0. 背景
机构:香侬科技
作者:Yuxian Meng*, Wei Wu*
发布地方:NeurIPS 2019
面向任务:Language Representation
论文地址:https://arxiv.org/pdf/1901.10125
论文代码:https://github.com/ShannonAI/glyce
0.1 摘要
对于表意文字(logographic,又称语素文字,在非正式场合又称象形文字)语言如中文,从直觉上来说,其NLP任务应该是能够从字形信息中受益。但是,由于象形文字中丰富的象形信息数据甚为匮乏,且标准计算机视觉模型对字符数据的泛化能力较弱,如何有效地利用象形文字信息还有待探索。本文提出Glyce来弥补这一缺憾,Glyce的字形向量是中文字符的一种表征。本文有如下3大创新:
(1)使用中文的各种文字形式,比如青铜器上的汉字,篆书,繁体中文等
(2)设计CNN结构(田字格-CNN)以适用中文字符的图像处理
(3)引入图像分类作为多任务学习的辅助任务,通过该辅助任务有效地提升了模型的泛化能力
通过在一系列中文NLP任务上的实验,证明本文基于字形的模型能够超越基于word和基于char的模型,并在多个中文NLP任务如序列标注(包括NER、CWS、POS)、句子对分类、单句分类、依存分析和语义角色标注任务上刷新记录。在OntoNotes(NER数据集)上的F1值达80.6,比BERT高出1.5;在Fudan语料上进行文本分类,精确度可以达到99.8%。惊不惊喜,期不期待~
1. 介绍
先贤们基于CNN设计的中文字符表征系统之所以无效,性能反而下降,大概有以下3个方面的原因:
(1)没有选用正确的汉字。汉字系统历史悠久,其演变从最早的易于绘制的字符,逐渐演变为易于书写的字符。易于书写,也意味着丢失了更多的象形信息,变得更抽象。现在,使用最为广泛的简体汉字,也是最易于书写的,但是不可避免地丢失了最重要的象形文字信息。比如,简体汉字"人"和"入",这2者意义上无关,但是在字形上却非常相似。这与历史上的其他文字如青铜器文字就有很大不同。
(2)没有选用合适的CNN架构。不像ImageNet的数据集那样,图像尺寸是800*600,字符标志的图像要小得多,一般是12*12。这就需要一个不同的CNN架构以捕捉字符图像的局部象形特征。
(3)没有使用合适的目标函数。ImageNet的数据集很大,有数千万的数据,而中文字符只有1W个左右。因此,急需一个辅助的训练目标在防止过拟合的同时,提升模型的泛化能力。
汉字演化如Figure 1所示:
本文所提出的GLYCE,用GLYph-Vevtors来对中文字符进行表征。将中文字符作为图像输入到CNNs中以获得其对应的表征。本文通过下述3项关键技术方案解决了上述提及的3个问题:
(1)综合利用历史和当代文字(如青铜器文字、隶书、篆书、繁体字等),由于这些汉字拥有不同的书写风格(如草书),所以可以从字符图像中获取到丰富的象形信息。
(2)为中文的象形字符定制田字格-CNN的架构。
(3)新增一个图像分类的损失函数以增强模型的泛化能力,并采用多任务学习的方式进行整体训练。
本文提出的Glyce能够提升多个中文NLP任务,并在多个任务上刷新记录。其中包括序列标注任务中的NER、CWS和POS任务,句对分类任务(使用以下数据集进行验证:BQ, LCQMC, XNLI, NLPCC-DBQA),单句分类任务(使用以下数据集进行验证:ChnSentiCorp, the Fudan corpus, iFeng),依存分析和语义角色标注任务。
2. Glyce
2.1 Using Historical Scripts
正如第一章所讨论的那样由于简体中文丢失过多的象形信息,所以本文采用不同历史上朝代中的字体及其不同的书写风格。主要收集的字体如Table 1所示: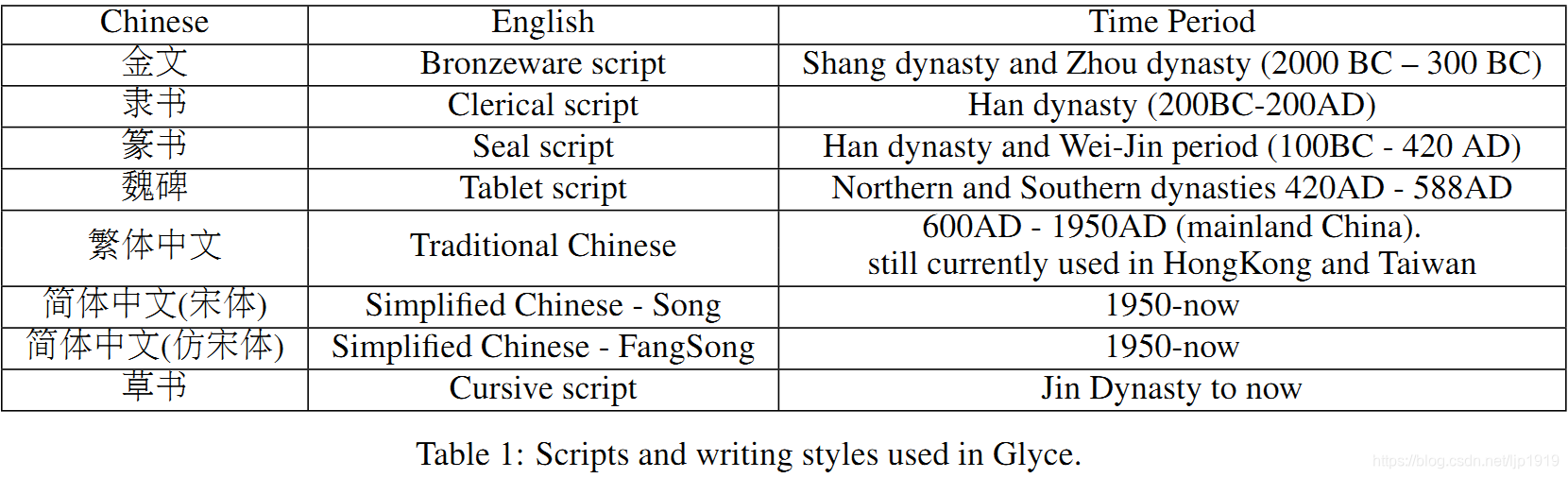
不同历史时期的文字字形也是有很大差异,这有助于模型整合来自不同来源的象形信息;不同的书写风格能够提升模型的泛化能力。这两种策略类似于计算机视觉中广泛使用的数据增强策略。
2.2 The Tianzige-CNN Structure for Glyce
直接将CNNs应用于本文的数据集中,效果是很差的,其原因之前已经分析过了。(1)图像尺寸不同。ImageNet是800*600,而本文数据集只有12*12。
(2)缺乏训练样本。ImageNet的数据集是千万级,而中文字符只有1W左右。为解决上述2个问题,本文为中文字符量身定制Tianzige-CNN,如Figure 2所示:
田字格是中国书法的传统形式,由4个方格组成,类似汉字中的"田"字。田字格主要用于汉字的初学书写阶段,对于初学汉字的书写大有裨益。输入的图像先输入到一个卷积size=5的卷积层,输出通道尺寸为1024,据此捕获低阶的象形特征。再输入到卷积核size=4的最大池化层,用以特征映射并将分辨率从8*8降低到田字格的。田字格的结构能够表示出中文字符之间偏旁部首的分布及其汉字的书写顺序。实验证明田字格的结构在抽取字符含义上具体重大意义。最后,再田字格的输出输入到一个卷积操作中,完成最终的输出。这里的卷积操作,用的是分组卷积[Krizhevsky et al., 2012, Zhang et al., 2017],分组卷积核比常见的卷积核更小,因此不太可能过度拟合。 本文模型从单字体调整到适用多字体也很简单,仅需要简单地将输入从2D(即)变为3D(即),其中表示字体大小。
2.3 图像分类作为辅助目标
为防止过拟合,引入一个图像分类的辅助任务。将从CNNs得到的字形嵌入输入到一个图像分类器,以预测其所对应的charID。假设图像的label是,则图像分类任务的训练目标如下:
表示待处理的具体任务task的目标函数,比如语言建模任务,分词任务或者机器阅读理解任务等。再将和进行线性组合,所以最终的训练目标函数:
其中控制具体任务目标和辅助图像分类任务目标函数之间的比重。是关于epcohs迭代次数的一个函数:,其中表示初始值,表示衰减值。这意味着图像分类任务的目标函数的影响随着训练的进行是不断减弱的,直观上的解释是早期的训练阶段,需要从图像分类任务中获取更多校准。引入图像分类任务作为训练目标其实是模拟的多任务学习。
2.4 联合Glyph的信息和BERT
字形嵌入是可以直接输入到下游模型,比如RNNs、LSTMs或者Transformers。鉴于预训练模型在多个NLP任务上战绩卓越,本文也探索了BERT和字形嵌入的结合。这种策略有可能赋予模型双方优势,包括字形信息和大规模的预训练。Figure 3展示了本文是如何将这二者进行结合的。该模型由4层组成:BERT层、glyph层(即字形层)、Glyce-BERT层和任务输出层。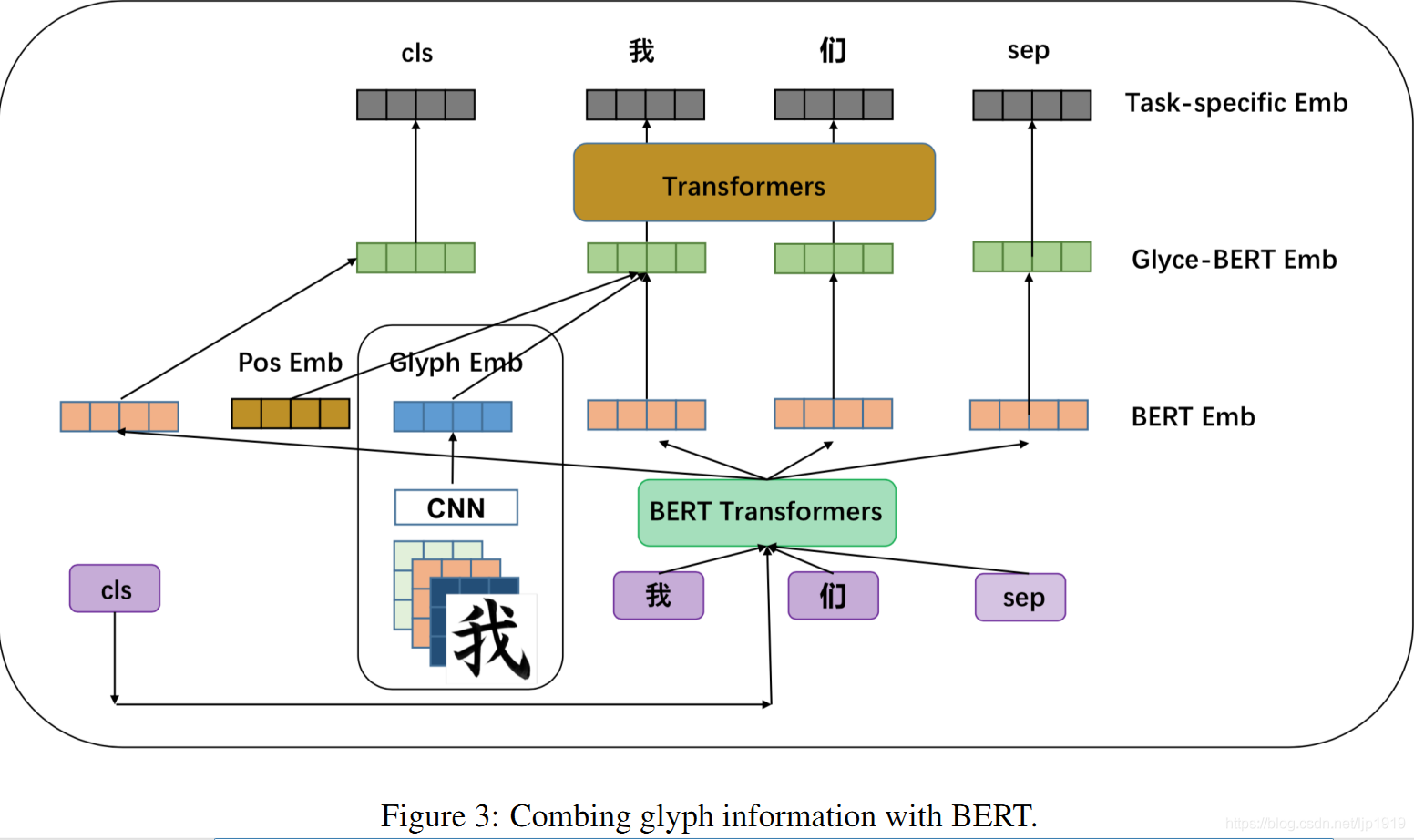
BERT层:
每个输入的句子以预定义的特殊token CLS作为起始,以预定义的特征token SEP作为句子结尾。给定预训练的BERT模型,利用BERT计算得到每个句子的嵌入,以BERT transformer的最后一层的输出作为当前token的表征。
**Glyph Layer:**即tianzige-CNNs
Glyce-BERT layer:
在字形嵌入glyph embeddings前面加入位置嵌入。再把加入了位置嵌入的字形嵌入与BERT嵌入拼接,最终得到满Glyce表征(full Glyce representation)。该层也就是实现Glyph和BERT表征的结合。
Task-specific output layer:
Glyce-BERT表征有位置信息,也有了来自BERT的上下文语境信息。此外,还需要一个额外的上下文模型以编码带有上下文语境
的字形表征。为此,本文选用了一个多层transformers。transformers的输出表征输入到预测层。值得一提的是,特殊token CLS和 SEP的位置表征在最后的下游任务嵌入层仍旧是保留的。
3. 任务
本章节将介绍如何将字形嵌入用于具体的NLP任务中。在最初的字形嵌入版本中,字形嵌入glyph embeddings仅仅简单地被当做一种字符嵌入,然后输入到顶层如RNNs、CNNs或其他更复杂的模型中。但是本文的模型此时已经引入了BERT,所以需要在不同场景特殊处理字形嵌入和预训练嵌入。
基于Glyce-BERT处理不同任务如Figure 4所示: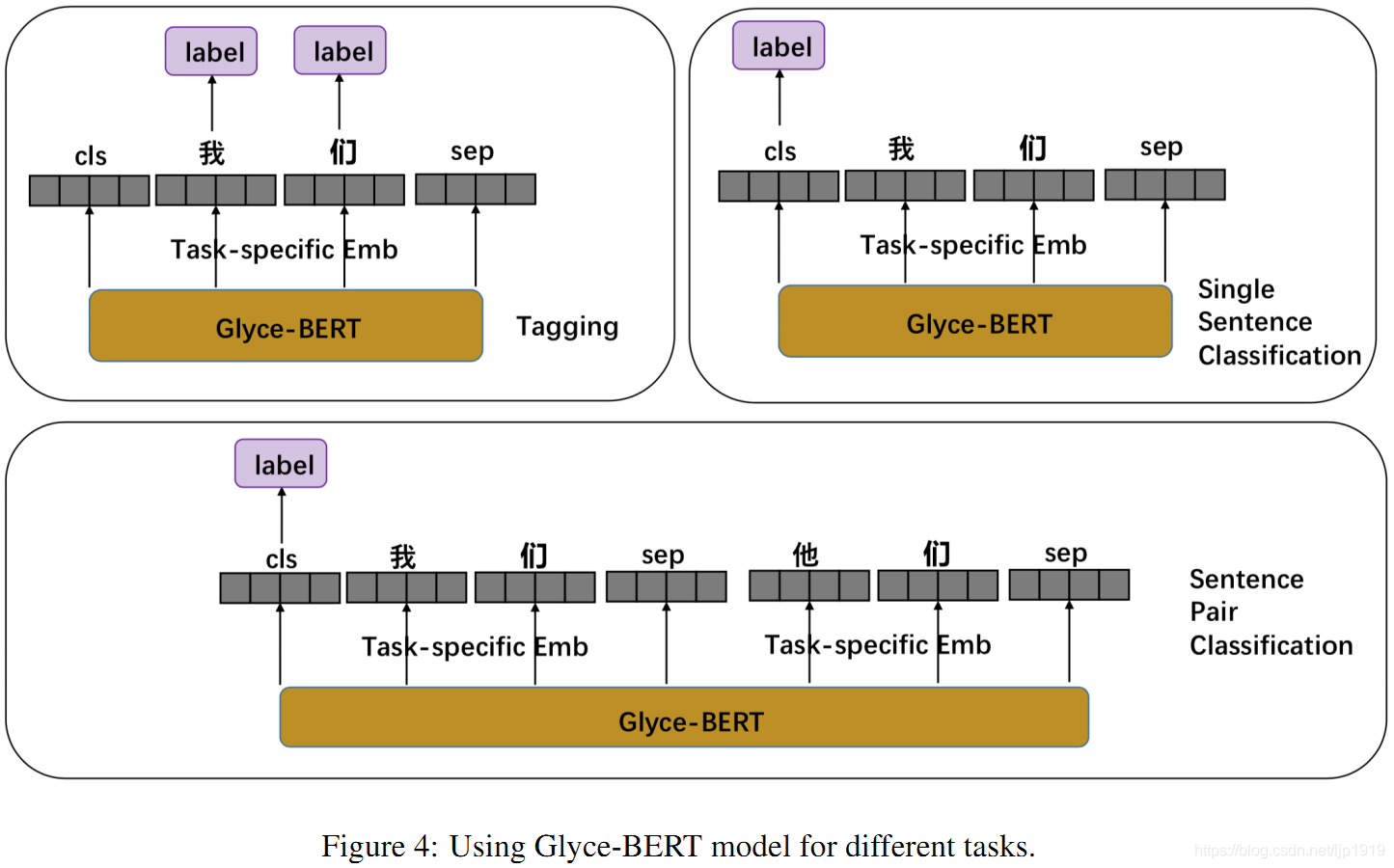
3.1 序列标注任务
命名实体实体(NER)、中文分词(CWS)和词性标注(POS)任务,都可以视为字符级的序列标注任务。对于这些任务,需要对每个字符预测一个label。当使用Glyce-BERT模型时候,只需要将task-specific layer的输出再输入到CRF模型预测label即可。
3.2 单句分类
这里的单句分类是指一个句子只预测一个label。在BERT模型中,将最后一层CLS token的表征再输入到softmax层预测label。
本文的Glyce-BERT也是采用类似策略,将task-specific layer中CLS token的表征输入到softmax层以预测label。
3.3 句子对分类
句对分类任务如SNIS[Bowman et al., 2015],需要处理两个句子之间的相互作用,再预测一个label。在BERT中,将句子对拼接起来,起始一个CLS token,句子中间间隔一个 SEP token,句子结尾再接一个 SEP token。具体形如:。再将拼接后的结果输入到BERT,其中CLS token在BERT中最后一层的表征再输入到softmax中预测label。本文的 Glyce-BERT也采用类似策略:先后输入到BERT layer, Glyph layer, Glyce-BERT layer和 task-specific output layer。再将task-specific层中CLS token的表征输入到softmax层预测label。
4. 实验
为了方便同类比较,本文在dev data上用对baseline和Glyce-BERT进行网格参数搜索。
4.1 序列标注
NER:
采用的数据集:OntoNotes, MSRA,Weibo and resume datasets
CWS:
采用的数据集:PKU, MSR, CITYU 和 AS
POS:
采用的数据集:CTB5, CTB9 和 UD1 (Universal Dependencies)
上述三种任务的baseline方法都是:Lattice-LSTMs 和 CRF+LSTM
详情结果参考Table 2,3和4。对比非BERT模型时候发现,Lattice-Glyce在所有任务中均是最优。BERT模型超出所有非BERT模型,而Glyce-BERT又超出BERT,且刷新全部数据集的记录。这说明,引入字形信息的有效性。
Table 2: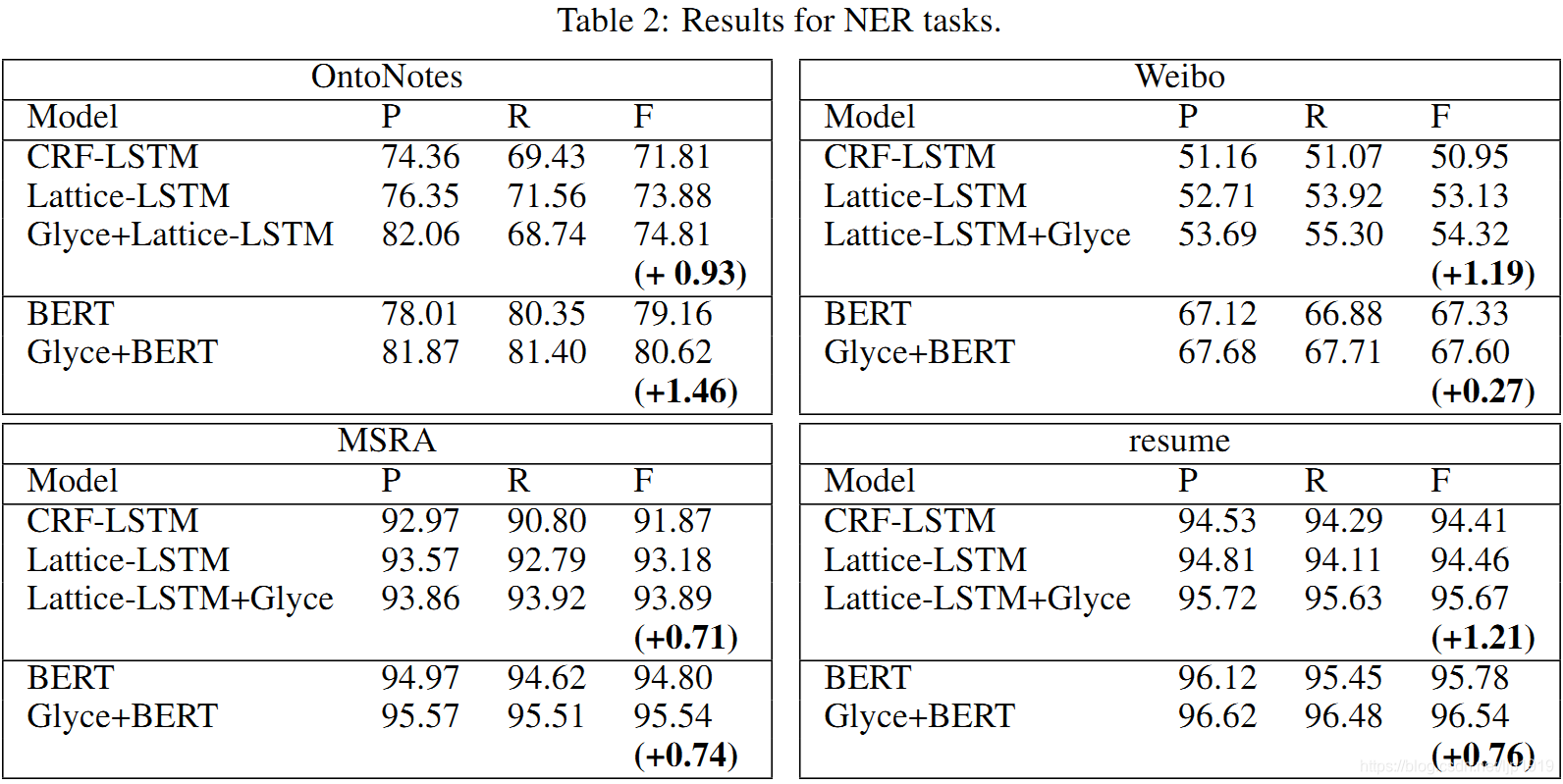
Table 3: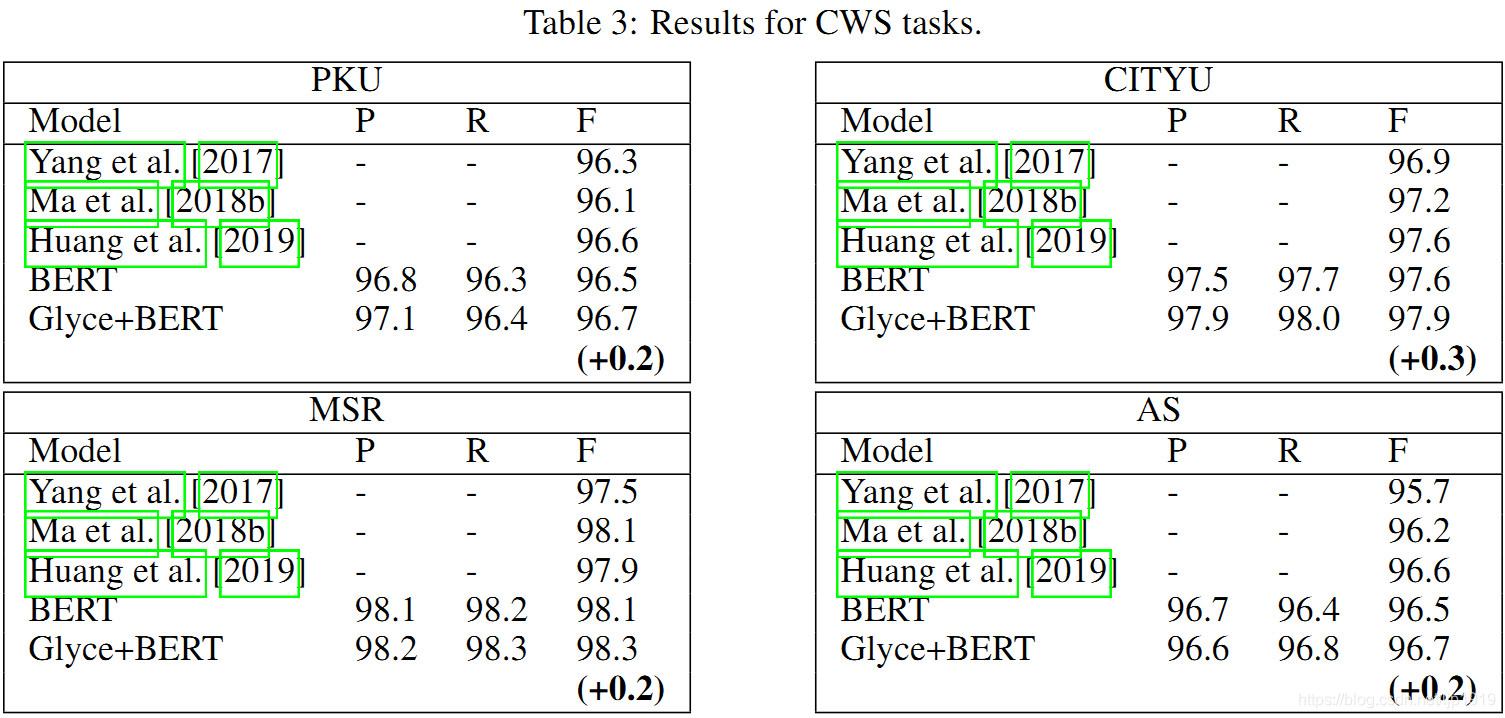
对于CWS,F1 值在 BERT 上涨幅较少,这是由 CWS 本身的难度和数据集较小导致的。
Table 4: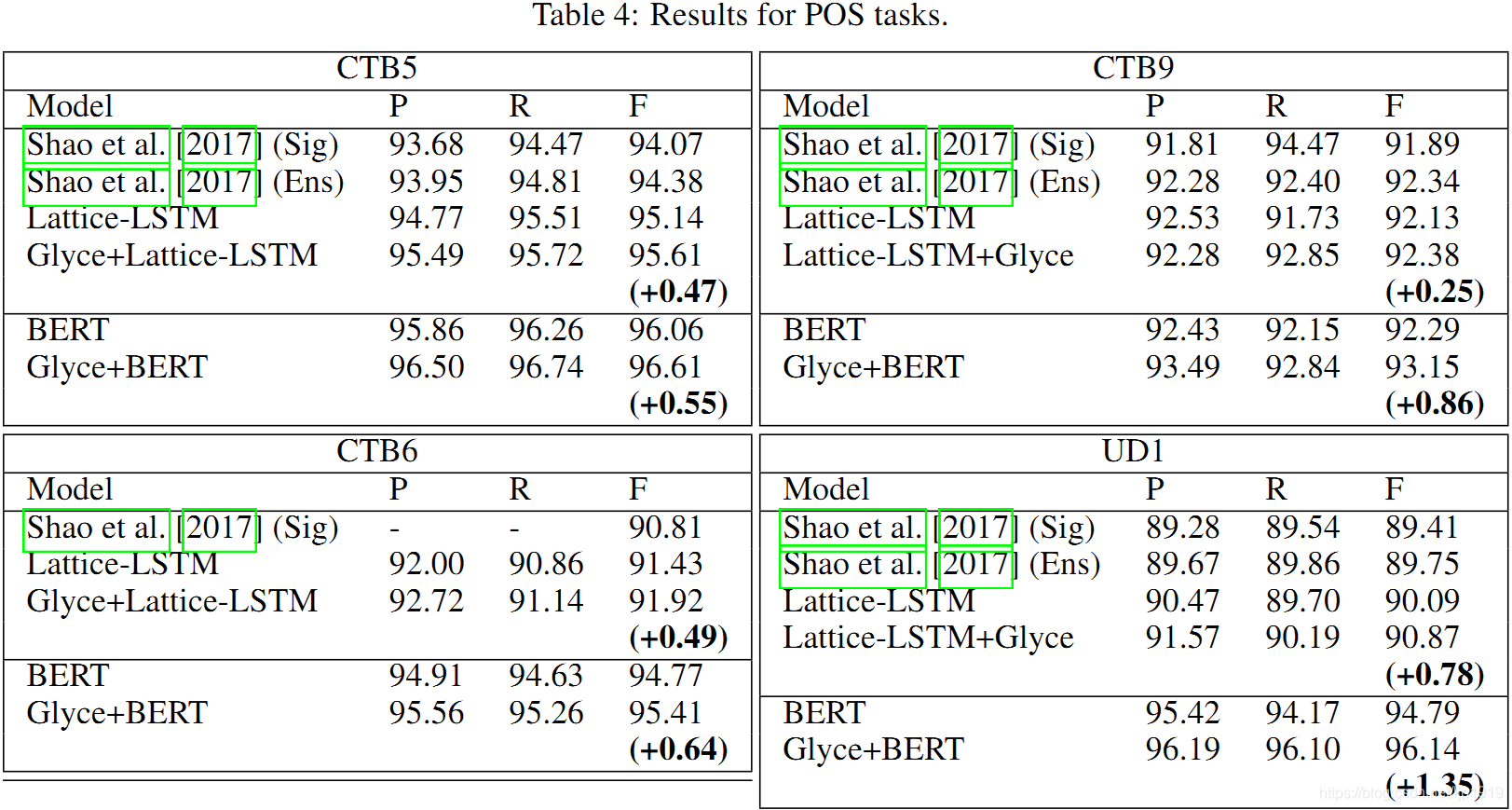
加入 Glyce 后,对 Lattice-LSTM 和 BERT 都有相应的提升。
4.2 句子对分类
采用的数据集:BQ Corpus(2分类)、LCQMC(2分类)、XNLI(3分类)、NLPCC-DBQA(2分类)
baseline:bilateral multi-perspective matching model(BiMPM)[Wang et al., 2017]和Glyce+BiMPM
详细对比结果见于Table 5: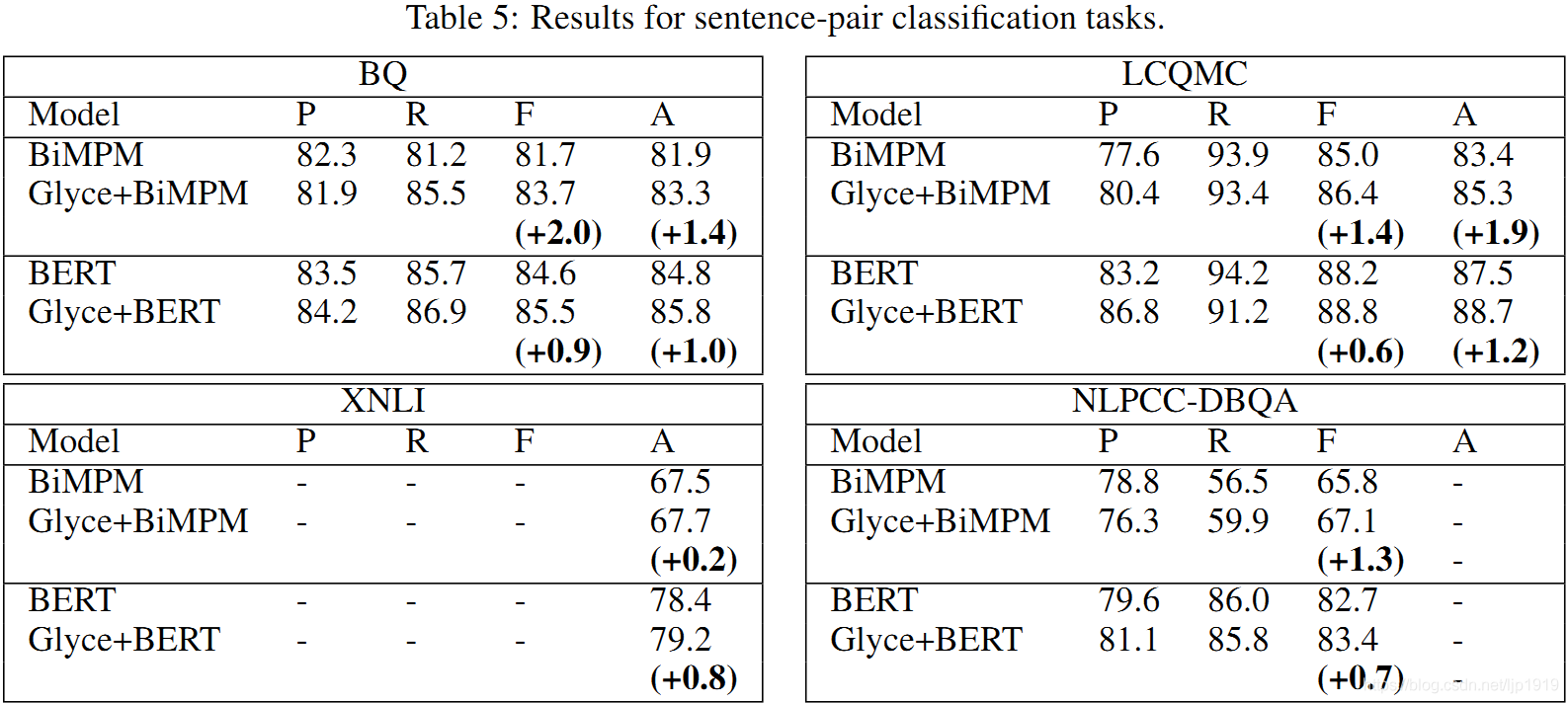
可以看出Glyce+BiMPM优于BiMPM,在所有非BERT模型中取得最佳结果。BERT优于所有非BERT模型,Glyce+BERT结果全场最佳,并刷新了4个数据集的记录。
4.3 单句分类
采用的数据集:ChnSentiCorp、Fudan、Ifeng
baseline:LSTM
不同模型在各个数据集上的对比见于Table 6: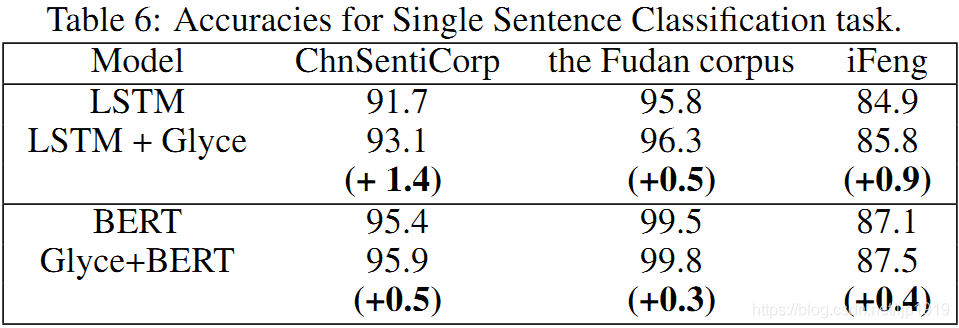
可以看出引入字形信息的有效性。
4.4 依存分析和语义角色标注
依存句法分析所用的数据集:CTB5.1
语义角色标注所用的数据集:CoNLL-2009
具体的对比结果:
在中文 SRL 和中文依存句法分析上,相比之前的最优结果(未使用 BERT,因为BERT在这两个任务上毫无竞争力,所以原文就没有列出),使用 Glyce 之后能取得接近 1 个点的提升。
5. 消融研究
本章节主要讨论Glyce-BERT模型的影响因素,包括训练策略、模型架构、图像分类这个辅助任务。使用句对分类任务中的LCQMC数据集用以说明。
5.1 训练策略
首先探讨几种不同的训练策略:
(1)BERT-Glyph-Joint:首先微调BERT,再固定 BERT,微调 Glyce,最后综合两者微调直到收敛
(2)Glyph-Joint:首先固定BERT,微调 Glyce层,然后再将BERT和Glyce层联合微调,直至收敛
(3)Joint:直接训练 BERT 和 Glyce直到收敛
下图是几种训练策略的实验结果,可以看到,BERT-Glyph-Joint 的训练策略效果最佳,而 Joint 效果最差。这是因为,BERT 是经过预训练的,而 Glyce 是随机初始化的。训练集较少的时候,如此策略在早期训练阶段会使BERT层-glyph层随机初始化失配,最终使得性能下降。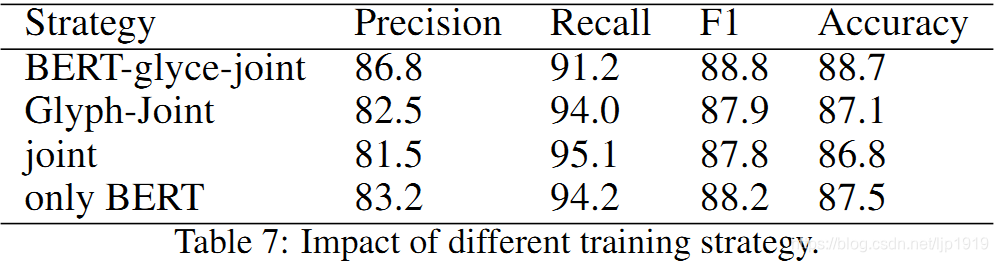
5.2 图像分类的训练目标
Table 8是有无图像分类损失对最终结果的影响。可以看到,加上图像分类损失后,F1 值提高了 0.4,Accuracy 提高了 0.8。使用图像损失,是为了避免小数据(只有大概10000 个中文字符)下的过拟合。
5.3 特定任务的输出层
Glyce-BERT的task-specific output layer使用的是两层 Transformer Block,实验过程中将Transformer 替换为 BiLSTM、CNN 与 BiMPM 以研究其影响。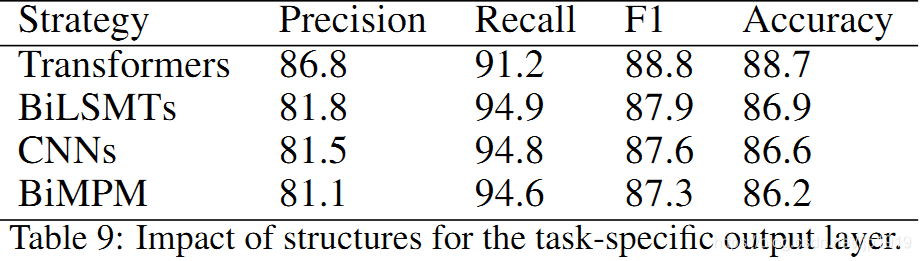
显然,Transformer 结果显著更优,这是因为 BERT 和 Transformer 结构更加匹配。
5.4 CNN结构
最后,分析 CNN 结构的影响。在对比了 [Kim, 2014]、[He, 2016] 和 Vanilla-CNN 后,结果如Table 10所示。可以看到,使用 Tianzige-CNN 能显著提高 F1 值。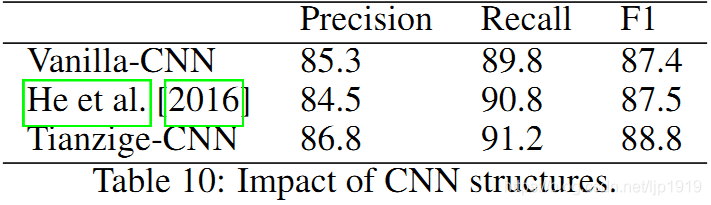
6. 结论
本文提出了Glyce和用于表征中文字符的Glyph-vectors。Glyce将中文字符视为图像,并使用Tianzige-CNN抽取字符语义。Glyce是一种面向表意文字的字符建模通用方案。其通用性如词嵌入,可以将Glyce集成到已有的深度学习系统中。
来源:https://blog.csdn.net/ljp1919/article/details/100775997