前言
Docker由于使用了基于namespace和cgroup的技术,因此监控docker容器和监控宿主机在某些性能指标和方式上有一些区别,而传统的监控方式可能无法满足docker容器内部的指标监控,本篇系列文章主要分享使用telegraf+influxdb+grafana去监控docker容器内部资源使用情况。目前主要关注的监控指标为:每个宿主机上的docker容器数量,每个docker容器的内存使用情况,CPU使用情况,网络使用情况以及磁盘使用情况。同时这套方案也能够监控到宿主机的一些基本资源使用情况。
Telegraf简介与实践
简介:
由influxdata公司开发的用于采集系统数据的服务,用纯go编写,通过插件化方式进行采集各种服务(system,docker,redis,nginx,kafka等)监控指标并且上报给相应的中间件,比如influxdb,opentsdb(商城docker监控使用这个)。Telegraf也是整个TICK(telegraf+influxdb+chronograf+kapacitor)生态栈的第一块组件也是最重要的组件。
特点:
纯go编写,不需要依赖其他组件;消耗相关系统资源比较小;plugins支持多种输入输出插件(采集和上报); 相关连接:
github:https://github.com/influxdata/telegraf
官网文档:https://docs.influxdata.com/telegraf/v1.0/
TICK生态栈:https://www.influxdata.com/downloads/#telegraf
安装:
所有的安装以及部署都是在linux下的,所以不知道linux下安装基础软件包的,请自觉绕路!
Centos系列可以配置yum源或者直接下载包,并安装。个人建议直接下载包,由于不需要其他系统依赖,可以直接在集群环境进行共享。
wgethttps://dl.influxdata.com/telegraf/releases/telegraf-1.0.0.x86_64.rpm && rpm -ivh telegraf-1.0.0.x86_64.rpm 其他环境安装指南:
Ubuntu && Debin:
ubuntu repo:
curl -sLhttps://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/lsb-release
echo “deb https://repos.influxdata.com/{DISTRIB_CODENAME} stable” | sudo tee /etc/apt/sources.list.d/influxdb.list
Debin repo:
curl -sLhttps://repos.influxdata.com/influxdb.key | sudo apt-key add -
source /etc/os-release
test $VERSION_ID = “7” && echo “debhttps://repos.influxdata.com/debianwheezy stable” | sudo tee /etc/apt/sources.list.d/influxdb.list
test $VERSION_ID = “8” && echo “debhttps://repos.influxdata.com/debian jessie stable” | sudo tee /etc/apt/sources.list.d/influxdb.list
配置完ubuntu系列的repo之后,就可以执行sudo apt-get update && sudo apt-get install telegraf进行安装了
直接下载deb包方式:
wgethttps://dl.influxdata.com/telegraf/releases/telegraf_1.0.0_amd64.deb&& sudo dpkg -i telegraf_1.0.0_amd64.deb
启动:
telegraf可以支持多种服务管理方式,安装之后默认可用使用service和systemd进行管理,因此在centos6-7中都可以使用系统自带的服务管理进行维护(init.d和systemctl)
/etc/init.d/telegraf start 或者systemctl restart telegraf
配置:
配置可以说是telegraf运用中最核心的一个环节,因为配置的细节决定你采集数据的指标。telegraf的配置可以说是比较千变万化,因为可以支持多种输出、输入组件,并且每种组件的配置支持不通的过滤规则,能够让配置管理和维护者正确的采集自己需要的信息。
默认配置文件存放路径:/etc/telegraf/telegraf.conf ,额外配置路径/etc/telegraf/telegraf.d/。
在生产环境中建议自定生成配置并存放在/etc/telegraf/telegraf.d/中。
自定义生成配置文件:
#telegraf -sample-config > telegraf.conf 这样生成的配置文件将包含每一个插件,但是大部分会被注释掉,可以根据实际的业务场景进行定义
配置文件示例以及详细讲解:
#cat telegraf.conf
########################################全局配置############################################################
#全局tag配置,采用key = "values"方式,这样在本机采集到的所有数据将都有这个标签
[global_tags]
dc = "docker-test"
#agent配置
[agent]
#默认的数据(input)采集间隔时间
interval = "10s"
#采用轮询时间间隔。默认是使用interval里面的值进行轮询,比如interval = "10s",那采集时间将是:00, :10, :20, 等
round_interval = true
#每次发送到output的度量大小不能超过metric_batch_size的值
metric_batch_size = 1000
#telegraf会为每一个output去缓存一份度量值,metric_buffer_limit为缓存的限制,并且刷新buffer以确定成功写入。如果达到这个限制了,老的数据会被第一时间丢弃
#当然了,增加这个值能够容忍更多的数据连接,但是这也将会增加telegraf潜在的内存占用。这个值可以大于metric_batch_size但是必须小于它的两倍
metric_buffer_limit = 10000
#通过随机度量来对采集时间进行抖动。每个插件在采集数据之前将会有一个随机时间的休眠,但是这个时间应小于collection_jitter
#这个设置是为了防止多个采集源数据同一时间都在队列
collection_jitter = "0s"
#默认所有数据flush到outputs的时间(在数据被flush到output之前,最大能到flush_interval + flush_jitter)。不能低于interval
flush_interval = "10s"
# 通过随机数来对flush间隔进行抖动。这个主要是为了避免当运行一个大的telegraf实例的时候有比较大的写入。(jitter=5s,flush_interval=10s意味着每10-15s会发生一次flush操作)
flush_jitter = "0s"
#默认这个值被设置相同的时间戳通过采集间隔排序。最大值为1s。这个指标一般不会用在service input(比如logparser和statsd)。单位(ns,us,ms,s)
precision = ""
#以debug模式运行
debug = false
#以安静模式运行
quiet = false
#这个将会覆盖默认的hostname,如果为空的话,将会采用os.Hostname()
hostname = ""
#如果设置为true,就不允许在telegraf agent里面设置"host"标签了
omit_hostname = false
##############################################度量值过滤#######################################################
#过滤可以被配置在每一个输入和输出值
namepass:一个数组字符串可以被用来过滤由当前input生成的度量值,在数组中的每一个字符串和全局匹配到的测量值名字进行对比,如果匹配了,值被采用
namedrop:pass的反向含义,如果匹配,则不使用
fieldpass:在namepass满足的条件下,output的fieldpass不可用
fielddrop:pass的反向含义,如果field名字匹配,将不被采用。output的fielddrop不可用
tagpass:tag names和数组中的字符串都被用来过滤当前input的值,数组中的每一个每一个字符串和tag name对比,匹配则则采用
tagdrop:tagpass的反向含义,如果tag匹配,该度量值不被采用
tagexclude:被用来从度量值(measurements)中执行一个tag。作为tagdrop的对立面,它将丢弃所有依赖于tag的相关度量值,tagexclude只是单纯的从度量值中给tag一个key
这个可以被用作input和output中,但是强烈建议用在input中,他会在同一个采集时间点更加有效的过滤out tags
taginclude:tagexclude的反向含义。在最终的度量值中,也将包含tag keys
注意:tagpass和tagdrop参数必须等一在plugin函数的底部,不然对应的子plugin配置可能被tagpass/tagdrop映射中的内容截断
#################################################(OUTPUT)输出配置##############################################
#输出插件,我们使用的是influxdb,得先进行安装配置
[[outputs.influxdb]]
## The full HTTP or UDP endpoint URL for your InfluxDB instance.
#如果有多个urls,可以指定为相同集群的一部分。意味着urls中的一个将被写到每一个间隔
# urls = ["udp://localhost:8089"] # UDP endpoint example
urls = ["http://172.25.46.7:8086"] # required
#默认需要连接的telegraf库,没有则自己创建
database = "telegraf" # required
precision = "s"
#修改保留策略
retention_policy = ""
#持续写入,仅支持集群模式, can be: "any", "one", "quorum", "all"
write_consistency = "any"
#作为influxdb客户端,设置写超时时间,如果为空默认为5s超时,0s表示不设置超时时间(不建议)
timeout = "5s"
#设置telegraf的库的用户名和密码
# username = "telegraf"
# password = "metricsmetricsmetricsmetrics"
###############################################(INPUT)输入配置###################################################
inputs插件全局参数:
#每一个input都可以配置的全局配置项
#name_override:覆盖默认的度量值名字(默认是input的名字)
#name_prefix:指定一个前缀并附加到度量值的名字(measuerments name)
#name_suffix:指定后缀
#tags:一个标签映射到指定的input度量值
#interval:多久采集一次数据,默认可用使用全局配置中的参数
配置示例:
[[inputs.cpu]]
#采集每个cpu的指标
percpu = true
#采集总的cpu指标
totalcpu = true
#会丢弃掉time开头的。如果想要采集原始的cpu相关指标,请注释
fielddrop = ["time_*"]
[[inputs.disk]]
#默认的telegraf将手机所有挂载点的信息
#下面这个参数可以指定挂载点
mount_points = ["/"]
#仅存储磁盘inode相关的度量值
fieldpass = ["inodes*"]
#通过文件系统类型来忽略一些挂载点,比如tmpfs
ignore_fs = ["tmpfs", "devtmpfs"]
#仅存储tagpass相关的信息
[inputs.disk.tagpass]
fstype = [ "ext4", "xfs" ]
path = [ "/export", "/home*" ]
#默认telegraf将采集所有存储设备的信息,devices参数可以指定
# devices = ["sda", "sdb"]
#如果需要磁盘的串行号可以将下面注释打开
# skip_serial_number = false
[[inputs.mem]]
#采集docker和redis的插件
[[inputs.docker]]
#指定docker启动的api接口,并指定需要采集那些容器指标
endpoint = "tcp://10.0.0.2:5256"
container_names = []
[[inputs.redis]]
#指定redis的相关接口
servers = ["tcp://10.0.0.1:6379"]
测试插件是否正常工作:
使用以下命令会将telegraf采集的数据默认输出到终端,依次来检验配置的监控项是否是自己所期望的指标。
#telegraf -config /etc/telegraf/telegraf.conf -input-filter docker -test 会输出docker相关的监控信息说明配置正确(当然也可以去测试其他inputs plugins)
注意:上面的配置文件中使用的output plugins是influxdb,因此在没有成功配置influxdb的前提下,此配置文件是不能正常让telegraf正常启动的!下一节将会讲到influxdb的相关知识influxdb相关:
重启服务:
centos6.x:
#/etc/init.d/telegraf restart (service telegraf restart )
centos7.x:
#systemctl restart telegraf
此时,可以查看相关日志,确保telegraf正常启动,启动之后去influxdb就可以查询相关采集到的数据。
附:
telegraf常用的input plugins:
收集docker相关的信息:https://github.com/influxdata/telegraf/tree/master/plugins/inputs/docker主要是通过docker API调用相关监控
收集相关redis的信息:https://github.com/influxdata/telegraf/tree/master/plugins/inputs/redis
收集相关mesos的信息:https://github.com/influxdata/telegraf/tree/master/plugins/inputs/mesos
收集相关nginx的信息:https://github.com/influxdata/telegraf/tree/master/plugins/inputs/nginx
收集相关mysql的信息:https://github.com/influxdata/telegraf/tree/master/plugins/inputs/mysql
收集ping相关信息:https://github.com/influxdata/telegraf/tree/master/plugins/inputs/ping
收集influxdb相关信息:https://github.com/influxdata/telegraf/tree/master/plugins/inputs/influxdb
收集系统相关的信息:https://github.com/influxdata/telegraf/tree/master/plugins/inputs/system
收集haproxy相关信息:https://github.com/influxdata/telegraf/tree/master/plugins/inputs/haproxy
收集cgroup相关信息:https://github.com/influxdata/telegraf/tree/master/plugins/inputs/cgroup
核心plugins 监控指标的采集原理(system,docker)
-
system plugin:主要监控项包含CPU,DISK,KERNEL,KERNEL_VMSTAT,NETSTAT,PROCESS,SYSTEM
CPU中有两个参数,分别为totalcpu和percpu,如果为true经分别采集相关cpu的指标。主要指标有:user,nice,system,idle,iowait,cpu_usage等
DISK:主要指标有free,total;used(单位字节);uesd_percent;inode_free;inode_total;inode_used.需要注意的是,used_percent指标通过使用used/(used+free)计算得出。
MEM:主要指标total;available(/proc/meminfo原生值);available_percent(available / total * 100);used_percent(used / total * 100)
NET:通过lsof采集tcp连接状态和udp相关信息。指标:established syn_sent syn_recv fin_wait1 time_wait close listen closing
PROCESS:收集进程总数个状态组(zombie,sleeping,running),也是通过采集/proc中的数据
SYSTEM:系统负载,load1;load15;load5 -
docker plugin:主要监控项包括ocker_container_mem,docker_container_cpu,docker_container_net,docker_container_nlkio,docker_,docker_data,docker_metadata。基本上是通过docker api进行采集docker容器相关的监控指标的(https://docs.docker.com/engine/reference/api/docker_remote_api_v1.25/#/inspect-a-container)
具体的监控项可以在源码中进行查看:(https://github.com/influxdata/telegraf/blob/master/plugins/inputs/docker/docker.go) -
几个主要关心的指标:
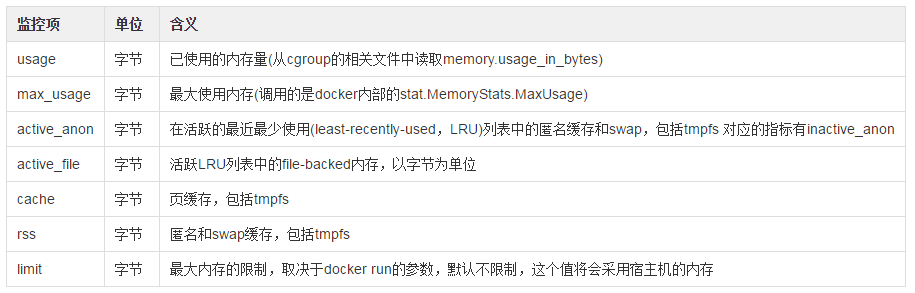
docker_memory:
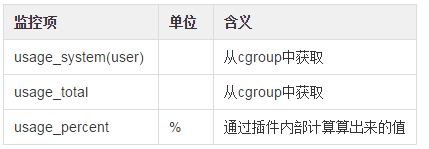
docker_cpu:
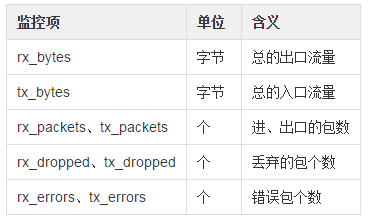
docker_net:
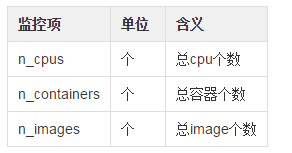
docker相关:
注意:原创著作,转载请联系作者!
来源:oschina
链接:https://my.oschina.net/u/1026229/blog/751330