课程网站:https://classroom.udacity.com/courses/ud170
目录
学习内容
*Python数据分析
1.数据读取
2.数据修正(数值和日期格式的转化)
3.数据探索(熟悉数据内容,提出问题)
4.问题处理(异常值、特殊值和特定数据提取)
5.数据可视化(关键数据可视化图表呈现)*Numpy和Pandas处理一维数据
待学习*Numpy和Pandas处理二维数据
待学习
学习感受
课程篇
Udacity的课程总是一如既往的详细,均是从基础开始讲起,最重要的是讲解知识时提出许多具有启发性的问题,加上合理的练习设计,学起来总是事半功倍。
内容篇
第一部分内容比较基础,重点在于对列表、字典和元组的理解和使用。主要通过合理的建立字典和列表,将我们感兴趣的数据放入,而将不感兴趣和异常值去除。
而这个操作一般都是:建立字典——for循环——if条件选择——输出目标值到新字典。
内容的重点在于:熟悉数据内容,提出能从数据中获得的有趣问题,以何种思路去回答问题,以及如何根据问题获得有价值的信息。
总结回顾
按照学习内容依次总结:
1.读取csv文件:
# 用到特殊库文件unicodecsv
import unicodecsv
def read_csv(file):
with open(file, 'rb') as f:
reader = unicodecsv.DictReader(f)
return list(reader)读取csv格式文件,并返回列表。
2.数据修正
from datetime import datetime as dt
# 将字符串格式的时间转为 Python datetime 类型的时间。
# 如果没有时间字符串传入,返回 None
def parse_date(date):
if date == '':
return None
else:
return dt.strptime(date, '%Y-%m-%d')
# 将可能是空字符串或字符串类型的数据转为 整型 或 None。
def parse_maybe_int(i):
if i == '':
return None
else:
return int(i)
# 清理文件表格中的数据类型其中涉及到日期修改,用到datetime库的strptime函数,在使用时格式为dt.strptime(date, “%Y-%m-%d”)。当然其输出格式可以多种选择,可以自行搜索文档查看格式。
数据类型转换可以直接强制转换为对应类型:int(i),其中有部分数据需要将尾数去掉,如课程完成值为1.5,需要转化为1,可利用如下代码:
b = int(float(a))3.数据探索
提供数据为:
enrollments(第一个项目完成情况(内含学员账号、加入时间、取消时间等))
daily-engagement(每天学习情况(内含学员账号、浏览课程时间、完成课程总数和完成项目总数))
project-submissions(提交项目情况(内含提交项目日期、项目状态等))
提问:
学员花费在课程上时间与学员提交项目关系?(求得数据中学员花费在课程上的总时间)
# 导入 defaultdict ,可输出空列表
from collections import defaultdict
# 定义在数据 data 中寻找特定项 value 的函数
def find_special_value(value, data):
engagement_by_account = defaultdict(list)
# 在数据中提取 “account_key”,并将对应数据传递给 “engagement_by_account”, 形成字典 “engagement_by_account”
for data_point in data:
account_key = data_point["account_key"]
engagement_by_account[account_key].append(data_point)
# 创建空字典,储存结果
total_by_account = {}
# 字典 “engagement_by_account” 用两次for循环查找数据中对应 "value" 项,并将其累加,存入字典 “total_by_account”中,注意其中的 "items"
for account_key, engagement_by_student in engagement_by_account.items():
total = 0
for engagement_record in engagement_by_student:
total += engagement_record[value]
total_by_account[account_key] = total
# 提取字典中 “value” 值并存入元组 "total_value" 中
total_value = total_by_account.values()
学员完成课程数与学员完成项目数关系?
# 访问次数道理与求累计学习时间相同,将value值改为 "num_courses_visited"即可学员访问课程教室天数与项目完成关系?
def find_lessons_value(value, data):
engagement_by_account = defaultdict(list)
for engagement_record in data:
account_key = engagement_record["account_key"]
engagement_by_account[account_key].append(engagement_record)
total_by_account = {}
for account_key, engagement_by_student in engagement_by_account.items():
total = 0
for engagement_record in engagement_by_student:
# 特别之处在于,访问天数的计算:只能是每天为1或者0,即如果当天有访问次数记录,只记为1次;没有记录,记为0次!
if engagement_record[value]:
total += 1
total_by_account[account_key] = total
total_value = total_by_account.values()4.问题处理
异常值、特殊值和特定数据提取
数据集daily-engagement中键值问题“acct”:
# 将 "acct" 对应内容 Value 赋值给 "account_key" , 删除 "acct"
def engagement in daily-engagement:
engagement["account_key"] = engagement["acct"]
del engagement["acct"]数据集中出现重复注册问题:
# 通过 “account_key” 的唯一账号,剔除重复用户
def get_unique_student(data):
unique_student = set()
for data_point in data:
unique_student.add(data_point["account_key"])
return unique_student官方测试账号异常问题:
# 为所有 Udacity 测试帐号建立一组 set
udacity_test_accounts = set()
for enrollment in enrollments:
if enrollment['is_udacity']:
udacity_test_accounts.add(enrollment['account_key'])
# 通过 "account_key" 找到不是官方测试账号的数据存入 non_udacity_account 中
def remove_udacity_accounts(data):
non_udacity_data = []
for data_point in data:
if data_point["account_key"] not in udacity_accounts:
non_udacity_data.append(data_point)
return non_udacity_data5.数据可视化
得到对应结果后,可通过强大、神奇的numpy来处理,比如:
import numpy
total_value = total_by_account.values()
print "mean:", np.mean(total_value)
print "standard Deviation", np.std(total_value)
print "Minium", np.min(total_value)
print "Maxium", np.max(total_value)最后再将结果可视化,比如最基本的直方图:
# 关键数据可视化图表呈现
def describe_data(data):
print 'Mean:', np.mean(data)
print 'Standard deviation:', np.std(data)
print 'Minimum:', np.min(data)
print 'Maximum:', np.max(data)
plt.hist(data)可以非常直观的看到提出数据分布!!! 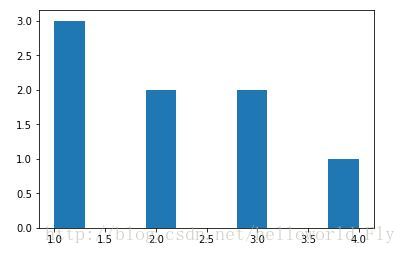
学习原因及计划
原因
数据分析与处理是进行深度学习必不可少的一门学科,在对大型、复杂数据进行处理时,不仅仅需要熟练的编程技巧,更需要扎实的理论和丰富的经验来分析和理解数据的特性,并根据其特性来进行合适的模型选择。学习完Udacity的深度学习纳米课程已经两个多月了,但在实战项目中,发现对数据的预处理不足,会导致模型的训练效果大打折扣,且Python的基础不扎实,需要一段时间的磨练,决定花一周的时间学习数据分析入门和用 MongoDB 进行数据整理课程,打基础同时锻炼编程能力,更深入的理解编程思想。
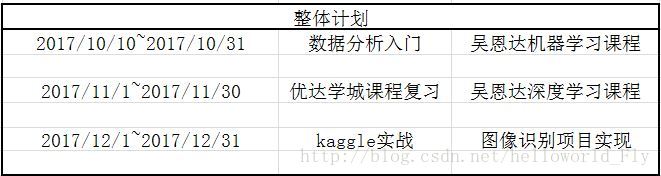
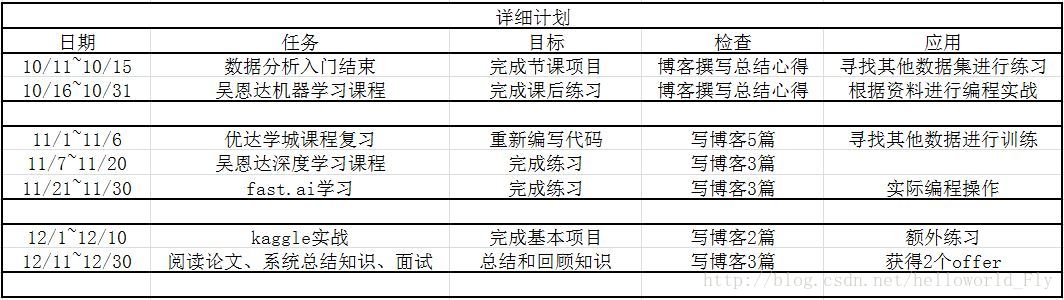
计划

写在最后的最后,希望我能坚持到底,享受这个过程,成为更好的自己,得到nice的结果!
来源:CSDN
作者:helloworld_Fly
链接:https://blog.csdn.net/helloworld_Fly/article/details/78208072