Spark SQL的发展
HDFS -> HIVE
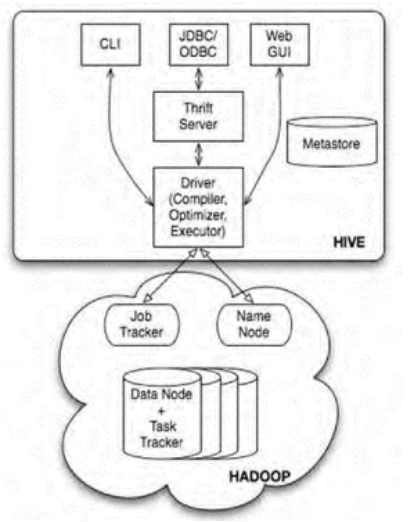
由于Hadoop在企业生产中的大量使用,HDFS上积累了大量数据,为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生。Hive的原理是将SQL语句翻译成MapReduce计算。
HIVE -> SHARK
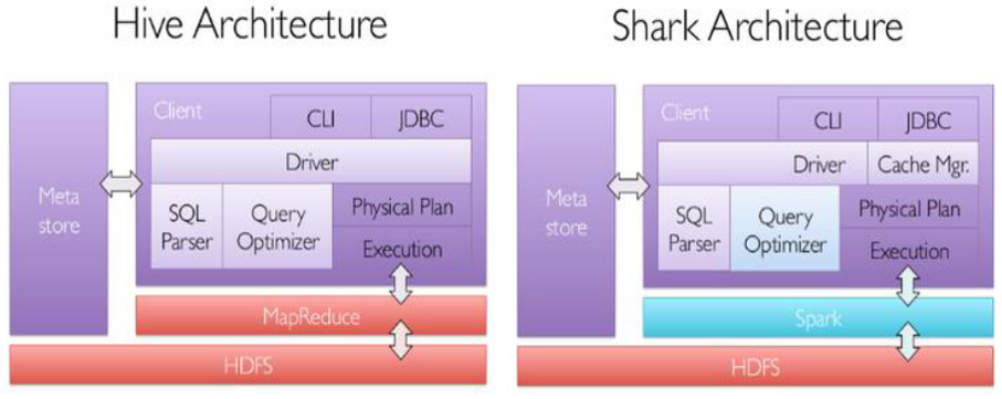
MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低了运行效率,为了提供SQL-on-Hadoop的效率,Shark出现了。
Shark是伯克利AMPLab实验室Spark生态环境的组件之一,它修改了Hive中的内存管理、物理计划和执行三个模块,使得SQL语句直接运行在Spark上,从而使得SQL查询的速度得到10-100倍的提升。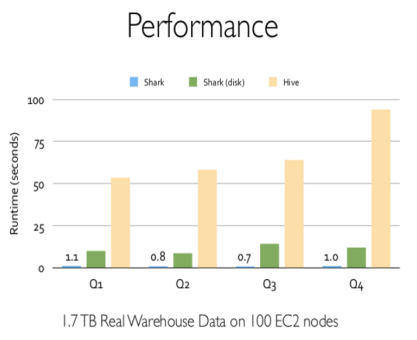
SHARK -> SPARK SQL
2014年6月1日,Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放sparkSQL项目上,至此,Shark的发展画上了句号。
随着Spark的发展,Shark对于Hive的太多依赖制约了Spark的One Stack rule them all的方针,制约了Spark各个组件的相互集成,同时Shark也无法利用Spark的特性进行深度优化,所以决定放弃Shark,提出了SparkSQL项目。
随着Shark的结束,两个新的项目应运而生:SparkSQL和Hive on Spark。其中SparkSQL作为Spark生态的一员继续发展,而不再受限于Hive,只是兼容Hive;而Hive on Spark是一个Hive的发展计划,该计划将Spark作为Hive的底层引擎之一,也就是说,Hive将不再受限于一个引擎,可以采用Map-Reduce、Tez、Spark等引擎。
SparkSQL优势
SparkSQL摆脱了对Hive的依赖性,无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
1、数据兼容方面
不但兼容Hive,还可以从RDD、parquet文件、JSON文件中获取数据,未来版本甚至支持获取RDBMS数据以及cassandra等NOSQL数据;
2、性能优化方面
除了采取In-Memory Columnar Storage、byte-code generation等优化技术外、将会引进Cost Model对查询进行动态评估、获取最佳物理计划等等;
3、组件扩展方面
无论是SQL的语法解析器、分析器还是优化器都可以重新定义,进行扩展;
Spark SQL的性能优化
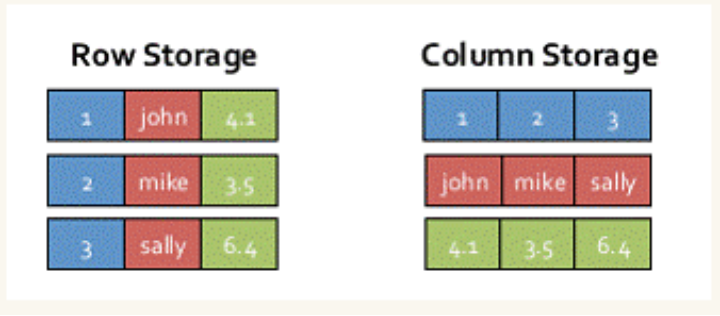
内存列存储(In-Memory Columnar Storage)
对于内存列存储来说,将所有原生数据类型的列采用原生数组来存储,将Hive支持的复杂数据类型(如array、map等)先序列化后并接成一个字节数组来存储。
这样,每个列创建一个JVM对象,从而导致可以快速地GC和紧凑的数据存储。
额外的,还可以用低廉CPU开销的高效压缩方法来降低内存开销。
更有趣的是,对于分析查询中频繁使用的聚合特定列,性能会得到很大的提高,原因就是这些列的数据放在一起,更容易读入内存进行计算。
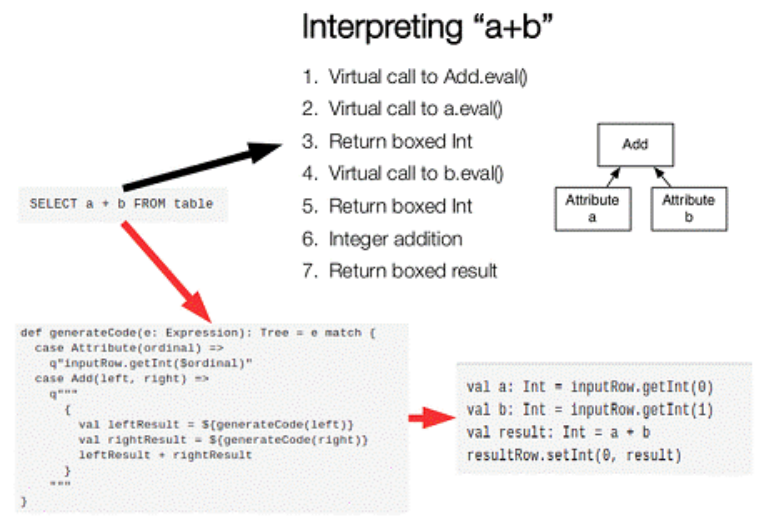
字节码生成技术(bytecode generation,即CG)
在数据库查询中有个昂贵的操作就是查询语句中的表达式,主要是由JVM的内存模型引起的。如SELECT a+b FROM table,这个查询里如果采用通用的SQL语法途径去处理,会先生成一个表达树,会多次设计虚函数的调用,这会打断CPU的正常流水线处理,减缓执行速度。
spark -1.1.0在catalyst模块的expressions增加了codegen模块,如果使用动态字节码生成技术,Spark SQL在执行物理计划时,会对匹配的表达式采用特定的代码动态编译,然后运行。
Scala代码的优化
Spark SQL在使用Scala语言编写代码时,应尽量避免容易GC的低效代码。尽管增加了编写代码的难度,但对于用户来说,还是使用了统一的接口,让开发在使用上更加容易。
Spark SQL的运行架构
SparkSQL有两个分支,sqlContext和hiveContext,sqlContext现在只支持SQL语法解析器;hiveContext现在支持SQL语法解析器和hivesql语法解析器,默认为hiveSQL语法解析器,用户可以通过配置切换成SQL语法解析器,来运行hiveSQL不支持的语法。

Spark SQL由Core、Catalyst、Hive、Hive-ThriftServer四部分构成:
1.Core: 负责处理数据的输入和输出,如获取数据,查询结果输出成DataFrame等
2.Catalyst: 负责处理整个查询过程,包括解析、绑定、优化等
3.Hive: 负责对Hive数据进行处理
4.Hive-ThriftServer: 主要用于对hive的访问
SparkSQL有两个分支,sqlContext和hiveContext,sqlContext现在只支持SQL语法解析器;hiveContext现在支持SQL语法解析器和hivesql语法解析器,默认为hiveSQL语法解析器,用户可以通过配置切换成SQL语法解析器,来运行hiveSQL不支持的语法。
Spark SQL语句的执行顺序
1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行的;
3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4.计划执行(Execute),按Operation-->Data Source-->Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运
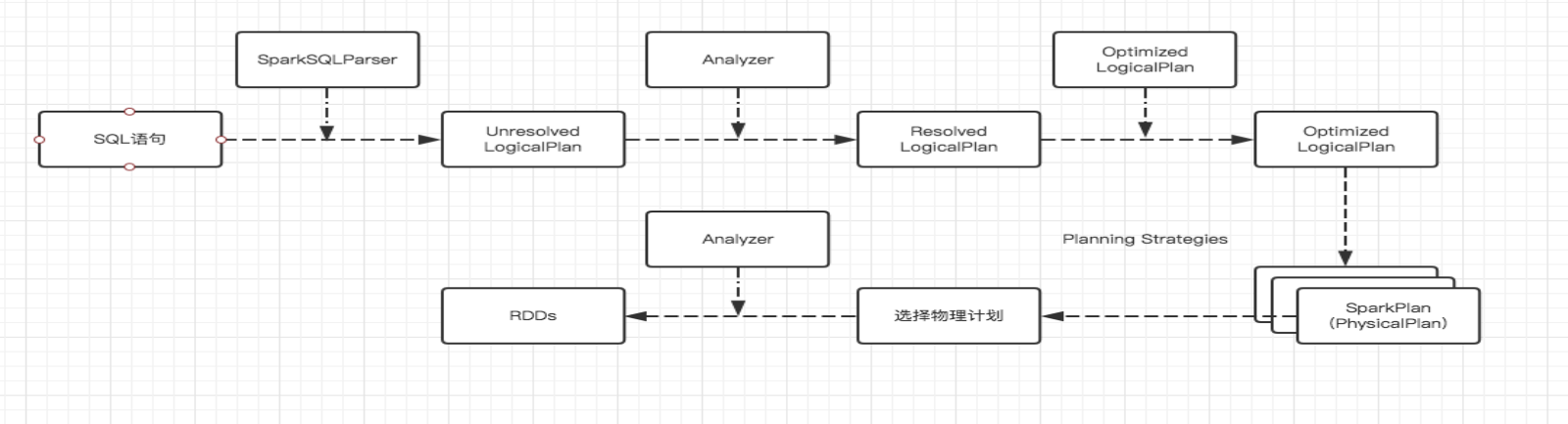
Spark SQL的运行原理
1,使用SessionCatalog保存元数据
在解析SQL语句之前,会创建SparkSession,或者如果是2.0之前的版本初始化SQLContext,SparkSession只是封装了SparkContext和SQLContext的创建而已。会把元数据保存在SessionCatalog中,涉及到表名,字段名称和字段类型。创建临时表或者视图,其实就会往SessionCatalog注册。
2,解析SQL使用ANTLR生成未绑定的逻辑计划
当调用SparkSession的SQL或者SQLContext的SQL方法,我们以2.0为准,就会使用SparkSqlParser进行解析SQL。使用的ANTLR进行词法解析和语法解析。它分为2个步骤来生成Unresolved LogicalPlan:
词法分析:Lexical Analysis, 负责将token分组成符号类。
构建一个分析树或者语法树AST。
3,使用分析器Analyzer绑定逻辑计划
在该阶段,Analyzer会使用Analyzer Rules,并结合SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划。
4,使用优化器Optimizer优化逻辑计划
优化器也是会定义一套Rules,利用这些Rule对逻辑计划和Exepression进行迭代处理,从而使得树的节点进行合并和优化。
5,使用SparkPlanner生成物理计划
SparkSpanner使用Planning Strategies,对优化后的逻辑计划进行转换,生成可以执行的物理计划SparkPlan.
6,使用QueryExecution执行物理计划
此时调用SparkPlan的execute方法,底层其实已经再触发JOB了,然后返回RDD。
Spark SQL的运行架构
TreeNode
逻辑计划、表达式等都可以用tree来表示,它只是在内存中维护,并不会进行磁盘的持久化,分析器和优化器对树的修改只是替换已有节点。
TreeNode有2个直接子类,QueryPlan和Expression。QueryPlan下又有LogicalPlan和SparkPlan. Expression是表达式体系,不需要执行引擎计算而是可以直接处理或者计算的节点,包括投影操作,操作符运算等
Rule & RuleExecutor
Rule就是指对逻辑计划要应用的规则,以到达绑定和优化。他的实现类就是RuleExecutor。优化器和分析器都需要继承RuleExecutor。
每一个子类中都会定义Batch、Once、FixPoint. 其中每一个Batch代表着一套规则,Once表示对树进行一次操作,FixPoint表示对树进行多次的迭代操作。
RuleExecutor内部提供一个Seq[Batch]属性,里面定义的是RuleExecutor的处理逻辑,具体的处理逻辑由具体的Rule子类实现。
Catalyst优化器
SparkSQL1.1总体上由四个模块组成:core、catalyst、hive、hive-Thriftserver:
core处理数据的输入输出,从不同的数据源获取数据(RDD、Parquet、json等),将查询结果输出成schemaRDD;
catalyst处理查询语句的整个处理过程,包括解析、绑定、优化、物理计划等,说其是优化器,还不如说是查询引擎;
hive对hive数据的处理
hive-ThriftServer提供CLI和JDBC/ODBC接口
在这四个模块中,catalyst处于最核心的部分,其性能优劣将影响整体的性能。由于发展时间尚短,还有很多不足的地方,但其插件式的设计,为未来的发展留下了很大的空间。
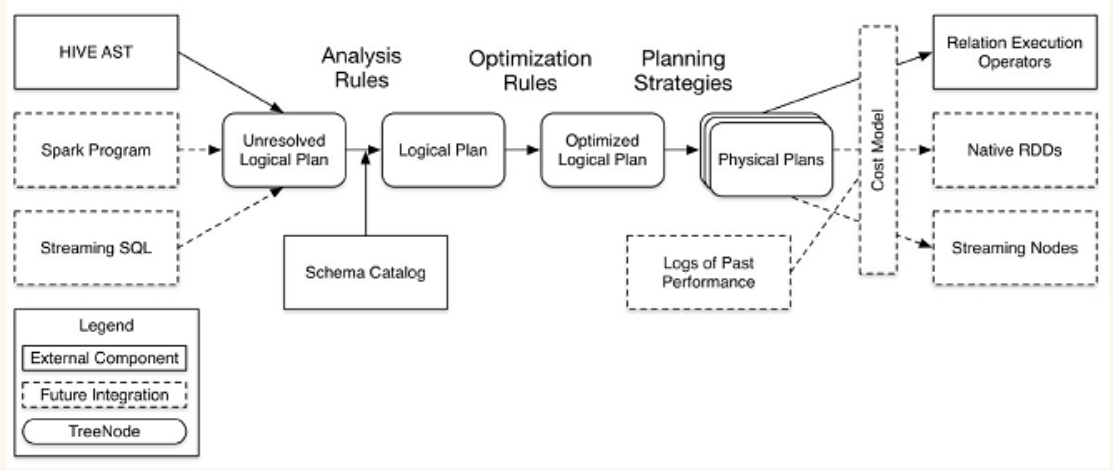
从上图看,catalyst主要的实现组件有:
1.sqlParse,完成sql语句的语法解析功能,目前只提供了一个简单的sql解析器;
2.Analyzer,主要完成绑定工作,将不同来源的Unresolved LogicalPlan和数据元数据(如hive metastore、Schema catalog)进行绑定,生成resolved LogicalPlan;
3.optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan;
4.Planner将LogicalPlan转换成PhysicalPlan;、
5.CostModel,主要根据过去的性能统计数据,选择最佳的物理执行计划
这些组件的基本实现方法:
1.先将sql语句通过解析生成Tree,然后在不同阶段使用不同的Rule应用到Tree上,通过转换完成各个组件的功能。
2.Analyzer使用Analysis Rules,配合数据元数据(如hive metastore、Schema catalog),完善Unresolved LogicalPlan的属性而转换成resolved LogicalPlan;
3.optimizer使用Optimization Rules,对resolved LogicalPlan进行合并、列裁剪、过滤器下推等优化作业而转换成optimized LogicalPlan;
4.Planner使用Planning Strategies,对optimized LogicalPlan
执行优化
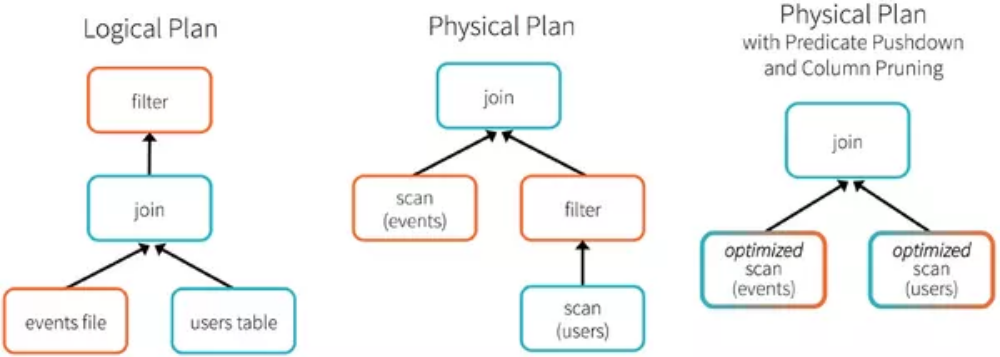
为了说明查询优化,我们来看下图展示的人口数据分析的示例。图中构造了两个DataFrame,将它们join之后又做了一次filter操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为join是一个代价较大的操作,也可能会产生一个较大的数据集。如果我们能将filter下推到 join下方,先对DataFrame进行过滤,再join过滤后的较小的结果集,便可以有效缩短执行时间。而Spark SQL的查询优化器正是这样做的。简而言之,逻辑查询计划优化就是一个利用基于关系代数的等价变换,将高成本的操作替换为低成本操作的过程。
得到的优化执行计划在转换成物 理执行计划的过程中,还可以根据具体的数据源的特性将过滤条件下推至数据源内。最右侧的物理执行计划中Filter之所以消失不见,就是因为溶入了用于执行最终的读取操作的表扫描节点内。
DataFrame初探
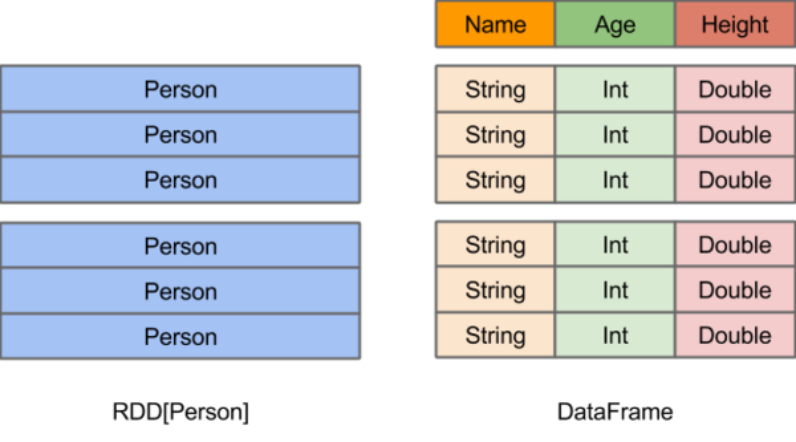
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
DataFrame的特性
能够将单个节点集群上的大小为Kilobytes到Petabytes的数据处理为大型集群。
支持不同的数据格式(Avro,csv,弹性搜索和Cassandra)和存储系统(HDFS,HIVE表,mysql等)。
通过Spark SQL Catalyst优化器(树变换框架)的最先进的优化和代码生成。
可以通过Spark-Core轻松地与所有大数据工具和框架集成。
提供用于Python,Java,Scala和R编程的API。
创建DataFrame
在Spark SQL中,开发者可以非常便捷地将各种内、外部的单机、分布式数据转换为DataFrame。
# 从Hive中的users表构造
DataFrame users = sqlContext.table("users")
# 加载S3上的JSON文件
logs = sqlContext.load("s3n://path/to/data.json", "json")
# 加载HDFS上的Parquet文件
clicks = sqlContext.load("hdfs://path/to/data.parquet", "parquet")
# 通过JDBC访问MySQL comments = sqlContext.jdbc("jdbc:mysql://localhost/comments", "user")
# 将普通RDD转变为
DataFrame rdd = sparkContext.textFile("article.txt") \
.flatMap(lambda line: line.split()) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b) \
wordCounts = sqlContext.createDataFrame(rdd, ["word", "count"]) # 将本地数据容器转变为
DataFrame data = [("Alice", 21), ("Bob", 24)]
people = sqlContext.createDataFrame(data, ["name", "age"]) 使用DataFrame
和R、Pandas类似,Spark DataFrame也提供了一整套用于操纵数据的DSL。这些DSL在语义上与SQL关系查询非常相近(这也是Spark SQL能够为DataFrame提供无缝支持的重要原因之一) 。
# 创建一个只包含"年轻"用户的DataFrame
df = users.filter(users.age < 21)
# 也可以使用Pandas风格的语法
df = users[users.age < 21]
# 将所有人的年龄加1
df.select(young.name, young.age + 1)
# 统计年轻用户中各性别人数
df.groupBy("gender").count()
# 将所有年轻用户与另一个名为logs的DataFrame联接起来
df.join(logs, logs.userId == users.userId, "left_outer")
保存DataFrame
当数据分析逻辑编写完毕后,我们便可以将最终结果保存下来或展现出来。
# 追加至HDFS上的Parquet文件
df.save(path="hdfs://path/to/data.parquet",
source="parquet",
mode="append")# 覆写S3上的JSON文件
df.save(path="s3n://path/to/data.json",
source="json",
mode="append")# 保存为SQL表
df.saveAsTable(tableName="young", source="parquet" mode="overwrite")
# 转换为Pandas DataFrame(Python API特有功能)
pandasDF = young.toPandas()
# 以表格形式打印输出
df.show()
来源:oschina
链接:https://my.oschina.net/u/3728166/blog/3075944