10.6 监控io性能
10.7 free命令
10.8 ps命令
10.9 查看网络状态
扩展tcp三次握手四次挥手 http://www.doc88.com/p-9913773324388.html
三次握手要查看,面试会被问到
tshark几个用法:http://www.aminglinux.com/bbs/thread-995-1-1.html
10.10 linux下抓包
10.6 监控io性能:
如果我们cpu和内存明明还有剩余,但是系统就是负载很高。用vmstat的查看发现b列或者wa列比较大。那是不是说明我们磁盘有瓶颈,那我们就要更详细的查看磁盘的状态
我们在安装sysstat的时候,就会安装上iostat这个命令。instat和sar属于同一个包
我们直接敲iostat就可以查看,或者敲instat 1(iostat 1 10)来查看读写,跟sar -b的结果差不多
我们需要掌握的是:
~1. iostat -x 1
主要查看 %util。他首先是一个百分比。
&util这一列表示你的io 等待,总之就是你这个磁盘使用有多少时间,就是说占用cpu的。那么我们这个cpu有一部分是给进程处理的、计算的。那也有一部分时间是要等待io的,等待磁盘读写,要把这个数据读出来,数据的读写也要等待的吧。那么这个时间比是多少。就是我等待你的时间比是多少,就是%util
如果这个数字很大,比如50%或60%。那磁盘的io也就太差了,说明他非常的忙。那%util很大,那么相应的读和写这一列也就很大。但是如果,读和写并不大,而%util很大,那么说明磁盘可能出现问题,有故障
如果硬盘很慢,会影响系统的性能。即是cpu运行的再快,硬盘跟不上,也是存在很大的瓶颈
所以,我们iostat -x 就是关注%util
~2. iotop
yum install -y iotop
比如,我们发现磁盘很忙,很频繁。那到底是哪一个进程在频繁的读写呢?这时候我们就要获得是哪一个进程,那么就要使用iotop
他和top命令其实是很像的,也是动态显示。
intop
使用的话,直接敲iotop就可以。我们主要关注io这一列
WRITE是写,READ是读
实例:
1.
[root@axinlinux-01 ~]# iostat -x 1 我们主要关注%util这一列
Linux 3.10.0-693.el7.x86_64 (axinlinux-01) 2018年07月11日 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.27 0.00 0.37 0.42 0.00 98.95
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.04 1.99 0.89 75.58 5.00 55.90 0.03 10.48 13.82 3.06 4.33 1.25
2.
[root@axinlinux-01 ~]# iotop
Total DISK READ : 0.00 B/s | Total DISK WRITE : 0.00 B/s
Actual DISK READ: 0.00 B/s | Actual DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
512 be/4 chrony 0.00 B/s 0.00 B/s 0.00 % 0.00 % chronyd
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % systemd --switched-root --system --deserialize 21
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
3 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [ksoftirqd/0]
----------------------------------------------------------------------------------------------------------------------------------------------------
10.7 free命令:
~1. free 查看内存使用情况
以KB为单位显示
Mem代表内存,swap代表交换分区
total表示总共的大小、used表示使用了多少、free表示剩余多少、shared表示共享了多少
会发现使用的和剩余的相加不等于总共的。是因为linux会将内存预分配出来一部分给buff和cache
~2. free -m / -g / -h
-m 以MB显示
-g 以G为单位,用不到
-h后缀单位来显示,更直观
~3.buffer/cache 区别
buff是缓冲、cache是缓存
cache可这样理解:0000数据(磁盘)-->内存(cache) -->cpu
我们把0000这个数据从磁盘中取出来,让cpu去分析运算,因为磁盘很慢,所以我们先缓存到内存中。让cpu从 内存中去拿,这样就很快了。那这一部分,我们叫做cache(缓存)
buff可这样理解 :cpu(oooo数据)-->内存(buffer)-->磁盘
接上面,cpu分析完了之后,要在返还给磁盘保存,因为磁盘很慢。cpu还要处理后面排队的进程,等不及,所以先缓冲到内存中。经有内存保存到磁盘中。那这一部分,我们叫做buffer(缓冲)
所以也解释了,为什么系统要预留出空间给cache和buffer
这就是数据的流向不一样。那么内存使用角色的名字也不一样
~4.公式:total=used+free+buff/cache
会发现使用的和剩余的相加不等于总共的。是因为linux会将内存预分配出来一部分给buff和cache
buff是缓冲、cache是缓存
~5. avaliable包含free和buffer/cache剩余部分
avaliable是系统预留给cache和buffer的空间,还没有用完的
所以,我们用free来查看内存的时候。真正关注的是avaliable,而不是free
~6. swap
平时也要注意
如果used跑慢了,free没剩余了,就要加swap了。当然加swap不是解决的方法,需要加内存。swap不够说明内存不够,或者说内存泄漏了。说明程序有bug要排查
实例:
[root@axinlinux-01 ~]# free 直接free,会以KB显示
total used free shared buff/cache available
Mem: 1875504 125088 1472808 8764 277608 1568236
Swap: 1999868 0 1999868
[root@axinlinux-01 ~]# free -h -h会自动加上单位
total used free shared buff/cache available
Mem: 1.8G 122M 1.4G 8.6M 271M 1.5G
Swap: 1.9G 0B 1.9G
[root@axinlinux-01 ~]# free -m -m以MB显示
total used free shared buff/cache available
Mem: 1831 122 1438 8 271 1531
Swap: 1952 0 1952
[root@axinlinux-01 ~]# free -g -g
total used free shared buff/cache available
Mem: 1 0 1 0 0 1
Swap: 1 0 1
----------------------------------------------------------------------------------------------------------------------------------------------------
10.8 ps命令:
把当前的进程的快照给汇报一下
top也可以查看进程,ps和top的区别在于,top动态的具体的查看进程,查看使用cpu的,使用内存的,也可以做一个排行榜出来。而ps是静态的,一次性的,把当前的进程的使用状况列出来
~1. ps aux
把系统里所有的进程全部列出来
~2. ps aux | grep nginx
最常用的方法,加上管道符。将ps aux过滤出某个任务。比如,查看nginx有没有在运行,或查看mysql有没有在运行
~3. ps -elf
效果跟ps aux差不多。平常用ps aux就可以了
~4. kill pid
杀死一个进程,例如要杀死一个进程,就要看他的pid
写法为 kill 1346。
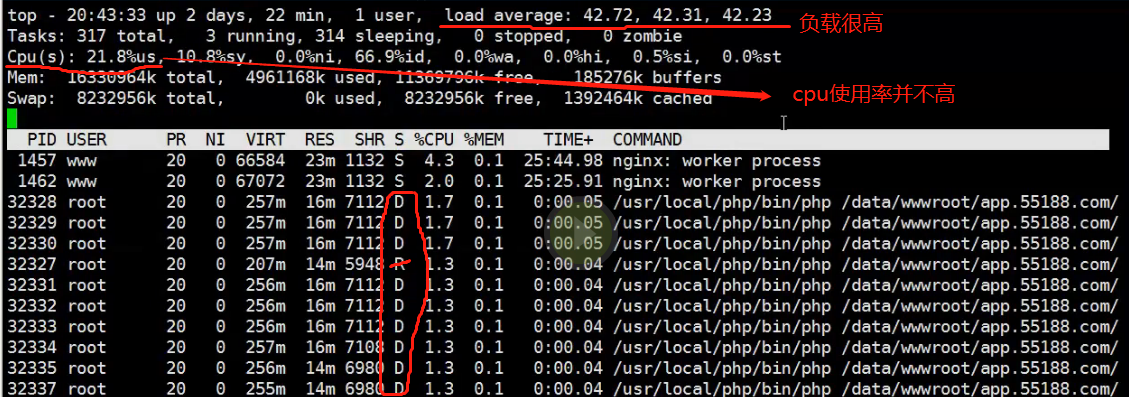
~5. STAT部分,这一列的说明
D 不能中断的进程
假如有一台服务器,D进程很多,相应的系统负载很高。但是他的cpu使用率不高,也是没有什么问题的
这是一种特例,不能中断的进程

R run状态的进程
正在跑的进程,并不是说他正在使用着cpu。而是说某个时间段在使用着cpu
S sleep状态的进程
这中进程,就是他在使用完cpu,运算完之后,就先休息一会,过一会就会再激活,然后在继续使用cpu
T 暂停的进程
比如我们,运行vmstat 1,因为这个命令一直在运行时动态的,我们ctrl +z一下,暂停一下。在ps aux | grep vmstat就会显示 T 状态。那我们不暂停,在另一个终端上,再过滤一下,会发现他是S状态。这是因为,我们只是用这个命令运行了一下,就抓这么一下,cpu就去忙别的事了,然后就sleep了,他基本上不会占用什么cpu资源,所以会显示S。这种情况需要注意
Z 僵尸进程
很少有。如果有太多的话,要想办法杀死
< 高优先级进程
优先级高,先给他用cpu
N 低优先级进程
L 内存中被锁了内存分页
理解就可以
s 主进程
父进程与子进程的区别。也就是由父进程延伸出来的。父进程通常为root,然后延伸给其他用户。父进程就是主进程
l 多线程进程
线程与进程是有区别的。线程是有一个大的进程组成的,一个进程里有多个线程。其中还涉及内存的,进程与进程之间是不共享内存的,线程与线程之间是可以共享内存的
多线程进程就是这个进程里有多个线程
+ 前台进程
都在我们这个前台的终端上,不在后台
比如我们ps aux | grep mysql,他是在前台执行的。我们在另一个tty,另一个终端ps aux的时候就会显示+,因为是在前台执行的
实例:
1.
2.
[root@axinlinux-01 ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 128208 6844 ? Ss 7月11 0:02 /usr/lib/systemd/systemd --switched-root --system --deserialize 21
root 2 0.0 0.0 0 0 ? S 7月11 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 7月11 0:00 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< 7月11 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? S 7月11 0:00 [kworker/u128:0]
[root@axinlinux-01 ~]# ps aux | grep kthreadd
root 2 0.0 0.0 0 0 ? S 7月11 0:00 [kthreadd]
root 1445 0.0 0.0 112724 980 pts/0 S+ 00:20 0:00 grep --color=auto kthreadd
5.
[root@axinlinux-01 ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.3 128208 6844 ? Ss 7月11 0:02 /usr/lib/systemd/systemd --switched-root --system --deserialize 21
root 2 0.0 0.0 0 0 ? S 7月11 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 7月11 0:00 [ksoftirqd/0]
root 5 0.0 0.0 0 0 ? S< 7月11 0:00 [kworker/0:0H]
root 9 0.0 0.0 0 0 ? R 7月11 0:01 [rcu_sched]
root 31 0.0 0.0 0 0 ? SN 7月11 0:00 [ksmd]
root 359 0.0 0.1 36872 2908 ? Ss 7月11 0:00 /usr/lib/systemd/systemd-journald
----------------------------------------------------------------------------------------------------------------------------------------------------
10.9 查看网络状态:
netstat这个命令是用来查看网络状态的,linux作为服务器上的操作系统。这个服务器上会有很多服务,服务往往是跟客户端相互通信的,所以意味着他要有监听端口,要有对外的通信端口。那netstat命令查看的就是tcp/ip对外的状态
相当于说,服务器想让别人访问或互联,就需要打开一个口,一个端口。通过这个端口,让外界访问。netstat就是查看这个口的
~1. netstat 查看网络状态
相当于说,服务器想让别人访问或互联,就需要打开一个口,一个端口。通过这个端口,让外界访问。netstat就是查看这个口的
~2. netstat -lnp 查看监听端口
详细见实例 2.
也可加t,netstat -ltnp,只查看tcp,我们需要重点查看的
还可以加u,netstat -ltunp,查看tcp和ucp。tcp和ucp都是我们需要经常查看的
~3. netstat -an 查看系统的网络连接状况
查看tcp/ip状态
大多数的状态(state)是 TIME_WAIT,客户端和服务端相互通信,通信完了之后,他们的链接还没有断开。处于一种等待的状态,等待下一次通信再一次的链接,传输数据。这个就是TIME_WAIT状态
ESTABLISHED(state)表示建立链接的,正在传输数据。如果这个数据很大,说明你的系统很忙。正常是在1000以内,服务器都是可以接受的
~4. netstat -lntp 只看出tcp的,不包含socket
~5. ss -an 和nestat 异曲同工
ss -an不会显示进程的名字和pid
~6. 分享一个小技巧
netstat -an | awk '/^tcp/{++sta[$NF]} END {for(key in sta) print key,"\t",sta[key]}'
可查看所有的链接的状态有多少的,配合awk使用的
实例:
2.
[root@axinlinux-01 ~]# netstat -lnp
主要查看这些端口
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 881/sshd
这个sshd就是我们之前远程连接的端口,就22端口
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1115/master
tcp6 0 0 :::22 :::* LISTEN 881/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1115/master
udp 0 0 127.0.0.1:323 0.0.0.0:* 512/chronyd
udp6 0 0 ::1:323 :::* 512/chronyd
unix 2 [ ACC ] STREAM LISTENING 13742 1/systemd /var/run/dbus/system_bus_socket
netstat也可以监听socket文件
unix 2 [ ACC ] STREAM LISTENING 17910 1115/master public/flush
unix 2 [ ACC ] STREAM LISTENING 17925 1115/master public/showq
unix 2 [ ACC ] STREAM LISTENING 14313 504/VGAuthService /var/run/vmware/guestServicePipe
unix 2 [ ACC ] STREAM LISTENING 8429 1/systemd /run/systemd/journal/stdout
[root@axinlinux-01 ~]# netstat -ltnp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 881/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1115/master
tcp6 0 0 :::22 :::* LISTEN 881/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1115/master
[root@axinlinux-01 ~]# netstat -ltunp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 881/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1115/master
tcp6 0 0 :::22 :::* LISTEN 881/sshd
tcp6 0 0 ::1:25 :::* LISTEN 1115/master
udp 0 0 127.0.0.1:323 0.0.0.0:* 512/chronyd
udp6 0 0 ::1:323 :::* 512/chronyd
6.
[root@axinlinux-01 ~]# netstat -an | awk '/^tcp/{++sta[$NF]} END {for(key in sta) print key,"\t",sta[key]}'
LISTEN 4
ESTABLISHED 1
----------------------------------------------------------------------------------------------------------------------------------------------------
10.10 linux下抓包:
例如我们会遇到攻击,进入的包会超过1万。就要知道有哪些数据包进来,那么就可以用tcpdump这个命令查看
yum -install -y tcpdump
~1. 抓包工具 tcpdump
~2. 用法:tcpdump -nn
基本用法
第一个n表示你的ip以数字的形式显示出来,如果不加会显示成主机名,而且端口会显示成.ssh,不会显示数字(具体哪个端口,会比较麻烦。所以还是加上-nn
因为没有连接服务器,所有的都是从22端口出去的
~3. tcpdump -nn -i ens33
-i给他指定网卡的名字,inconfig看一下,就是ens33
我们最主要关注的就是 源IP与源端口到哪个IP与端口去(详细见实例3.)
还有就是看length(长度)
常见的包是tcp的,但是又udp的包,很有可能是被攻击了
有一种攻击是DDOS udp flood洪水攻击,300个G的攻击。只能找专业的防攻击系统,比如创宇。了解一下
~4. tcpdump -nn port 80
指定端口,例如80
因为抓包的时候回抓到很多,可以指定他的端口
~5. tcpdump -nn not port 22 and host 192.168.0.100
在指定抓包的同时还可以加 and 指定他的源IP,也就是指定他从哪个IP出去的
~6. tcpdump -nn -c 100 -w 1.cap
-c只抓100个
-w把他存到哪个文件里去
如果暂定不动了,是因为我们在这个终端不去产生一些数据流的话,就不会产生那么多的数据包让我们抓
这个.cap文件是不能直接解析不能直接看的,只能file查看他的基本信息。因为抓取的就是网卡里面的原始数据,一个真真正正通信的数据
如果想看,可以用tcpdump -r 1.cap,但是查看的也是你抓到的一些数据流向,
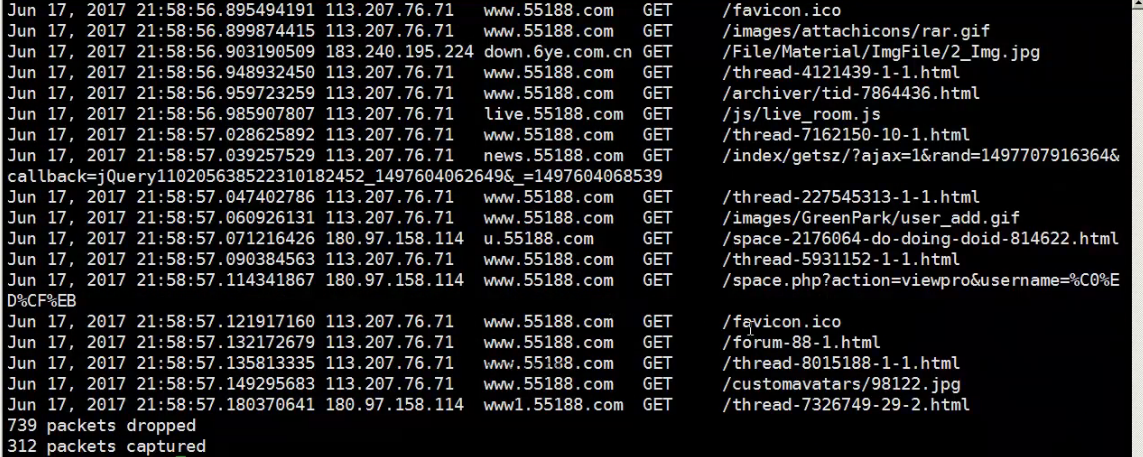
~7. tshark -n -t a -R http.request -T fields -e "frame.time" -e"ip.src" -e "http.host" -e "http.request.method" -e "http.request.uri"
指定网卡80端口的一个web访问的情况。类似于web的访问日志。可以很清晰的发现在这个网卡上有什么IP来访问我的网站,访问网站的说明链接
~8. yum install -y wireshark
实例:
3.
[root@axinlinux-01 ~]# tcpdump -nn -i ens33
01:35:04.465877 IP 192.168.159.128.22 > 192.168.159.1.50111: Flags [P.], seq 311036:311408, ack 53, win 448,
时间 源IP与源端口 >到哪里去 到这个IP去与端口 后面的是数据包的信息
主要关注的
options [nop,nop,TS val 13524436 ecr 1422241], length 372
01:35:04.466196 IP 192.168.159.1.50111 > 192.168.159.128.22: Flags [.], ack 311408, win 236, options [nop,nop,TS val 1422241 ecr 13524435], length 0
其实这两个是一对,从22端口到50111端口去。然后50111在返回到22端口去
7.
来源:oschina
链接:https://my.oschina.net/u/3866149/blog/1844758