题目链接 https://www.luogu.org/problem/P2168
题目大意是给定 n 个单词的出现次数wi,求用k 进制的前缀码转换后得到的最小总长度,以及在保证总长度最小时的最长串 si 的长度最短。
这题现在来看算是NOI里很简单的了(我竟然凹出来了w),但是据说当时这题可是难倒一大片。首先是因为这题题干太长不怎么容易看懂,另外可能是因为当时哈弗曼树还没有那么常见,几乎没人想到有哈弗曼树这么一个东西。
好,来看题。题目很明确,目标是要使编码之后的总长度最小,那么现在就要想着,怎样把出现次数多的编码长度尽可能的缩小。但是题目里有个限制:任意一个k进制编码都不是其它编码的前缀。这样一来,题目的做法就指向了哈弗曼树。
哈弗曼树与哈夫曼编码
这里简单重复一下 ——(证明过程引用自耿国华主编的《数据结构——C语言描述》)
哈夫曼树特性:从根结点到所有叶子结点的带权路径长度最短(就是权大的放靠近树根的地方)
做法:挑选序列里最小的2个点合并作为子节点,根节点的权值为他们的和,把根节点加入原序列,重复上述操作。
哈夫曼编码特性:1.它是前缀码。前缀码就是题目里给的那种,任何一个编码都不是其它编码的前 t项。证明:哈夫曼编码是根到叶子路径上的边的编码序列,也就是等价边序列,而由树的特点可知,若路径A是另一条路径B的最左部分,则B经过了A,因此,A的终点不是叶子。而哈夫曼编码都对应终点为叶子的路径,所以,任一哈夫曼编码都不会与任意其他哈夫曼编码的前部分完全重叠,因此哈夫曼编码是前缀码。
2.它是最优前缀码。就是:对于n个字符,将它们按使用频度为叶子构造哈夫曼树,则能使编码后的各种报文对应的编码平均长度最短。证明:由于哈夫曼编码对应叶子权为各字符使用频度的哈夫曼树,因此,该树为带权长度最小的树,即∑WP最小,其中W是第i个字符的使用频度,而P是第i个字符的编码长度,这正是度量报文平均长度的式子 。
作用:这是数据压缩技术最基本的思想诶!
做法:拿堆来存东西。
好的,可以发现这道题与哈夫曼树的思路 完 全 一 致。那么就用哈夫曼编码来试试好了。。
大佬们已经对这道题分析得非常透彻了,所以我划划水就好了。
哈夫曼树是二叉树。而这题里给的是多叉树。其实就是拓展嘛。
我们想象构造好哈夫曼树之后的样子。首先,树的深度就是编码后这个词的长度,最上面的点是出现次数最多的单词,最下面是出现次数最少的。拿样例来说话,就是这样的:
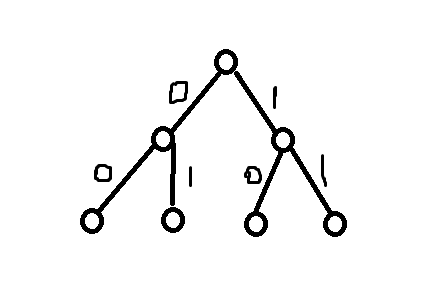 这样标码,四个点分别是00,01,10,11;
这样标码,四个点分别是00,01,10,11;
根据哈夫曼树的思想,每次必须拿两个当前点权最小的点来合成一个他们的父结点,直至最后所有结点被合并为一个。这道题是拿k*k个点合成一层结点,他们的父结点为子结点权值之和,如此一直合并到只剩一个。这里的“权值”可以这么理解:假设我是一个结点,我下面只有一层,共k个点,我的权值是我所有子结点的出现次数之和。谁要是和我合并产生一个我的父结点,那么我下面的子结点的长度统统都被加上了1,即为:在“我被合并”这个操作中,总长度被加上了:我的权值*1。
至此这道题的思路就差不多捋清了:首先找一个合适的数据结构存信息,保存点的权值,然后逐步合并点并更新它们父结点的权值和高(深)并记录每一步对总长度造成的影响,最后只剩一个点时,输出总长度和顶点的高。
数据结构这里推荐——优先队列。这是一个应用起来非常简单的玩意儿,自己瞎试几下就会用了。优先队列在这里是模拟了一个类似堆的结构,就是总是把点权小的那几个放在队列的前面。
最后,一个大细节。只是按上面的思路那样做的话会出现一种情况:如图,n=6,k=3.
如果只是按照上面的逻辑搞就会有这样的情况发生,红圈标出来的点本来可以是编号为“2”,它不会成为别人的前缀和,但是它浪费了这个位置。解决办法:适当地补上一些点使树成为完全k叉树,这些点的权值为0(就是肯定会排在最底层且对答案没有影响,这样就可以实现把本来该在上面的点挤上去的功能),高度初始化为1。点的个数为:k-1-(n-1)%(k-1)。慢慢体会~
补点之后的操作起来是这样(还是n=6,k=3):这里只需要补一个点。补的点我们叫ex. ex肯定是第一个被塞到底层的点。那么当我们跑到刚才红圈圈出的那个点时,实际上这六个点的位置已经被填满了。那么这个点将会和那两个蓝圈圈出来的点一起合并。图:
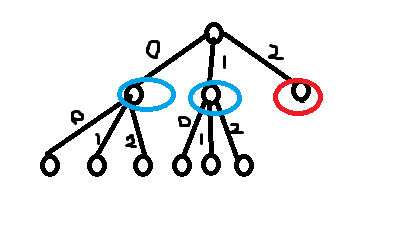
于是,我们就把它挤到了红圈这个位置。
好的。附代码。
#include<iostream>
#include<iomanip>
#include<algorithm>
#include<cstring>
#include<cstdio>
#include<queue>
using namespace std;
int n,k;
long long lenth;
struct tree{
long long val;
long long h;
};
priority_queue<tree>q; //优先队列
bool operator<(tree a,tree b){
if(a.val!=b.val) return a.val>b.val; //把点权从低到高排序
else return a.h>b.h; //不然优先排高度低的(为了模拟完全k叉树
}
inline long long max(long long a,long long b){
if(a>b)return a;
else return b;
}
int main(){
cin>>n>>k;
long long remain=0;
for(int i=1; i<=n; i++){
tree a;
scanf("%lld",&a.val );
a.h =1;
q.push(a);
}
int extra=0;
if((n-1)%(k-1))extra=k-1-(n-1)%(k-1); // *深入灵魂的做法*
for(int i=1; i<=extra; i++){ // 需要补足成完全k叉树所需的额外结点
tree a;
a.val=0; a.h =1;
q.push(a);
}
remain+=n+extra;
while(remain!=1){
tree a;
long long cnt=1,maxh=0,tmp=0;
while(cnt<=k){ //k进制
a=q.top() ; //a现在是队首(权值最小)的一个tree
q.pop() ;
maxh=max(maxh,a.h);//更新当前正在合成的结点的高度
tmp+=a.val ;
cnt++;
}
a.h =maxh+1;
a.val =tmp;
lenth+=tmp;
q.push(a);
remain=remain-k+1;
}
tree a=q.top() ;
cout<<lenth<<endl<<a.h -1;
}
应该是第一次发文吧...很紧张。看了一眼洛谷的题解,发现有那么一篇好相似(汗)。。