1.之前我们学的都是字符设备驱动,先来回忆一下
字符设备驱动:
当我们的应用层读写(read()/write())字符设备驱动时,是按字节/字符来读写数据的,期间没有任何缓存区,因为数据量小,不能随机读取数据,例如:按键、LED、鼠标、键盘等
2.接下来本节开始学习块设备驱动
块设备:
块设备是i/o设备中的一类, 当我们的应用层对该设备读写时,是按扇区大小来读写数据的,若读写的数据小于扇区的大小,就会需要缓存区, 可以随机读写设备的任意位置处的数据,例如 普通文件(*.txt,*.c等),硬盘,U盘,SD卡,
3.块设备结构:
- 段(Segments):由若干个块组成。是Linux内存管理机制中一个内存页或者内存页的一部分。
- 块 (Blocks): 由Linux制定对内核或文件系统等数据处理的基本单位。通常由1个或多个扇区组成。(对Linux操作系统而言)
- 扇区(Sectors):块设备的基本单位。通常在512字节到32768字节之间,默认512字节
4.我们以txt文件为例,来简要分析下块设备流程:
比如:当我们要写一个很小的数据到txt文件某个位置时, 由于块设备写的数据是按扇区为单位,但又不能破坏txt文件里其它位置,那么就引入了一个“缓存区”,将所有数据读到缓存区里,然后修改缓存数据,再将整个数据放入txt文件对应的某个扇区中,当我们对txt文件多次写入很小的数据的话,那么就会重复不断地对扇区读出,写入,这样会浪费很多时间在读/写硬盘上,所以内核提供了一个队列的机制,再没有关闭txt文件之前,会将读写请求进行优化,排序,合并等操作,从而提高访问硬盘的效率
(PS:内核中是通过elv_merge()函数实现将队列优化,排序,合并,后面会分析到)
5.接下来开始分析块设备框架
当我们对一个*.txt写入数据时,文件系统会转换为对块设备上扇区的访问,也就是调用ll_rw_block()函数,从这个函数开始就进入了设备层.
5.1先来分析ll_rw_block()函数(/fs/buffer.c):

void ll_rw_block(int rw, int nr, struct buffer_head *bhs[])
//rw:读写标志位, nr:bhs[]长度, bhs[]:要读写的数据数组
{
int i;
for (i = 0; i < nr; i++) {
struct buffer_head *bh = bhs[i]; //获取nr个buffer_head
... ...
if (rw == WRITE || rw == SWRITE) {
if (test_clear_buffer_dirty(bh)) {
... ...
submit_bh(WRITE, bh); //提交WRITE写标志的buffer_head continue;
}}
else {
if (!buffer_uptodate(bh)) {
... ...
submit_bh(rw, bh); //提交其它标志的buffer_head
continue;
}}
unlock_buffer(bh); }
}
其中buffer_head结构体,就是我们的缓冲区描述符,存放缓存区的各种信息,结构体如下所示:
struct buffer_head {
unsigned long b_state; //缓冲区状态标志
struct buffer_head *b_this_page; //页面中的缓冲区
struct page *b_page; //存储缓冲区位于哪个页面
sector_t b_blocknr; //逻辑块号
size_t b_size; //块的大小
char *b_data; //页面中的缓冲区
struct block_device *b_bdev; //块设备,来表示一个独立的磁盘设备
bh_end_io_t *b_end_io; //I/O完成方法
void *b_private; //完成方法数据
struct list_head b_assoc_buffers; //相关映射链表
/* mapping this buffer is associated with */
struct address_space *b_assoc_map;
atomic_t b_count; //缓冲区使用计数
};
5.2然后进入submit_bh()中, submit_bh()函数如下:
int submit_bh(int rw, struct buffer_head * bh)
{
struct bio *bio; //定义一个bio(block input output),也就是块设备i/o
... ...
bio = bio_alloc(GFP_NOIO, 1); //分配bio
/*根据buffer_head(bh)构造bio */
bio->bi_sector = bh->b_blocknr * (bh->b_size >> 9); //存放逻辑块号
bio->bi_bdev = bh->b_bdev; //存放对应的块设备
bio->bi_io_vec[0].bv_page = bh->b_page; //存放缓冲区所在的物理页面
bio->bi_io_vec[0].bv_len = bh->b_size; //存放扇区的大小
bio->bi_io_vec[0].bv_offset = bh_offset(bh); //存放扇区中以字节为单位的偏移量
bio->bi_vcnt = 1; //计数值
bio->bi_idx = 0; //索引值
bio->bi_size = bh->b_size; //存放扇区的大小
bio->bi_end_io = end_bio_bh_io_sync; //设置i/o回调函数
bio->bi_private = bh; //指向哪个缓冲区
... ...
submit_bio(rw, bio); //提交bio
... ...
}
submit_bh()函数就是通过bh来构造bio,然后调用submit_bio()提交bio
5.3 submit_bio()函数如下:
void submit_bio(int rw, struct bio *bio)
{
... ...
generic_make_request(bio);
}
最终调用generic_make_request(),把bio数据提交到相应块设备的请求队列中,generic_make_request()函数主要是实现对bio的提交处理
5.4 generic_make_request()函数如下所示:
void generic_make_request(struct bio *bio)
{
if (current->bio_tail) { // current->bio_tail不为空,表示有bio正在提交
*(current->bio_tail) = bio; //将当前的bio放到之前的bio->bi_next里面
bio->bi_next = NULL; //更新bio->bi_next=0;
current->bio_tail = &bio->bi_next; //然后将当前的bio->bi_next放到current->bio_tail里,使下次的bio就会放到当前bio->bi_next里面了
return; }
BUG_ON(bio->bi_next);
do {
current->bio_list = bio->bi_next;
if (bio->bi_next == NULL)
current->bio_tail = ¤t->bio_list;
else
bio->bi_next = NULL;
__generic_make_request(bio); //调用__generic_make_request()提交bio
bio = current->bio_list;
} while (bio);
current->bio_tail = NULL; /* deactivate */
}
从上面的注释和代码分析到,只有当第一次进入generic_make_request()时, current->bio_tail为NULL,才能调用__generic_make_request().
__generic_make_request()首先由bio对应的block_device获取申请队列q,然后要检查对应的设备是不是分区,如果是分区的话要将扇区地址进行重新计算,最后调用q的成员函数make_request_fn完成bio的递交.
5.5 __generic_make_request()函数如下所示:
static inline void __generic_make_request(struct bio *bio)
{
request_queue_t *q;
int ret;
... ...
do {
q = bdev_get_queue(bio->bi_bdev); //通过bio->bi_bdev获取申请队列q
... ...
ret = q->make_request_fn(q, bio); //提交申请队列q和bio
} while (ret);}
这个q->make_request_fn()又是什么函数?到底做了什么,我们搜索下它在哪里被初始化的
如下图,搜索make_request_fn,它在blk_queue_make_request()函数中被初始化mfn这个参数
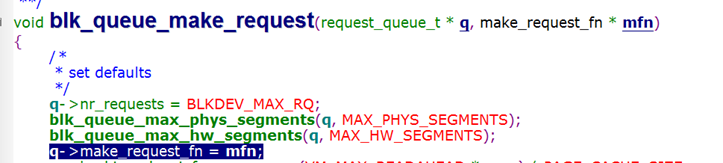
继续搜索blk_queue_make_request,找到它被谁调用,赋入的mfn参数是什么
如下图,找到它在blk_init_queue_node()函数中被调用

最终q->make_request_fn()执行的是__make_request()函数
5.6我们来看看__make_request()函数,对提交的申请队列q和bio做了什么
static int __make_request(request_queue_t *q, struct bio *bio)
{
struct request *req; //块设备本身的队列
... ...
//(1)将之前的申请队列q和传入的bio,通过排序,合并在本身的req队列中
el_ret = elv_merge(q, &req, bio);
... ...
init_request_from_bio(req, bio); //合并失败,单独将bio放入req队列
add_request(q, req); //单独将之前的申请队列q放入req队列
... ...
__generic_unplug_device(q); //(2) 执行申请队列的处理函数
}
1)上面的elv_merge()函数,就是内核中的电梯算法(elevator merge),它就类似我们坐的电梯,通过一个标志,向上或向下.
比如申请队列中有以下6个申请:
4(in),2(out),5(in),3(out),6(in),1(out) //其中in:写出队列到扇区,ou:读入队列
最后执行下来,就会排序合并,先写出4,5,6,队列,再读入1,2,3队列
2) 上面的__generic_unplug_device()函数如下:
void __generic_unplug_device(request_queue_t *q)
{ if (unlikely(blk_queue_stopped(q)))
return;
if (!blk_remove_plug(q))
return;
q->request_fn(q);
}
最终执行q的成员request_fn()函数, 执行申请队列的处理函数
6.本节框架分析总结,如下图所示:

7.其中q->request_fn是一个request_fn_proc结构体,如下图所示:
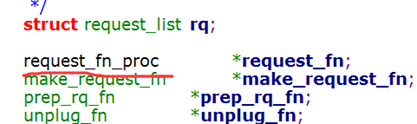
7.1那这个申请队列q->request_fn又是怎么来的?
我们参考自带的块设备驱动程序drivers\block\xd.c
在入口函数中发现有这么一句:
static struct request_queue *xd_queue; //定义一个申请队列xd_queue xd_queue = blk_init_queue(do_xd_request, &xd_lock); //分配一个申请队列
其中blk_init_queue()函数原型如下所示:
request_queue *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock); // *rfn: request_fn_proc结构体,用来执行申请队列中的处理函数 // *lock:队列访问权限的自旋锁(spinlock),该锁需要通过DEFINE_SPINLOCK()函数来定义
显然就是将do_xd_request()挂到xd_queue->request_fn里.然后返回这个request_queue队列
7.2我们再看看申请队列的处理函数 do_xd_request()是如何处理的,函数如下:
static void do_xd_request (request_queue_t * q)
{
struct request *req;
if (xdc_busy)
return;
while ((req = elv_next_request(q)) != NULL) //(1)while获取申请队列中的需要处理的申请
{
int res = 0;
... ...
for (retry = 0; (retry < XD_RETRIES) && !res; retry++)
res = xd_readwrite(rw, disk, req->buffer, block, count); //将获取申请req的buffer成员 读写到disk扇区中,当读写失败返回0,成功返回1
end_request(req, res); //申请队列中的的申请已处理结束,当res=0,表示读写失败
}
}
(1)为什么要while一直获取?
因为这个q是个申请队列,里面会有多个申请,之前是使用电梯算法elv_merge()函数合并的,所以获取也要通过电梯算法elv_next_request()函数获取.
通过上面代码和注释,内核中的申请队列q最终都是交给驱动处理,由驱动来对扇区读写
8.接下来我们就看看drivers\block\xd.c的入口函数大概流程,是如何创建块设备驱动的
static DEFINE_SPINLOCK(xd_lock); //定义一个自旋锁,用到申请队列中static struct request_queue *xd_queue; //定义一个申请队列xd_queue
static int __init xd_init(void) //入口函数
{
if (register_blkdev(XT_DISK_MAJOR, "xd")) //1.创建一个块设备,保存在/proc/devices中
goto out1;
xd_queue = blk_init_queue(do_xd_request, &xd_lock); //2.分配一个申请队列,后面会赋给gendisk结构体的queue成员
... ...
for (i = 0; i < xd_drives; i++) {
... ...
struct gendisk *disk = alloc_disk(64); //3.分配一个gendisk结构体, 64:次设备号个数,也称为分区个数
/* 4.接下来设置gendisk结构体 */
disk->major = XT_DISK_MAJOR; //设置主设备号
disk->first_minor = i<<6; //设置次设备号
disk->fops = &xd_fops; //设置块设备驱动的操作函数
disk->queue = xd_queue; //设置queue申请队列,用于管理该设备IO申请队列
... ...
xd_gendisk[i] = disk;
}
... ...
for (i = 0; i < xd_drives; i++)
add_disk(xd_gendisk[i]); //5.注册gendisk结构体
}
其中gendisk(通用磁盘)结构体是用来存储该设备的硬盘信息,包括请求队列、分区链表和块设备操作函数集等,结构体如下所示:
struct gendisk {
int major; /*设备主设备号*/
int first_minor; /*起始次设备号*/
int minors; /*次设备号的数量,也称为分区数量,如果改值为1,表示无法分区*/
char disk_name[32]; /*设备名称*/
struct hd_struct **part; /*分区表的信息*/
int part_uevent_suppress;
struct block_device_operations *fops; /*块设备操作集合 */
struct request_queue *queue; /*申请队列,用于管理该设备IO申请队列的指针*/
void *private_data; /*私有数据*/
sector_t capacity; /*扇区数,512字节为1个扇区,描述设备容量*/
....
};
9.所以注册一个块设备驱动,需要以下步骤:
- 创建一个块设备
- 分配一个申请队列
- 分配一个gendisk结构体
- 设置gendisk结构体的成员
- 注册gendisk结构体
原文:https://www.cnblogs.com/lifexy/p/7651667.html
来源:https://www.cnblogs.com/Ph-one/p/8497251.html