转自:https://laike9m.com/blog/huan-zai-yi-huo-bing-fa-he-bing-xing,61/
还在疑惑并发和并行?
OK,如果你还在为并发(concurrency)和并行(parallesim)这两个词的区别而感到困扰,那么这篇文章就是写给你看的。搞这种词语辨析到底有什么意义?其实没什么意义,但是有太多人在混用错用这两个词(比如遇到的某门课的老师)。不论中文圈还是英文圈,即使已经有数不清的文章在讨论并行vs并发,却极少有能讲清楚的。让一个讲不清楚的人来解释,比不解释更可怕。比如我随便找了个网上的解释:
前者是逻辑上的同时发生(simultaneous),而后者是物理上的同时发生.
并发性(concurrency),又称共行性,是指能处理多个同时性活动的能力,并发事件之间不一定要同一时刻发生。
并行(parallelism)是指同时发生的两个并发事件,具有并发的含义,而并发则不一定并行。
来个比喻:并发和并行的区别就是一个人同时吃三个馒头和三个人同时吃三个馒头。
看了之后,你懂了么?不懂,更晕了。写出这类解释的人,自己也是一知半解,却又把自己脑子里模糊的影像拿出来写成文章,让读者阅毕反而更加疑惑。当然也有可能他确实懂了,但是写出这种文字也不能算负责。至于本文,请相信,一定是准确的,我也尽量做到讲解清晰。
OK,下面进入正题,concurrency vs parallesim
让我们大声朗读下面这句话:
“并发”指的是程序的结构,“并行”指的是程序运行时的状态
即使不看详细解释,也请记住这句话。下面来具体说说:
并行(parallesim)
这个概念很好理解。所谓并行,就是同时执行的意思,无需过度解读。判断程序是否处于并行的状态,就看同一时刻是否有超过一个“工作单位”在运行就好了。所以,单线程永远无法达到并行状态。
要达到并行状态,最简单的就是利用多线程和多进程。但是 Python 的多线程由于存在著名的 GIL,无法让两个线程真正“同时运行”,所以实际上是无法到达并行状态的。
并发(concurrency)
要理解“并发”这个概念,必须得清楚,并发指的是程序的“结构”。当我们说这个程序是并发的,实际上,这句话应当表述成“这个程序采用了支持并发的设计”。好,既然并发指的是人为设计的结构,那么怎样的程序结构才叫做支持并发的设计?
正确的并发设计的标准是:使多个操作可以在重叠的时间段内进行(two tasks can start, run, and complete in overlapping time periods)。
这句话的重点有两个。我们先看“(操作)在重叠的时间段内进行”这个概念。它是否就是我们前面说到的并行呢?是,也不是。并行,当然是在重叠的时间段内执行,但是另外一种执行模式,也属于在重叠时间段内进行。这就是协程。
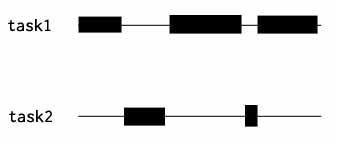
使用协程时,程序的执行看起来往往是这个样子:

task1, task2 是两段不同的代码,比如两个函数,其中黑色块代表某段代码正在执行。注意,这里从始至终,在任何一个时间点上都只有一段代码在执行,但是,由于 task1 和 task2 在重叠的时间段内执行,所以这是一个支持并发的设计。与并行不同,单核单线程能支持并发。
经常看到这样一个说法,叫做并发执行。现在我们可以正确理解它。有两种可能:
- 原本想说的是“并行执行”,但是用错了词
- 指多个操作可以在重叠的时间段内进行,即,真的并行,或是类似上图那样的执行模式。
我的建议是尽可能不使用这个词,容易造成误会,尤其是对那些并发并行不分的人。但是读到这里的各位显然能正确区分,所以下面为了简便,将使用并发执行这个词。
第二个重点是“可以在重叠的时间段内进行”中的“可以”两个字。“可以”的意思是,正确的并发设计使并发执行成为可能,但是程序在实际运行时却不一定会出现多个任务执行时间段 overlap 的情形。比如:我们的程序会为每个任务开一个线程或者协程,只有一个任务时,显然不会出现多个任务执行时间段重叠的情况,有多个任务时,就会出现了。这里我们看到,并发并不描述程序执行的状态,它描述的是一种设计,是程序的结构,比如上面例子里“为每个任务开一个线程”的设计。并发设计和程序实际执行情况没有直接关联,但是正确的并发设计让并发执行成为可能。反之,如果程序被设计为执行完一个任务再接着执行下一个,那就不是并发设计了,因为做不到并发执行。
那么,如何实现支持并发的设计?两个字:拆分。
之所以并发设计往往需要把流程拆开,是因为如果不拆分也就不可能在同一时间段进行多个任务了。这种拆分可以是平行的拆分,比如抽象成同类的任务,也可以是不平行的,比如分为多个步骤。
并发和并行的关系
Different concurrent designs enable different ways to parallelize.
这句话来自著名的talk: Concurrency is not parallelism。它足够concise,以至于不需要过多解释。但是仅仅引用别人的话总是不太好,所以我再用之前文字的总结来说明:并发设计让并发执行成为可能,而并行是并发执行的一种模式。
最后,关于Concurrency is not parallelism这个talk再多说点。自从这个talk出来,直接引爆了一堆讨论并发vs并行的文章,并且无一例外提到这个talk,甚至有的文章直接用它的slide里的图片来说明。比如这张:
以为我要解释这张图吗?NO。放这张图的唯一原因就是萌萌的gopher。
再来张特写:
之前看到知乎上有个关于go为什么流行的问题,有个答案是“logo萌”当时我就笑喷了。
好像跑题了,继续说这个 talk。和很多人一样,我也是看了这个 talk 才开始思考 concurrency vs parallesim 的问题。为了研究那一堆推小车的 gopher 到底是怎么回事,我花费了相当多的时间。实际上后来我更多地是通过网上的只言片语(比如SO的回答)和自己的思考弄清了这个问题,talk 并没有很大帮助。彻底明白之后再回过头来看这个 talk,确实相当不错,Andrew Gerrand 对这个问题的理解绝对够深刻,但是太不新手向了。最大问题在于,那一堆 gopher 的例子不够好,太复杂。Andrew Gerrand 花了大把时间来讲述不同的并发设计,但是作为第一次接触这个话题的人,在没有搞清楚并发并行区别的情况下就去研究推小车的 gopher,太难了。“Different concurrent designs enable different ways to parallelize” 这句总结很精辟,但也只有那些已经透彻理解的人才能领会,比如我和看到这里的读者,对新手来说就和经文一样难懂。总结下来一句话,不要一开始就去看这个视频,也不要花时间研究推小车的gopher。Gopher is moe, but confusing.
2015.8.14 更新
事实上我之前的理解还是有错误。在《最近的几个面试》这篇文章里有提到。最近买了《七周七并发模型》这本书,发现其中有讲,在此摘录一下(英文版 p3~p4):
Although there’s a tendency to think that parallelism means multiple cores, modern computers are parallel on many different levels. The reason why individual cores have been able to get faster every year, until recently, is that they’ve been using all those extra transistors predicted by Moore’s law in parallel, both at the bit and at the instruction level.
Bit-Level Parallelism
Why is a 32-bit computer faster than an 8-bit one? Parallelism. If an 8-bit computer wants to add two 32-bit numbers, it has to do it as a sequence of 8-bit operations. By contrast, a 32-bit computer can do it in one step, handling each of the 4 bytes within the 32-bit numbers in parallel. That’s why the history of computing has seen us move from 8- to 16-, 32-, and now 64-bit architectures. The total amount of benefit we’ll see from this kind of parallelism has its limits, though, which is why we’re unlikely to see 128-bit computers soon.
Instruction-Level Parallelism
Modern CPUs are highly parallel, using techniques like pipelining, out-of-order execution, and speculative execution.
As programmers, we’ve mostly been able to ignore this because, despite the fact that the processor has been doing things in parallel under our feet, it’s carefully maintained the illusion that everything is happening sequentially. This illusion is breaking down, however. Processor designers are no longer able to find ways to increase the speed of an individual core. As we move into a multicore world, we need to start worrying about the fact that instructions aren’t handled sequentially. We’ll talk about this more in Memory Visibility, on page ?.
Data Parallelism
Data-parallel (sometimes called SIMD, for “single instruction, multiple data”) architectures are capable of performing the same operations on a large quantity of data in parallel. They’re not suitable for every type of problem, but they can be extremely effective in the right circumstances. One of the applications that’s most amenable to data parallelism is image processing. To increase the brightness of an image, for example, we increase the brightness of each pixel. For this reason, modern GPUs (graphics processing units) have evolved into extremely powerful data-parallel processors.
Task-Level Parallelism
Finally, we reach what most people think of as parallelism—multiple processors. From a programmer’s point of view, the most important distinguishing feature of a multiprocessor architecture is the memory model, specifically whether it’s shared or distributed.
最关键的一点是,计算机在不同层次上都使用了并行技术。之前我讨论的实际上仅限于 Task-Level 这一层,在这一层上,并行无疑是并发的一个子集。但是并行并非并发的子集,因为在 Bit-Level 和 Instruction-Level 上的并行不属于并发——比如引文中举的 32 位计算机执行 32 位数加法的例子,同时处理 4 个字节显然是一种并行,但是它们都属于 32 位加法这一个任务,并不存在多个任务,也就根本没有并发。
所以,正确的说法是这样:
并行指物理上同时执行,并发指能够让多个任务在逻辑上交织执行的程序设计
按照我现在的理解,并发针对的是 Task-Level 及更高层,并行则不限。这也是它们的区别。
评论内容:
鸡翅 • 3 months ago
实际上个人觉得从计算机体系发展的角度来介绍更为合适,也更容易理解。
从Instruction-Level Parallelism来说,这个其实和Task-Level Parallelism是息息相关的。从早期的计算机来看,任何一个严格意义上的Task-Level Parallelism必然是对应着Instruction-Level Parallelism的,而Instruction-Level Parallelism必然要依赖于硬件的。这种观点是很容易接受的,因为这种计算机实质上属于批处理系统,执行时不存在外部干预,并且不存在程序设计语言,只有指令。
任何属于冯诺依曼结构的计算机,其中的CPU(或者说核)必然是串行执行指令的。所以在任何单CPU机器上,是不存在严格意义上,或者说狭义上的并行的--在指令级别的严格意义上的并行,是指在一个足够小的时刻,可以允许大于一条的指令在执行。
因此在早期的计算机中,实现严格意义上的并行只能采取增加计算机数量的方法。在这种情况下,Task-Level Parallelism和Instruction-Level Parallelism几乎没有区别。
想要在这种计算机上同时运行多道程序,历史上采用的技术就是--多任务。
(这里说句题外话,如果大家看过早起计算机如何编写指令,如何输入指令,如何输出--简单来说,就是从搬纸带到搬磁带的进化,那么看gopher的那些关于并行并发的图会好理解很多。这些图简直就是在向当时的搬砖工,啊不对计算机先驱们致敬啊。)
这里需要介绍一下为什么会有多任务。正如我们知道的,程序从大致可以分为计算密集型和IO密集型两个极端,而商业程序大多比较偏向IO密集型,所以早期的计算机在很有限的计算资源下,就已经出现了IO和计算能力不匹配的问题,即在IO上花的时间要远远大于计算的时间。当然这个问题当时并没有导致并发方案的出现,而是导致了一种硬件的并行--比如IBM 1401这样的数据处理专用机的出现。当然之后在第三代计算机中出现了SPOOLing技术就不再需要这样的机器了。
回到多任务上来。IO操作耗时较长,也并不需要占用CPU,但这时候CPU即使没有在执行指令却也必须等待输入完毕,导致了CPU的空闲。在那个年代,计算资源大多是按时间售卖的,这种空闲是一种极大的浪费。那么我们为什么不能让CPU在等待IO的这段时间里也去执行指令呢?这就很自然的引出了多任务(Multitasking)的概念了。这个概念的理念很好理解,即当一个程序进行IO或者其他耗时却不占用CPU的操作时,将这个程序切换出去,去执行另一个程序的指令。之后等之前的程序IO完毕了,再切换回来继续执行,以此防止计算资源的浪费。这种切换即上下文切换(context switch)。
事实上,这就是一种并发了。在那个时代的计算机上,因为计算资源的限制很可能导致单个任务的完成时间明显大于预期,导致并发带来的"并行感"还不是太强烈。但是在现代计算机上,这很容易造成一种两个任务同时执行的错觉。
因此我们可以很容易的看出,这里的并发本质上是一种多个操作者对于计算资源的共享使用,它的目的是达到减少的资源闲置导致的浪费--因此,自然会涉及到计算资源如何分配等问题,这就引申出调度和锁等概念。事实上,如果将“计算”两字去掉,这个描述就可以扩展到计算机中任何对于资源的共享使用,包括了各种层级的方方面面,比如在中文件,内存页面中,进程线程中等。
当然,以上的并发是从一种常见的实现的角度来描述的。正如博主所说,我们可以用真正的并行来实现并发,比如在双核CPU上每个核里跑一个独立的进程。我们也可以在一个单核的CPU上通过程序调度来实现这两个进程的并发。
而严格意义上的并行,在指令水平,必然只能指同一时刻有多于一条指令处于执行阶段,因此就必须得“We move into a multicore world”才行。。即使例子中的pipelining,对于单核的CPU也并非实现并行,而只是让每个时刻,IF, ID, EX, MA, WB这五个步骤对应的回路单元都不会闲置而已--事实上这个理念就是并发了,正如博主所说的“并发设计往往需要把流程拆开,是因为如果不拆分也就不可能在同一时间段进行多个任务了。这种拆分可以是平行的拆分,比如抽象成同类的任务,也可以是不平行的,比如分为多个步骤。”--因此,并发并不仅限于程序设计的
Task-Level上,它是关于资源共享和使用问题的解决方法的一种抽象。
-
laike9m Mod 鸡翅 • 3 months ago
把加法看成多个任务的话,也可以说有并发了。所以其实本质在于站在哪个层次来看。
-
鸡翅 laike9m • 3 months ago
非常对,把加法这个任务分成多个子任务就可以视作并发了。其实主要还是因为这两个词都有狭义和广义的解释的原因。如果从广义上来说,并行必然是并发,因为广义的并发的高度抽象定义可以说是,多个问题或者问题的几个部分在一个重叠的时间段内被解决。
不过个人还是喜欢用并发来表示通过调度器以及上下文切换等实现的多任务或者其他类似的技术和手段(其实是不知道用什么词代替好),用并行来表示严格的物理上的并行。
来源:https://www.cnblogs.com/mysic/p/5633860.html