
决策树算法在工业中本身应用并不多,但是,目前主流的比赛中的王者,包括GBDT、XGBOOST、LGBM都是以决策树为积木搭建出来的,所以理解决策树,是学习这些算法的基石,今天,我们就从模型调用到调参详细说说决策树的使用方法。
一、什么是决策树
既然要用决策树,那么我们首先要知道决策树的基本原理。
初听到决策树这个名字的时候,我觉得他是一种最不像机器学习算法的算法。因为这不就是编程里最基本的if-else选择语句嘛,还能有多厉害?
而且我们生活中的和决策树相关的例子比比皆是,假如你出去买东西,如果价格合适,那就买下来,如果价格太高,那就和商家讨价还价,如果商家同意打折,那就买下来,如果商家不同意便宜点,那就放下东西走人。这就会构建出下图这样的一个决策树。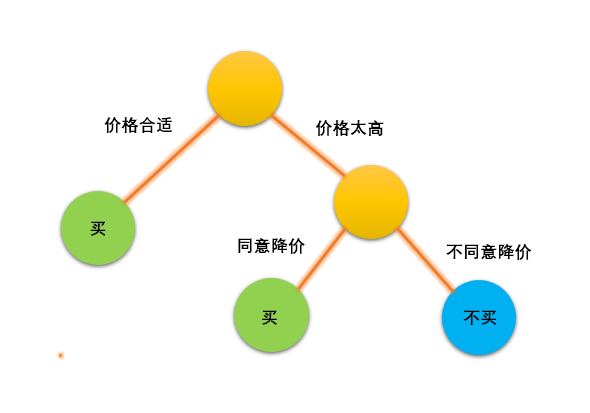
别急,决策树算法之所以能成为机器学习十大算法,必然有其过人之处。仔细想想,决策树算法并不是单纯地进行决策,而是通过数据集让程序学会像人一样做这一系列的决策过程。
所以决策树算法的核心是要解决两个问题:
1)如何从数据集中找出最佳分枝?
2)如何在合适的时候让决策树停止生长,防止过拟合?
几乎所有与决策树有关的模型调整方法,都逃不开这两个核心问题。
关于第一个问题,一个数据集必然给出了很多的特征,先按照哪个特征来高效地划分数据集,是决策树需要解决的最大问题。当然,我们完全可以按照特征从头到尾顺次来划分数据集,但是,这样做其实并不好,因为你如果一不小心把重要的特征排到了后边,那么你的决策树会很低效。
比如说,你的一个决策树算法在分辨兔子和鸡(想到了小时候被鸡兔同笼问题支配的恐惧了吗),而你恰恰把眼睛数量、嘴巴数量等次要特征排在了前边,而把腿的数量等重要特征放在了最后,那结果就是本来只需要一步决策就可以分辨出来的问题,你的算法必须执行很多步。
为了解决这个问题,就必须要设置一个衡量标准来衡量特征的重要程度。
于是,机器学习专家们就去信息学科中偷来了一个词语:信息熵。信息越确定(单一),信息熵越小;信息越多变(混乱),信息熵越大。
通过比较拆分前后的信息熵之差找出更重要的特征的方法,就产生了ID3和C4.5两种决策树算法。
之后,科学家又找到了一个更好的衡量方法——基尼系数。于是就产生了CART决策树。
在实际使用中,信息熵和基尼系数的划分效果基本相同。只是信息熵因为要计算对数,速度上比计算基尼系数慢一些。另外,如果数据维度过高或者存在大量噪音数据,使用信息熵很容易过拟合。综上,在我们使用决策树的过程中一般无脑采用基尼系数就好了。
信息熵和基尼系数的公式如下: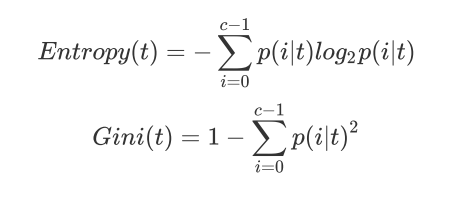
因为篇幅有限,这里就不再详解这些基本公式的含义了,翻开任意一本算法书,都已经讲得很明白了。
【关于决策树的原理以及直观理解,我最近在制作一个动画来直观展示,制作好之后会插入文章中,感兴趣的可以后续关注一下。】
对于ID3,C4.5以及CRAT这三种决策树,单纯从在scikit-learn中使用的角度来说,没必要了解他们的区别,但是在面试等场合还是需要了解一下的。所以我附在了本文后边,感兴趣的可以阅读完正文之后去附录中阅读。
二、决策树的使用
从应用角度可以把决策树分为分类决策树和回归决策树。
顾名思义,分类决策树用来解决分类问题,回归决策树用来解决回归问题。分别通过:“DecisionTreeClassifier()”,“DecisionTreeRegressor()”两个函数来调用。
用scikit-learn调用决策树的方式我在机器学习超详细实践攻略(8):使用scikit-learn构建模型的通用模板【万字长文】中已经给出,只要按照模板套用即可,下面,重点介绍使用决策树需要用到的参数以及调参过程。
分类决策树总共有12个参数可以自己调整,这么多参数一个个记起来太麻烦,我们可以把这些参数分成三个类别。
1、用于模型调参的参数:
1)criterion(划分标准):有两个参数 ‘entropy’(熵) 和 ‘gini’(基尼系数)可选,默认为gini。
2)max_depth(树的最大深度):默认为None,此时决策树在建立子树的时候不会限制子树的深度。也可以设置具体的整数,一般来说,数据少或者特征少的时候可以不管这个值。如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体的取值取决于数据的分布。常用的可以取值10-100之间。
3)min_samples_split(分割内部节点所需的最小样本数):意思就是只要在某个结点里有k个以上的样本,这个节点才需要继续划分,这个参数的默认值为2,也就是说只要有2个以上的样本被划分在一个节点,如果这两个样本还可以细分,这个节点就会继续细分
4)min_samples_leaf(叶子节点上的最小样本数):当你划分给某个叶子节点的样本少于设定的个数时,这个叶子节点会被剪枝,这样可以去除一些明显异常的噪声数据。默认为1,也就是说只有有两个样本类别不一样,就会继续划分。如果是int,那么将min_samples_leaf视为最小数量。如果为float,则min_samples_leaf为分数,ceil(min _ samples _ leaf * n _ samples)为每个节点的最小样本数。
2、用于不平衡样本预处理参数:
- class_weight: 这个参数是用于样本不均衡的情况下,给正负样本设置不同权重的参数。默认为None,即不设置权重。具体原理和使用方法见:【机器学习超详细实践攻略(12):三板斧干掉样本不均衡问题之2——通过正负样本的惩罚权重解决样本不均衡】
3、不重要的参数:
这些参数一般无需自己手工设定,只需要知道具体的含义,在遇到特殊情况再有针对性地调节即可。
1)‘max_features’:如果我们训练集的特征数量太多,用这个参数可以限制生成决策树的特征数量的,这个参数在随机森林中有一定的作用,但是因为随机抽取特征,这个算法有概率把数据集中很重要的特征筛选掉,所以就算特征太多,我宁愿采用降维算法、或者计算特征重要度自己手工筛选也不会设置这个参数。
2) ‘min_impurity_decrease’(节点划分最小不纯度): 这是树增长提前结束的阈值,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点 。一般不推荐改动。
3)‘max_leaf_nodes’(最大叶子节点数): 默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立一个在最大叶子节点数内最优的决策树。限制这个值可以防止过拟合,如果特征不多,可以不考虑这个值,但是如果特征多的话,可以加以限制。
4)‘random_state’(随机数种子): 默认为None,这里随便设置一个值,可以保证每次随机抽取样本的方式一样。
5)‘splitter’:用来控制决策树中划分节点的随机性,可选”best"和“random"两个值,默认为“best”。当输入”best",决策树在分枝时虽然随机,但是还是会优先选择更重要的特征进行分枝,输入“random",决策树在分枝时会更加随机,从而降低对训练集的拟合成都。这也是防止过拟合的一种方式。当然,这种防止过拟合的方法属于“伤敌一千自损八百”的方法,树的随机分枝会使得树因为含有更多的不必要信息而更深更大,所以我们最好使用上边的剪枝参数来防止过拟合,这个参数一般不用动。
6)min_weight_fraction_leaf(叶子节点最小的样本权重和):这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们才会稍微注意一下这个值。
7)‘ccp_alpha’(复杂性参数):这个参数同样是是用于避免树的过度拟合。在树生成节点的过程中,加入一个惩罚因子(逻辑回归里的惩罚项),避免生成的树过于冗余,公式如下: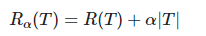
其中T就是树的总节点个数, 就是我们设置的参数,随着树节点的增多,最终损失函数就会变得更大。默认为0,即不加入惩罚项。
以上就是分类决策树12个参数的介绍。
说完了分类决策树,回归决策树就自然而然懂了,它和分类决策树在参数上的区别只有两个地方:
1) ‘criterion’: 评价划分节点质量的参数,类似于分类决策树的熵,有三个参数可选,‘mse’(default)均方误差;'friedman_mse’均方误差近似,最小化L2 loss;'mae’平均绝对误差,最小化L1 loss。
2)少了’class_weight’: None,当然,回归问题也就不存在给每个类别加不同的权重了。
三、决策树调参步骤:
通过上边的介绍,可以看到在模型调参的过程中只需要重点调整决策树的4个参数即可。这四个参数中,criterion只有两个值可选,是最好调的,剩下三个参数在调参过程中会互相影响,需要我们确定一个顺序。
1)确定criterion参数(决策树划分标准):这里可以简单比较一下,不过一般情况选用gini系数模型效果更好。
2)通过绘制得分曲线缩小max_depth(树的最大深度)的搜索范围,得到一个暂定的max_depth。
之所以第一个参数调max_depth,是因为模型得分一般随着max_depth单调递增,之后会区域稳定。
3)利用暂定的max_depth参数,绘制曲线,观察得分随着min_samples_split(分割内部节点所需的最小样本数)的变化规律,从而确定min_samples_split参数的大概范围。
因为随着min_samples_split的增大,模型会倾向于向着简单的方向发展。所以如果模型过拟合,那么随着min_samples_split的增大,模型得分会先升高后下降,我们选取得分最高点附近的min_samples_split参数;如果模型欠拟合,那么随着min_samples_split的增大,模型得分会一直下降,接下来调参时只需要从默认值2开始取就好。
4)利用暂定的max_depth和min_samples_split参数,绘制曲线,观察得分随着min_samples_leaf(叶子节点上应有的最少样例数)的变化规律,从而确定min_samples_leaf参数的大概范围。该参数的范围确定方法同上。
5)利用网格搜索,在一个小范围内联合调max_depth、min_samples_split和min_samples_leaf三个参数,确定最终的参数。
初看这些话,可能觉得很难理解,别急,下面我们通过一个对手写数字识别数据集的调参实例来逐条理解这几句话。
0)首先导入必要包和加载数据集
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split,GridSearchCV,cross_val_score
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import numpy as np
#准备数据集
data = load_digits()
x = data.data
y = data.target
1)比较决策树划分标准对模型影响
DT = DecisionTreeClassifier(random_state = 66)
score = cross_val_score(DT,x,y,cv=10).mean()
print('基尼系数得分: %.4f'%score)
DT = DecisionTreeClassifier(criterion = 'entropy',random_state = 66)
score = cross_val_score(DT,x,y,cv=10).mean()
print('熵得分: %.4f'%score)
输出:
基尼系数得分: 0.8252
熵得分: 0.8036
可以看到,使用基尼系数比使用熵得到的结果更好。
2.1)在大范围内搜索max_depth的参数范围。
画出得分随着这个参数变化的曲线,观察两者的关系。
###在大范围内画出max_depth这个参数变化曲线
ScoreAll = []
for i in range(10,100,10):
DT = DecisionTreeClassifier(max_depth = i,random_state = 66)
score = cross_val_score(DT,data.data,data.target,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
# print(ScoreAll[,0])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.show()
输出:
最优参数以及最高得分: [20. 0.82524209]
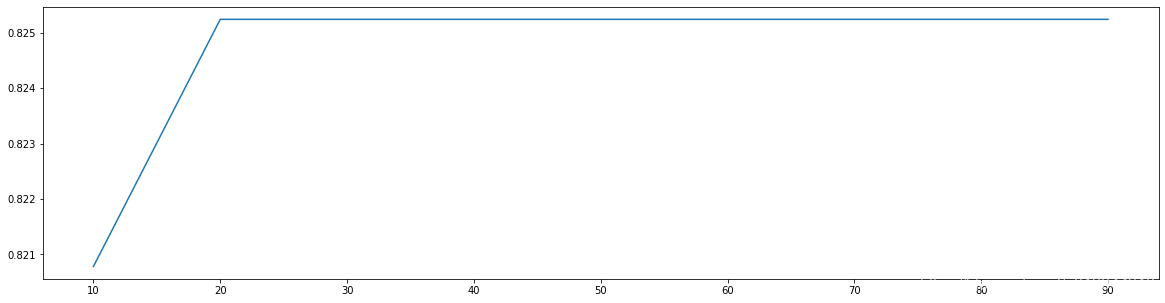
可以看到,当树的深度达到20的时候,再增加树的深度,模型正确率不再上升。
但是别忘了,我们为了能够搜索更大的范围,只搜索了10的整数倍的树的深度。既然转折发生在20附近,那么我们在20附近进一步搜索。
2.2)进一步缩小max_depth这个参数的范围
代码和上述一样,只是这回在10~25之间搜索,每个值都不放过。
###进一步缩小max_depth这个参数的范围
ScoreAll = []
for i in range(10,25):
DT = DecisionTreeClassifier(max_depth = i,random_state = 66)
score = cross_val_score(DT,data.data,data.target,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
# print(ScoreAll[,0])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.show()
输出:
最优参数以及最高得分: [13. 0.82691186]
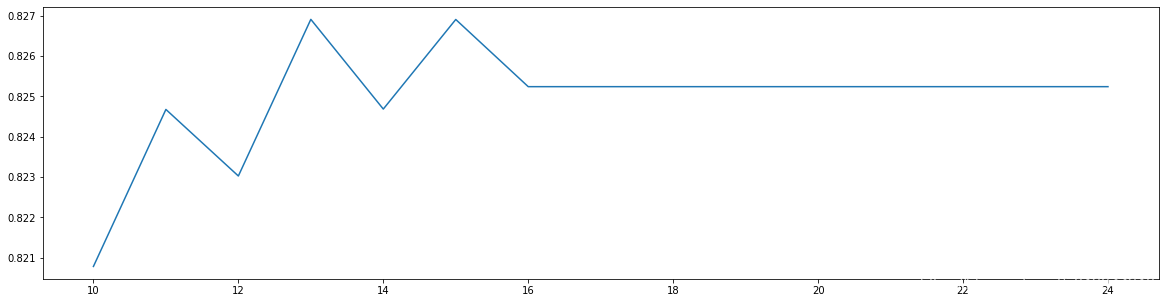
从这回的曲线里已经看到了得分随着树的高度的曲折变化了。我们暂定树的高度为13,模型达到了 0.826。
3)利用暂定的max_depth参数,绘制曲线,观察得分随着min_samples_split(分割内部节点所需的最小样本数)的变化规律,从而确定min_samples_split参数的大概范围。
为了减少计算量,令max_depth = 13,然后看看min_samples_split的变化趋势。这里就让min_samples_split从2取到30吧。
#单独看看min_samples_split的变化趋势
ScoreAll = []
for i in range(2,30):
DT = DecisionTreeClassifier(max_depth = 13,min_samples_split = i,random_state = 66)
score = cross_val_score(DT,data.data,data.target,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
# print(ScoreAll[,0])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.show()
输出:
最优参数以及最高得分: [7. 0.83309848]
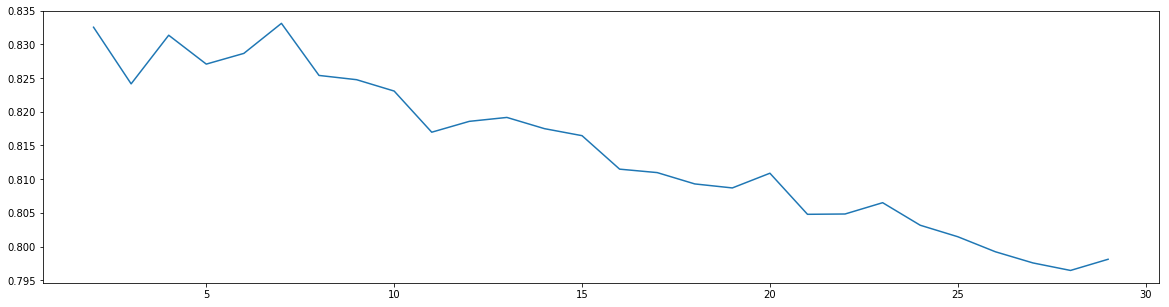
可以看到,随着min_samples_split的增大,模型得分上升一点之后就一直下降,这就说明模型稍微有一些过拟合。所以我们下一步调参时min_samples_split直接从2~10这个范围取数就可以。
4)确定min_samples_leaf参数的大概范围。
###调min_samples_leaf这个参数
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
import numpy as np
ScoreAll = []
for i in range(1,30):
DT = DecisionTreeClassifier(min_samples_leaf = i,min_samples_split = 7,max_depth = 13,random_state = 66)
score = cross_val_score(DT,data.data,data.target,cv=10).mean()
ScoreAll.append([i,score])
ScoreAll = np.array(ScoreAll)
max_score = np.where(ScoreAll==np.max(ScoreAll[:,1]))[0][0] ##这句话看似很长的,其实就是找出最高得分对应的索引
print("最优参数以及最高得分:",ScoreAll[max_score])
# print(ScoreAll[,0])
plt.figure(figsize=[20,5])
plt.plot(ScoreAll[:,0],ScoreAll[:,1])
plt.show()
输出:
最优参数以及最高得分: [1. 0.83309848]
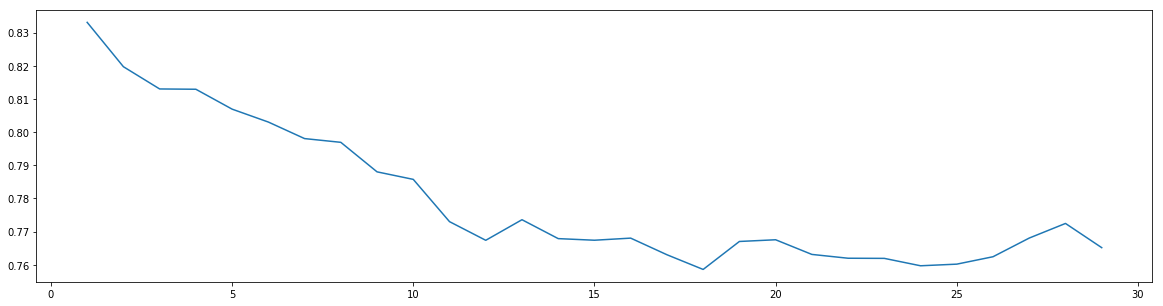
5)利用网格搜索,在小范围内联调max_depth、min_samples_split和min_samples_leaf三个参数
根据我们前边的一系列操作,我们确定因为max_depth在13附近,min_samples_split在7附近,min_samples_leaf在1附近是最优参数,所以我们分别在这个附近利用网格搜索得到最优参数(具体在这个附近多远需要自己把握)。因为要涉及到三个参数联调,这里就要用到网格搜索函数。代码如下:
#max_depth、min_samples_leaf和min_samples_split一块儿调整
param_grid = {
'max_depth':np.arange(10, 15),
'min_samples_leaf':np.arange(1, 8),
'min_samples_split':np.arange(2, 8)}
rfc = DecisionTreeClassifier(random_state=66)
GS = GridSearchCV(rfc,param_grid,cv=10)
GS.fit(data.data,data.target)
print(GS.best_params_)
print(GS.best_score_)
输出:
{‘max_depth’: 14, ‘min_samples_leaf’: 2, ‘min_samples_split’: 5}
0.8397328881469115
【注:这里采用网格搜索计算得分,和交叉验证得分的计算方式是一模一样的】
可以看到,最终模型从默认参数下的0.8252提高到了0.8397。这里我们可以看到,上述三个参数和我们前边所暂定的参数都不一样。证明三者之间确实是相互影响的!
当然,这只是我个人总结的一个调参顺序,仅用来参考,没必要这么固化。其实,正是调参过程充满的各种不确定性,才是调参的真正魅力所在。
四、附录:ID3、C4.5和CART决策树的比较
ID3决策树算是决策树的鼻祖,它采用了信息增益来作为节点划分标准,但是它有一个缺点:在相同条件下,取值比较多的特征比取值少的特征信息增益更大,导致决策树偏向于选择数量比较多的特征。所以,C4.5在ID3的基础上做了改进,采用了信息增益率来解决这个问题,而且,C4.5采用二分法来处理连续值的特征。以上两个决策树都只能处理分类问题。
决策树的集大成者是CART决策树。
很多文章里提到CART决策树和ID3、C4.5的区别时,都简单地归结为两者使用的节点划分标准不同(用基尼系数代替信息熵)。其实除此之外,CART和以上两种决策树最本质的区别在于两点:
1、CART决策树对树的形状做了规定,只能二叉树,同时规定,内部结点特征的取值左为是,右为否。这个二叉树的规定,使得对于同样的数据集,CART决策树的深度更深。
2、从它的英文名:classification and regression就可以看出,CART决策树不仅可以处理分类问题,而且还可以处理回归问题。在处理回归问题时,回归cart树可以用MSE等多种评价指标。
3、值得一提的是,随机森林、GBDT、XGBOOST算法都是基于CART决策树来的。
三种树的对比做一个总结:
- ID3:倾向于选择水平数量较多的变量,可能导致训练得到一个庞大且深度浅的树;另外输入变量必须是分类变量(连续变量必须离散化);最后无法处理空值。
- C4.5在ID3的基础上选择了信息增益率替代信息增益,同时,采用二分法来处理连续值的特征,但是生成树浅的问题还是存在,且只能处理分类问题。
- CART以基尼系数替代熵,划分规则是最小化不纯度而不是最大化信息增益(率)。同时只允许生成二叉树,增加树的深度,而且可以处理连续特征和回归问题。
- CART决策树是根据ID3等决策树改进来的,scikit-learn实现的决策树更像是CRAT决策树。但是,节点的划分标准也可以选择采用熵来划分。
五、本系列相关文章
来源:CSDN
作者:东写西读1
链接:https://blog.csdn.net/u013044310/article/details/103996047