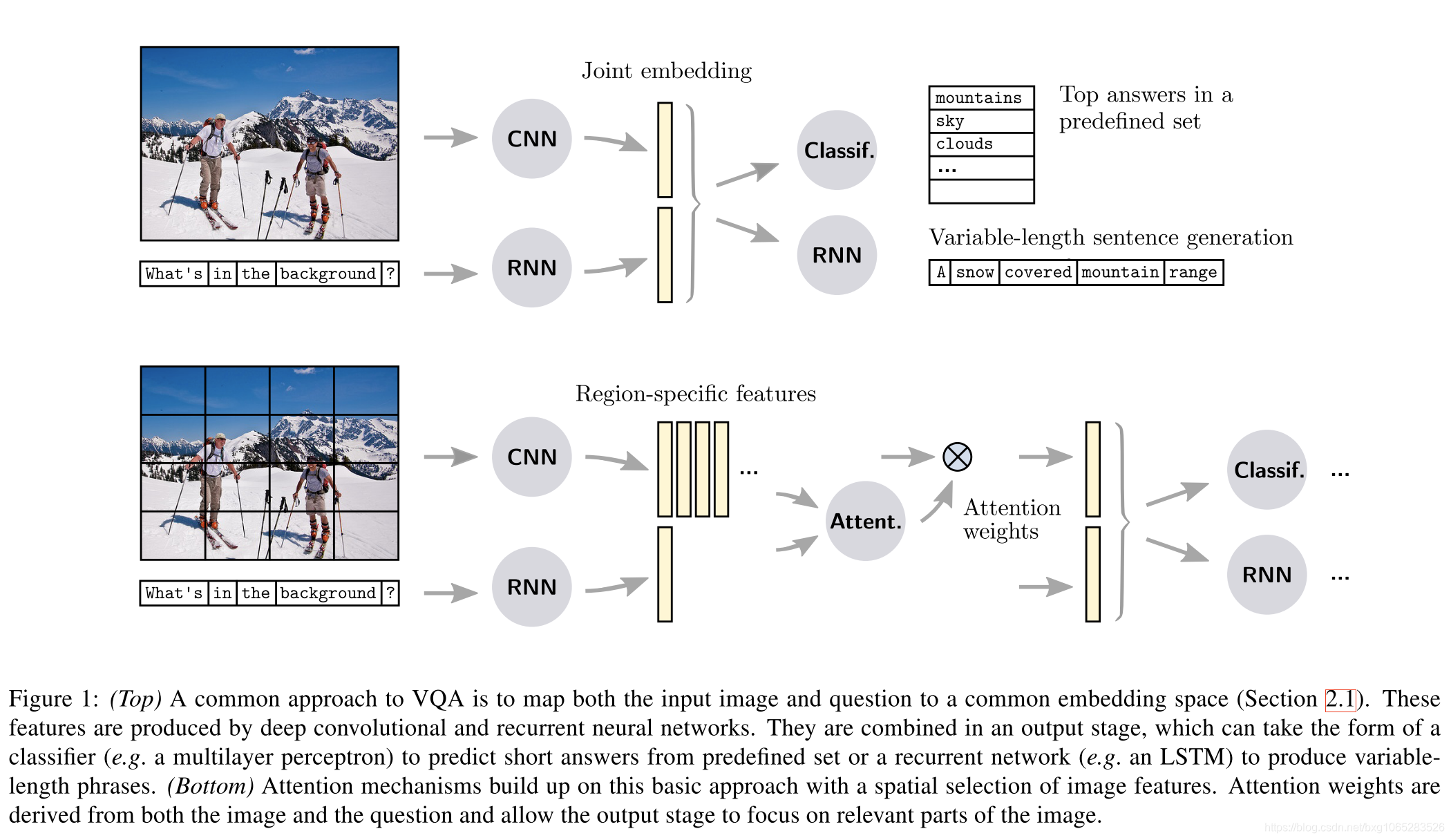
Methods:Malinowski等[52]提出了一种名为“神经图像-QA”的方法,该方法通过递归神经网络(RNN)与长短期记忆单元(LSTM)一起实现(图1)。 RNN背后的动机是处理可变大小的输入(问题)和输出(答案)。图像特征是由经过预训练的用于物体识别的CNN产生的。问题和图像特征都一起馈送到第一个“编码器” LSTM。它产生固定大小的特征向量,然后将其传递到第二个“解码器” LSTM。解码器产生变长答案,每个循环迭代一个字。在每次迭代中,最后一个预测的单词将通过循环循环馈入LSTM,直到预测出特殊的<END>符号。提出了这种方法的几种变体。例如,Ren等人的“ VIS + LSTM” [63]直接将编码器LSTM产生的特征向量输入分类器,以从预定义的词汇表中生成单字答案。换句话说,他们将答案表述为分类问题,而Malinowski等人则将其作为分类问题。 [52]将其视为序列生成程序。任等人。 [63]用“ 2-VIS + BLSTM”模型提出了其他技术改进。它使用两个图像特征源作为输入,并在疑问句的开头和结尾处将其馈送到LSTM。它还使用LSTM向前和向后扫描问题。这些双向LSTM更好地捕获了问题中遥远单词之间的关系。
高等。 [22]提出了一种略有不同的方法,称为“多峰质量保证”(mQA)。 它使用LSTM编码问题并产生答案,与[52]有两个区别。 首先,[52]使用编码器和解码器LSTM之间的公共共享权重,而mQA学习不同的参数,并且仅共享单词嵌入。 这是由问题和答案的潜在不同属性(例如,在语法方面)引起的。 其次,用作图像表示的CNN特征不会在问题之前馈入编码器,而是在每个时间步入。
Noh等。 [58]通过学习带有动态参数层(DPPnet)的CNN来解决VQA,该动态参数层的权重是根据问题来自适应确定的。 对于自适应参数预测,他们采用了一个单独的参数预测网络,该网络由门控循环单元(GRU,LSTM的一种)组成,该单元以问题为输入,并通过其输出的完全连接层产生候选权重。 与[52,63]相比,这种安排可显着提高回答准确性。 在此问题被用来根据每个特定实例量身定制主要计算的意义上,人们可以注意到与第2.3节的模块化方法在精神上具有相似性。
福井等[21] 提出了一种合并方法来执行视觉和文本特征的联合嵌入。 他们通过将图像和文本特征随机投影到高维空间来执行“多峰紧凑双线性池”(MCB),然后将两个向量与傅立叶空间中的乘法进行卷积以提高效率。 Kim等。 [38]使用多模式残差学习框架(MRN)来学习图像和语言的联合表示。 Saito等。 [65]提出了一个“ DualNet”,它集成了两种操作,即逐元素求和和逐元素乘法,以嵌入其视觉和文本特征。 与[63,58]类似,他们将答案公式化为一组可能的答案的预定义问题。 Kafle等。 [34]集成了对问题的预期答案类型的显式预测,并在贝叶斯框架中制定了答案。
其他一些作品没有利用RNN编码问题。 Ma等。 [49]使用CNN处理问题。 来自图像CNN和文本CNN的特征通过其他层(“多峰CNN”)嵌入到公共空间中,从而形成总体上同类的卷积结构。 周等。 [99]和Antol等。 [3]都使用问题的传统词袋表示。
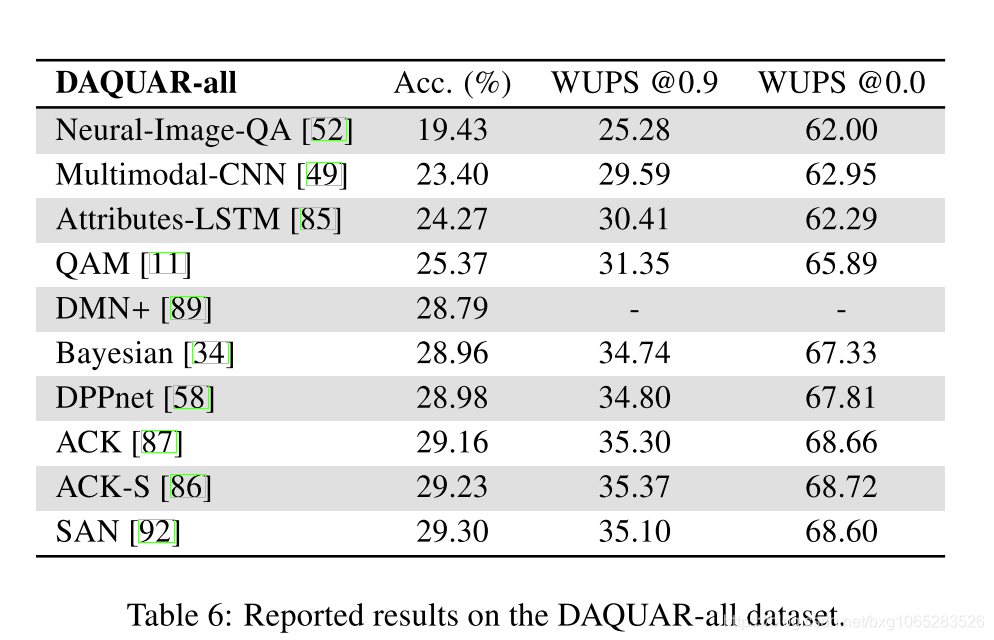
Performance and limitations:我们在表6–9中总结了所有讨论的方法和数据集的性能。 作为最早引入的方法之一,“ Neural-Image-QA”被认为是事实上的基线结果。 “ 2-VIS + BLSTM”在DAQUAR数据集上略有改善,这主要归功于用于编码问题的双向LSTM。 不幸的是,“ mQA”模型并未在公开的数据集上进行测试,因此无法比较。 DPPnet [58]通过动态参数层自适应地为每个问题量身定制计算,从而显示出显着的优势。 在其出版时,它的性能优于其他联合嵌入方法[52,63,3,99]。 最新的MCB池[21]和多模式残差学习(MRN)带来了进一步的改进,并在撰写本文时取得了最佳性能。
联合嵌入方法的原理很简单,并且构成了当前大多数VQA方法的基础。 以MCB和MRN为例,最新的改进仍然显示出特征提取及其向嵌入空间的投影方面潜在的改进空间。
2.2 Attention mechanisms
Motivation:上面介绍的大多数模型的局限性是使用全局(整个图像)功能来表示视觉输入。 这可以将无关或嘈杂的信息馈送到预测阶段。 注意机制的目的是通过使用局部图像特征来解决此问题,并允许模型为来自不同区域的特征分配不同的重要性。 Xu等人在图像字幕的背景下提出了对视觉任务的早期关注。 [91]。 他们模型的注意力成分识别图像中的显着区域,然后进一步的处理将字幕生成集中在这些区域上。 这个概念很容易转化为VQA的任务,即专注于与问题相关的图像区域。 在某些方面,注意过程会在推理过程中强制执行一个明确的附加步骤,该步骤会在执行进一步计算之前识别“要看的地方”。
尽管注意力模型的灵感来自人类视觉的计算模型,但与生物系统的明显相似可能会产生误导。 人工神经网络中的注意力可能会通过允许其他非线性和/或相互作用类型(例如,通过注意力权重进行的乘法相互作用)而有所帮助,而生物视觉系统中的注意力更可能是有限资源(例如分辨率,视野, 和处理能力。
Methods: 朱等。 [100]描述了如何增加对标准LSTM模型的空间关注。 注意力增强型LSTM进行的计算描述如下:
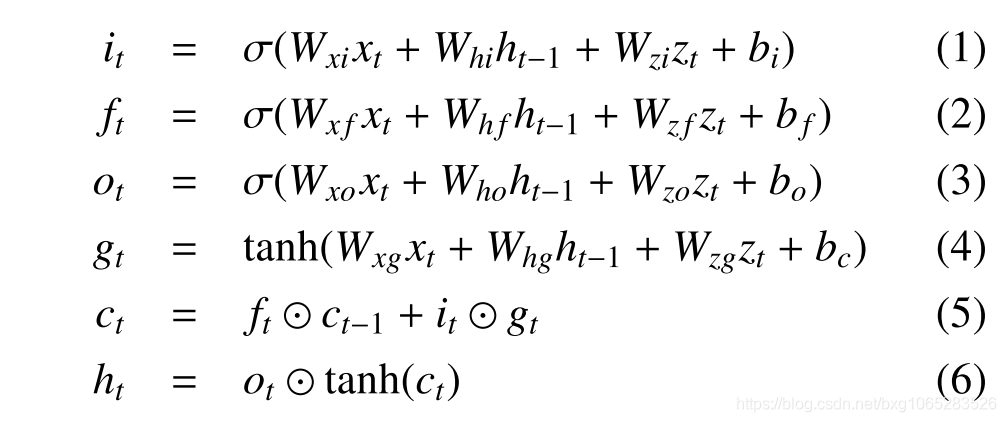
其中 是S型非线性,,,是LSTM的输入,忘记,记忆和输出状态。 各种W和b矩阵都是经过训练的参数,并且表示具有门值的按元素乘积。 是输入(例如问题的单词),是时间步t的隐藏状态。 注意机制由术语引入,是卷积特征的加权平均值,取决于先前的隐藏状态和卷积特征:
是S型非线性,,,是LSTM的输入,忘记,记忆和输出状态。 各种W和b矩阵都是经过训练的参数,并且表示具有门值的按元素乘积。 是输入(例如问题的单词),是时间步t的隐藏状态。 注意机制由术语引入,是卷积特征的加权平均值,取决于先前的隐藏状态和卷积特征:
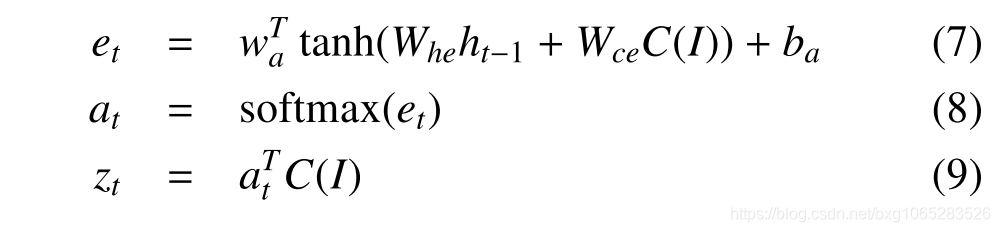
其中C(I)表示图像I的卷积特征图。注意项at设置了第t步中每个卷积特征的贡献。 中的较大值表示相应区域与问题的相关性更高。 在这种表述中,可以将标准LSTM视为特例,其值在统一设置,即每个区域的贡献相等。 Jiang等[32]采用了与上述类似的机制。
Chen等[11]使用不同于上述单词引导注意的机制。他们通过在空间图像特征图中搜索与输入问题的语义相对应的视觉特征来生成“问题导向的注意力图”(QAM)。通过将视觉特征图与可配置的卷积内核进行卷积来实现搜索。通过将问题嵌入从语义空间转换为视觉空间来生成此内核,该视觉空间包含由问题意图确定的视觉信息。杨等。[92]也将这种方案与“堆叠式注意力网络”(SAN)结合使用,以迭代方式得出答案。徐等。 [90]提出了一种“多跳图像注意方案”(SMem)。第一跳是单词引导的注意力,而第二跳是问题引导的。在[66]中,作者生成带有对象建议的图像区域,然后选择与问题和可能的答案选择相关的区域。同样,Ilievski等。 [29]采用现成的物体检测器来识别与问题关键词相关的区域,然后通过LSTM将来自具有全局特征的区域的信息融合在一起。 Lu等。 [48]提出了一个“分层的共同注意模型”(HieCoAtt),它共同引起关于图像和问题注意的原因。尽管上述作品仅关注视觉注意力,但HieCoAtt可以对称地处理图像和问题,从某种意义上说,图像表示可以引导人们注意问题,反之亦然。最近,Fukui等人。 [21]将注意力机制结合到了第2.1节中已经提到的“多峰紧凑双线性池”(MCB)中。
安德里亚斯等[2]以不同的方式运用注意力机制。 他们提出了一个组成模型,该模型可以根据针对每个问题的模块构建神经网络,如2.3.1节中所述。 这些模块中的大多数模块都在关注的空间中操作,或者从图像生成关注图(即,识别一个显着的对象),执行一元操作(例如,将注意从对象转化为周围的上下文),或者关注之间的交互( 例如从另一个减去注意图)。
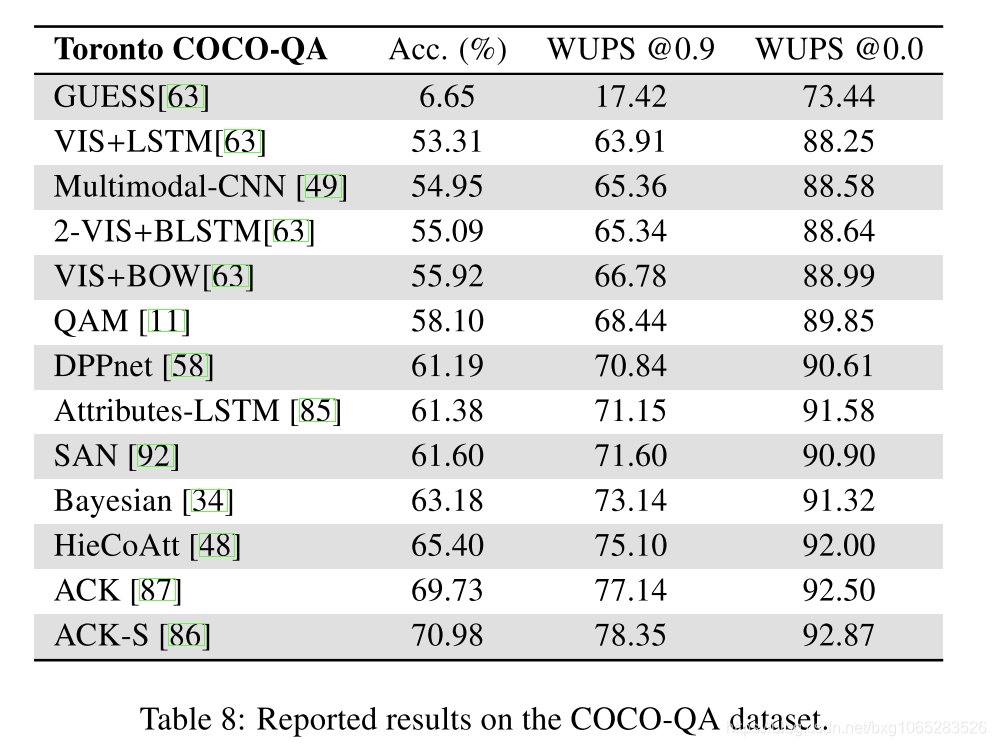
Performance and limitations:所报告的注意机制的使用总是比使用全局图像功能的模型有所改进。 例如,[100]中的作者表明,在Visual7W数据集的“演讲”和“接地”任务中,上述增强注意力的LSTM优于“ VIS + LSTM”模型[63](请参见第3.1节)。 。 SAN的多个关注层[92]仅对一层关注[32,11]带来了进一步的改进,尤其是在VQA数据集上。 HieCoAtt模型[48]显示了问题的分层表示以及共同注意机制(问题指导的视觉注意和图像指导的问题关注)的好处。
有趣的是,注意力机制提高了所有VQA数据集的整体准确性,但按问题类型进行更仔细的检查显示,对二进制(是/否)问题几乎没有好处。一种假设是二元问题通常需要更长的推理链,而开放式问题通常只需要从图像中识别和命名一个概念。因此,改善二元问题可能会需要除视觉关注之外的其他创新。端到端联合嵌入方法的输出(无论使用注意力如何)是通过从大量嵌入的视觉和文本特征到答案的简单映射而得出的,而这些映射是从大量的培训示例中学到的。关于如何提高输出答案的了解很少。可以争论在映射中是否执行和/或编码了任何“推理”。通过询问是否可以仅从给定的视觉输入中回答问题来提出另一个重要问题。通常,他们需要先验知识,范围从常识到特定主题甚至专家级知识。如何将此类信息提供给VQA系统以及如何将其纳入推理仍是一个悬而未决的问题(请参见第2.4节)。
2.3 Compositional Models
迄今为止讨论的方法存在与用于提取图像和句子表示的CNN和RNN的整体性质有关的限制。人工神经网络设计中越来越流行的研究方向是考虑模块化体系结构。这种方法涉及连接为特定的所需功能(例如内存或特定类型的推理)设计的不同模块。一个潜在的优势是更好地利用监督。一方面,由于可以在不同的总体体系结构和任务中使用和培训相同的模块,因此它便于进行迁移学习(请参阅第2.3.1节)。另一方面,它允许使用“深度监督”,即优化取决于内部模块输出的目标(例如,关注机制应关注的支持事实[83])。在第2.2节(注意力模型)和第2.4节(与知识库的连接)中讨论的其他模型也属于模块化体系结构类别。在这里,我们关注两个主要在模块化方面做出贡献的特定模型,即神经模块网络(NMN)和动态内存网络(DMN)。
2.3.1 Neural Module Networks
Motivation:神经模块网络(NMN)由Andreas等人在[2]中介绍,并在[1]中进行了扩展。 它们是专门为VQA设计的,旨在利用问题的构成语言结构。 问题的复杂程度差异很大。 例如,这是卡车吗? 仅需要从图像中检索一条信息,而烤面包机的左侧有多少个对象? 需要多个处理步骤,例如识别和计数。 NMN反映了问题中每个问题实例的实时组装问题的复杂性。 该策略与文本QA [44]中的方法有关,该方法使用语义解析器将问题转换为逻辑表达式。 NMN的重要贡献是将这种逻辑推理应用于连续的视觉特征,而不是离散或逻辑谓词。
Method:该方法基于使用NLP社区中众所周知的工具对问题进行的语义解析。 解析树变成预定义集中的模块的组合,然后将它们一起用于回答问题。 至关重要的是,所有模块都是独立且可组合的(图2)。 换句话说,针对每个问题实例执行的计算将有所不同,并且在测试时的问题实例可能会使用一组在训练过程中未一起看到的模块。
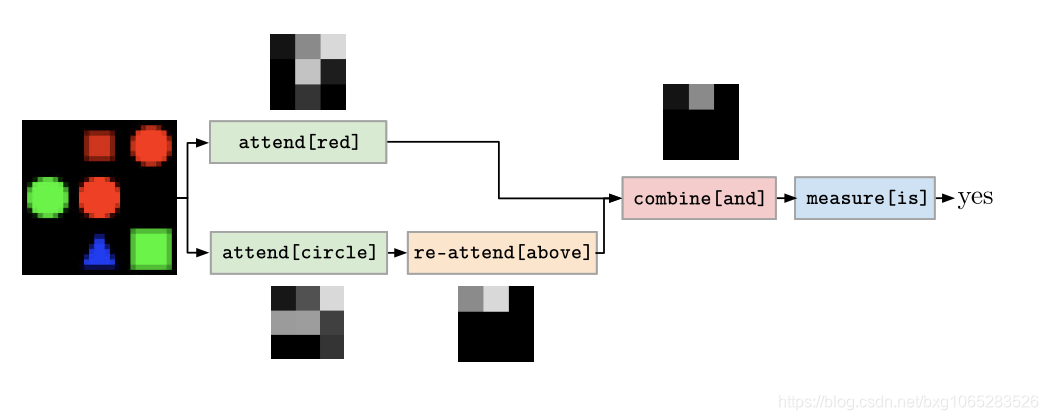
模块的输入和输出可以是三种类型:图像特征、对图像的关注(区域)和标签(分类决策)。一组可能的模块是预定义的,每个模块都根据其输入和输出的类型来定义,但是它们的确切行为将通过对特定问题实例的端到端培训来获得。因此,培训不需要额外的监督,只需要三个图像、问题和答案。
问题的解析是一个关键的步骤,它是由斯坦福德依存关系解析器[来完成的,该解析器基本上识别句子各部分之间的语法关系。然后,NMNs的作者使用特别的手写规则,以模块组合的形式,确定性地将解析树转换成结构化查询,[2]。在他们的第二篇论文《[1》中,他们还学习了一个排序函数,从候选解析中选择最佳结构。整个过程仍然对问题中的语言使用强有力的简化假设。视觉特征是由一个固定的,预先训练的VGG CNN[68]。
Performance and limitations:神经模块网络在VQA基准上进行了评估,显示出与竞争方法不同的优势和劣势。它通常在具有组合结构的问题上胜过竞争对手,例如要求定位一个对象并描述其属性之一。然而,VQA数据集中的许多问题都非常简单,并且几乎不需要合成或推理。作者介绍了一个新的数据集,命名为“形状”,合成图像(第3.4节)与复杂的问题配对,涉及空间关系,集合论推理,形状和属性识别。
该方法的局限性是问题解析过程中形成的瓶颈所固有的。此阶段修复网络结构,错误无法恢复。此外,模块的组装使用了问题的积极简化,抛弃了一些语法线索。作为一种变通方法,作者通过将他们的输出与经典LSTM问题编码器的输出进行平均来获得最终答案。
由于VQA基准中缺乏真正复杂的问题,国家监测网络的潜力在实践中变得暗淡。在这个数据集上报告的结果使用可能模块的受限子集,大概是为了避免过度拟合。在合成形状数据集上的结果表明,语义结构预测确实提高了深层网络的泛化能力。整体方法展现了解决在开放世界的VQA可能出现的概念和关系组合爆炸的潜力。最后,注意NMNs的一般公式可以包含其他方法,包括下面给出的记忆网络,其可以被公式化为“注意”和“分类器”模块的组合。
2.3.2 Dynamic Memory Networks
Motivation:动态记忆网络(DMN)是具有特定模块化结构的神经网络。在[42]中描述了它们,同时提出了一些变体[83,70,8,59]。其中大部分应用于文本质量保证。在这里我们重点介绍熊等人的作品,他们把这些作品改编成的作品。DMNs属于内存扩充网络的更广泛的类别,它对输入的内部表示执行读写操作。这种机制类似于注意力(参见第2.2节),旨在通过对数据的多个部分之间的多次交互进行建模来解决需要复杂逻辑推理的任务。
Method:动态存储网络由4个主要模块组成,[42]允许其特定实现的独立性。输入模块将输入数据转换成一组称为“事实”的向量。它的实现(如下所述)因输入数据的类型而异。问题模块使用门控递归单元(GRU,LSTM的变体)计算问题的向量表示。情节记忆模块检索回答问题所需的事实。他们的关键是允许情节记忆模块多次传递事实,以允许传递性推理。它结合了选择相关事实的注意机制和从当前状态和检索到的事实之间的交互中生成新的内存表示的更新机制。第一个状态用问题模块的表示进行初始化。最后,答案模块使用记忆和问题的最终状态来预测输出,对于单个单词使用多项式分类,对于需要较长句子的数据集使用GRU分类。
VQA·[89]的输入模块用VGG CNN[68]在小图像块上提取图像特征。这些特征以句子的语言形式被输入到GRU,以蛇一样的方式穿越图像。这是对[42中原始输入模块的特别改编,该模块使用GRU来处理句子中的单词。情节记忆模块还包括关注特定图像区域的注意机制。
让我们也在这里提到诺赫等人的工作[57]。他们的方法与内存网络的相似之处在于使用一个类似内存的内部单元,在这个单元上执行多次传递。主要的新颖之处是在每一次传递中使用一个损失,而不是在最终结果中使用一个损失。在训练之后,测试时的推断只使用一次这样的通过。
Performance and limitations:在DAQUAR和VQA基准上评估了动态内存网络,并显示了所有类型问题的竞争性能。与神经模块网络(第2.3.1节)相比,它们在是/否问题上表现相似,在数字问题上稍差,但在所有其他类型的问题上明显更好。计数的问题可能源于固定图像块的有限粒度,它可能跨越对象边界。
有趣的是,除了输入模块之外,该论文使用了基本相同的方法,在VQA和基于文本的问答[89]上展示了竞争结果。使用[82]的基于文本的问答数据集需要对多个事实进行推理,这是该模型推理能力的一个积极指标。对文本和图像应用相同模型的一个潜在批评来自于单词序列和图像块序列的本质不同。文本叙事的时间维度不同于相对的几何位置,尽管两者在实践中似乎都被GRUs充分处理。
2.4 Models using external knowledge bases
Motivation:VQA的任务包括理解图像的内容,但通常需要事先的非视觉信息,范围从“常识”到特定主题甚至百科知识。例如,为了回答“这张图片中出现了多少哺乳动物?”,人们必须理解“哺乳动物”这个词,并知道哪些动物属于这一类。这一观察允许精确定位联合嵌入方法的两个主要弱点(第2.1节)。首先,他们只能捕获训练集中存在的知识,很明显,扩大数据集的努力永远无法覆盖真实世界。第二,用这种方法训练的神经网络能力有限,不可避免地会被我们想要学习的信息量所超越。
另一种方法是将推理(例如作为神经网络)与数据或知识的实际存储分离。大量的研究致力于知识的结构化表示。这导致了大规模知识库(KB)的发展,如DBpedia[5]、Freebase[7]、YAGO[27,50]、OpenIE[6,17,18]、NELL[10]、WebChild[73,72]和ConceptNet[47]。这些数据库以机器可读的方式存储常识和事实知识。每一段知识,称为事实,通常表示为三元组(arg1、rel、arg2),其中arg1和arg2表示两个概念,rel表示它们之间的关系。这些事实的集合形成一个相互关联的图,该图通常根据资源描述框架(RDF[24])规范进行描述,并且可以由查询语言(如SPARQL[62])访问。将这些知识库与VQA方法相连接,可以将推理与先前知识的表示以实用和可伸缩的方式分离。
Method:Wang等人[78]提出了一个名为“Ahab”的VQA框架,它使用了DBpedia,一个最大的结构化知识库。视觉概念首先用CNNs从给定的图像中提取,然后与DBpedia中表示相似概念的节点相关联。鉴于联合嵌入方法(第2.1节)学习从图像/问题到答案的映射,作者建议在此学习将图像/问题映射到构建的知识图上的查询。最后的答案是通过汇总这个查询的结果得到的。[78]的主要限制是处理有限类型的问题。虽然这些问题可以用自然语言提供,但它们是使用手动设计的模板解析的。FVQA[79]改进的方法使用LSTM和数据驱动的方法来学习图像/问题到查询的映射。这项工作还使用了另外两个知识库ConceptNet和WebChild。
知识的显式表示的一个有趣的副产品是,上述方法可以通过提供推理过程中使用的推理链[78]或支持事实[79]来指示它们是如何得到答案的。这与单片神经网络形成了鲜明对比,后者对产生最终答案所进行的计算几乎没有洞察力。
Wu等人[87]提出了一种联合嵌入方法,该方法也受益于外部知识库。给定一幅图像,他们首先用CNN提取语义属性。然后,从包含简短描述的DBpedia版本中检索与这些属性相关的外部知识,这些描述通过Doc2Vec嵌入到固定大小的向量中。嵌入的向量被输入到LSTM模型中,LSTM模型用问题解释它们,并最终生成答案。此方法仍然学习从问题到答案的映射(与其他联合嵌入方法一样),并且无法提供有关推理过程的信息。
Performance and limitations:Ahab和FVQA都特别关注需要外部知识的视觉问题。大多数现有的VQA数据集包含了大多数需要少量先验知识的问题,因此这些数据集的性能很难反映这些方法的特定功能。因此,这两种方法的作者包括对新的小规模数据集的评估(见第3.3节)。Ahab[78]在总体准确性方面明显优于其KB-VQA数据集[78]的联合嵌入方法(69.6%比44.5%)。特别是,Ahab在需要更高水平知识的视觉问题上比联合嵌入方法明显更好。同样地,FVQA方法[79]也比传统方法[79]在总的前1名准确率方面表现得更好(58.19%对23.37%)。这两种方法的评价问题是问题类型的数量有限和数据集的规模较小。
吴等人的方法。[87]在多伦多COCO-QA和VQA数据集上进行了评估,显示了使用外部知识库在平均准确性方面的优势。
3. Datasets and evaluation
为了研究虚拟质量保证(VQA),人们提出了大量的数据集。它们至少包含由图像、问题及其正确答案组成的三元组。有时还提供附加注释,例如图像标题、支持答案的图像区域或多项选择候选答案。数据集内的数据集和问题在其复杂性、推理量和推断正确答案所需的非视觉(如“常识”)信息方面有很大差异。本节包含对可用数据集的全面比较,并讨论它们对评估VQA系统不同方面的适用性。我们根据数据集的图像类型(自然的、剪贴画的、合成的)对其进行广泛的分类。表3.1总结了关键特性。有关各种数据集的示例,请参见图3-5。
给定的数据集通常用于训练和评估VQA系统。然而,这项任务的开放性表明,其他大规模的信息来源将是有益的,而且可能是培训实际VQA系统的必要条件。一些数据集通过在结构化的非可视化知识库中对支持事实的注释来专门解决这个问题(第3.3节)
其他非VQA专用的数据集值得一提。它们针对涉及视觉和语言的其他任务,例如图像字幕(例如[12、26、45、94])、生成[53]和理解[36、28]引用表达式,以检索自然语言中的图像和对象。这些数据集超出了本文的讨论范围(请参见[19]以获取评论),但它们是VQA额外训练数据的潜在来源,因为它们将图像与文本注释结合在一起。
3.1 Datasets of natural images
Geman等人[23]提出了一项早期的工作,即为VQA专门编译一个数据集。数据集包含从对象、属性和对象之间关系的固定词汇表的模板生成的问题。Tu等人在[74]中提出了另一个早期数据集。他们研究了视频和文本的联合解析来回答查询,并考虑了两个数据集,每个数据集包含15个视频片段。这两个例子仅限于有限的设置和相对较小的规模。下面我们将讨论目前使用的开放世界大型数据集。
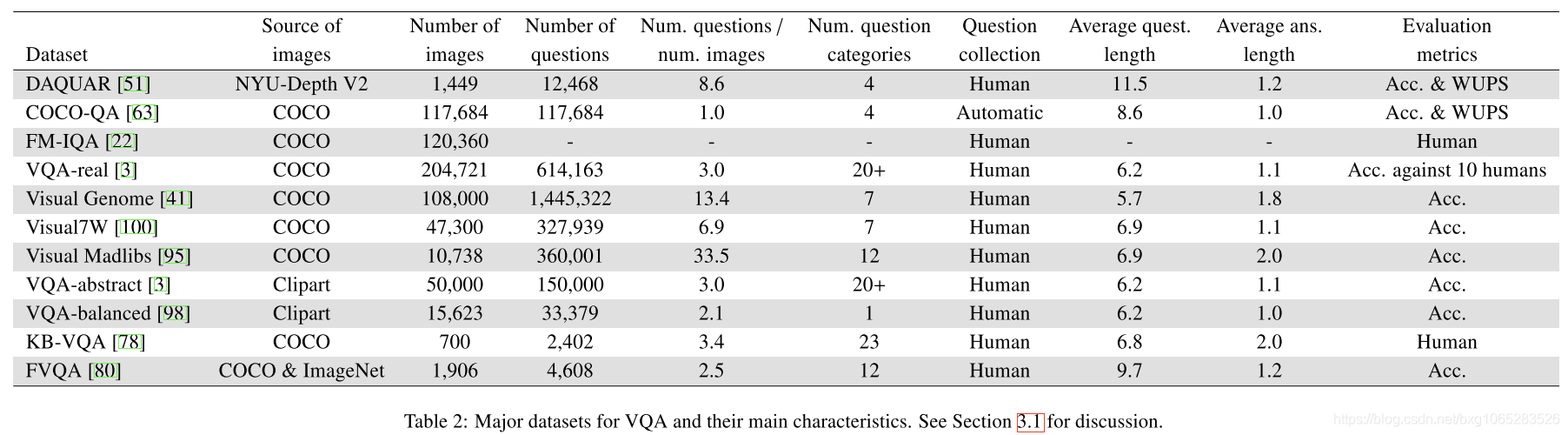
DAQUAR:作为基准设计的第一个VQA数据集是DAQUAR,用于在真实世界图像上回答问题的数据集[51]。它是用纽约大学深度v2数据集[67]中的图像构建的,该数据集包含1449个室内场景的RGBD图像,以及带注释的语义分段。DAQUAR的图像被分成795个训练和654个测试图像。收集两类问答对。首先,使用8个预定义模板和纽约大学数据集的现有注释自动生成合成问题/答案。其次,从5个注释者那里收集人类的问题/答案。他们被要求关注基本的颜色、数字、对象(894个类别)以及这些对象的集合。总共收集了12468对问答,其中6794对用于培训,5674对用于测试。大尺寸的DAQUAR是利用深层神经网络开发和训练VQA早期方法的关键[52,63,49]。DAQUAR的主要缺点是将答案限制在预先定义的16种颜色和894个对象类别上。数据集还显示出强烈的偏见,表明人类倾向于关注一些突出的物体,如桌椅[51]。
COCO-QA:COCO-QA数据集[63]代表了为提高VQA的训练数据规模所做的大量努力。此数据集使用来自Microsoft Common Objects in Context data(COCO)数据集[45]的图像。COCO-QA包含123287个图像(训练用72783个,测试用38948个),每个图像有一对问答。它们是通过将原始COCO数据集的图像描述部分转换为问答形式自动生成的。这些问题根据预期答案的类型分为四类:对象、数字、颜色和位置。字幕自动转换的一个副作用是问题的高重复率。在38948道试题中,9072道(23.29%)也作为训练题出现。
FM-IQA:FM-IQA(自由式多语种即时问答)数据集[22]使用123287张图片,也来自COCO数据集。COCO-QA的不同之处在于,这里的问题/答案是由人类通过Amazon Mechanical Turk群组采购平台提供的。注释者可以自由地给出任何类型的问题,只要它们与每个给定图像的内容相关。这导致问题的多样性比以前可用的数据集要大得多。回答这些问题通常既需要理解图像的视觉内容,也需要包含先前的“常识”信息。该数据集包含120360幅图片和250560对问答,这些图片最初是用中文提供的,然后由人工翻译成英文。
VQA-real:最广泛使用的数据集之一来自弗吉尼亚理工大学的VQA团队,通常简称为VQA[3]。它包括两部分,一部分使用名为VQA real的自然图像,另一部分使用名为VQA abstract的卡通图像,我们将在第3.2节中讨论。VQA real包含123287个训练样本和81434个测试图像,分别来自COCO[45]。鼓励人类注释者提出有趣和多样的问题。与上述数据集相比,还允许使用二进制(即是/否)问题。数据集还允许在多项选择设置中进行评估,为每个问题提供17个额外(不正确)的候选答案。总的来说,它包含614163个问题,每个问题都有10个不同注释者的10个答案。作者从问题类型、问题/答案长度等方面对数据集[3]进行了非常详细的分析。他们还进行了一项研究,以调查问题是否需要事先的非视觉知识,通过对人类的民意调查来判断。大多数受试者(至少6/10)估计18%的问题需要常识。估计只有5.5%的问题需要成人水平的知识。这些适度的数字表明,回答大多数问题只需要简单的视觉信息。
Visual Genome and Visual7W:在撰写本文时,Visual Genome QA数据集[41]是VQA可用的最大数据集,具有170万个问题/答案对。它是用Visual Genome项目[41]的图像构建的,该项目以场景图的形式包含了场景内容的独特结构化注释。这些场景图描述了场景的视觉元素,它们的属性以及它们之间的关系。人类受试者提出的问题必须以“七个世界”之一开始,即谁,什么,什么地方,何时,为什么,如何以及哪个(在撰写本文时尚未发布“哪个”问题)。问题也必须与图像有关,以便仅在显示图像时才能清楚回答。考虑两种类型的问题:自由形式和基于区域的问题。在自由格式设置中,为注释者显示图像,并要求其提供8个问题/答案对。为了鼓励多样性,注释者被迫使用上述7个中的3个“ W”。在基于区域的设置中,注释者必须提供与特定的给定图像区域有关的问题/答案。视觉基因组中答案的多样性要大于VQA-real中的答案[3],前1000个最常见的答案仅覆盖了正确答案的64%。在VQA-real中,相应的前1000个答案覆盖了测试集答案的80%。 VQA的Visual Genome数据集的一个主要优点是可以使用结构化场景注释,我们将在第4节中进行进一步研究。但是,使用此信息来帮助设计和训练VQA系统仍然是一个尚待研究的问题。
Visual7w [100]数据集是Visual Genome的子集,其中包含其他注释。 在多选设置中评估问题,每个问题提供4个候选答案,其中只有一个是正确的。 另外,问题中提到的所有对象都是可视化的,即与它们在图像中的描绘的边界框相关联。
Visual Madlibs:视觉MADLIB数据集(95)被设计为评估系统上的“填补空白”任务。其目的是确定单词来完成描述给定图像的确认。例如,描述“两个在公园里玩”,提供了相应的图像,可能必须填写“男人”和“飞盘”。这些句子实质上相当于以陈述式形式表达的问题,大多数VQA系统可以很容易地适应这种设置。该数据集包括来自COCO[45]的10738幅图像和360001幅聚焦自然语言描述的图像。使用模板从这些描述自动生成不完整的句子。开放式和多项选择评估都是可能的。
Evaluation Measures:计算机生成的自然语言句子的评价是一项内在的复杂任务。句法(语法)和语义的正确性都应该考虑在内。用基本真句生成的对比类似于释义的评价,这在自然语言处理领域仍然是一个开放性的研究课题。VQA的大多数数据集允许绕过这个问题,将答案限制为单个单词或短语,通常是1到3个单词。这允许自动评估,并限制注释过程中的模糊性,因为它迫使问题和答案更加具体。
马林诺夫斯基等人的开创性论文。[51]提出了VQA的两个评价指标。第一种方法是使用字符串匹配来简单地测量相对于地面真实度的精度。只有完全匹配才被认为是正确的。第二种方法使用WUPS(WUPS)[88]来评估它们在分类树中的公共子序列之间的相似性。当两个词之间的相似度超过阈值时,候选答案被认为是正确的。在[51]中,度量是根据两个阈值0.9和0.0来计算的。在[22]中,Gao等人。使用人工判断进行实际的视觉图灵测试。受试者可以看到来自VQA系统或其他人的图像、问题和候选答案。然后,他或她需要根据答案来确定它是由人类(即通过测试)还是机器(即未通过测试)生成的。他们也给每个候选人的答案打分。
VQA真实数据集[3]识别模糊问题,并为每个问题收集10个不同主题的10个基本真实答案。对该数据集的评估必须将生成的答案与以下10个人工生成的答案进行比较:

换句话说,如果至少有3个注释者提供了准确的答案,则认为答案是100%准确的。



像[41,100]这样的其他数据集只是通过预测和答案之间的精确匹配比率来测量准确性,这在答案很短的时候是合理的,因此大多数情况下是明确的。在多项选择设置中(例如[95])的计算是直接的。它通过将输出空间限制在几个离散点上,使得VQA的任务更加容易,并且它消除了评估中可能由所选度量产生的任何伪影。
现有方法的结果大多数现代VQA方法已经在VQA real[3]、DAQUAR[51]和COCO-QA[63]数据集上进行了评估。我们在表6、7、8和9中总结了这三个主要数据集的结果。
3.2 Datasets of clipart images
本节讨论从剪贴画插图手动创建的合成图像的数据集。 它们通常被称为“抽象场景” [3],尽管这种命名方式令人困惑,因为它们虽然以简约的表示形式被认为描绘了现实情况。 这样的“卡通”图像允许通过关注高级语义而不是视觉识别来研究视觉与语言之间的联系。 这种类型的图像以前曾用于捕获常识[20、46、75],学习人与人之间的互动模型[4],从自然语言描述生成场景[103]以及学习视觉特征的语义相关性 [102,104]。
VQA abstract scenes
VQA基准测试(第3.1节)包含带有问题/答案对的剪贴画场景,它们是对真实图像的独立补充集。目的是使研究专注于高级推理,而无需解析真实图像。这样,除了实际图像之外,还以结构化(XML)描述的形式提供了场景。场景是手动创建的。指示注释者通过拖放界面表示现实情况。室内和室外都有两种场景,每种场景都允许使用不同的元素集,包括动物,物体和可调整姿势的人。总共生成了50,000个场景,并以与VQA数据集的真实图像相似的方式收集了每个场景3个问题(即总共150,000个问题)(第3.1节)。每个问题均由10位受试者回答,他们也提供了置信度得分。问题标有答案类型:“是/否”,“数字”和“其他”。有趣的是,问题长度和问题类型的分布(基于问题的前四个词)类似于真实图像。但是,唯一的单字答案的数量要少得多(3,770对23,234个),这反映了场景中较小的变化和有限的对象集。在抽象场景中,地面真相答案中的歧义也较低,这表现为更好的人际协议(87.5%对83.3%)。到目前为止,这些抽象场景的结果仅在[3]和[98]中有所报道。
Balanced dataset
上述数据集的另一个版本见[98]。大多数VQA数据集都有很强的偏见,以至于一个只使用语言的“盲”模型(即不使用视觉输入)常常能猜出正确的答案。这严重阻碍了VQA作为一个代理来评估深度图像理解的最初目标。合成场景允许更好地控制数据集中的分布。[98]中的作者将现有的抽象二进制VQA数据集(如上所述)与附加的互补场景进行了平衡,使得对于两个非常相似的场景,每个问题都有“是”和“否”的答案。
上面讨论的数据集的另一个版本在[98]中提出。 大多数VQA数据集存在强烈的偏见,因此仅使用语言的“盲”模型(即不使用视觉输入)通常可以猜出正确答案。 这严重阻碍了VQA充当评估深度图像理解的代理的原始目标。 合成场景可以更好地控制数据集中的分布。 [98]中的作者将现有的抽象二进制VQA数据集(如上所述)与其他互补场景进行了平衡,因此对于两个非常相似的场景,每个问题都具有“是”和“否”的答案。
正如VQA数据集[3]中关于强烈偏见的例子一样,任何以“什么是运动”开头的问题在41%的时间里都可以用“网球”来正确回答。同样,“什么颜色的”在23%的时间里正确回答为“白色”[98]。总的来说,一半的问题可以通过一个盲神经网络得到正确的答案,即单独使用问题。对于二元问题,这一比例上升到78%以上。
最终的平衡数据集包含分别用于训练和测试集的10,295对和5,328对互补场景。评估应使用VQA评估指标[3]。通过平衡和非平衡训练与测试集的组合来报告结果[98],其中我们总结了有趣的观察结果。首先,在测试不平衡数据(即先前工作的设置)时,最好对类似的不平衡数据进行训练,以便学习和利用数据集偏差(例如,答案的69%是“是”)。其次,对新的平衡数据进行测试,现在最好对相似的平衡数据进行训练。它迫使模型使用视觉信息,而无法利用训练集中的语言偏见。在这种情况下,盲人模型的表现接近预期。评估的特定模型是一种依赖于语言解析和许多手工设计规则的视觉验证方法。作者还以更加困难的形式提供了结果,只有在模型可以正确回答场景的两个版本(是和否)时,预测才被认为是正确的。在这种情况下,仅语言的模型的性能为零,可以说是构成最严格的度量标准之一以量化实际对深度场景的理解。
一种批评是,在一个被认为描绘了真实场景的数据集中,强迫消除偏见的做法是,它人为地将分布从现实世界中转移出去。数据集中出现的统计偏差反映了世界固有的统计偏差,这些偏差应该在多大程度上进入通用VQA系统的学习过程中是有争议的。
3.3 Knowledge base-enhanced datasets
上面讨论的数据集包含各种比例的纯视觉问题和需要外部知识的问题。例如,DAQUAR[51]中的大多数问题在本质上都是纯粹的视觉问题,涉及对象的颜色、数字和物理位置。在COCO-QA数据集[63]中,问题由描述图像主要视觉元素的图像标题自动生成。在VQA数据集[3]中,5.5%的问题需要“成人级常识”,但没有一个需要“知识库级”知识[78]。我们在第2.4节讨论了使用外部知识库的VQA方法。这两种方法的作者[78,79]提出了两个数据集,可以突出显示这种特殊的功能。这些数据集的范围不同于上面讨论的通用VQA数据集,而且它们的规模也较小。
KB-VQA 构建KB-VQA数据集[78]以评估Ahab VQA系统的性能[78]。它包含需要DBpedia中特定主题知识的问题。从COCO图像数据集[45]中选择700幅图像,每幅图像收集3到5个问答对,共2402个问题。每个问题都遵循23个预定义模板中的一个。这些问题需要不同层次的知识,从常识到百科全书知识。
FVQA :FVQA数据集[79]仅包含涉及外部(非可视)信息的问题。它旨在包括其他注释,以简化使用知识库的方法的有监督的训练。与大多数仅提供问题/答案对的VQA数据集[3、22、63、100]相比,FVQA在每个问题/答案中都包含一个支持的事实。这些事实表示为三元组(arg1,rel,arg2)。例如,考虑问题/答案“为什么这些人穿黄色外套?为了安全”。这将包括佐证事实(穿着鲜艳的衣服,艾滋病,安全)。为了收集该数据集,从知识库数据库DBpedia [5],ConceptNet [47]和Webchild [73,72]中提取了大量与视觉概念有关的事实(三元组)。注释者选择了图像和图像的视觉元素,然后不得不选择与视觉概念相关的那些预先提取的支持事实之一。他们最后不得不提出一个具体涉及所选支持事实的问题/答案。数据集包含与580个视觉概念(234个对象,205个场景和141个属性)有关的193,005个候选支持事实,总共有4,608个问题。
3.4 Other datasets
Diagrams Kembhavi等人[37]提出了一个图上VQA的数据集,称为AI2图(AI2D)。它包含5000多个图表,代表了小学的科学主题,如水循环和消化系统。每个图表都用分段和图形元素之间的关系进行注释。数据集包括15000多个选择题和答案。在同一篇论文中,作者提出了一种特别设计的方法来推断这个数据集上的正确答案。该方法构建结构化表示,命名为图解析图(DPG),使用专门针对图的技术,例如,使用OCR识别箭头或文本。然后使用dpg推断正确答案。与自然图像上的VQA相比,图的可视化解析仍然具有挑战性,而且问题往往需要高水平的推理,这使得任务的总体难度非常大。
Shapes Andreas等人[2] 提出一个合成图像的数据集。它是对自然图像数据集的补充,因为它提供了不同的挑战,通过强调理解多个对象之间的空间和逻辑关系。数据集由关于彩色形状排列的复杂问题组成。这些问题是围绕概念和关系的组合而构建的,例如,圆圈上方是否有一个红色的形状?还是红色的蓝色?。这使得作者能够强调神经模块网络的能力(见第2.3.1节)。问题包含两到四个属性、对象类型或关系。总共有244个问题和15616张图片,所有问题都有是与否的答案(以及相应的支持图片)。这消除了学习偏差的风险,如第3.2节所述。作者提供了他们自己的方法和联合植入基线重新实施的结果[63]。到目前为止还没有其他结果的报道。注意,这个数据集在精神上类似于文本QA中使用的合成“bAbI”数据集[82]。
4. Structured scene annotations for VQA
视觉基因组[41]是目前可用于VQA的最大数据集。它以场景图的形式为每个图像提供了人工生成的结构化注释的独特优势。总而言之,场景图是由表示场景的视觉元素的节点组成的,这些元素可以是对象、属性、动作等。节点与表示它们之间关系的有向边相链接(示例见图3)。详细描述见[41]。
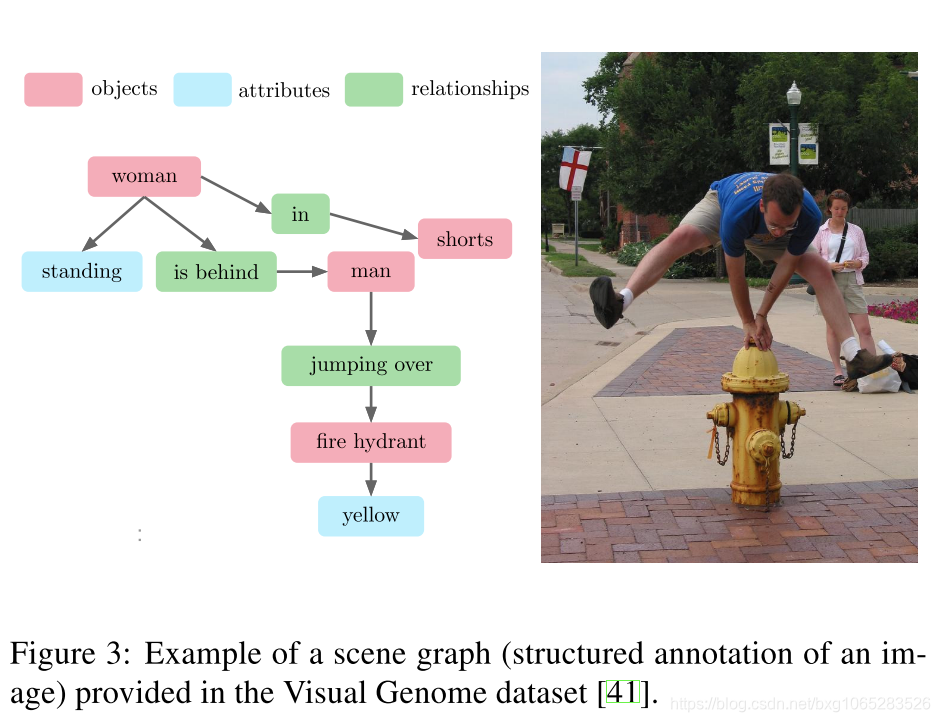
与更典型的对象级和图像级注释相比,将场景图(scene graph)与图像包含在一起是朝着丰富和更全面的注释方向迈出的重要一步。在这一部分中,我们将研究场景图是否可以用于直接回答相关的视觉问题。换言之,如果我们假设一个完美的视觉系统能够恢复输入图像与被人类注释的图像相同的场景图,那么答案是否可以从中简单地得到?我们检查这样一个假设的先决条件,即答案是否真的以图形元素的形式出现。实际上,我们首先根据每个图像对应的场景图为其建立词汇表。词汇表中的单词是由图形的所有节点构成的。然后,对于每一个问题,我们检查它的答案是可以与单词匹配,还是可以与它的图像词汇表中的单词组合匹配(图4)。
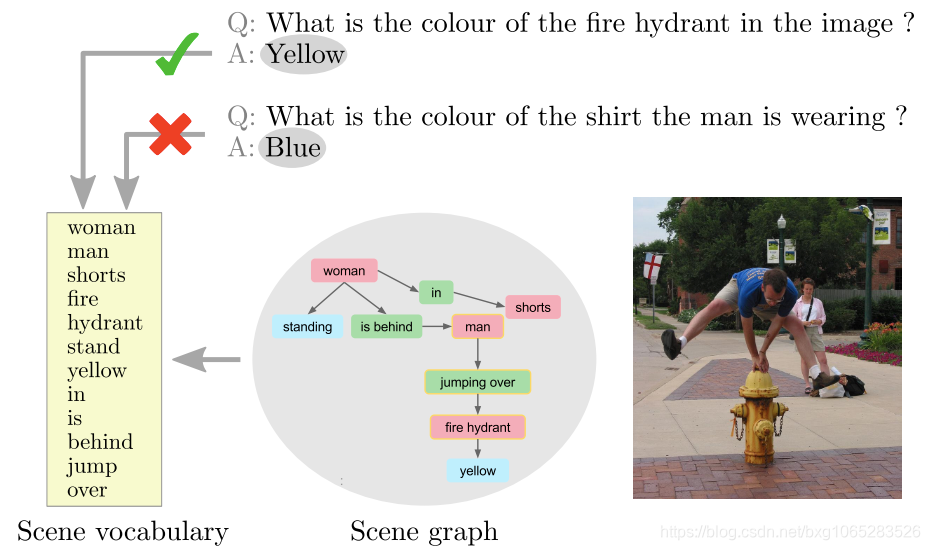
我们将上述程序应用于视觉基因组数据集的所有图像和问题。我们发现只有40.02%的答案可以直接在场景图中找到,也就是说,只有40.02%的问题可以直接用场景图表示。另外7%的答案是数字(即计数问题),我们选择将其从我们的其他答案中剔除分析。那里仍有53%的问题无法从场景图中直接回答。考虑到作为场景图提供的描述的明显详细程度,这个比率出奇地高。
为了描述剩下的53%的问题,我们使用问题的前几个单词来检查问题类型(图5)。以“什么”开头的大量问题属于场景图无法直接回答的问题。注意,问题类型在整个数据集上的总体分布(包括那些可以直接从场景图中回答的问题)有很大的不同(图6)。我们在图7中报告了场景图中无法回答的问题数量,作为每种类型的所有问题的一部分。我们发现大部分以“何时”、“为什么”和“如何”开头的问题在场景图中找不到答案。事实上,回答这些问题通常涉及与特定视觉实体不对应的信息,因此不由场景图中的节点表示。但是,可以使用常识或特定对象的知识来恢复这些答案。
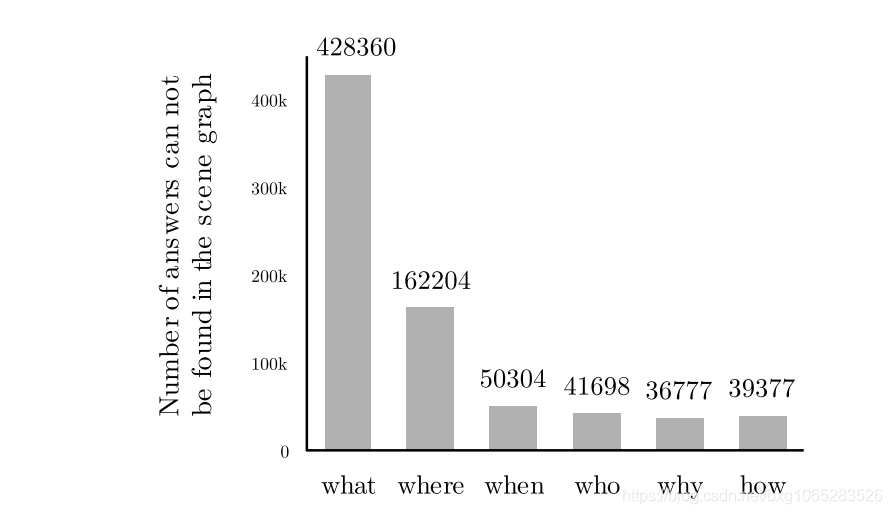

我们记录了在场景图中找不到的答案,并按出现频率排列(表4)。无法在场景图中找到的“what”问题的答案主要是颜色和材质等属性,注释者可能认为这些属性太细,无法包含在场景图中。“where”问题缺少的答案大多是全局场景标签,如卧室、街道、动物园等。“when”问题缺少的答案90%是白天、晚上及其变体。这些标签很少在场景图中表示,大量的同义词可以表示相似的语义概念。最后,“为什么”和“如何”问题引出更高层次的概念,如行动、原因、天气类型等。
以上分析得出结论:目前的场景图是对场景的丰富的中间抽象,但它们不够全面,无法捕获VQA所需的所有元素。例如,在这种表示中,诸如颜色和材质之类的低级视觉属性丢失,因此需要访问图像来回答涉及它们的问题。全局场景属性(如位置、天气或一天中的时间)很少被标记,但它们通常涉及“在何处”和“何时”问题。是否应该投入更多的人力来获得全面的注释,仍有争议。另一种解决方案是将可视化数据集与提供可视化和非可视化概念常识信息的大规模知识库(KBs)结合起来。这些知识库中的信息类型是对视觉注释(如场景图)的补充。例如,虽然“白天”可能不会被注释为特定场景,“晴朗的蓝天”的注释可能会导致一些常识知识关于白天的原因。类似的推理可以将“烤箱”与“厨房”联系起来,“食物”与“吃”联系起来,“雪”与“冷”联系起来。
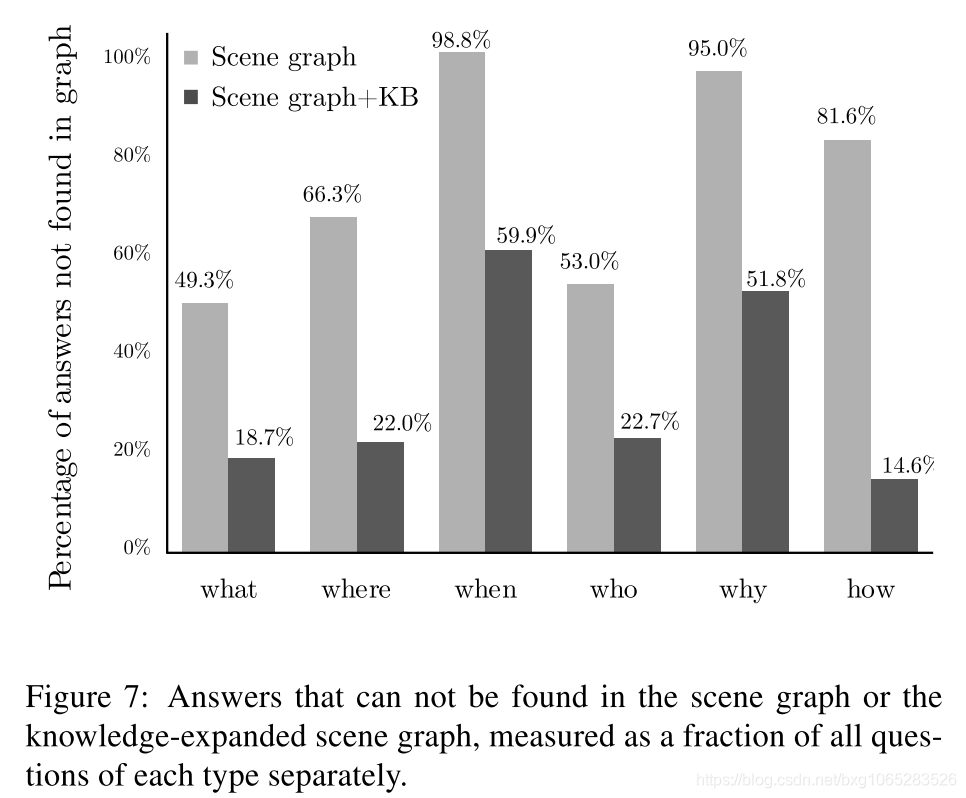
我们进行了另外一个实验来估计场景图与通用知识库连接的可能性。对于每个问题,我们使用知识库中的关系来检查是否可以在场景图的一阶扩展中找到正确的答案。
更具体地说,我们使用场景图所有节点的标签来查询3个大KB(DBpedia [5],WebChild [73、72]和ConceptNet [47])。 查询产生的三元组用于扩展场景图及其词汇。 例如,标记为“猫”的场景图节点可能会返回事实<cat,isa,mammal>,该事实将附加到场景图的“猫”节点上。 这个简单的过程可以有效地完成具有特定领域知识的图形。 与上述类似,然后我们检查是否可以仅从该表示形式中潜在地回答问题,检查正确答案和单词之间的匹配项或扩展词汇表中单词的组合。 我们发现,有79.58%的问题属于这种情况,几乎是同一实验的两倍,没有KB扩展(40.02%)。 这清楚地显示了用通用知识库中的信息补充视觉内容解释的潜力。

5. Discussion and future directions
VQA的任务是最近才引入的,它在短短几年内引起了极大的兴趣并加速了发展。VQA是一项复杂的任务,它最初受到计算机视觉基本任务(如图像识别)达到一定成熟度的鼓励。VQA之所以特别吸引人,是因为它构成了一个最终形式的人工智能完整任务,即考虑开放世界的自由形式问题和答案。最近的结果,虽然令人鼓舞,但不应愚弄我们,因为这一最终目标无疑离任何当前的技术都有很长的路要走。减少和限制形式的VQA,例如多项选择格式、简短的回答长度、有限类型的问题等,是合理的中间目标,似乎是可以实现的。他们的评估实际上更容易,可能更能代表我们的实际进展。
我们对数据集的回顾(第3节)显示了用于收集数据(从人类注释器或半自动从图像标题)和施加某些约束(例如聚焦于某些图像区域、对象或问题类型)的协议的多样性。这些选择会在很多方面影响收集到的问题和答案。首先,它们影响到复杂程度和所涉及的事实数量,即在识别单个项目/关系/属性后是否能够推断出正确答案,或者是否需要对场景的多个元素和特征进行推理。第二,它们影响了视觉与文本之间的比例。一个极端的例子是合成的“形状”数据集(第3.4节),它只需要通过名称识别少量的形状和颜色,而是强调对这些元素之间关系的推理。第三,它们影响所需的先验外部知识的数量。外部是指不能从给定的视觉和文本输入中推断出的意义。然而,这些信息在自然界中可能是可视的,例如,白天会出现明亮的蓝天,或者为了安全起见通常会穿黄色夹克。
External knowledge
如上所述,VQA构成了一个人工智能的完全挑战,因为人工智能中的大多数任务都可以表述为图像问题。但请注意,这些问题往往需要外部知识才能得到回答。这是最近人们对将VQA与结构化知识库连接起来的方法以及需要这种机制的问题的特定数据集感兴趣的原因。有人可能会说,这样复杂的问题会分散人们对应该首先解决的纯视觉问题的注意力。我们相信这两条道路可以并行探索。不幸的是,目前使用知识库进行VQA的方法存在严重的局限性。[78,79]只能处理由手工编码模板预定义的有限数量的问题类型。[87]使用Doc2Vec对检索到的信息进行编码,但是编码过程与问题无关,并且可能包括与问题无关的信息。记忆增强神经网络的概念可以为VQA提供一个合适的、可扩展的框架,用于融合和自适应地选择相关的外部知识。据我们所知,这条路还没有探索过。在数据集方面,涉及重要外部知识的问题表现得不均衡。有人提出了具体的数据集,提出了这些问题,并对支持事实作了补充说明,但这些数据集的规模有限。对数据集的努力可能会刺激这方面的研究,并有助于培训合适的模型。请注意,这些工作可能只是涉及对现有数据集的附加注释。
Textual question answering
文本问答的任务比视觉问答早了几十年,产生了大量的工作。传统上提出了两种截然不同的方法:信息检索和语义分析与知识库相结合。一方面,信息检索方法使用非结构化的文档集合,在这些文档集合中寻找问题的关键词以识别相关段落和句子[33,40]。然后,排名函数对这些候选项进行排序,然后从一个或多个顶级匹配项中提取答案。该方法可以与VQA的基本“注意联合嵌入”方法进行比较,该方法将描述每个图像区域的特征与问题的表示进行比较,确定要关注的区域,然后提取答案。一个关键的概念是从问题中预测答案类型(例如颜色、日期、答案等),以便于从候选段落中最终提取答案。Kafle和Kanan最近将这种答案类型预测的概念带回了VQA[34]。另一方面,语义分析方法侧重于更好地理解问题,使用更复杂的语言模型和解析器将问题转换为结构化查询[16、30、69、81]。然后,可以在特定于域的数据库或通用结构化知识库上执行这些查询。在wang等人的VQA方法中使用了类似的过程。用于查询外部知识库[78,79]。
如前所述,对VQA的兴趣来自于对图像识别任务(对象、活动、场景等)的深入学习。因此,目前关于VQA的大部分工作都是用计算机视觉社区的工具和方法构建的。文本问答一直是自然语言处理领域的研究热点,其方法和算法各不相同。从NLP到最近的VQA研究,已经渗透了许多概念,例如单词嵌入、句子表示、递归神经网络处理等,一些显著的成功归功于这两个领域的共同努力(如[189])。我们相信,仍然存在更好地利用NLP的概念来解决VQA中的挑战的潜力。语言模型可以在大量最小标记文本上进行训练,独立于可视化数据。然后可以在VQA系统的输出阶段使用它们来生成自然语言的长答案。类似地,语法分析器可以单独在文本上进行预训练,并且可以被重用,以便更为原则性地处理输入问题。对这个问题的理解不必像目前大多数VQA系统那样进行端到端的培训。在NLP中,文本查询的逻辑表示的解释已经有了自己的研究(如[97,60,16])。
6. Conclusion
本文综述了视觉问答的研究现状。我们回顾了最流行的方法,将问题和图像映射到公共特征空间中的矢量表示。我们描述了在此概念基础上的其他改进,即注意机制、模块化和内存增强架构。我们重新审视了可用于培训和评估VQA方法的越来越多的数据集,强调了它们所包含的问题类型和难度的差异。除了一个描述性的回顾,我们指出了未来研究的一些有希望的方向。特别是,我们建议扩大从结构化知识库中包含额外外部知识的规模,并继续探索自然语言处理工具的潜力。我们相信,目前和未来在这些特定点上的工作将有利于VQA的具体任务以及视觉场景理解的总体目标。
来源:oschina
链接:https://my.oschina.net/u/4364157/blog/4288011