
Python是一种简单易学,功能强大的编程语言,它有高效率的高层数据结构,简单而有效地实现面向对象编程。Python简洁的语法和对动态输入的支持,再加上解释性语言的本质,使得它在大多数编程语言的使用场景中都堪称最优解。
成熟的Python工程师在自己的工作中会使用不同的工具,也因此产生不同见解,有人爱Django,有人爱Numpy,有人爱Tensorflow,甚至有些程序员会自己创造工具。不过对于初学者而言,答案可能只有一个:爬虫。
那么什么是爬虫?互联网上有着无数的网页,包含着海量的信息,无孔不入、森罗万象。但很多时候,无论出于数据分析或产品需求,我们需要从某些网站,提取出我们感兴趣、有价值的内容,那么我们如何去提取?难道还是要靠传统模式去粘贴和复制吗?在当今大数据时代,显然这种模式已经不适用,所以我们需要一种能自动获取网页内容并可以按照指定规则提取相应内容的程序。这就是爬虫!
特别的Python爬虫入门到实战课程,从最基础的爬虫分类讲起,用史上最详细的视频教程帮助你快速入门爬虫。只需要10个小时,你就能从新手完成进阶!
这是一门什么样的课程?
这是一门面向Python初学者和爬虫爱好者,提供爬虫知识入门和进阶的课程,可以帮助你快速入门。
这门课程有什么特点?
这门课程为零基础人士进行了特别优化。我们将从爬虫基础开始讲起,视频教程内容十分详细,涵盖几乎所有初学者必备知识点。可以帮你实现从零到进阶的过程。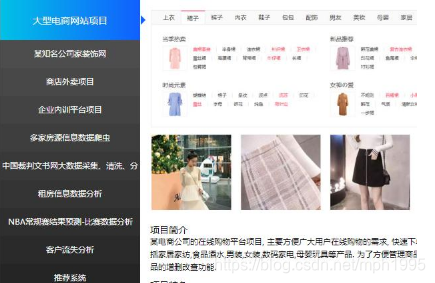
学习本课程的目的:
- 让大家掌握现实中编写Python爬虫会遇到的方方面面的问题,让大家以后在实际爬虫工作中,不惧任何挑战。
课程大纲
一、Python网络爬虫
1、什么是爬虫
2、一起编写第一个爬虫
二、专业HTTP分析工具Fiddler的使用
1、Fiddler 用户界面
2、Fiddler 主菜单
3、Fiddler 工具栏
4、信任 Fiddler 证书
5、Inspector
6、保存\导入\导出数据流
7、使用Fiddler检测手机流量
8、Fiddler自动生成爬虫代码
三、实际爬虫Python编码问题
1、vim中如何查看文件编码
2、str编码转换
3、print函数如何处理编码
4、浏览器如何推断网页编码
5、使用Python推测一个文件的编码并给出推断概率
6、Windows 命令行编码查看与设置
7、如何解决Windows命令行的乱码问题
四、urllib2 的使用
1、urllib2请求返回网页
2、urllib2使用代理访问网页
3、urllib2修改header
五、TesseractOCR语言模型爬取使用带验证码登录的网站
1、Tesseract 使用介绍
2、Tesseract 语言模型训练
3、带验证码网站登录示例
六、Beautiful Soup
1、bs4解析器选择
2、lxml解析器安装与使用
七、XPath & CSS选择器
1、XPath语法讲解
2、XPath 选择示例
3、浏览器对XPath的支持
4、CSS选择器原理
5、CSS选择器使用实例
八、PhantomJS
1、安装
2、脚本传参
3、页面加载
4、Code Evaluation
5、DOM 操作
6、网络请求及响应
九、SeleniumWebdriver
1、元素的定位
2、添加等待时间
3、打印信息
4、浏览器的操作
5、浏览器前进后退
6、键盘事件
十、Scrapy大型框架使用代理服务器爬取
1、鼠标事件
2、定位一组元素
3、上传文件
4、下拉框处理
5、调用JavaScript脚本
6、控制浏览器滚动条
7、原理解析
8、代理ip的获取
9、代理ip的使用
10、架构概览
11、Spider
12、Selector
13、Item
14、Scrapy Shell
15、Item Pileline
十一、Scrapy、分布式集群多代理爬虫Redis、分布式集群Redis MongoDB在爬虫里的应用
1、Requests and Responses
2、Link Extractor
3、Logging
4、编写应用MongoDB的Scrapy-Redis 爬虫
5、应用之前讲过的多代理技术\分布式爬虫技术\Redis集群技术, 编写一个大型房源网站整站遍历抓取爬虫项目
十二、数据分析、工具与模块
1、Numpy
2、Pandas
3、Scipy
4、Matplotlib
5、Seaborn
6、Scikit-Learn
Python必须掌握的核心能力:
-
掌握各类HTTP调试器用法
-
理解网络爬虫编写的基本套路
-
了解网络爬虫编写的各种陷阱
-
能够应对动态网站爬取
-
能够应对带有验证码的网站
-
能够应对需要浏览器渲染的网站
-
能够应对分布式抓取需要
-
能够应对反爬虫技术
-
能够应对无界面抓取
-
能够利用爬虫平台
强力推荐的学习素材
本套课程是小编千挑万选的一个学习视频资料,即使不懂Python的人,也能在半个月之内掌握Python爬虫。
最后,如何获取这份资料呢
请大家转发本文+关注并私信小编:“资料”,即可免费获取哦!
温馨提示,不管再忙都要坚持每天要至少保持3个小时以上的练习时间 。
来源:CSDN
作者:编程小悦
链接:https://blog.csdn.net/mph1995/article/details/103921984