堆的介绍
Q: 什么是堆?
A: 这里的“堆”是指一种特殊的二叉树,不要和Java、C/C++等编程语言里的“堆”混淆,后者指的是程序员用new能得到的计算机内存的可用部分
A: 堆是有如下特点的二叉树:
1) 是一棵完全二叉树
2) 通常由数组实现。前面介绍了如何用数组表示树
3) 堆中的每个节点都满足堆的条件,即每个节点的关键字都大于(或等于)这个节点的子节点关键字
下图显示了堆与实现它的数组之间的关系: 
A: 堆是完全二叉树的事实说明了表示堆的数组中没有“洞”,从下标0到N-1,每个元素都有数据项
A: 本篇中假设最大的关键字在根节点,基于这种堆的优先级是降序的优先级队列
A: 若数组中节点的索引为i,则
1) 它的父节点的下标为(i - 1) / 2;
2) 它的左子节点的下标为 2 * i + 1;
3) 它的右子节点的下标为 2 * i + 2
Q: 弱序?
A: 堆相对于二叉搜索树比较而言是弱序的,在二叉搜索树中所有的节点的左子孙的关键字都小于右子孙的关键字。二叉搜索树可以通过简单的算法就可以按序遍历节点,但在堆中,按序遍历节点是困难的,这是因为堆的组织规则比二叉搜索树的组织规则弱。
A: 对堆来说,只要求沿着从根到叶子的每一条路径,节点都是按降序排列
A: 在堆中不能便利地查找指定的关键字,因为在查找过程中,没有足够的信息来决定选择通过节点的哪一个子节点走向下一层。同理它也不能在少至O(logN)的时间内删除一个指定关键字的节点,只能以较慢的O(N)时间去执行。
A: 堆的这种组织似乎非常接近无序。不过堆支持快速移除最大节点和快速插入新节点的操作,这两个操作恰好是优先级队列所需的全部操作
Q: 移除关键字最大节点?
A: 就是移除根节点,根在数组的索引总是0。
maxNode = array[0];
A: 一旦移除了根节点,树就不再是完全的了
A: 数组里就有了一个空的数据元素,这个“洞”必须要填上,可以把数组中所有数据项都向前移动一个单元,但是还有一个更好的方法
A: 这个方法的步骤是:
1) 移除根后,把最后一个节点移动到根的位置
array[0] = array[n - 1]; n--
2) 一直向下筛选这个节点,直到放在堆的合适位置为止
A: 步骤1恢复了对的完全性的特征(没有洞),而步骤2恢复了堆的条件(每个节点都大于的它子节点而小于它的父节点),移除过程如下图: 
在被筛选目标节点的每个暂时停留的位置上,向下筛选的算法都要检查哪一个子节点更大,然后目标节点和较大的子节点交换位置。想一想为什么要这样做。
A: 如果把目标节点和较小的子节点交换,那么这个子节点就会变成大子节点的父节点,这就违背了堆的条件
Q: 插入新节点?
A: 新节点插入到数组最后第一个空着的元素
array[n] = newNode; n++
如果插入的新节点大于它的父节点,就会破坏了堆的条件
A: 因此需要向上筛选这个节点,直到它放到堆中合适的位置。插入过程如下图: 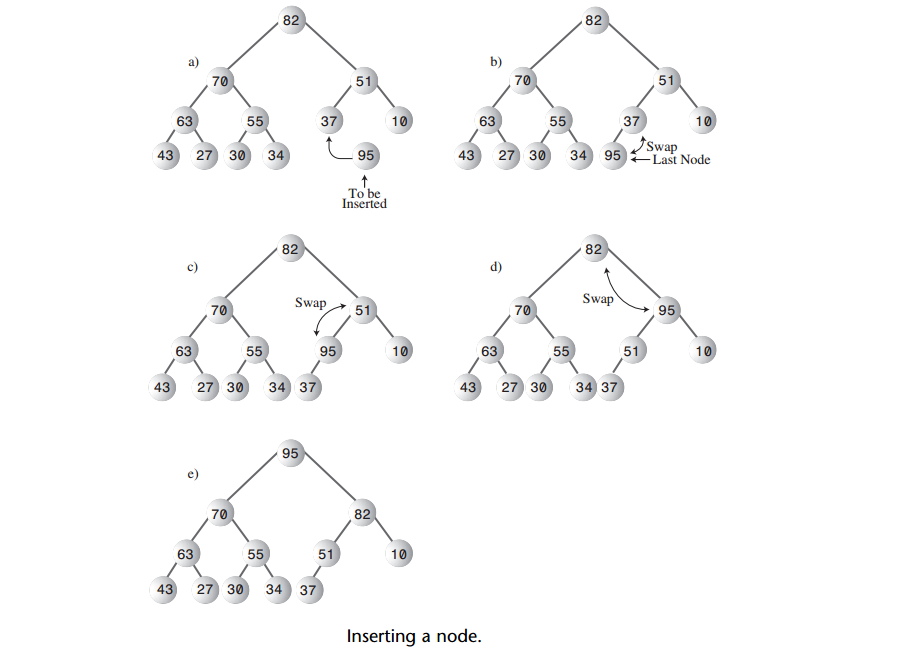
向上筛选的算法比向下筛选的算法相对简单,节点只有一个父节点,目标节点只要和它的父节点交换位置即可
A: 比较上面两张图,发现如果先移除一个节点在插入相同的一个节点,结果并不一定是恢复为原来的堆。一组给定的节点可以组成很多合法的堆,这取决于节点插入的顺序
Q: 换位的时候不是真的交换?
A: 我们知道一次swap需要三次复制,因此下图a)中3次交换就需要9次复制,当层数越大时,复制的时间将会越多。 
A: 可以使用复制的方案来取代交换方案,可以减少所需的复制总数。如b)所示,复制次数只有5次,首先暂时保存节点A,然后B覆盖A,C覆盖B,D覆盖C,最后,在从临时存储中取出A覆盖到D,这样就把复制的次数从9次减少到5次
堆的Java代码
Q: insert?
A: 首先要检查一下数组是否已满;
然后用参数传递的关键字值创建一个新的节点,把这个节点插入到数组的末端;
最后调用trickleUp()把这个节点向上移动到适当的位置。
Q: remove?
A: 首先保存根节点,把最后一个节点(下标为mSize - 1)放到根的位置上,然后调用trickleDown()把这个根节点放到适当的位置。
Q: change?
A: 有了trickleDown()和trickleUp()方法之后,很容易实现改变节点的优先级算法,先更改节点关键字的值,然后再把节点向上或者向下移动到适当的位置。
Q: 堆操作的效率?
A: 对于有足够多数据项的堆来说,向上筛选和向下筛选算法是最费时的部分,这两个算法的时间都花费在一个循环中,沿着一条路径重复地向上或者向下移动节点,所需要的复制次数和堆的高度有关。
A: trickleUp()方法在它的循环里只有一个主要的操作:比较新插入节点的关键字和当前位置节点的关键字。
A: trickleDown()方法需要两次比较:一次找到最大的子节点,一次比较这个最大的子节点和临时节点。
A: 它们必须都要从顶层到底层或者从底层到顶层复制节点来完成操作。堆是一种特殊的二叉树,二叉树的层数L等于log2(N+1),其中N为节点数。trickleUp()和trickDown()中的循环执行了L-1次,所以trickleUp()执行的时间和Log2N成正比,trickleDown()执行时间略长一点,因为它需要执行额外的比较。
A: 总之,堆操作的时间复杂度是O(logN)
基于树的堆
Q: 实现原理?
A: 前面的Java代码实现堆是基于数组的,不过也可以基于真正的树来实现。
A: 这棵树可以是二叉树,但不会是二叉搜索树。不过因为满足堆的条件,必须是一棵满二叉树,没有空缺的结点,因此也可以称这样的树为树堆(tree heap)
A: 可以用二进制码来表示从根到叶子的路径,用二进制数字指示从每个父节点到它子节点的路径:0表示左子节点,1表示右子节点
A: 假设树中有29个节点,根的编号为1,现在想要查找最后一个节点,十进制29转化为二进制是11101。移除开始的1,保留1101。下图就是从根到编号为29的结点的路径:向右,向右,向左,向右 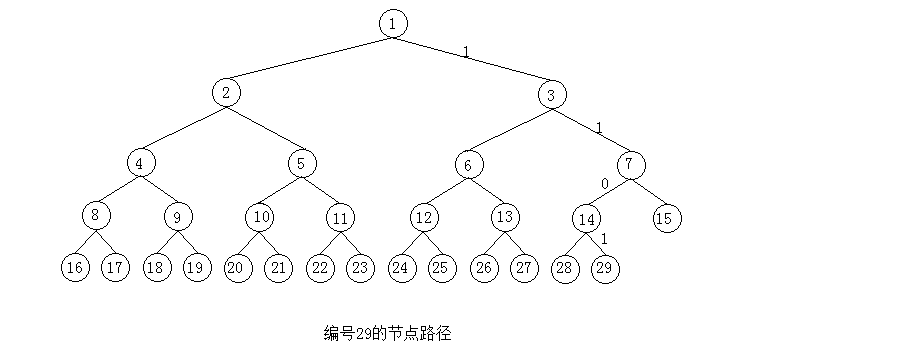
A: 为了执行这个运算,可以重复使用%操作符求出节点n被2整除后的余数,并再用/操作符执行真正的整除。当n小于1时,操作完成,所得的余数序列,可以保存在一个数组或者字符串中,这就是二进制码字。也可以使用递归的方法来实现。
while(n >= 1) {
array[i++] = n % 2;
n = n / 2;
}
堆排序?
Q: 基本思想?
A: 堆排序(英语:Heapsort)是指利用堆这种数据结构所设计的一种排序算法
A: 首先使用普通的insert()在堆中插入全部无序的数据项,然后重复用remove(),就可以按序移除所有数据项.
示例: HeapTestCase.testHeapSort2()
A: 因为insert()和remove()方法操作的时间复杂度都是O(logN),并且每个方法都必须执行N次,所以整个排序操作需要O(N*logN),这和快排一样。但是它不如快排快,部分原因是trickDown()里while循环的操作比快排里循环的操作要多。
Q: 向下筛选到适当的位置((Trickling Down in Place)?
A: 有一个更妙的技巧,可以使堆排序更有效,其一是节省时间,其二是节省内存。
A: 由两个正确的子堆形成一个正确的堆
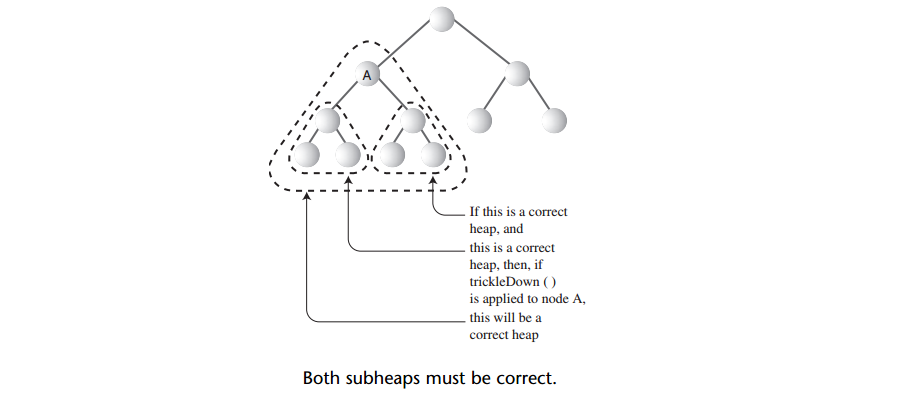
如上图,假设A节点作为两个堆的根,此时A不满足堆的条件,这个时候对A进行trickleDown()一次, 又变成一个堆了。
A: 这就提出了一个把无序的数组变成堆的方法,从数组末端的节点开始,然后上行直到根的各个节点都调用trickleDown,在每一步调用方法时,该节点下面的子堆都是正确的堆(因为已经对它们调用了trickleDown()方法),然后在对根调用trickleDown()之后,无序的数组就转化为堆了。
A: 不过,注意在最后一行的节点,由于没有子节点,它们本身已经是正确的堆了(因为它们是单节点的树,没有违背堆的条件,因此不用对这些节点调用trickleDown()方法)。可以从节点N/2 - 1开始,即最右边一个有子节点的节点,这样筛选操作只需执行N/2次insert()方法就够了。
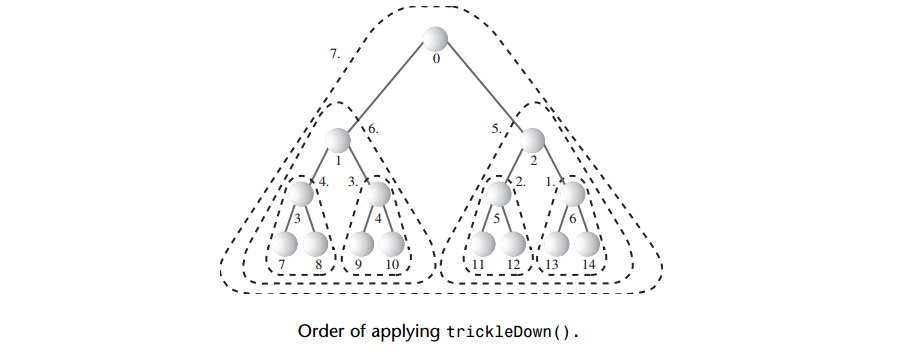
如上图显示了使用向下筛选的算法的次序:堆中一共有15个结点,从节点6开始筛选。
Q: 使用同一个数组?
A: 原始代码片段显示了数组中的无序数据,然后把数据插入到堆中,最后从堆中移除它并把它有序地写回数组,这个过程需要两个大小为N的数组:初始数组和用于堆的数组。
A: 事实上,堆和初始数组可以使用同一个数组,这样推排序所需要的存储空间减少了一半。
A: 每从堆顶移除一个数据项,堆数组的末端单元就变成空的;堆减少一个节点,可以把最近一次移除的节点放到这个新空出的单元中。因此,有序数组和堆数组就可以共同使用一块存储空间。如下图 
A: 示例:HeapSort,注意这次增加的方法没有依照面向对象编程的思想(Heap类接口应该对类用户屏蔽掉堆内部的实现),这里允许违背OOP的原则是因为数组和堆结构的联系太紧密了。
Q: 堆排序的效率?
A: 前面已经讲过,堆排序运行的时间复杂度为O(NlogN)。尽管它比快排略慢,但是它比快速排序优越的一点是它对初始数据的分布不敏感。比如,快排的时间复杂度可以降到O(N2)级,然而堆排序对任意排列的数据,都是O(NlogN)。
小结
- 在一个升序优先级队列中,最大关键字的数据项被称为有最高的优先级,反之在降序优先级队列中优先级最高的是最小的数据项
- 优先级队列是提供了数据插入和移除最大(或者最小)数据项方法的抽象数据类型(ADT)
- 堆是优先级队列ADT的有效实现方式
- 堆提供移除最大数据项和插入的方法,时间复杂度为O(logN)
- 最大数据项总是在根的位置上
- 堆不能有序地遍历所有的数据,不能找到特定关键字数据项的位置,也不能移除特定关键字的数据项
- 堆通常用数组来实现,表现为一棵完全二叉树,根节点的下标为0,最后一个节点的下标为N-1
- 每个节点的关键字都小于它的父节点,大于它的子节点
- 要插入的数据项总是先被存放到数组第一个空的单元中,然后再向上筛选它至适当的位置
- 当从根移除一个数据项时,用数组中最后一个数据项取代它的位置,然后再向下筛选这个结点到适当的位置
- 向上筛选和向下筛选算法可以被看作是一系列的交换,但更有效的做法是进行一系列的复制
- 可以更改任一个数据项的优先级。首先,更改它的关键字。如果关键字增加了,数据项就向上筛选;而如果关键字减少了,数据项就向下筛选。
- 堆的实现可以基于二叉树(不是搜索树),它映射堆的结构,称为树堆。
- 堆排序是一种高效的排序过程,它的时间复杂度为O(N*logN)
- 在概念上堆排序的过程包括先在堆中插入N次,然后再做N次移除
- 通过堆无序数组中的N/2个数据项施用向下筛选算法,而不作N次插入,可以使堆排序的运行速度更快
- 可以使用同一个数组来存放初始无序的数据、堆以及最后有序的数据,因此堆排序不需要额外的存储空间
参考
1.《Java数据结构和算法》Robert Lafore 著,第12章 - 堆
来源:https://www.cnblogs.com/fireway/p/10068892.html