分类与预测的任务是在数据挖掘中经常完成的任务,那么这带来的一个问题是我们如何对一个分类与预测的模型进行评价那?
评价有很多的方式,你比如说:均方误差法,这应该是误差分析的综合指标的方式之一,这在神经网络是经常用到的.
这里我们主要关注分类或者预测的结果与实际值之间的差距,有一个很重要的模型,是经常用到关于其分类的评价的,即ROC曲线.
ROC曲线在我以前的博客中已经有实现的具体代码,这里要详细展开详细分析.
ROC的模型的构建的基础是混淆矩阵.从混淆矩阵中,混淆矩阵是模式识别领域中一种常用的表达形式,它描绘了样本数据的真实属性与识别结果之间类型的关系。(如果评价结果合理,其对角线上的值总是非常大的)*

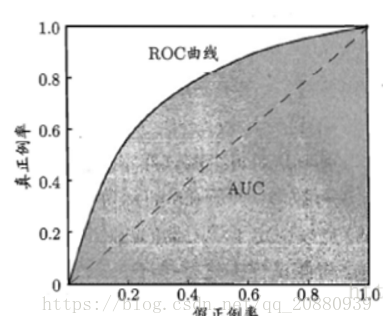
ROC曲线的横轴与纵轴就是基于混淆矩阵而产生。纵轴称为“真正例率(TPR)”,横轴称为“假正例率(FPR)”
对应的混淆矩阵如下;
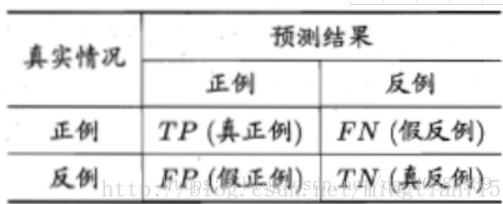
其对应的定义为:

其绘制的评价的ROC曲线为:
上面的大多数东西在网上都能够找到,那么我们怎么样评价模型的好坏那?
即引出AUC的概念,它的意思是曲线与横轴围成的面积,直观一点说就是,如果曲线越靠近我们的y轴,那么其模型的评价就是越好的.,因为越靠近y轴,其面积也就越大..(具体计算可以积分)
这带来的一个启发就是,我们针对一个分类与预测问题,可以分别用不同的算法是对其实现(比如可以用决策树与神经网络分别对其实现),分别构造这两者的混淆矩阵.然后绘制其ROC曲线,然后评价到底使用哪一种方法对实现这个问题是比较好的..
来源:CSDN
作者:qq_20880939
链接:https://blog.csdn.net/qq_20880939/article/details/79940561