1.分析网址结构

由上可知小说的网址。然后分析章节的地址。
分析文本具体位置
2.代码实现
# 用于获取网页的html
from urllib import request
# 用于解析html
from bs4 import BeautifulSoup
import re
# 得到网页的html
def getHtml(url):
url = url
res = request.urlopen(url)
res = res.read().decode()
# print(res)
return res
# 解析小说章节页面,获取所有章节的子链接
def jsoupUrl(html):
# 获取soup对象
url_xiaoshuo = BeautifulSoup(html)
# 因为我们要拿取class为box1中的div
class_dict = {'target': '_blank'}
url_xiaoshuo = url_xiaoshuo.find_all('a',attrs=class_dict)
# 因为分析html中的代码可以发现div的class为box1的有两个,通过上面的代码返回的是一个list格式的结果,所以下面的索引应该是1
# 我们要获取li中的值,所以find_all,这个方法返回的是一个list集合
# url_xiaoshuo = url_xiaoshuo[0].attrs['href']
# print(url_xiaoshuo)
# 创建一个集合,用于存放每个章节的链接
url_xs = []
for item in url_xiaoshuo:
# print(type(item['href']))
# 获取每个元素中的href值
if '/chapter/' in item['href']:
url = 'https://www.17k.com'+item['href']
# 将值传入url_xs集合中
url_xs.append(url)
# print(url_xs)
return url_xs
# 解析小说每个章节的的主要内容
def jsoupXiaoshuo(list):
for item in list:
html = getHtml(item)
html = BeautifulSoup(html)
# 获取小说标题
title = html.h1.get_text()
xiaoshuo = html.find_all(attrs={'class':'p'})
for item in xiaoshuo:
str1 = item.get_text()
# # open中的第二个参数是让每一次的字符串接连到上一个字符串,千万不能是w
with open('./大国制作/'+title + '.txt', 'a',encoding='utf8') as f:
f.write(str1+'\n')
f.flush()
if __name__ == '__main__':
html = getHtml("https://www.17k.com/list/3051803.html")
url_xs = jsoupUrl(html)
jsoupXiaoshuo(url_xs)
3.结果显示
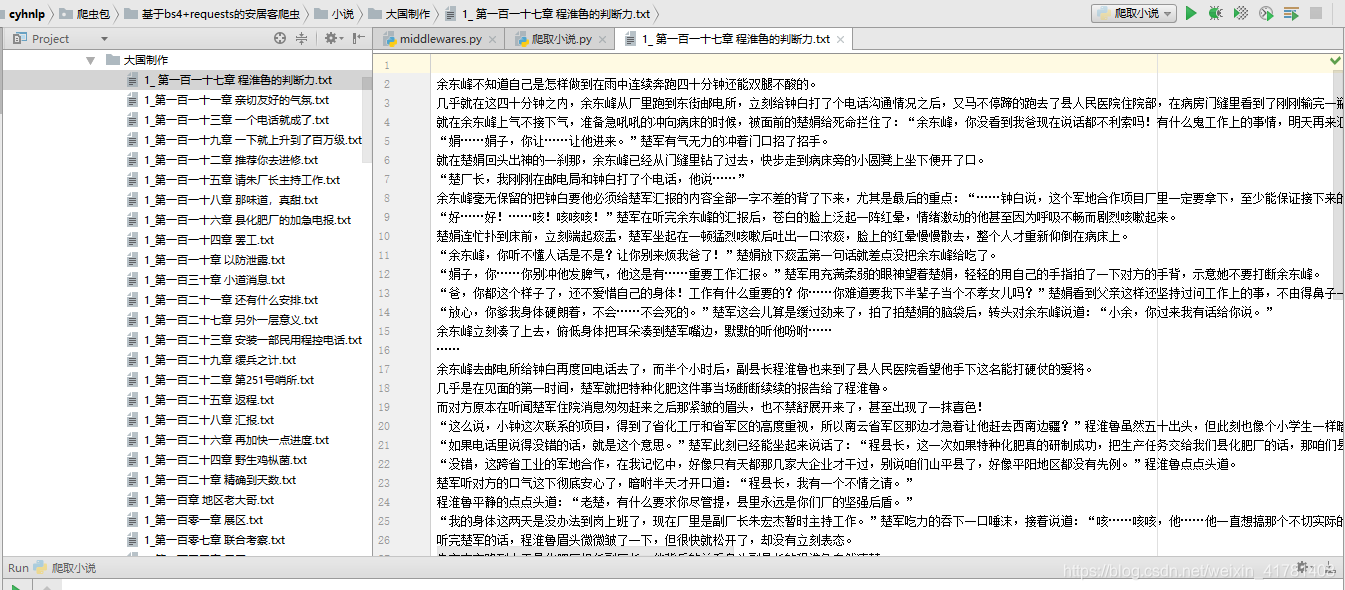
来源:CSDN
作者:dayday学习
链接:https://blog.csdn.net/weixin_41781408/article/details/103791531