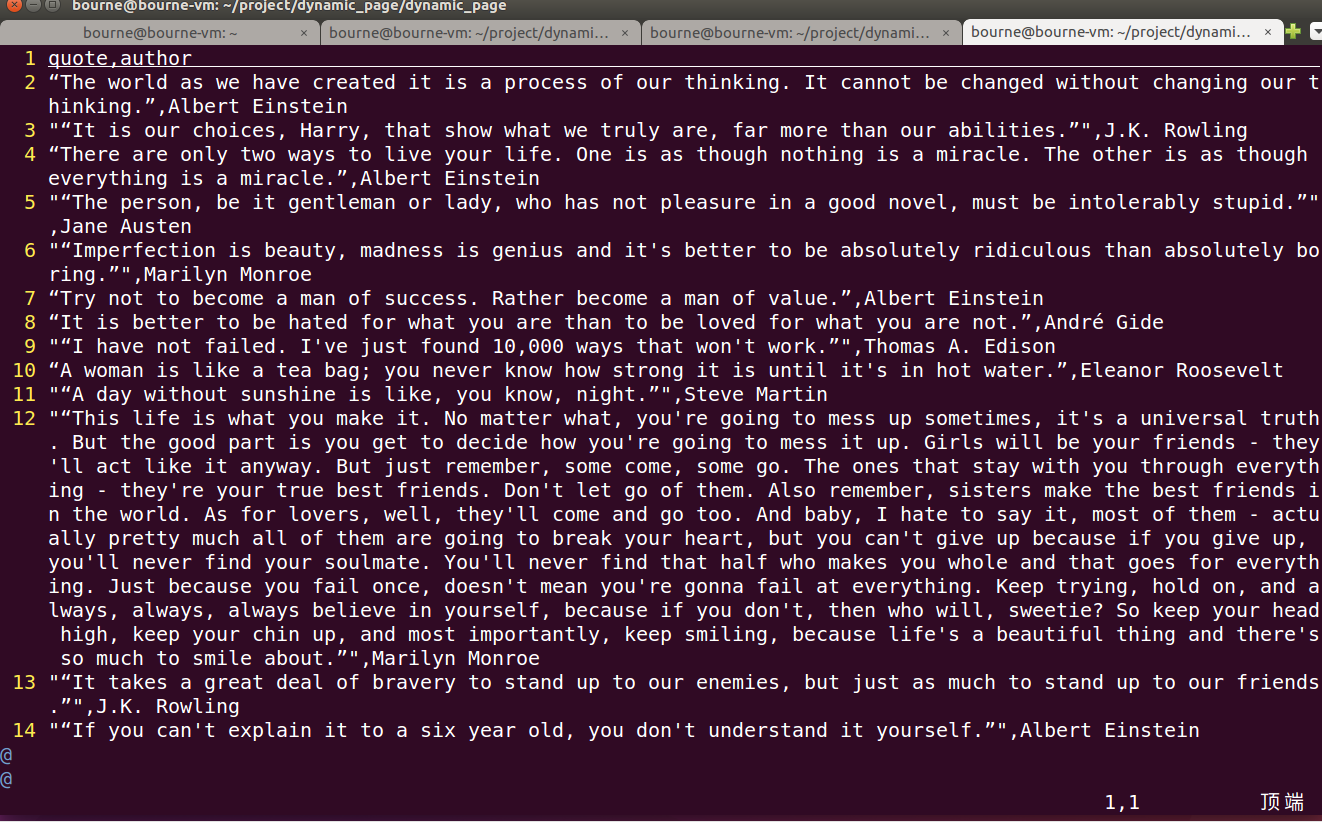
(1)、前言
动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成
静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送给我们客户端
这里我们可以观察一个典型的供我们练习爬虫技术的网站:quotes.toscrape.com/js/
我们通过实验来进一步体验下:(这里我使用ubuntu16.0系统)
1、启动终端并激活虚拟环境:source course-python3.5-env/bin/activate
2、爬取页面并分析
1 (course-python3.5-env) bourne@bourne-vm:~$ scrapy shell http://quotes.toscrape.com/js/
2 2018-05-21 22:50:18 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: scrapybot)
3 2018-05-21 22:50:18 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.5.2 (default, Nov 23 2017, 16:37:01) - [GCC 5.4.0 20160609], pyOpenSSL 17.5.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Linux-4.13.0-41-generic-x86_64-with-Ubuntu-16.04-xenial
4 2018-05-21 22:50:18 [scrapy.crawler] INFO: Overridden settings: {'LOGSTATS_INTERVAL': 0, 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter'}
5 2018-05-21 22:50:18 [scrapy.middleware] INFO: Enabled extensions:
6 ['scrapy.extensions.memusage.MemoryUsage',
7 'scrapy.extensions.telnet.TelnetConsole',
8 'scrapy.extensions.corestats.CoreStats']
9 2018-05-21 22:50:18 [scrapy.middleware] INFO: Enabled downloader middlewares:
10 ['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
11 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
12 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
13 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
14 'scrapy.downloadermiddlewares.retry.RetryMiddleware',
15 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
16 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
17 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
18 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
19 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
20 'scrapy.downloadermiddlewares.stats.DownloaderStats']
21 2018-05-21 22:50:18 [scrapy.middleware] INFO: Enabled spider middlewares:
22 ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
23 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
24 'scrapy.spidermiddlewares.referer.RefererMiddleware',
25 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
26 'scrapy.spidermiddlewares.depth.DepthMiddleware']
27 2018-05-21 22:50:18 [scrapy.middleware] INFO: Enabled item pipelines:
28 []
29 2018-05-21 22:50:18 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
30 2018-05-21 22:50:18 [scrapy.core.engine] INFO: Spider opened
31 2018-05-21 22:50:19 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/js/> (referer: None)
32 [s] Available Scrapy objects:
33 [s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
34 [s] crawler <scrapy.crawler.Crawler object at 0x7f72fee54c18>
35 [s] item {}
36 [s] request <GET http://quotes.toscrape.com/js/>
37 [s] response <200 http://quotes.toscrape.com/js/>
38 [s] settings <scrapy.settings.Settings object at 0x7f72fee54ac8>
39 [s] spider <DefaultSpider 'default' at 0x7f72fe9daf60>
40 [s] Useful shortcuts:
41 [s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
42 [s] fetch(req) Fetch a scrapy.Request and update local objects
43 [s] shelp() Shell help (print this help)
44 [s] view(response) View response in a browser
45 In [1]: response.css('div.quote')
46 Out[1]: []代码分析:这里我们爬取了该网页,但我们通过css选择器爬取页面每一条名人名言具体内容时发现没有返回值
我们来看看页面:这是由于每一条名人名言是通过客户端运行一个Js脚本动态生成的
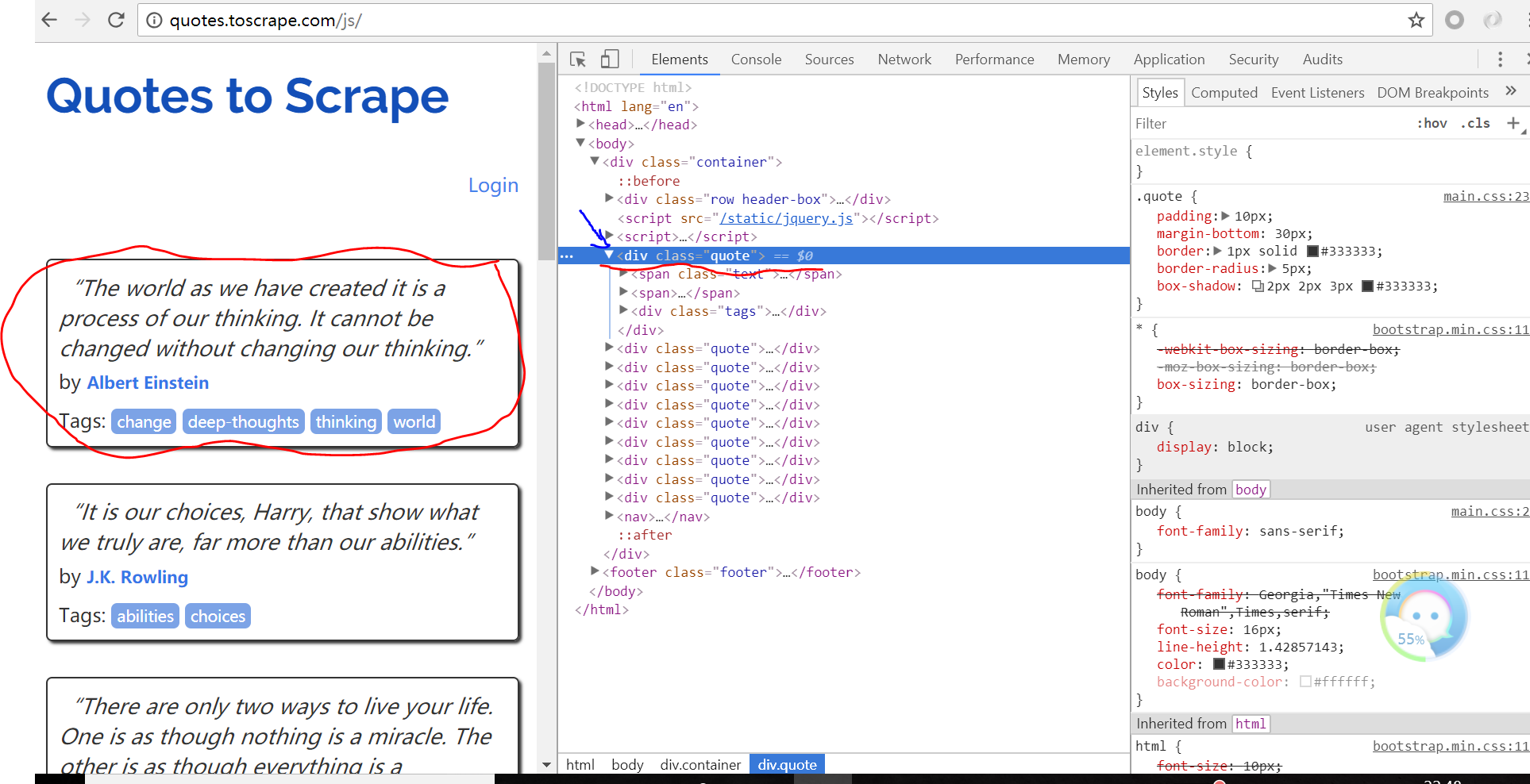
我们将script脚本打开看看发现这里包含了每一条名人名言的具体信息

(2)、问题分析
scrapy爬虫框架没有提供页面js渲染服务,所以我们获取不到信息,所以我们需要一个渲染引擎来为我们提供渲染服务---这就是Splash渲染引擎(大侠出场了)
1、Splash渲染引擎简介:
Splash是为Scrapy爬虫框架提供渲染javascript代码的引擎,它有如下功能:(摘自维基百科)
(1)为用户返回渲染好的html页面
(2)并发渲染多个页面
(3)关闭图片加载,加速渲染
(4)执行用户自定义的js代码
(5)执行用户自定义的lua脚步,类似于无界面浏览器phantomjs
2、Splash渲染引擎工作原理:(我们来类比就一清二楚了)
这里我们假定三个小伙伴:(1--懒惰的我 , 2 --提供外卖服务的小哥,3---本人喜欢吃的家味道餐饮点)
今天正好天气不好,1呆在宿舍睡了一早上起来,发现肚子饿了,它就想去自己爱吃的家味道餐饮点餐,他在床上大喊一声我要吃大鸡腿,但3并没有返回东西给他,这是后怎么办呢,2出场了,1打来自己了饿了吗APP点了一份荷叶饭,这是外卖小哥收到订单,就为他去3那,拿了他爱吃的荷叶饭给了1,1顿时兴高采烈!

Client----相当于1 /Splash---相当于2 /Web server---相当于3
即:我们将下载请求告诉Splash ,然后Splash帮我们去下载并渲染页面,最后将渲染好的页面返回给我们
(3)、安装Splash
启动终端:
sudo apt-get install docker docker.io(安装docker镜像)
sudo docker pull scrapyhub/splash(用docker安装Splash)
安装过程比较缓慢,小伙伴们安心等待即可
启动Splash:
sudo docker run -p 8050:8050 scrapinghub/splash(这里我们在本机8050端口开启了Splash服务)
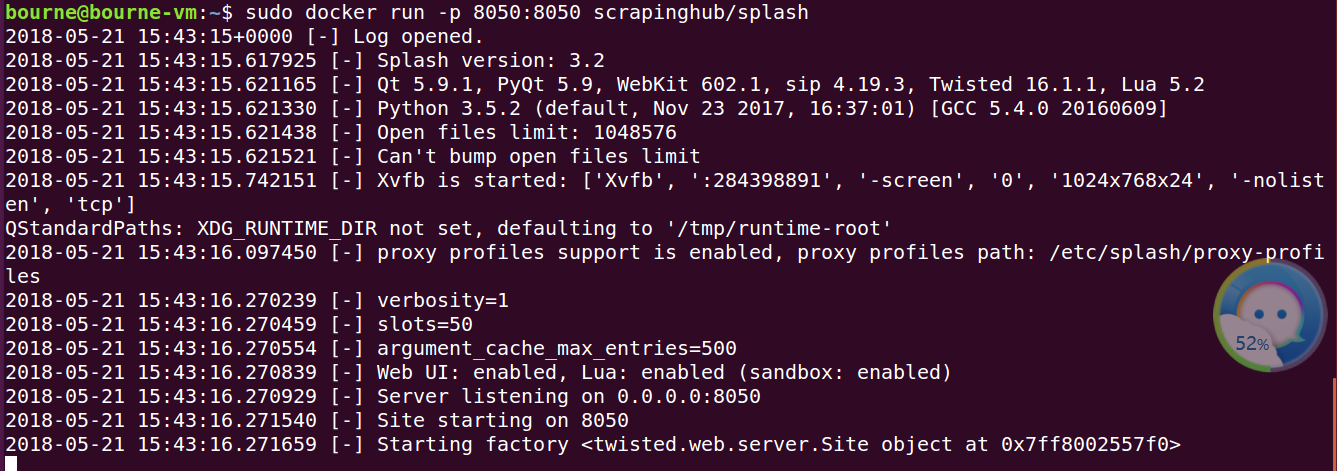
得到上面输出,表明该引擎已启动
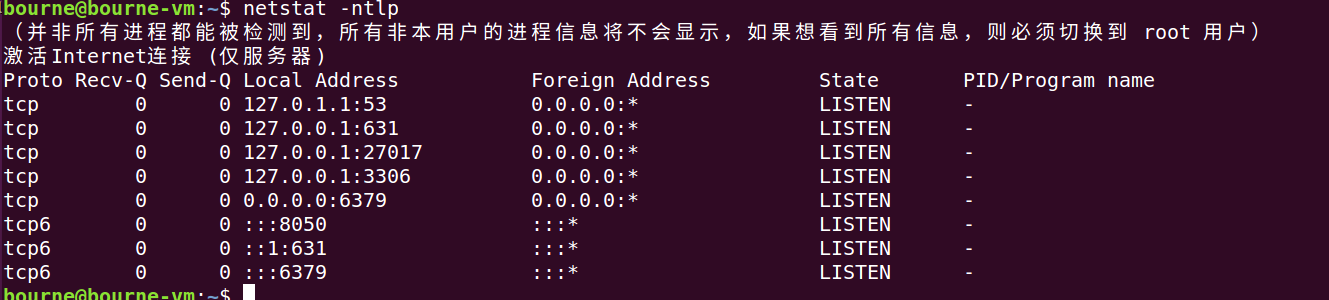
我们使用命令查看,可以看见8050端口已经开启服务了
(4)、Splash简要使用说明
Splash为我们提供了多种端点的服务,具体参见http://splash.readthedocs.io/en/stable/api.html#render-html
1、下面我们以render.html端点来体验下:(这里我们使用requests库)
实验:
首先:我们在本机8050端口开启splash 服务:sudo docker run -p 8050:8050 scrapinghub/splash
接着:激活虚拟环境source course-python3.5-env/bin/activate----启动ipython:
import requests
from scrapy.selector import Selector
splash_url = 'http://localhost:8050/render.html'
args = {'url':'http://quotes.toscrape.com/js','timeout':10,'image':0}
response = requests.get(splash_url,params = args)
sel = Selector(response)
sel.css('div.quote span.text::text').extract()得到如下输出:
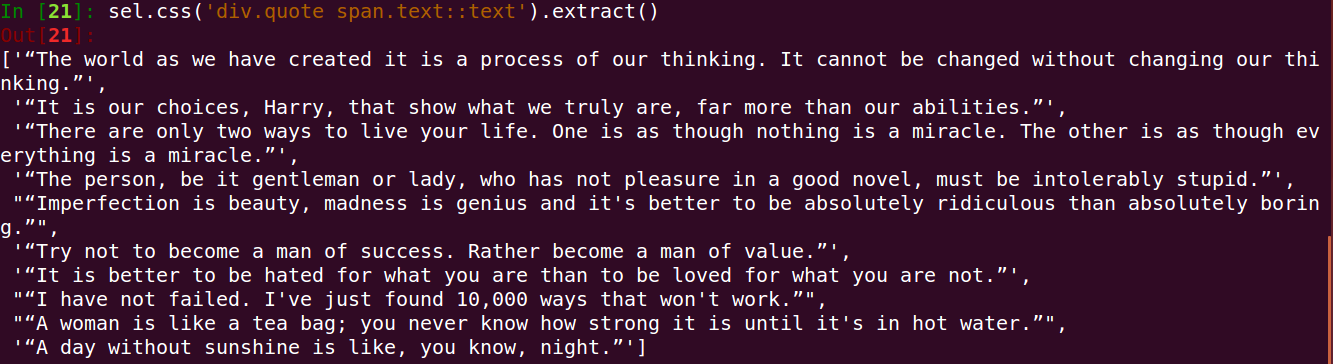
2、下面我们来介绍另一个重要的端点:execute端点
execute端点简介:它被用来提供如下服务:当用户想在页面中执行自己定义的Js代码,如:用js代码模拟浏览器进行页面操作(滑动滚动条啊,点击啊等等)
这里:我们将execute看成是一个可以模拟用户行为的浏览器,而用户的行为我们通过lua脚本进行定义:
比如:
打开url页面
等待加载和渲染
执行js代码
获取http响应头部
获取cookies
实验:
ln [1]: import requests
In [2]: import json
#编写lua脚本,:访问属性
In [3]: lua = '''
...: function main(splash)
...: splash:go('http:example.com') #打开页面
...: splash:wait(0.5) #等待加载
...: local title = splash:evaljs('document.title') #执行js代码
...: return {title = title} #{中的内容类型python中的键值对}
...: end
...: '''
In [4]: splash_url = 'http://localhost:8050/execute' #定义端点地址
In [5]: headers = {'content-type':'application/json'}
In [6]: data = json.dumps({'lua_source':lua}) #做成json对象
In [7]: response = requests.post(splash_url,headers = headers,data=data) #使用post请求
In [8]: response.content
Out[8]: b'{"title": "Example Domain"}'
In [9]: response.json()
Out[9]: {'title': 'Example Domain'}Splash对象常用属性和方法总结:参考官网http://splash.readthedocs.io/en/stable/scripting-overview.html#和书本
splash:args属性----传入用户参数的表,通过该属性可以访问用户传入的参数,如splash.args.url、splash.args.wait
spalsh.images_enabled属性---用于开启/禁止图片加载,默认值为True
splash:go方法---请求url页面
splash:wait方法---等待渲染的秒数
splash:evaljs方法---在当前页面下,执行一段js代码,并返回最后一句表达式的值
splash:runjs方法---在当前页面下,执行一段js代码
splash:url方法---获取当前页面的url
splash:html方法---获取当前页面的HTML文档
splash:get_cookies---获取cookies信息
(5)、在Scrapy 中使用Splash
1、安装:scrapy-splash
pip install scrapy-splash
2、在scrapy_splash中定义了一个SplashRequest类,用户只需使用scrapy_splash.SplashRequst来替代scrapy.Request发送请求
该构造器常用参数如下:
url---待爬取的url地址
headers---请求头
cookies---cookies信息
args---传递给splash的参数,如wait\timeout\images\js_source等
cache_args--针对参数重复调用或数据量大大情况,让Splash缓存该参数
endpoint---Splash服务端点
splash_url---Splash服务器地址,默认为None
实验:https://github.com/scrapy-plugins/scrapy-splash(这里有很多使用例子供大家学习)
step1:新建项目和爬虫(先用终端开启splash服务:sudo docker run -p 8050:8050 scrapinghub/splash,这里我创建了一个project目录--进入目录scrapy startproject dynamic_page ---cd dynamic_page ---scrapy genspider spider quotes.toscrape.com/js/)
创建好的项目树形目录如下:
step2:改写settIngs.py文件这里小伙伴们可参考github(https://github.com/scrapy-plugins/scrapy-splash)---上面有详细的说明
在最后添加如下内容:
2 #Splash服务器地址
93 SPLASH_URL = 'http://localhost:8050'
94
95 #开启两个下载中间件,并调整HttpCompressionMiddlewares的次序
96 DOWNLOADER_MIDDLEWARES = {
97 'scrapy_splash.SplashCookiesMiddleware': 723,
98 'scrapy_splash.SplashMiddleware':725,
99 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware':810,
100 }
101
102 #设置去重过滤器
103 DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
104
105 #用来支持cache_args(可选)
106 SPIDER_MIDDLEWARES = {
107 'scrapy_splash.SplashDeduplicateArgsMiddleware':100,
108 }
109
110 DUPEFILTER_CLASS ='scrapy_splash.SplashAwareDupeFilter'
111
112 HTTPCACHE_STORAGE ='scrapy_splash.SplashAwareFSCacheStorage'
113step3:修改spider.py文件
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from scrapy_splash import SplashRequest #重新定义了请求
4
5 class SpiderSpider(scrapy.Spider):
6 name = 'spider'
7 allowed_domains = ['quotes.toscrape.com']
8 start_urls = ['http://quotes.toscrape.com/js/']
9
10 def start_requests(self): #重新定义起始爬取点
11 for url in self.start_urls:
12 yield SplashRequest(url,args = {'timeout':8,'images':0})
13
14 def parse(self, response): #页面解析函数,这里我们使用了CSS选择器
15 authors = response.css('div.quote small.author::text').extract() #选中名人并返回一个列表
16 quotes = response.css('div.quote span.text::text').extract() #选中名言并返回一个列表
17 yield from (dict(zip(['author','quote'],item)) for item in zip(authors,quotes)) #使用zip()函数--小伙伴们自行百度菜鸟教程即可
18构造了一个元祖再进行遍历,再次使用zip结合dict构造器做成了列表,由于yield ,所以我们使用生成器解析返回
19
20 next_url = response.css('ul.pager li.next a::attr(href)').extract_first()
21 if next_url:
22 complete_url = response.urljoin(next_url)#构造了翻页的绝对url地址
23 yield SplashRequest(complete_url,args = {'timeout':8,'images':0})
~step4:运行爬虫,得到如下输出(scrapy crawl spider -o result.csv)---将其写入csv文件,这里普及下小知识点:csv文件简单理解就是如excet类型的文件格式,只不过excel拿表格分割,而csv文件以逗号分割而已
(6)、项目实战(我们以爬取京东商城商品冰淇淋为例吧)
---我是个吃货,夏天快到了我们来爬京东中的冰淇淋信息吧---
第一步:分析页面
打开京东商城,输入关键字:冰淇淋,滑动滚动条,我们发现随着滚动条向下滑动,越来越多的商品信息被刷新了,这说明该页面部分是ajax加载
我们打开scrapy shell 爬取该页面,如下图:
(course-python3.5-env) bourne@bourne-vm:~/project/dynamic_page$ scrapy shell 'https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8'
2018-05-22 20:31:50 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: dynamic_page)
2018-05-22 20:31:50 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.5.2 (default, Nov 23 2017, 16:37:01) - [GCC 5.4.0 20160609], pyOpenSSL 17.5.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Linux-4.13.0-41-generic-x86_64-with-Ubuntu-16.04-xenial
2018-05-22 20:31:50 [scrapy.crawler] INFO: Overridden settings: {'NEWSPIDER_MODULE': 'dynamic_page.spiders', 'BOT_NAME': 'dynamic_page', 'DUPEFILTER_CLASS': 'scrapy_splash.SplashAwareDupeFilter', 'LOGSTATS_INTERVAL': 0, 'ROBOTSTXT_OBEY': True, 'HTTPCACHE_STORAGE': 'scrapy_splash.SplashAwareFSCacheStorage', 'SPIDER_MODULES': ['dynamic_page.spiders']}
2018-05-22 20:31:50 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage']
2018-05-22 20:31:50 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy_splash.SplashCookiesMiddleware',
'scrapy_splash.SplashMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-05-22 20:31:50 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy_splash.SplashDeduplicateArgsMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-05-22 20:31:50 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-05-22 20:31:50 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6024
2018-05-22 20:31:50 [scrapy.core.engine] INFO: Spider opened
2018-05-22 20:31:50 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.jd.com/error.aspx> from <GET https://search.jd.com/robots.txt>
2018-05-22 20:31:50 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.jd.com/error.aspx> (referer: None)
2018-05-22 20:31:51 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x7f203f840da0>
[s] item {}
[s] request <GET https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8>
[s] response <200 https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8>
[s] settings <scrapy.settings.Settings object at 0x7f203f8407b8>
[s] spider <DefaultSpider 'default' at 0x7f203f38d4e0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]: response.css('div.gl-i-wrap')
Out[1]:
[<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>]
In [2]: len(response.css('div.gl-i-wrap'))
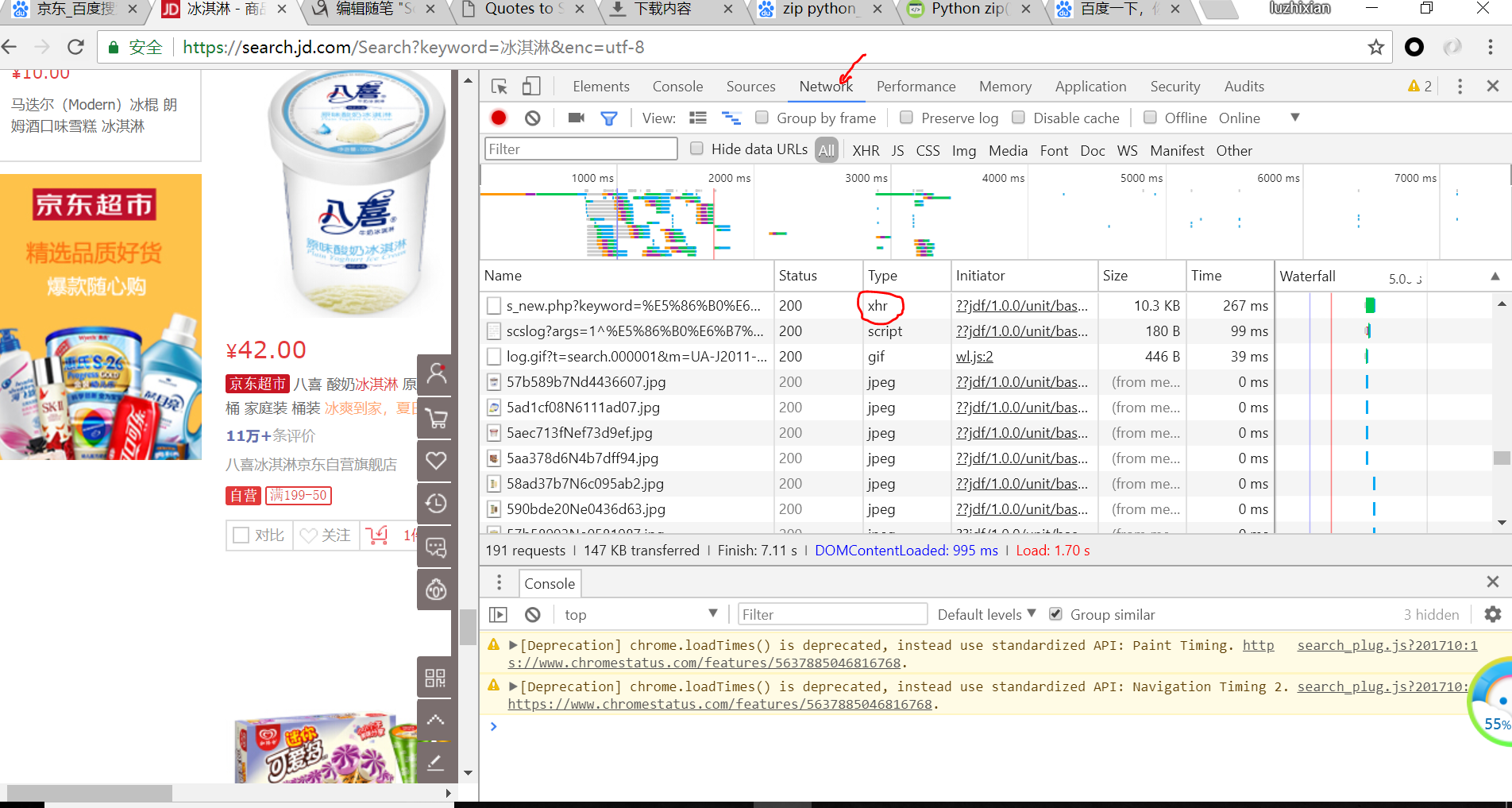
Out[2]: 30得到返回结果发现只有30个冰淇凌的信息,而我们再页面中明明看见了60个冰淇凌信息,这是为什么呢?
答:这也说明了刚开始页面只用30个冰淇淋信息,而我们滑动滑块时,执行了js代码,并向后台发送了ajax请求,浏览器拿到数据后再进一步渲染出另外了30个信息
我们可以点击network选项卡再次确认:
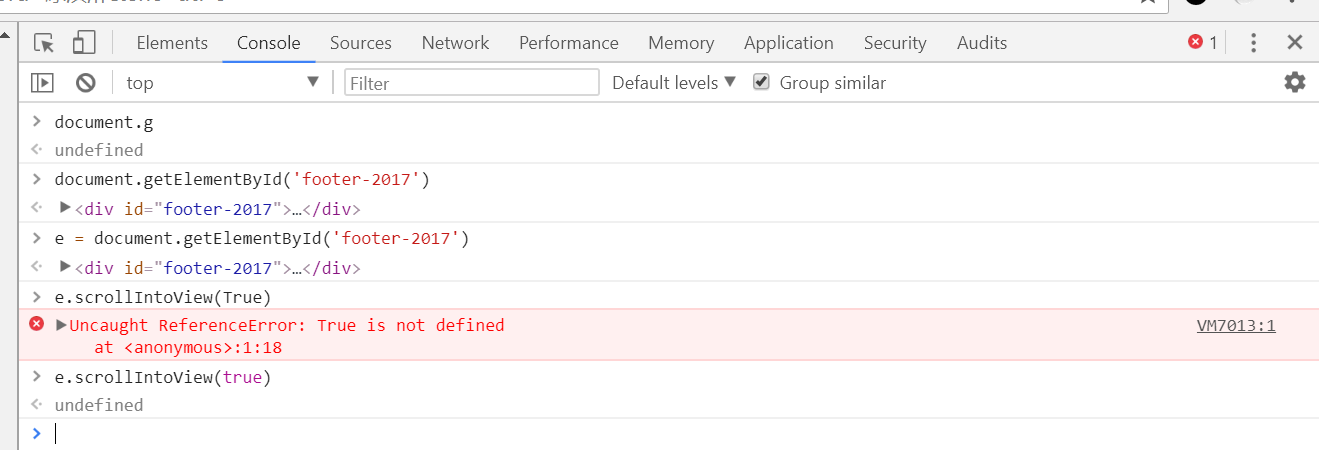
鉴于此,我们就想出了一种解决方案:即用js代码模拟用户滑动滑块到底的行为再结合execute端点提供的js代码执行服务即可(小伙伴们让我们开始实践吧)
首先:模拟用户行为:
启动终端并激活虚拟环境,我们首先使用Request发送请求观察结果
(course-python3.5-env) bourne@bourne-vm:~/project/dynamic_page$ scrapy shell 'https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8'
2018-05-23 10:04:44 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: dynamic_page)
2018-05-23 10:04:44 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.5.2 (default, Nov 23 2017, 16:37:01) - [GCC 5.4.0 20160609], pyOpenSSL 17.5.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Linux-4.13.0-41-generic-x86_64-with-Ubuntu-16.04-xenial
2018-05-23 10:04:44 [scrapy.crawler] INFO: Overridden settings: {'LOGSTATS_INTERVAL': 0, 'ROBOTSTXT_OBEY': True, 'NEWSPIDER_MODULE': 'dynamic_page.spiders', 'HTTPCACHE_STORAGE': 'scrapy_splash.SplashAwareFSCacheStorage', 'BOT_NAME': 'dynamic_page', 'SPIDER_MODULES': ['dynamic_page.spiders'], 'DUPEFILTER_CLASS': 'scrapy_splash.SplashAwareDupeFilter'}
2018-05-23 10:04:44 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.memusage.MemoryUsage']
2018-05-23 10:04:44 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy_splash.SplashCookiesMiddleware',
'scrapy_splash.SplashMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-05-23 10:04:44 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy_splash.SplashDeduplicateArgsMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-05-23 10:04:44 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-05-23 10:04:44 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6024
2018-05-23 10:04:44 [scrapy.core.engine] INFO: Spider opened
2018-05-23 10:04:45 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to <GET https://www.jd.com/error.aspx> from <GET https://search.jd.com/robots.txt>
2018-05-23 10:04:47 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.jd.com/error.aspx> (referer: None)
2018-05-23 10:04:48 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x7fc76d386d30>
[s] item {}
[s] request <GET https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8>
[s] response <200 https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8>
[s] settings <scrapy.settings.Settings object at 0x7fc76d386240>
[s] spider <DefaultSpider 'default' at 0x7fc76cf15518>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]: response.css('div.gl-i-wrap')
Out[1]:
[<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>,
<Selector xpath="descendant-or-self::div[@class and contains(concat(' ', normalize-space(@class), ' '), ' gl-i-wrap ')]" data='<div class="gl-i-wrap">\n\t\t\t\t\t<div class='>]
In [2]: len(response.css('div.gl-i-wrap'))
Out[2]: 30代码分析:我们使用scrapy.Request发送了请求,但由于页面时动态加载的所有我们只收到了30个冰淇淋的信息
下面我们来使用execute 端点解决这个问题:
(course-python3.5-env) bourne@bourne-vm:~/project/dynamic_page$ scrapy shell
2018-05-23 09:51:58 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: dynamic_page)
2018-05-23 09:51:58 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.5.2 (default, Nov 23 2017, 16:37:01) - [GCC 5.4.0 20160609], pyOpenSSL 17.5.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Linux-4.13.0-41-generic-x86_64-with-Ubuntu-16.04-xenial
2018-05-23 09:51:58 [scrapy.crawler] INFO: Overridden settings: {'SPIDER_MODULES': ['dynamic_page.spiders'], 'DUPEFILTER_CLASS': 'scrapy_splash.SplashAwareDupeFilter', 'ROBOTSTXT_OBEY': True, 'NEWSPIDER_MODULE': 'dynamic_page.spiders', 'HTTPCACHE_STORAGE': 'scrapy_splash.SplashAwareFSCacheStorage', 'BOT_NAME': 'dynamic_page', 'LOGSTATS_INTERVAL': 0}
2018-05-23 09:51:58 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage']
2018-05-23 09:51:58 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy_splash.SplashCookiesMiddleware',
'scrapy_splash.SplashMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-05-23 09:51:58 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy_splash.SplashDeduplicateArgsMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-05-23 09:51:58 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-05-23 09:51:58 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x7ff4fda25b38>
[s] item {}
[s] settings <scrapy.settings.Settings object at 0x7ff4fc39fcf8>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [5]: from scrapy_splash import SplashRequest #使用scrapy.splash.Request发送请求
In [6]: url = 'https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8'
In [7]: lua = '''
...: function main(splash)
...: splash:go(splash.args.url)
...: splash:wait(3)
...: splash:runjs("document.getElementById('footer-2017').scrollIntoView(true)")
...: splash:wait(3)
...: return splash:html()
...: end
...: ''' #自定义lua 脚本模拟用户滑动滑块行为
In [8]: fetch(SplashRequest(url,endpoint = 'execute',args= {'lua_source':lua})) #再次请求,我们可以看到现在已通过本机的8050端点渲染了js代码,并成果返回结果
2018-05-23 09:53:55 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8 via http://localhost:8050/execute> (referer: None)
In [9]: len(response.css('div.gl-i-wrap'))
Out[9]: 60最后的任务就回归到了提取内容了阶段了,小伙伴让我们完成整个代码吧!---这里结合scrapy shell 进行测试
修改spider2.py
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from scrapy_splash import SplashRequest
4
5 lua = ''' #自定义lua脚本
6 function main(splash)
7 splash:go(splash.args.url)
8 splash:wait(3)
9 splash:runjs("document.getElementById('footer-2017').scrollIntoView(true)")
10 splash:wait(3)
11 return splash:html()
12 end
13 '''
14
15
16
17 class Spider2Spider(scrapy.Spider):
18 name = 'spider2'
19 allowed_domains = ['search.jd.com']
20 start_urls = ['https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8']
21 base_url = 'https://search.jd.com/Search?keyword=%E5%86%B0%E6%B7%87%E6%B7%8B&enc=utf-8'
22
23 def parse(self, response):
24 page_num = int(response.css('span.fp-text i::text').extract_first())
25
26 for i in range(page_num):
27 url = '%s?page=%s' % (self.base_url , 2*i+1) #通过观察我们发现url页面间有规律
28 yield SplashRequest(url,endpoint = 'execute',args ={'lua_source':lua},callback = self.parse_item)
29
30 def parse_item(self,response): #页面解析函数
31 for sel in response.css('div.gl-i-wrap'):
32 yield {
33 'name':sel.css('div.p-name em').extract_first(),
34 'price':sel.css('div.p-price i::text').extract_first(),
35 }
部分输出结果:

这里我一共拿到了4500条数据,距离6000条还差一些,我估计于网页结构有关,还有就是name字段,我处理了好久,就是包含字母,有高手可以解决如上问题,欢迎积极给我留言,供我学习!
来源:oschina
链接:https://my.oschina.net/u/4373953/blog/3286227