文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: 朱小五 凹凸玩数据
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
王思聪又又又上了微博热搜——然而这次却不是关于娱乐圈。
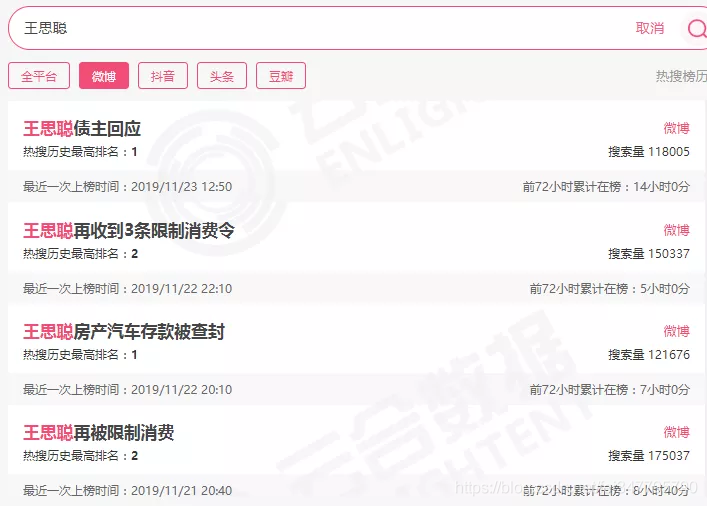
最近几天,王思聪与他的“限消令”接连登上热搜榜,引发吃瓜群众们广泛热议。
知乎的段子手们也纷纷发挥自己的想象力。

小五本来想看看王思聪的微博,结果发现他的微博早已做了隐藏。
那么我们不妨干脆转换一下思路,从微博热搜看看“娱乐圈纪检委”——王校长的热搜往事。
获取数据
【热搜神器】网站,统计了历史的微博热搜记录。
打开官网,F12,Network查看异步请求XHR。
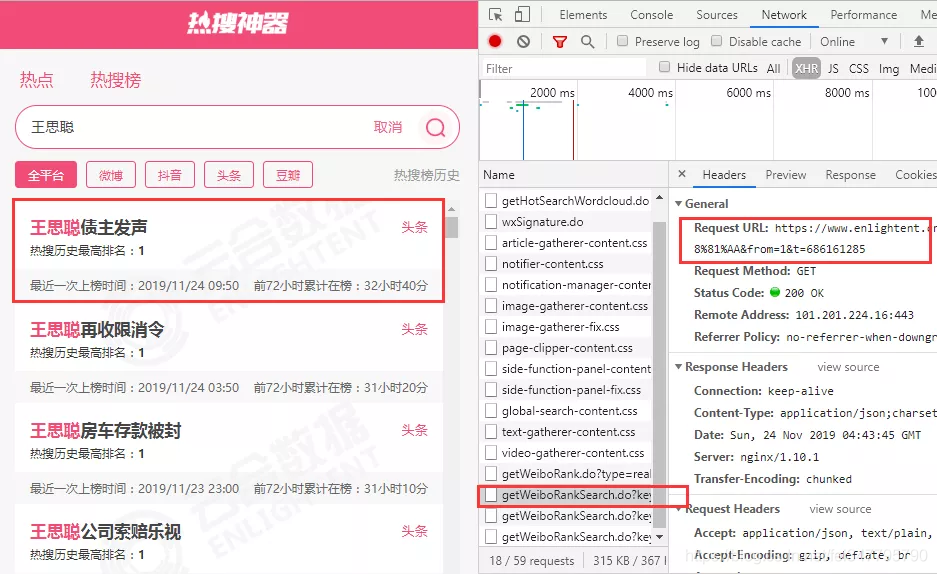
成功找到返回json格式数据的url。
利用requests爬取数据
1 resou = pd.DataFrame(columns=['datetime','title','searchCount'])
2
3 for i in range(1,20):
4 url= 'https://www.enlightent.cn/research/top/getWeiboRankSearch.do?keyword=王思聪&from='+ str(i) +'&t=395201742&type=realTimeHotSearchList'
5 html = requests.get(url=url, cookies=cookie, headers=header).content
6 data = json.loads(html.decode('utf-8'))
7 for j in range(20): #一页20个
8 resou = resou.append({'datetime':stampToTime(data['rows'][j]['updateTime']),
9 'title':data['rows'][j]['keywords'],'searchCount':data['rows'][j]['searchNums'],
10 },ignore_index=True)
11
12 resou.to_csv("resou.csv", index_label="index_label",encoding='utf-8-sig')
成功获取王思聪2017年5月-至今的所有微博热搜数据,共208条。
也就是说在这923天中,王思聪共上了208次热搜!!!平均4.4天就上一次热搜!!!
数说2017热搜往事
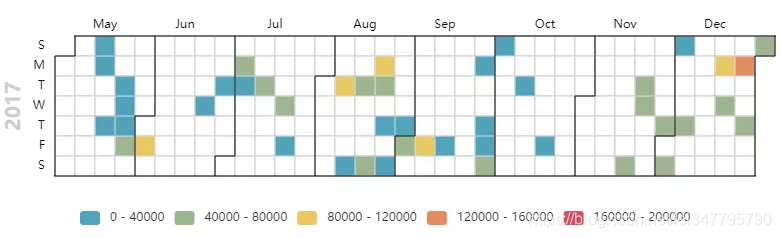
首先,小五利用pyecharts生成思聪在2017年上热搜的日历热度图。
1 calendar = (
2 Calendar(init_opts=opts.InitOpts(width='1800px',height='1500px'))
3 .add("", data,calendar_opts=opts.CalendarOpts(range_=['2017-05-01', '2017-12-31']))
4 .set_global_opts(
5 title_opts=opts.TitleOpts(title="思聪2017年热搜",pos_left='15%'),
6 visualmap_opts=opts.VisualMapOpts(
7 max_=200000,min_=0,orient="horizontal",is_piecewise=True,pos_top="230px",pos_left="100px",pos_right="10px"))
8 .render('2017日期热力图.html'))
同时,也用wordcloud将这些热搜的标题做成了词云。


2017年,风头正盛的王思聪最受关注的就是他传了一轮又一轮的绯闻女友,豆得儿、雪梨、慎婕……和看不惯谁就发声的张扬姿态,怼柯洁、怼陈欧、怼华大基因CEO……
一方面王思聪的微博下面每天都会有大量的男性和女性粉丝留言叫其老公,因此获得了“国民老公”的称号;另一方面,因为他经常今天diss这个娱乐圈明星、明天怼那个,获得了“娱乐圈纪检委”的称号。
哦对了,王思聪和周鸿祎朋友圈对话中,著名的“私人飞机”梗也是在这一年流传开来。
数说2018热搜往事
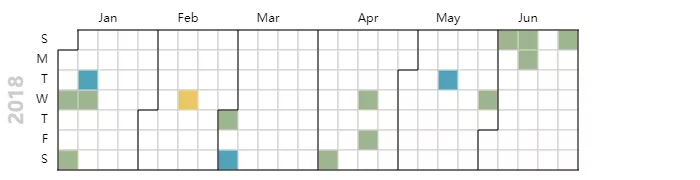


到了2018年,王思聪的电竞事业红红火火地搞了起来,不仅旗下战队 IG 夺得LOL S8全球总决赛,老板王思聪也体验了一把职业选手。
在IG决赛的现场,王思聪吃热狗的动作被做成表情包传遍全网,成为“漫画家”们练手的素材。
后续接连的抽奖也是噱头十足,先是简单粗暴的一万块,再是“抽手机壳送手机”这样的段子走进现实,当然还一不小心揭露了微博抽奖的“潜规则”。
2018年,王思聪有钱任性人设不崩,一个点赞或者取关都能轻松上热搜。
数说2019(上)热搜往事
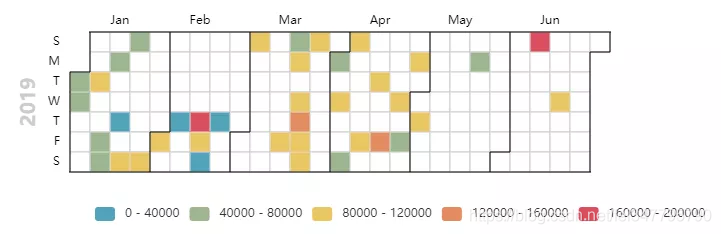

2019年上半年,王思聪坚持不懈的怼天怼地,diss吴秀波、diss大张伟。
2019年3月8日,是王思聪微博停更的第48天,他一手缔造的熊猫直播宣布破产。但那时,熊猫直播的破产还没有对他产生影响,王思聪还是那个“创业失败就只能回家继承千亿家产”的富二代。
同时,“吃热狗”、“吃玉米”梗的持续发酵、与李易峰的“捏脸杀”、与周洁琼的同游绯闻,他的热度从电竞圈到娱乐圈也算一波接一波,没有长期间断过。
数说2019(下)热搜往事
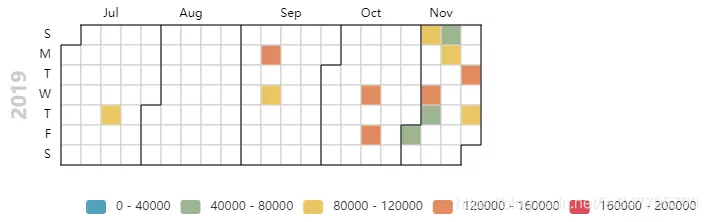

但到了2019年下半年,王思聪的热度肉眼可见的下降,大家对有钱任性的人设早已不再追捧,他本人也低调了许多。不仅本人数月来一直隐身,连历史微博也隐藏了起来。
等到他再上热搜的时候,关键词已经变成了冷冰冰的“限制”、“冻结”、“债主”、“查封”……
完整代码
1 import json
2 import requests
3 import time
4 import pandas as pd
5
6
7 ## 设置headers和cookie,数据爬取
8 header = '设置自己的header'
9 cookie = '设置自己的cookie'
10
11 def stampToTime(stamp): #时间转换
12 datatime = time.strftime("%Y-%m-%d",time.localtime(float(str(stamp)[0:10])))
13 return datatime
14
15 resou = pd.DataFrame(columns=['datetime','title','searchCount'])
16
17 for i in range(1,20):
18 url= 'https://www.enlightent.cn/research/top/getWeiboRankSearch.do?keyword=王思聪&from='+ str(i) +'&t=395201742&type=realTimeHotSearchList'
19 html = requests.get(url=url, cookies=cookie, headers=header).content
20 data = json.loads(html.decode('utf-8'))
21 for j in range(20): #一页20个
22 resou = resou.append({'datetime':stampToTime(data['rows'][j]['updateTime']),
23 'title':data['rows'][j]['keywords'],'searchCount':data['rows'][j]['searchNums'],
24 },ignore_index=True)
25
26 resou.to_csv("resou.csv", index_label="index_label",encoding='utf-8-sig')
27
28
29
30 resou_dt = resou.groupby('datetime',as_index=False).agg({'searchCount':['mean']})
31 resou_dt.columns = ['date','avg_count']
32
33 ## 绘制日历图
34 from pyecharts import options as opts
35 from pyecharts import Calendar
36 data = [
37 [resou_dt['date'][i], resou_dt['avg_count'][i]]
38 for i in range(resou_dt.shape[0])
39 ]
40
41 calendar = (
42 Calendar(init_opts=opts.InitOpts(width='1800px',height='1500px'))
43 .add("", data,calendar_opts=opts.CalendarOpts(range_=['2019-01-01', '2019-07-12']))
44 .set_global_opts(
45 title_opts=opts.TitleOpts(title="2019每日热搜平均指数",pos_left='15%'),
46 visualmap_opts=opts.VisualMapOpts(
47 max_=3600000,
48 min_=0,
49 orient="horizontal",
50 is_piecewise=False,
51 pos_top="230px",
52 pos_left="100px",
53 pos_right="10px"
54 )
55 )
56 .render('日期热力图.html')
57 )