文件操作
FILE *fopen(const char *path, const char *mode);
- FILE:返回值是文件流指针类型
- path:需要打开文件的路径,可以是绝对路径,也可以是相对路径(相对与当前目录的路径)
- mode:
- r: 以读方式打开,如果当前文件不存在,则会报错
- r+: 以读写方式打开,如果当前打开文件不存在,则报错
- w: 以写方式打开,如果文件不存在,则在当前目录下创建该文件;如果当前文件存在,则将当前文件截断(清空)
- w+: 以读写方式打开,其他和w形式相同
- a: 以追加方式打开(文件流指针指向当前文件的尾部,不能读),如果文件不存在则创建
- a+: 以追加方式打开,如果文件不存在则创建,支持可读可写
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream);
- ptr: 将fread读到的内容保存在ptr下
- size: 块的大小
- nmemb: 需要读的块的个数 size* nmemb == 总的字节数量
- stream: 文件流指针,从哪里读
- 返回值: 返回成功读取到的块的个数
- 用法: 将块的大小指定为1(1个字节),需要读的块的个数就可以认为是多少个字节(ptr的内存空间的大小);
需要读的块的个数,对于数组 char arr[1024] = {0},一般传入sizeof(arr)-1,即只读1024个字节,给结尾位置预留一个\0的位置,这种做法是为了防止读了1024个字节,把数组填满了,在数组末尾没有留下\0的位置,在访问arr数组的时候,就会因为找不到\0结束的标志而继续向后查找,就会出现内存访问越界的问题。
size_t fwrite(const void *ptr, size_t size, size_t nmemb,FILE *stream);
- ptr: 需要写的数据,写的数据保存在ptr数组中
- size: 写数据的时候块的大小
- nmemb: 要写入块的个数
- stream: 文件流指针,写到哪里去
- 用法: 将size指定为1,然后返回值就是成功写入数据所占的的字节数量
int fseek(FILE *stream, long offset, int whence);
- stream: 文件流指针
- offset: 偏移量,针对第三个参数whence
- whence: 需要将文件流指针定位到的位置
- SEEK_SET:偏移到文件头部
- SEEK_CUR:偏移到文件流指针当前的位置
- SEEK_END:偏移到文件尾部
int fclose(FILE *stream);
关闭文件
系统调用的文件操作
打开文件
int open(const char *pathname, int flags, mode_t mode)
- pathname: 要打开文件的路径
- flags: 以何种方式打开 (当做位图来处理,每一个bite位)
必须要指定的三个参数当中任选一个
- O_RDONLY:以只读方式打开
- O_WRONLY:以只写方式打开
- O_RDWR:以读写方式打开
可以附加的参数
- O_CREAT:如果打开的文件存在则创建
- O_TRUNC:打开文件之后截断文件
- O_APPEND:以追加方式
需要组合使用的时候,可以采用按位或的方式组合起来
- mode: 对于新创建的文件,设置文件读写权限,可以直接给八进制的文件权限位
返回值: 对于打开成功,则返回一个文件描述符;失败则返回-1
size_t write(int fd,const void* buf,size_t count);
- fd: 文件描述符
- buf: 写入什么数据
- count: 写入数据的大小
size_t read(int fd,char* buf,size_t count)
- fd:文件描述符
- buf:数据存储空间,读到的数据需要存放的位置
- count:最大可以读取的字节数,一般最大是buf空间大小-1
off_t lseek(int fd, off_t offset, int whence);
- fd:文件描述符
- offset:偏移量
- whence:偏移到的位置
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
//关闭标准输入
close(0);
int fd = open("./tmp.txt",O_RDWR | O_CREAT | O_APPEND,0664);
if(fd < 0)
{
perror("open\n");
return 0;
}
//write
int ret = write(fd,"hello linux\n ",11);
if(ret < 0)
{
perror("write error\n");
return 0;
}
lseek(fd,5,SEEK_SET);
//read
char buf[1024] = {'\0'};
ret = read(fd,buf,sizeof(buf)-1);
if(ret < 0)
{
perror("read error\n");
return 0;
}
else if(ret == 0)
{
printf("read size [%d]\n",ret);
}
printf("fd:[%d]\n",fd);
/*
while(1)
{
printf("I'm pausing here\n");
sleep(1);
}
*/
printf("%s\n",buf);
close(fd);
return 0;
}
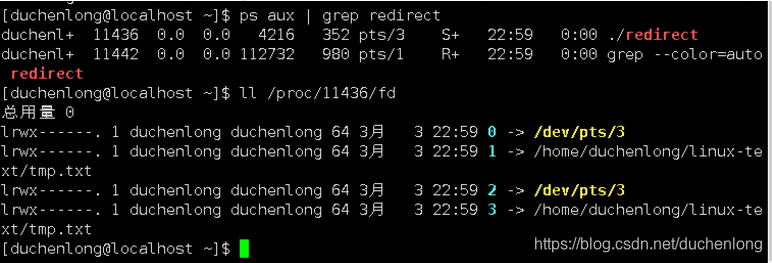
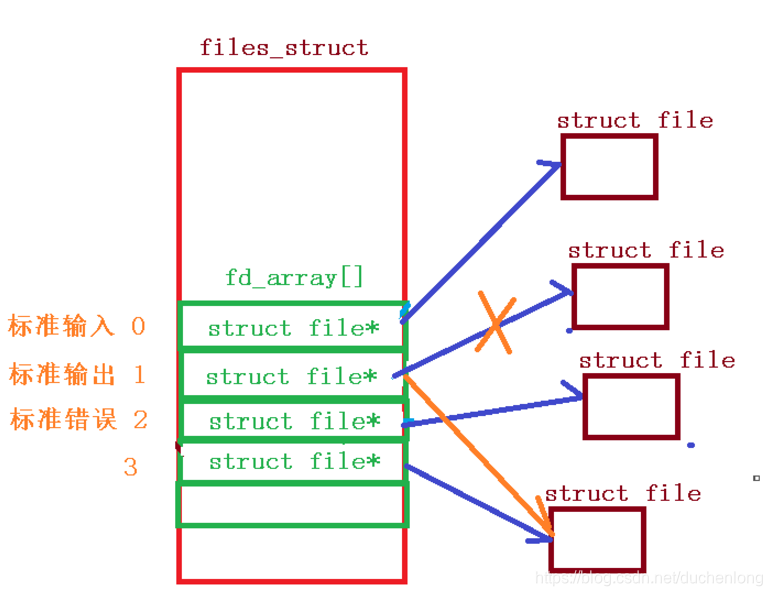
文件描述符
当前打开的文件描述符是有个大于0的整数,其实就是fd_array数组的下标,操作系统可以通过该下标找到对应的文件信息,从而进行读写操作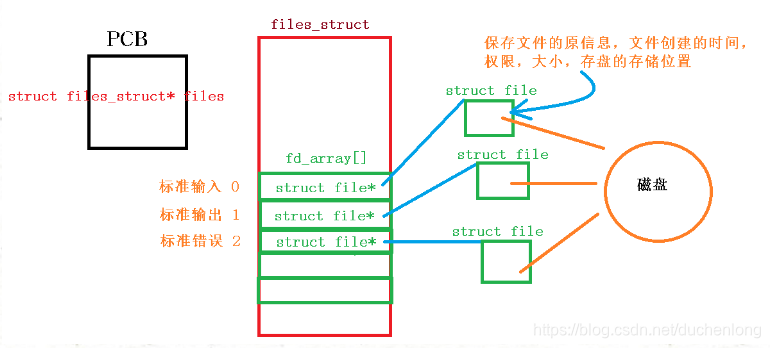
分配规则 :最小末分配规则
ps aux | grep file
ll /proc/6923
ll /proc/6923/fd #查看当前操作系统为进程所分配的文件描述符信息
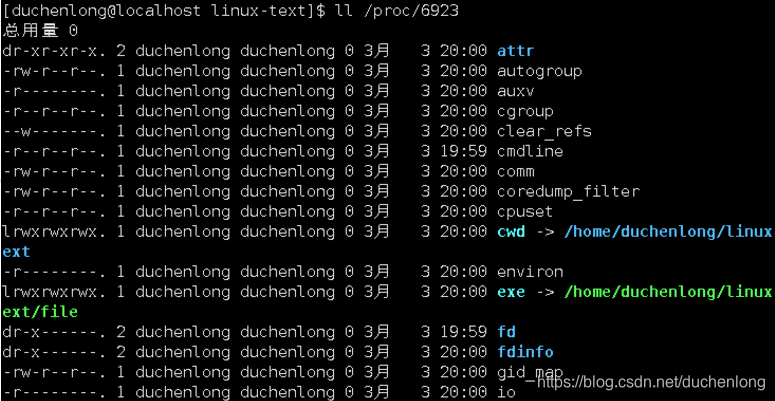
查看进程里的信息
cd /proc/[进程pid]
cd fd #查看进程的文件描述符
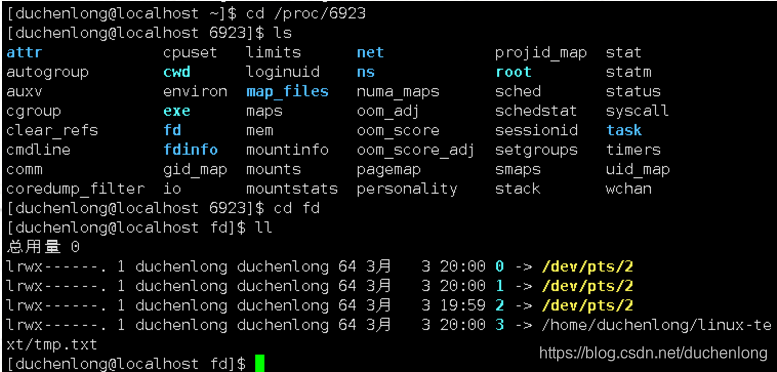
查看完之后,这里的0,1,2分别对应标准输入,标准输出,标准错误
关闭标准输入后,再查看文件描述符,会发现原本应该处于3号下标位置的file文件,却在了关闭的标准输入0号下标位置处。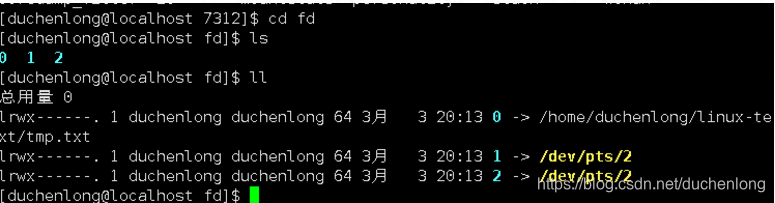
所以,在程序开发阶段,除了有内存泄漏的风险,还会有文件描述符的泄漏,一定需要这个问题:
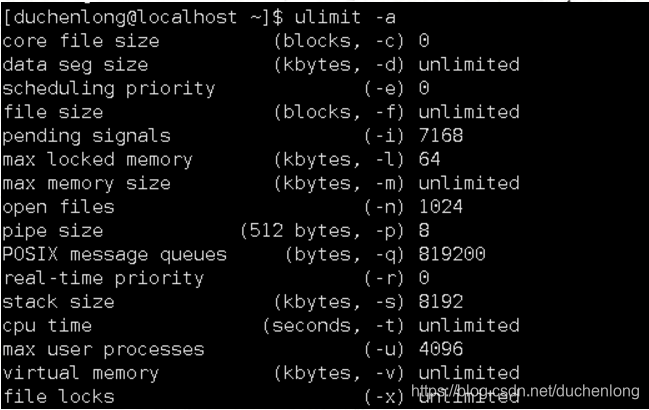
- ulimit -a 查看系统限制
- ll /proc/[pid]/fd 查看当前文件一共打开了多少个文件描述符
查看一次最多可以打开的文件数目
ulimit -a
文件流指针与文件描述符的关系
二者之间是封装的关系,文件流指针(接口都是库函数)封装文件描述符(接口都是系统调用)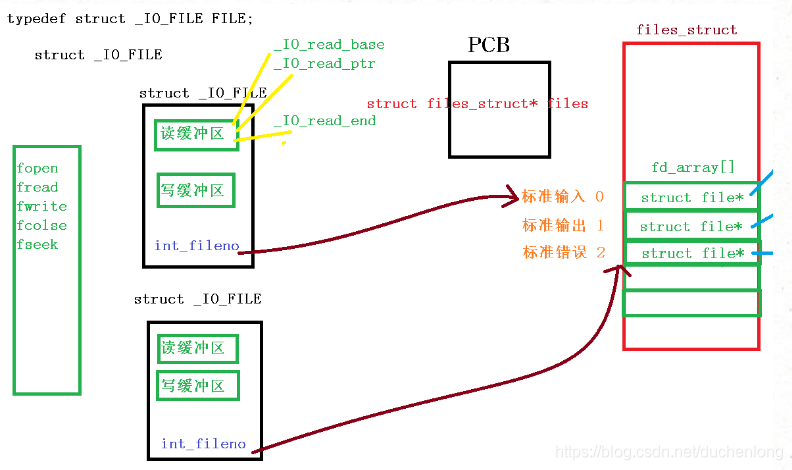
当我们使用fwrite函数进行写操作的时候,其实是先写到写缓冲区,然后当刷新缓冲区的时候,才通过_IO_FILE中保存的文件描述符信息将写到缓冲区当中的内容写到文件当中去
刷新缓冲区
- main函数的return 返回的时候,会刷新缓冲区
- fflush可以强制刷新缓冲区
- 缓冲区满的时候就会刷新缓冲区
- \n也会刷新缓冲区
当使用文件流指针操作文件的时候,一定要考虑读写缓冲区的问题,如果我们向一个文件中写数据的时候,程序崩溃了,有可能就会导致文件流指针写入的数据丢失
当使用文件描述符的时候,就不会出现这个问题,但是由于立即读取,立即写入的操作是非常耗费性能的,所以在写程序当中,我们可以吧一些不是很重要的数据采用文件流指针操作。
重定向
int dup(int oldfd);
int dup2(int oldfd, int newfd);
echo [文本] > [文件名]
echo "hello linux" > tmp.txt
- oldfd和newfd都是文件描述符
- 重定向本质:将newfd文件描述符拷贝oldfd文件描述符
如果oldfd是一个无效的文件描述符,newfd在重定向的时候,并不会关闭,调用dup2函数会
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
int main()
{
int fd = open("./tmp.txt",O_RDWR | O_CREAT,0664);
if(fd < 0)
{
perror("open error\n");
return 0;
}
//重定向
//需求是通过重定向,将本应该输出在标准输出上的内容输出到文件中去
dup2(fd,1);
printf("hello linux\n");
while(1)
{
printf("I'm pausing here\n");
sleep(1);
}
}
动态库和静态库
- 静态库
- windows环境下后缀是.lib
- linux环境下的后缀是.a
静态库会将编译的代码当中的所有函数的代码全部编译到静态库当中,如果程序链接静态库生成可执行程序的时候,会将静态库中所有的代码全部编译到可执行程序当中,所以说在执行的时候,就可以不需要依赖静态库了
静态库的生成与使用
- 静态库的生成
生成静态库的时候,使用.o文件进行编译生成
ar -rc lib[库文件名称(.h文件)].a xxx.o xxx.o
- 静态库的使用
-L [path] 指定库的路径
-L . 在当前目录想寻找
-l [库文件名称(去掉前缀和后缀的名称)] 可以指定链接的库文件是哪一个
gcc main.c -o main -L . -lprintf
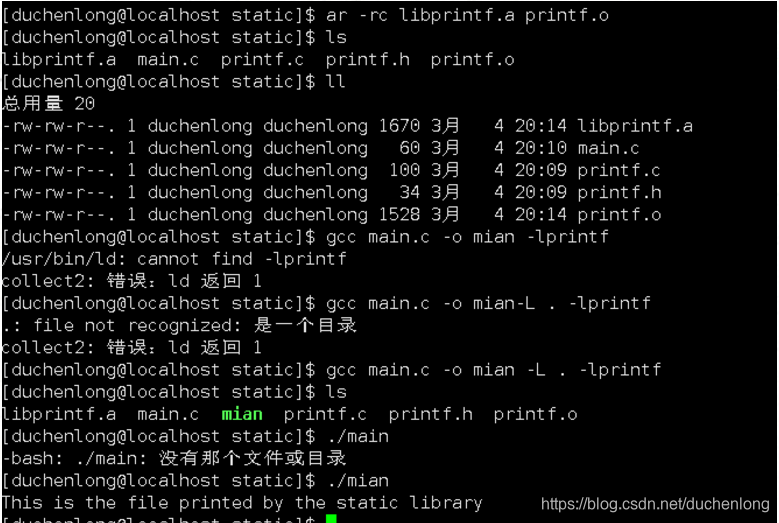
在使用静态库的时候,一定要注意是要用.o文件来进行编译生成,如果不用.o文件,就会出现找不到静态库的情况
生成汇编文件的指令
gcc -c printf.c -o printf.o
- 动态库
- windows环境下后缀是.dll
- linux环境下的后缀是.so (前缀同样是lib libxxxx.so)
当我们编译一个程序依赖一个动态库的时候,可执行程序会将动态库当中的函数保存在符号表中,当运行的时候,操作系统会加载动态库,从而使可执行程序可以通过符号表在动态库当中找到对应的函数来实现功能。
动态库的生成与使用
- 动态库的生成
- -shared 生成共享库的命令行参数
- -fPIC 产生位置无关代码,生成一个逻辑地址,然后程序在执行的时候,会通过逻辑地址找到该程序的准确地址,在不同的程序下都可以使用。
- 动态库的使用
如果可执行程序依赖一个动态库,在程序运行的时候,程序正常找到依赖动态库的方式有,把动态库放在当前可执行程序的目录下,或者在环境变量中设置动态库的搜索路径,设置环境变量
LD_LIBRARY_PATH
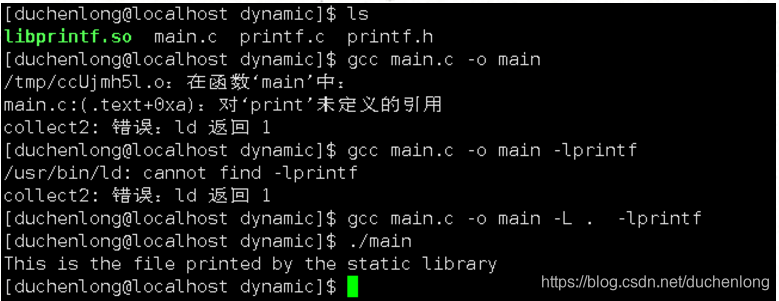
ldd [可执行程序名] #可以查看当前可执行程序运行所依赖的库
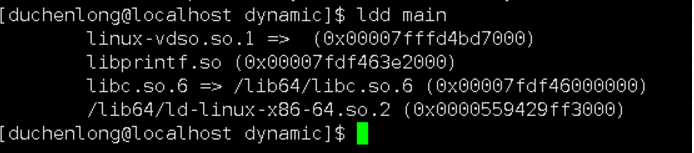
- 静态库和动态库的区别
静态库在生成可执行文件后,如果删除静态库,可执行文件依旧可以执行;但是动态库是因为每次在执行的时候先展开动态库,所以在生成可执行文件后删除动态库,可执行程序无法运行。
来源:CSDN
作者:Windy _ X
链接:https://blog.csdn.net/duchenlong/article/details/104662205