机器学习
概念
机器学习:先来看看百度百科的定义,“专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能”。可以看出,机器学习就是让机器模拟人的学习,最终目的是实现人工智能。也就是说,人们为了实现人工智能,其中的一种方式是通过机器学习。
那么,机器是怎么学习呢?简单的解释就是,人们给机器(一般指电脑)大量的数据,机器通过某种方法(算法)计算出这些数据的特征,之后机器就可以根据这些特征,来判断一个新给出的数据是什么。机器进行学习的过程就是发现数据的特征的过程。
让机器进行学习的方法(算法)有很多,主要的有回归算法、神经网络、SVM(支持向量机)、聚类算法、决策树、朴素贝叶斯等等。最近非常热门的深度学习属于机器学习方法中的神经网络算法,研究者在原来的神经网络算法上进行了改进,从而形成了这个热门的深度学习的方式。深度学习的方式让机器学习达到了更高的水平。
模式识别:上面讲了什么是机器学习,那么模式识别又是什么呢?模式识别的百度解释为“对表征事物或现象的各种形式的(数值的、文字的和逻辑关系的)信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程”。事实上,模式识别就是机器学习,在早期的工业应用中首先开始的是模式识别,后来发展到学术界就是机器学习。
早期的模式识别的方式是,人们给出某件事物的特征,电脑根据这些特征去辨认一件新东西是不是属于这个事物。由人为提取特征后交给机器,然后让机器可以根据这些特征辨认其他的东西。比如,我先给出两个大耳朵、长鼻子、四条腿、很胖这些是猪的特征,然后电脑根据这些特征,可以去分辨你新给出的一个动物是不是猪。但是这样的效果并不是很好,如果你新给出的是一匹马,但是电脑根据特征就可能也判断为是一只猪。因此在这些的基础上,机器学习做了改进,人们只需要给出一件事物,让电脑自己去发现其中的特征,寻找其中的规律,然后让电脑用这些规律去对新事物做判断。现在来说模式识别和机器学习就是等价的。
机器学习方法的分类:机器学习分为有监督学习和无监督学习。有监督学习就是把分好类的事物提供给机器,机器根据不同的类别发现特征。无监督学习就是有机器自己对所有事物进行特征和规律的计算,然后将这些事物分为不同的类别。
应用
下面讲一下matlab中模式识别的一个应用——车牌识别。
车牌识别:车牌识别是模式识别中文字识别的一个重要应用,即根据已有车牌,识别出车牌的号码。
矩阵匹配(模板匹配)
矩阵匹配:首先准备多个模板,每个模板都有各自的信息。将要识别的数据和已有的多个模板进行匹配,找到匹配度最大的那一个模板,该数据的信息就是该模板的信息。
矩阵匹配的数学方法为:矩阵 A 和 B 的点进行下面的相关性函数数学运算,得出两个矩阵的相关度,当相关度的值越接近于1,A 和 B 的匹配度越大。
更加具体的可以去搜索皮尔森相关系数进行了解。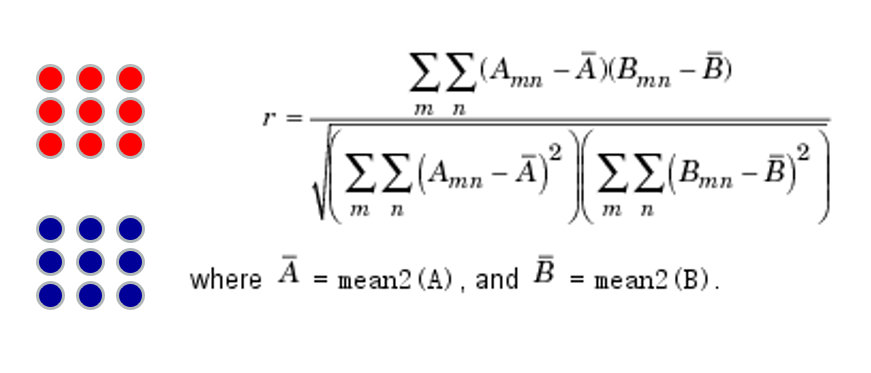
MATLAB函数实现:
r = corr2( A , B );
利用相关性函数,计算出A和B的相关度,但是 A 和 B 必须是尺寸大小相同的矩阵或图片。如果对两张尺寸不同的图片使用该函数,会出现报错。
F = imresize( F ,[ num1, num2] );
将图片尺寸大小变换成 num1×num2 。如果对两张不同大小的图片计算相关度,可以先使用该函数将图片归一化为相同大小。
1、用矩阵匹配(模板匹配)的方法实现文字识别
通过和右侧的各个模板做相关性运算,识别出左侧图片包含的文字。

思路
事先将右侧模板和文字建立一一对应关系,然后利用相关性函数,找到匹配度最大的模板,输出该模板对应的文字信息。
步骤
我所在目录的文件信息如下,右侧十五张模板在pic文件夹中,n.bmp为左侧要识别的图片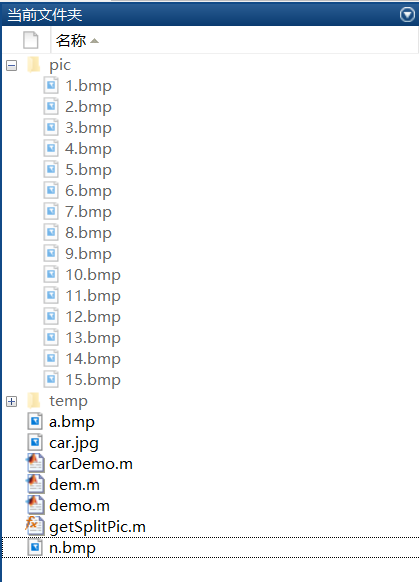
-
读入图片,用图片和第一张模板进行相关度运算,计算出相关度系数,保存到 r 中。
通过计算可以得出图片和第一个模板的相关度系数,根据该思路,可以通过循环,来计算和每个图的相关度系数,从而可以找到相关度最大的模板。
-
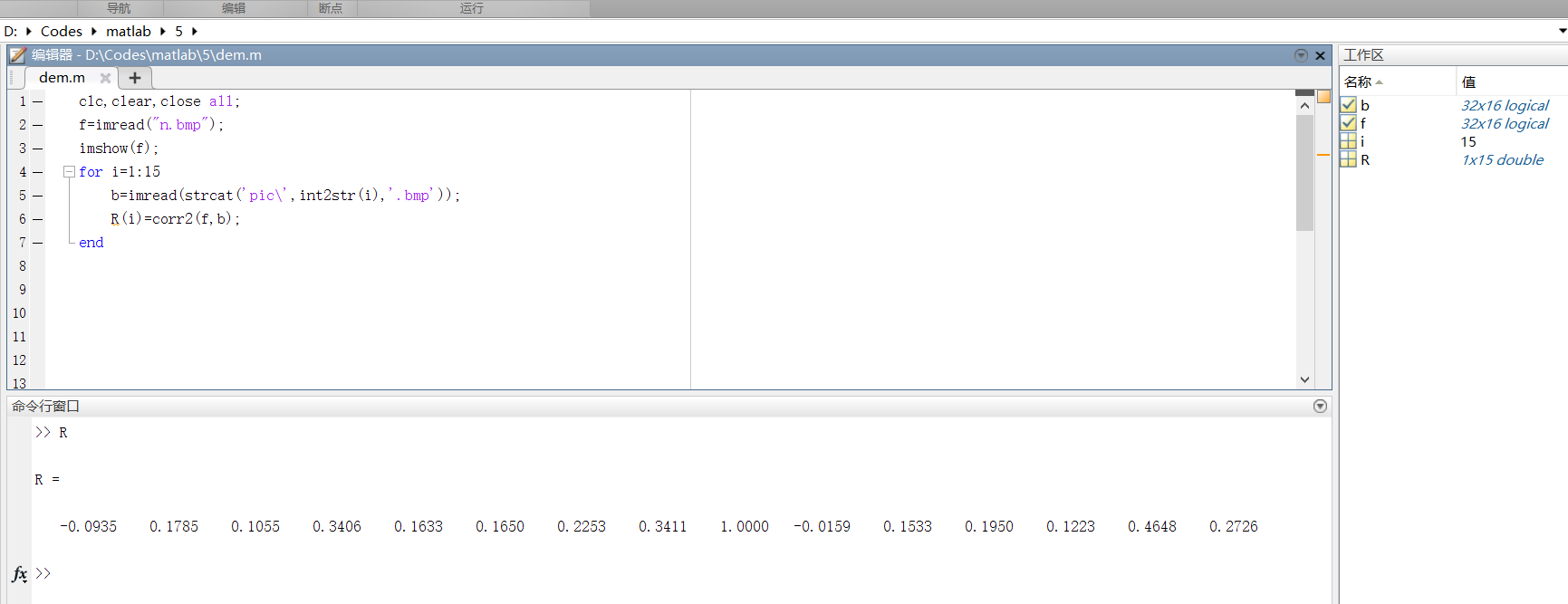
循环计算和每一个图做计算的相关系数的值,存到数组 R 中。
由第一步的结果可知通过循环计算,可以得到和每个模板的相关度系数。
为了可以循环计算和每个图的相关度系数,需要循环读入每一个图。在 imread(‘image.type’) 中的参数为字符串,由于模板图片的名字是有规律的,所以可以循环创建字符串来达到循环读入的效果。
创建字符串可以用 strcat(‘str1’,‘str2’,…) 将多个字符串连接为一个。
在本例中用strcat( ‘pic’ , int2str( i ) , ‘.bmp’ ),利用 i 做循环,因为 i 是整数,所以用 int2str() 转换为字符串,将整体连接成字符串读入模板图片。
利用 R(i) 来接收和每个模板的相关度系数。
下图我在命令行输出 R 的结果,可以看到和每个模板的相关度系数。
该步代码为:clc,clear,close all; f=imread('n.bmp'); imshow(f); for i=1:15 b=imread(strcat('pic\',int2str(i),'.bmp')); R(i)=corr2(f,b); end -
建立模板数组,将每个图片对应到相应的文字信息。
建立一个字符串,和模板图片的顺序对应,每个位置对应一个字符。
利用 str=‘xxxxxxx…’ 即可创建字符串。
该步只需新加代码:
font=‘ABCDEFGHNVJXSMQ’;
访问第 i 个元素使用 font( i ) -
从计算出的 R 中找到相关系数最大的值,对应的模板数组里面的信息就是该图片的文字。
利用 [ n, k]=max( R ) 找到 R 中最大的值,其中 n 是这个最大值, k 是该最大值的下标。
用函数 disp( ‘xxxxx’ ) 可以在控制台输出字符串。
本例代码为:clc,clear,close all; font='ABCDEFGHNVJXSMQ'; f=imread("n.bmp"); imshow(f); for i=1:15 b=imread(strcat('pic\',int2str(i),'.bmp')); R(i)=corr2(f,b); end [n,k]=max(R); s=strcat('这个字母是',font(k)); disp(s);


2、用矩阵匹配(模板匹配)的方法实现车牌识别
对于以下车牌
和下面的模板
利用模板匹配的方式识别该车牌的内容。
思路:要想得到车牌每个字符的信息,首先要对车牌进行图片切割,然后分别对每个字符和每个模板进行匹配,找出该字符代表的信息,从而得到整个车牌的内容。
步骤:
目录的文件夹信息如下,car.jpg 是车牌图片,temp 文件夹内保存的是模板。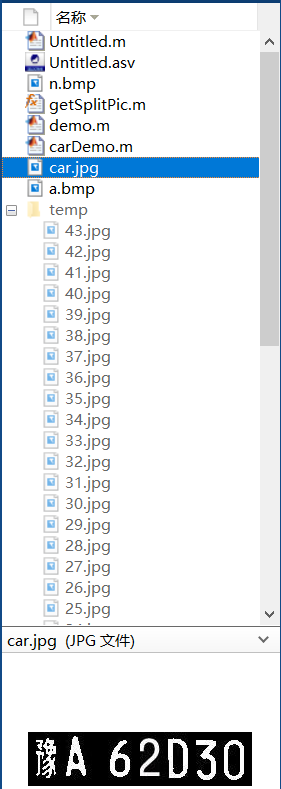
-
读入车牌,然后建立数组,将模板图片和文字信息对应。
-
对车牌进行切割,得到每个字符单独的图片。这里我们选择建立一个函数来专门处理车牌的分割。matlab中建立函数的方式如下。
点击主页->新建->函数,便可建立一个函数文件,新建函数文件的默认页面如下:function [outputArg1,outputArg2] = function-name(inputArg1,inputArg2) %UNTITLED2 此处显示有关此函数的摘要 % 此处显示详细说明 outputArg1 = inputArg1; outputArg2 = inputArg2; end- function 函数标识
- [outputArg1,outputArg2] 函数返回参数列表,可以在函数中直接赋值代表返回值,多个参数之间用逗号隔开
- function-name 函数名字,函数的名字要和文件的名字相同
- (inputArg1,inputArg2) 传入参数列表,该函数需要传入的参数要在这里面声明,多个参数之间用逗号隔开
- 两行% 表示函数的摘要和说明,在命令行用 “help 函数名” 可以显示摘要和声明
- 下面是函数体
- end 表示函数的结尾
这里我们建立一个切割图片的函数:函数的注释我都在函数中标明了,因此不在进行解释,如果有不懂的可以留言交流。
函数代码:function [fs,num] = SplitPic(f) %返回值fs是一个cell型数据,每个元素保存一张分割好的图片 %返回值num保存一共分割出了多少字符 num=0; %num保存有几个区域 %将图片转为二值图 g=rgb2gray(f); bw=imbinarize(g); %计算图片向下的投影累加和 hs=sum(bw); %计算图片的宽度 [~,w]=size(bw); s=0; %保存每个字符的起始位置 b=0; %保存每个字符的结束位置 i=1; %用i循环扫描投影和数组 %循环切割非空白区域 while(i<w) %判断循环是否超出边界 while(hs(i)==0&&i<w) %用while让i经过空白区域 i=i+1; end s=i; %s保存空白区域过后的非空白区域的第一个位置 while(hs(i)>0&&i<w) %让i经过非空白区域 i=i+1; end b=i; %b保存非空白区域的最后一个位置后的位置 if(s~=b) x=bw(:,s:b-1); %把二值图中横向位置为s到b-1的非空白区域分割出来 [r,~]=find(x); %找出纵向位置非空白区域 num=num+1; %每找到一个非空白区域该值加一 fs{num}=f(min(r):max(r),s:b-1,:); %从原图中切割出该非空区域 end end -
调用函数对图片进行切割,将切割好的图片返回给 fs 和 num ,fs 保存切割好的字符, num 保存一共有多少个字符。新建一个字符串,保存后面提取到的信息。
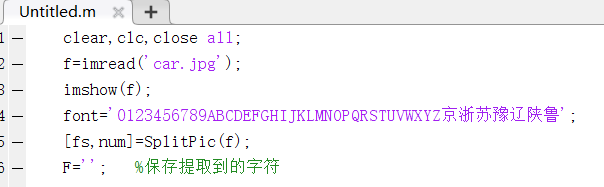
新增代码为:[fs,num]=SplitPic(f); F=''; %保存提取到的字符 -
循环处理每个分割出来的字符,计算和每个模板的相关度。因为原图是RGB图,因此切割出来的图片要先转换为二值图。由于字符图片和模板图片大小不一定相同,因此用 imresize 归一化相同大小。每个字符去和每个模板计算相关度,找到相关度最大的模板,这个模板的信息就是该字符的信息。
-
运行程序可以得到结果
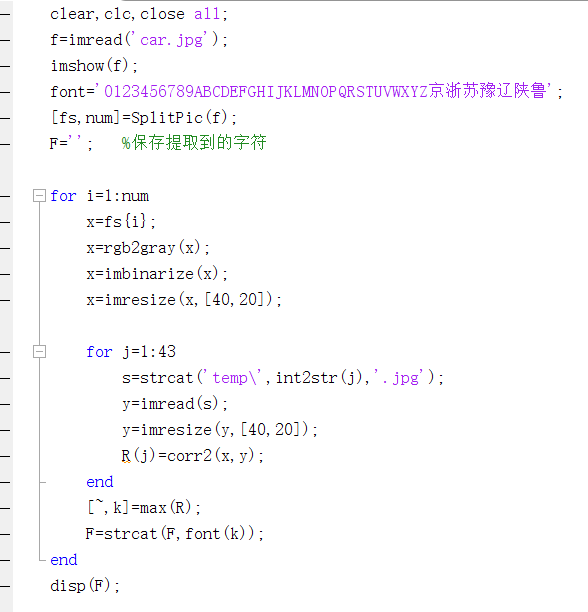
本例代码:clear,clc,close all; f=imread('car.jpg'); imshow(f); font='0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ京浙苏豫辽陕鲁'; [fs,num]=SplitPic(f); F=''; %保存提取到的字符 for i=1:num x=fs{i}; x=rgb2gray(x); x=imbinarize(x); x=imresize(x,[40,20]); for j=1:43 s=strcat('temp\',int2str(j),'.jpg'); y=imread(s); y=imresize(y,[40,20]); R(j)=corr2(x,y); end [~,k]=max(R); F=strcat(F,font(k)); end disp(F);



文章资源连接
由于图片较多,我把文件做成压缩包,上传到CSDN,我把连接放到下面了
点击这里下载
来源:CSDN
作者:上官永石
链接:https://blog.csdn.net/qq_36793268/article/details/90697263