目标检测基础
在图像中标出目标图像的位置,成为目标检测。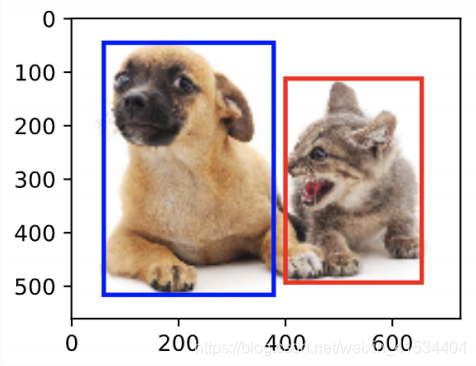
锚框
以每个像素为中心,生成多个大小和宽高比不用的边界框,这些边界框就是锚框。
设输入图像高为,宽为,锚框大小为且宽高比为。那么锚框的宽和高为和。
为了减少计算复杂度,在我们取个锚框中,我们只取包含或的组合,即
共个锚框。
交并比
衡量锚框和真实边界框之间的相似度: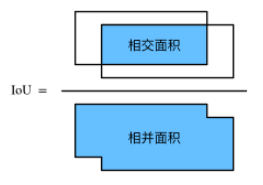
标注训练集的锚框
每个锚框标注两类标签:
- 目标类别.
- 真实边界框相对锚框的偏移量.
我们生成多个锚框,需要将锚框与相似的真实边界框匹配。
- 找出最大交并比的那一组,将同行同列的其他锚框和真实边界框丢弃。
- 重复第一步直至所以锚框都被选中或丢弃。
- 在被丢弃的锚框中根据预设的阈值判断是否为其分配真实边界,若是也按最大交并比分配。
- 未被标注的锚框记为背景

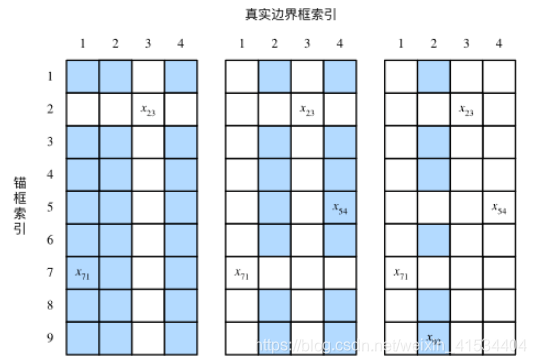
偏移量标注:
其中常数默认值
图像风格迁移
将一副图像的风格自动加在另一幅图上
本课用预训练好的模型,它能分解出图片的样式风格,我们将内容图像的样式风格数值根据模型改变。令其与原图内容损失最小,与样式图像样式损失最小。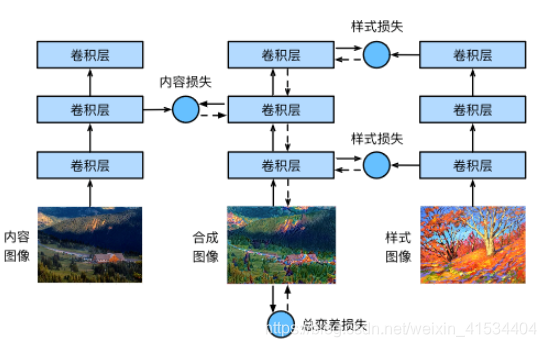
模型
这里用预训练的VGG19,一般来说,越靠近输入层的输出越容易抽取图像的细节信息,反之则越容易抽取图像的全局信息。
选用VGG靠近输出的层 – 第四个卷积快的最有一个卷积层为内容层,用不同层的输出 – 每个卷积快的第一个卷积层为样式层。
损失函数
内容损失
直接使用平方误差损失
样式损失
使用平方误差损失,不过使用的输入是Gram矩阵,它表达了通道上样式特征的相关性。在输入前将样式层的输出变换为
总变差损失
用于降噪,使邻近的像素值相似
总损失函数
将上面三个损失函数加权和,即构成了总损失函数,这里为了学习样式,我们将样式损失的权值设置的较大,另外两个较小。
图像分类案例1
任务
这里分类任务是CIFAR-10图像分类问题,比赛网址是https://www.kaggle.com/c/cifar-10
比赛数据分为训练集和测试集。训练集包含 50,000 图片。测试集包含 300,000 图片。两个数据集中的图像格式均为PNG,高度和宽度均为32像素,并具有三个颜色通道(RGB)。图像涵盖10个类别:飞机,汽车,鸟类,猫,鹿,狗,青蛙,马,船和卡车。
模型
使用RseNet18,18层的残差网络
ResNet-18网络结构:ResNet全名Residual Network残差网络。Kaiming He 的《Deep Residual Learning for Image Recognition》获得了CVPR最佳论文。他提出的深度残差网络在2015年可以说是洗刷了图像方面的各大比赛,以绝对优势取得了多个比赛的冠军。而且它在保证网络精度的前提下,将网络的深度达到了152层,后来又进一步加到1000的深度。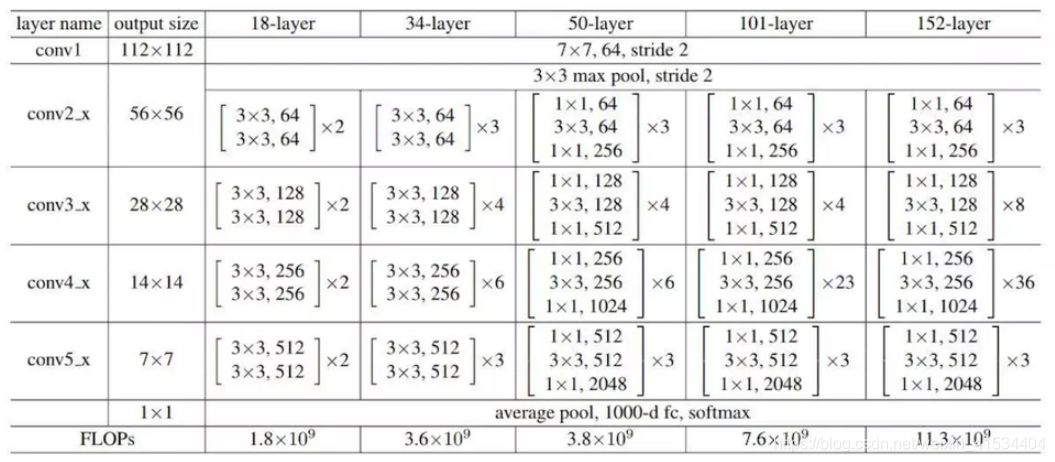
来源:CSDN
作者:Void_Pointer -
链接:https://blog.csdn.net/weixin_41534404/article/details/104490420