深深的感受到“细节决定成败”,“蝴蝶效应“一句话细节体现工作质量也体现个人能力。今天复盘回顾一个个坑哭的小细节,更好的迎接未来挑战。
1,窥见数据三重门
全局着眼,登高望远,窥见数据的三重门:ODS,DW,APP
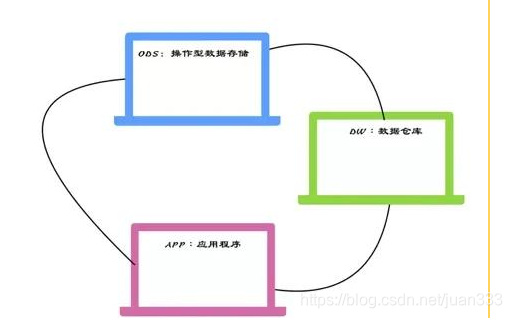
每一层的存在分管着不同的数据工作,一起探探门里的细节,把握清晰的脉络。
ODS层:是关注用户重点事务的原始业务表,重在离线统计用户细节的行为日志表。日志表可以包含业务表的相关数据,但是缺乏结构,需要ETL。
DW层:将ODS层作为直接的数据源,去建设满足业务分析要求的数仓,进行基础整合BAS,然后开发出事实层/维度层/宽表层。其目的将一大坨数据整合分类,方便快速查询。
APP层:是我们熟知的应用层,有报表,数据产品,API接口,特征数据,专题集市,OLAP, 业务系统。
三层形成上下游的环形网络,缺一不可。从而解耦三者的关系实现低耦合高内聚任重道远。
2,危险的金字塔
三重门可以拆解成一个倒立的金字塔,这个倒立着的金字塔是危险的,总要一种摇摇欲坠的感觉,需要数据攻城狮们殚心竭虑的守护。
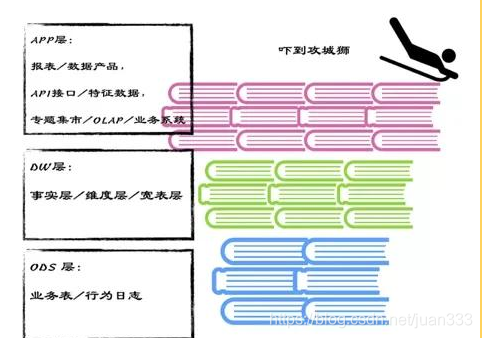
因为ODS数据源:业务表,埋点日志的采集 两大源头,一些细枝末节的变动,牵动ODS基础层,生产一只黑蝴蝶,让DW/APP层来一场雪崩。累惨数据工程师。
业务表和日志采集:动要有原则:
1,能添加值不要新增列,比如在json类型中加值,不要增加额外的列名。
2,能增加列不要新增一个表。
3,能加一个辅助表,不要重构原有表结构。
4,遵循添值,增列,副表的优先集,提前周知变化,早做应对。
3,动一下就是一万年
数据开发的工作流程是这样的。
接到一个数据需求,
第一步,我们要分析需求的合理性,能不能做。
第二步,我们要怎么做,哪一种方式最合适,安全快速。
第三步,需要哪些数据资源权限。
第四步,用SQL实现出自己的ETL逻辑代码。
第五步,测试自己的逻辑代码,看看小单位数据是否合理。
第六步,提交审核,生产数据(回溯数据很慢)。
其实在大数据量面前,生产数据的过程是漫长的,需要花费很多时间去等待。

第五步的测试极为重要 ,而且需要使用八倍镜,仔细推荐,认真核对。
比如:统计当日支付要看支付时间不要看下单时间应为下单可以在第二天支付。还有一个小小“=”号让统计意义南辕北辙。也一定要主要主要表的字段类型,不要望文生义,id不一定是数字。
第五步一定要多花点时间反复校验,不要因为小细节而花大时间回溯数据。
4,借助工具
用IDE 管理自己的ETL代码,方便查找。
高亮的语法提示也能更好的发现细节。
代码一定有做好格式处理,清晰可读很重要。
多写wiki,磨练写作基本功,沉淀常用的数据方法。
工具不要多,两个就够了。
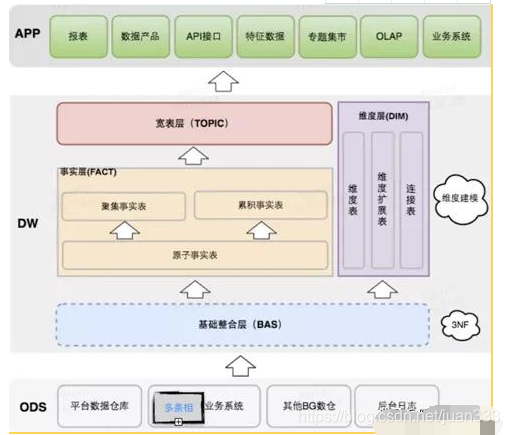
数据仓的经典模型
来源:CSDN
作者:juan333
链接:https://blog.csdn.net/juan333/article/details/104134744