保留版权所有,转帖注明出处
<div class="article-child "><h2>章节</h2><ul><li class="page_item page-item-4067"><a href="https://www.qikegu.com/docs/4067">SciKit-Learn 加载数据集</a></li> <li class="page_item page-item-4071"><a href="https://www.qikegu.com/docs/4071">SciKit-Learn 数据集基本信息</a></li> <li class="page_item page-item-4075"><a href="https://www.qikegu.com/docs/4075">SciKit-Learn 使用matplotlib可视化数据</a></li> <li class="page_item page-item-4080"><a href="https://www.qikegu.com/docs/4080">SciKit-Learn 可视化数据:主成分分析(PCA)</a></li> <li class="page_item page-item-4082"><a href="https://www.qikegu.com/docs/4082">SciKit-Learn 预处理数据</a></li> <li class="page_item page-item-4085"><a href="https://www.qikegu.com/docs/4085">SciKit-Learn K均值聚类</a></li> <li class="page_item page-item-4090"><a href="https://www.qikegu.com/docs/4090">SciKit-Learn 支持向量机</a></li> <li class="page_item page-item-4093"><a href="https://www.qikegu.com/docs/4093">SciKit-Learn 速查</a></li> </ul></div>
主成分分析(PCA)是一种常用于减少大数据集维数的降维方法,把大变量集转换为仍包含大变量集中大部分信息的较小变量集。
减少数据集的变量数量,自然是以牺牲精度为代价的,降维的好处是以略低的精度换取简便。因为较小的数据集更易于探索和可视化,并且使机器学习算法更容易和更快地分析数据,而不需处理无关变量。
总而言之,主成分分析(PCA)的概念很简单——减少数据集的变量数量,同时保留尽可能多的信息。
使用scikit-learn,可以很容易地对数据进行主成分分析:
# 创建一个随机的PCA模型,该模型包含两个组件
randomized_pca = PCA(n_components=2, svd_solver='randomized')
# 拟合数据并将其转换为模型
reduced_data_rpca = randomized_pca.fit_transform(digits.data)
# 创建一个常规的PCA模型
pca = PCA(n_components=2)
# 拟合数据并将其转换为模型
reduced_data_pca = pca.fit_transform(digits.data)
# 检查形状
reduced_data_pca.shape
# 打印数据
print(reduced_data_rpca)
print(reduced_data_pca)
输出
[[ -1.25946586 21.27488217]
[ 7.95761214 -20.76870381]
[ 6.99192224 -9.95598251]
...
[ 10.80128338 -6.96025076]
[ -4.87209834 12.42395157]
[ -0.34439091 6.36555458]]
[[ -1.2594653 21.27488157]
[ 7.95761471 -20.76871125]
[ 6.99191791 -9.95597343]
...
[ 10.80128002 -6.96024527]
[ -4.87209081 12.42395739]
[ -0.34439546 6.36556369]]
随机的PCA模型在维数较多时性能更好。可以比较常规PCA模型与随机PCA模型的结果,看看有什么不同。
告诉模型保留两个组件,是为了确保有二维数据可用来绘图。
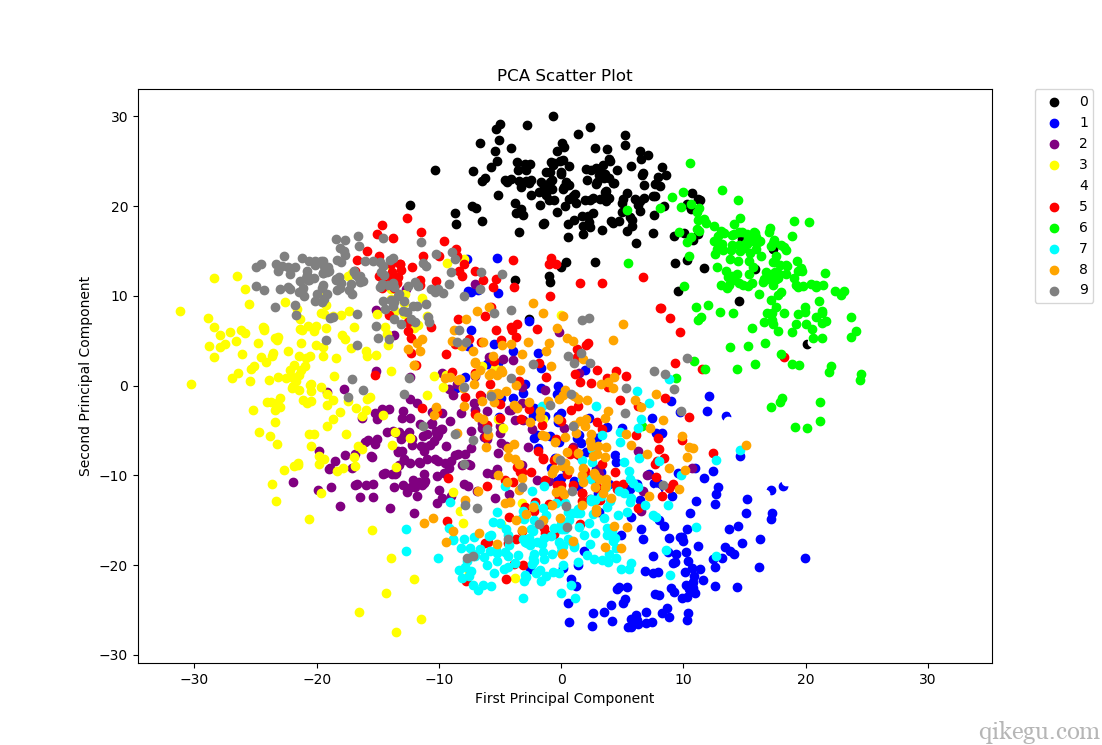
现在可以绘制一个散点图来可视化数据:
colors = ['black', 'blue', 'purple', 'yellow', 'white', 'red', 'lime', 'cyan', 'orange', 'gray']
# 根据主成分分析结果绘制散点图
for i in range(len(colors)):
x = reduced_data_rpca[:, 0][digits.target == i]
y = reduced_data_rpca[:, 1][digits.target == i]
plt.scatter(x, y, c=colors[i])
# 设置图例,0-9用不同颜色表示
plt.legend(digits.target_names, bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)
# 设置坐标标签
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')
# 设置标题
plt.title("PCA Scatter Plot")
# 显示图形
plt.show()
显示:
来源:oschina
链接:https://my.oschina.net/u/4344754/blog/3410782