此文为《python数据分析和数据挖掘》的读书笔记
通俗讲,经过我们前期的数据分析,得到了数据的缺陷,那么我们现在要做的就是去对数据进行预处理,可包括四个部分:数据清洗、数据集成、数据变换、数据规约。
处理过程如图所示:
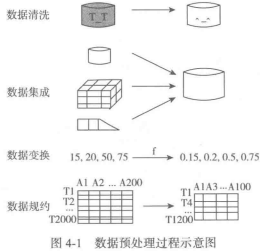
1、数据清洗
1) 缺失值处理:
删除记录、数据插补、不处理。不处理吧总感觉不自在,删除了吧数据又有点舍不得,所以一般插补方法用的比较多,该文重点介绍Lagrange插补法和牛顿插补法,并介绍代码。
偷点懒他的详细过程我截图好了。
a 拉格朗日插补法


b 牛顿插补法

但是由于python中的Scipy库中提供了Lagrange插值法的函数,实现上更为容易,应用较多。而牛顿插值法则需要根据自行编写。需要指出两者给出的结果是相同的(相同次数、相同系数的多项式),不过表现的形式不同而已。
二话不说贴上亲测的python代码:
import pandas as pd
from scipy.interpolate import lagrange#导入拉格朗日函数
import sys
sys.__stdout__=sys.stdout
inputfile='catering_sale.xls'#销售数据途径
outputfile='tmp/sales.xls'#输出数据途径
data=pd.read_excel(inputfile,Index_col=u'日期')#读入数据
data[u'销量'][(data[u'销量']<400)|(data[u'销量']>5000)]=None#过滤异常值,将其变为空值
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def polyinterp_column(s,n,k=5):
y=s[list(range(n-k,n))+list(range(n+1,n+1+k))]#取数
y=y[y.notnull()]#剔除空值
return lagrange(y.index,list(y))(n)#插值并返回插值结果
#逐个元素判断是否需要插值
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
for i in data.columns:
for j in range(len(data)):
if(data[i].isnull())[j]:
data[i][j]=polyinterp_column(data[i],j)#如果为空即插值
print(str(len(data))+'\n',data)
data.to_excel(outputfile)#输出结果导入文件具体代码作用有相应注释。
2)异常值处理:异常值是否删除,要先分析异常值出现的原因,判断异常值是否应该舍弃。但推荐将其视为缺失值处理,可以利用现有的变量信息,对异常值进行填补。

2、数据集成
将多个数据源合并存放在一个已知的数据存储中的过程,需要考虑实体识别和属性冗余问题,具体表现在单位要统一、属性不重复,命名不重合等马虎原因,该过程属于人工复查过程。
3、数据变换
规范化处理,满足挖掘需要。
简单函数变换:平方、开方、取对数、差分运算等。常用于将不具有正态分布的数据变换到具有正态分布的数据。在时间序列分析中简单的对数变换或差分变换可将非平稳序列转换成平稳序列,使用对数变换对其进行压缩是一种常用的一种变换处理方法。
1) 规范化:将数据映射到某一小区间,如归一化。
a) min-max规范化
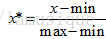
(data-data.min())/(data.max()-data.min())
b)零-均值规范化——当前应用更广泛
又称标准差标准化,经过处理的数据均值为0,标准差为1。转化公式为
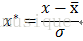
其中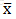 为原始数据的均值,
为原始数据的均值, 为原始数据的标准差。(data-data.mean())/data.std()
为原始数据的标准差。(data-data.mean())/data.std()
c) 小数定标规范化
通过移动属性值的小数位数,将属性值映射到[-1, 1]之间,移动的位数取决于属性值绝对值的最大值。转化公式为:
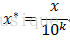
data/10**np.ceil(np.log10(data.abs().max()))
2) 连续属性离散化:在数据范围内设定若干个离散的划分点。确定分类数以及如何将连续属性值映射到这些分类值。
常用的有等宽法(属性置于划分成相同宽度的区间)、等频法(相同数量的记录放在同一区间)、基于聚类分析的算法。对聚类分析方法重点说明一下:1.将连续属性的值用聚类算法(K-Means算法)进行聚类 2.将聚类得到的簇进行处理,合并到一个簇的连续属性值并做同一标记。用户指定簇的个数从而决定产生的区间数。
对K-Mean的自己理解:随机一个点作为中心点,设定一个安全距离dist(可以是欧式距离),满足在dist内的所有点构成一个簇即一个类,然后重新算簇中所有点的平均值,以他为中心点将他安全距离dist内的所有点划为一类,big重新计算簇中所有点的平均值。大致细节是这样的,但是我们无法设定距离dist,只能设定期望得到的分类数咯。
#数据规范化
import pandas as pd
datafile='data/discretization_data.xls'#参数规范化
data=pd.read_excel(datafile)#读取数据
data=data[u'肝气郁结证型系数'].copy()#复制整份作为副本
k=4#分成4类
d1=pd.cut(data,k,labels=range(k))#等宽离散化,各个类比一次命名为0,1,2,3
#等频率离散化
w=[1.0*i/k for i in range(k+1)]
w=data.describe(percentiles=w)[4:4+k+1]#使用describe函数自动计算分位数
w[0]=w[0]*(1-1e-10)
d2=pd.cut(data,w,labels=range(k))
from sklearn.cluster import KMeans#引入KMeans
kmodel=KMeans(n_clusters=k) #建立模型,n_jobs是并行数,一般等于CPU数就好
kmodel.fit(data.values.reshape((len(data),1))) #训练模型
c=pd.DataFrame(kmodel.cluster_centers_).sort() #输出聚类中心,并且排序(默认是随机排序)
w=pd.rolling_mean(c,2).iloc[1:] #相邻两项求中点,作为边界点
w=[0]+list(w[0])+[data.max()] #把首末边界点加上
d3=pd.cut(data,w,labels=range(k))
import matplotlib.pyplot as plt#自定义左图函数显示聚类结果
def cluster_plot(d,k):
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False#用来正常显示负号
plt.figure(figsize=(8,3))
for j in range(0,k):
plt.plot(data[d==j],[j for i in d[d==j]],'o')
plt.ylim(-0.5,k-0.5)
return plt
cluster_plot(d1,k).show()
cluster_plot(d2,k).show()
cluster_plot(d3,k).show()3) 属性构造:该属性用于衡量标准的一个指标
4) 小波变换:信号分析手段,在时域和频域方面具有表征信号局部特征的能力,用于特征提取。
应用小波分析技术可以把信号在各个频率波段中的特征提取出来,基于小波变换的多尺度空间能量分布特征提取方法是对信号进行频带分析,再分别以计算所得各个频带的能量作为特征向量。信号f(t)的二级小波分解可表示为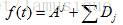
其中A为近似信号低频部分;D是细节信号高频部分,信号的频带分布如图所示
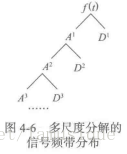
信号的总能量为: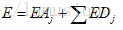
选择第j层的近似信号和各层的细节信号的能量作为特征,构造特征向量: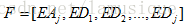
利用小波变换可以对声波信号进行特征提取,提取出可以代表声波信号的向量数据,即完成从声波信号到特征向量数据的变换。本里利用小波函数对声波信号数据进行分解得到5个层次的小波系数。利用这些小波系数求得各个能量值,这些能量值即可作为声波信号的特征数据。
在python中信号处理库为PyWavelets(pywt)
#利用小波分析进行特征分析
#参数初始化
inputfile='data/leleccum.mat'#提取自matlab的信号文件
from scipy.io import loadmat#mat是Python专用格式,需要用loadmat读取
mat=loadmat(inputfile)
signal=mat['leleccum'][0]
import pywt#导入PyWavelets
coeffs=pywt.wavedec(signal,'bior3.7',level=5)
#返回结果为level+1个数字,第一个数组为逼近系数数组,后面的一次是细节系数数组
print(coeffs)4、数据规约
产生更小但保持原数据完整性的新数据集,降低无效错误数据对建模的影响,减少挖掘时间,降低数据存贮成本。
1)属性规约:听着这名词高大上,其实就是删除不相关的属性(维)来减少数据维数,寻找出最小的维数确保新数据子集的概率分布尽可能接近原来数据集的概率分布。常用方法有合并属性、逐步向前选择、逐步向后删除、决策树归纳、PCA。
a. 决策树归纳:我印象中决策树主要通过比较各个属性的信息熵,这个属性你可以理解成数据的特征,而一个数据正是有多个特征或属性结合而成的行向量。根据一堆数据行向量逐行排成的数据矩阵(行向量数据的列向量)信息熵的大小,分析出对于该目标向量的最大最有效的属性,构成一个初始二叉决策树。没有出现在决策树上的属性均认为是无关属性。
b. PCA:用较少的变量去解释原始数据中的大部分变量,即将许多相关性很高的变量转化成彼此相互独立或不相关的变量。接下来这段知识,没学过矩阵理论的大侠就请绕过吧。用矩阵的知识可以这么解释:矩阵的列向量所张成的空间即为矩阵所代表的空间,即说明矩阵张成的空间维数等于列向量的列数,而PCA消失的维数代表化零维,即就是矩阵空间中的化零空间N(A),得到的空间成为秩空间R(A),满足dim(A)=dim(R(A))+dim(N(A))。那么怎么得到R(A)呢?——线性变换(+ .)。已知dim(R(A))=r秩,通过A矩阵所代表的平移伸缩,但并不会改变方向的空间向量,这种向量称之为特征向量,其伸缩因子称之为特征值,这是其几何显性意义。那么就可以通过特征值去获得较为全面的矩阵信息!且特征值的个数等于矩阵的秩。得到的特征向量,经矩阵A再反向张开,获得一个新矩阵来代表数据的有效信息。本处使用几何空间去解释矩阵,可以去了解《控制系统中的矩阵代数》的第一章内容。具体到PCA。
主成分分析的计算步骤:
1) 设原始变量的n次观测数据矩阵为:
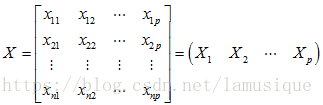
注意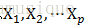 是列向量,分别表示某一特征数据的n次观测
是列向量,分别表示某一特征数据的n次观测
2) 将数据矩阵阵列进行中心标准化。为了方便仍将标准化后的数据矩阵仍然记为X
3) 求相关系数矩阵R,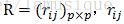 的定义为:
的定义为:
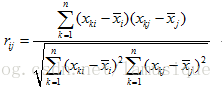
4) 求R的特征方程det(R-λE)=0的特征根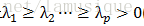 (从大到小的排列特征值)
(从大到小的排列特征值)
5) 确定主成分个数m: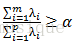 ,根据实际情况确定,一般取80%
,根据实际情况确定,一般取80%
6) 计算m个相应的单位特征向量:
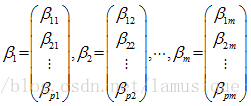
7) 计算主成分:
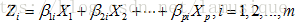
在python中主成分分析的函数位于Scikit-Learn下:
sklearn.decomposition.PCA(n_components=None,copy=True,whiten=False)
其中whiten表示白化,使得每个特征具有相同的方差,缺省是默认False;
n_components表示PCA算法要保留的主成分个数,也即要保留下来的特征个数;
copy表示是否在运行算法是保留原始训练数据,复制一份数据副本对其操作,默认为True。
import pandas as pd
#参数初始化
inputfile="data/principal_component.xls"
outputfile='tmp/dimention_reduces.xls'#降维后的数据
data=pd.read_excel(inputfile,header=None)#读入数据
from sklearn.decomposition import PCA
pca=PCA()
pca.fit(data)
print('各个特征向量\n',pca.components_)#返回模型的各个特征向量
print('\n各个成分各自的方差百分比\n',pca.explained_variance_ratio_)#返回各个成分各自的方差百分比
>>>
各个特征向量
[[ 0.56788461 0.2280431 0.23281436 0.22427336 0.3358618 0.43679539
0.03861081 0.46466998]
[ 0.64801531 0.24732373 -0.17085432 -0.2089819 -0.36050922 -0.55908747
0.00186891 0.05910423]
[-0.45139763 0.23802089 -0.17685792 -0.11843804 -0.05173347 -0.20091919
-0.00124421 0.80699041]
[-0.19404741 0.9021939 -0.00730164 -0.01424541 0.03106289 0.12563004
0.11152105 -0.3448924 ]
[-0.06133747 -0.03383817 0.12652433 0.64325682 -0.3896425 -0.10681901
0.63233277 0.04720838]
[ 0.02579655 -0.06678747 0.12816343 -0.57023937 -0.52642373 0.52280144
0.31167833 0.0754221 ]
[-0.03800378 0.09520111 0.15593386 0.34300352 -0.56640021 0.18985251
-0.69902952 0.04505823]
[-0.10147399 0.03937889 0.91023327 -0.18760016 0.06193777 -0.34598258
-0.02090066 0.02137393]]
各个成分各自的方差百分比
[ 7.74011263e-01 1.56949443e-01 4.27594216e-02 2.40659228e-02
1.50278048e-03 4.10990447e-04 2.07718405e-04 9.24594471e-05]当选取前4个主成分是,累计贡献率已达到97.37%,说明前3个主成分进行计算已经相当可以,因此可重新建立PCA模型,设置n_components=3。
#通过分析认为n_components=3最好
pca=PCA(3)
pca.fit(data)
low_d=pca.transform(data)#用它来降低维度
pd.DataFrame(low_d).to_excel(outputfile)#保存结果
pca.inverse_transform(low_d)#必要时可以用inverse)transform()函数来复原数据降维后的数据
[[ 8.19133694 16.90402785 3.90991029]
[ 0.28527403 -6.48074989 -4.62870368]
[-23.70739074 -2.85245701 -0.4965231 ]
[-14.43202637 2.29917325 -1.50272151]
[ 5.4304568 10.00704077 9.52086923]
[ 24.15955898 -9.36428589 0.72657857]
[ -3.66134607 -7.60198615 -2.36439873]
[ 13.96761214 13.89123979 -6.44917778]
[ 40.88093588 -13.25685287 4.16539368]
[ -1.74887665 -4.23112299 -0.58980995]
[-21.94321959 -2.36645883 1.33203832]
[-36.70868069 -6.00536554 3.97183515]
[ 3.28750663 4.86380886 1.00424688]
[ 5.99885871 4.19398863 -8.59953736]]原始数据从8维降到了3维,维持了95%的数据信息。
2) 数值规约:通过选择替代的、较小的数据来减少数据量,包括有参数方法和无参数方法两类。有参数方法是使用一个模型来评估数据只需存放参数,而不需要存放实际数据,例如回归(线性回归和多元回归)和对数线性模型(近似离散属性集中的多维概率分布)。无参数的方法就需要存放实际数据,例如直方图、聚类、抽样(采样)。
来源:CSDN
作者:lamusique
链接:https://blog.csdn.net/lamusique/article/details/79703088