一、常见问题
1、为什么要分库分表(设计高并发系统的时候,数据库层面该如何设计)?用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?你们是如何对数据库进行垂直拆分或水平拆分。
2、如何设计可以动态扩容的分库分表方案?
3、分库分表之后,ID如何处理。
二、为啥要分库分表
其实,这块肯定是扯到高并发了,因为分库分表一定是为了支撑高并发、数据量大两个问题。而且现在说实话,尤其是互联网公司类的公司面试,基本上都会来这么一下。分库分表如何普通的技术问题,不问实在不行,而如果你不知道那也实在说不过去。
说白了,分库分表是两回事,大家可别搞混了,可能光分库不分表,也可能光分表不分库。都有可能,先给大家抛出一个问题。
随着用户量的增长,每天活跃用户数上千万。每天单表新增数据,多个50万。目前1个表的总容量都已经达到两三千万啦!数据库磁盘容量不断消耗掉,高峰期并打达到了5000-8000。单机系统支撑不到现在。公司业务发展越好,用户就越多,数据量越大,请求量越大。那单个数据库一定扛不住。
假设把MySQL从单机变成了三机。
① MySQL从单机变成了三机,现在可以承受的并发增加了3倍。
② 将原来3千万数据从1个库分到了3个库,每个库就1/3的数据量,数据库服务器的磁盘使用率大大降低。
③ 原来1个单表是3千万数据,一个SQL要花3秒去跑,拆分之后,每个库的每个表就1千万数据,一个SQL花1秒去跑就可以啦。
三、用过哪些分库分表中间件,不同的分库分表中间件都有什么优点和缺点?
比较常见的包括sharding-jdbc、mycat。
1、sharding-jdbc:当当网开源的,属于client层方案。支持分库分表、读写分离、分布式ID生成、柔性事务(最大努力送达形事务、TCC事务)。
2、mycat:基于cobar改造的,属于proxy层方案。支撑的功能非常完善,不断流行的数据库中间件,社区很活跃。
sharding-jdbc这种client层方案的优点在于不用部署,运维成本低。但是如果遇到需要升级啥的需求各个系统都重新升级版本再发布;mycat这种proxy层方案的缺点在于需要部署及运维一套中间件。运维成本高。但是好处在于对各个项目是透明的,如果遇到升级,只需要搞中间件那里就ok。
一般建议中小公司使用sharding-jdbc。client层方案轻便,而且维护成本低,不需要额外增派人手,中小公司系统复杂度会低一些。项目也没那么多。但是中大型公司最好还是选用mycat这类proxy层方案,因为可能大公司系统和项目非常多。团队很大,人员充足,最好专门弄个人来研究和维护mycat。然后大量项目直接透明使用。
四、你们具体是如何对数据库进行垂直拆分或水平拆分
1、垂直拆分:

把常用的字段放在一张表,把不常用的字段放在另一张表。
其实这个挺常见的,把一个大表拆开。订单表、订单支付表、订单商品表。
2、水平拆分:
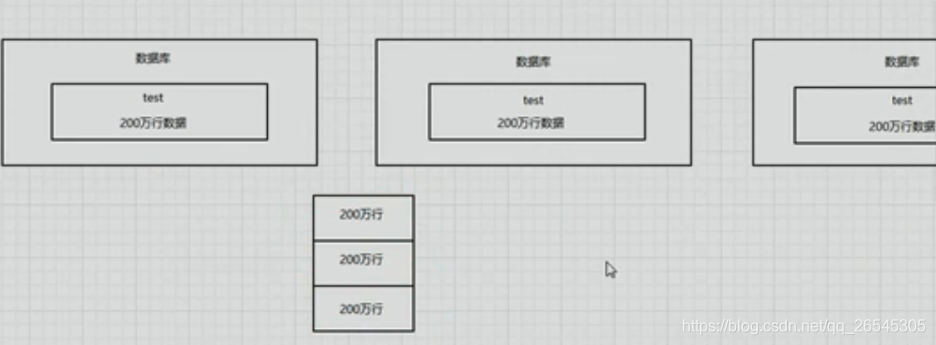

分成3个库,1个库里4个表。每个表的数据量从原来的单表600万,变成每个表50万。SQL的执行效率可能会增加好几倍。单库最高承受2000/s的QPS,3个库最高承受6000/s的QPS。假设原来单个库600万数据。占据了600M的磁盘空间。现在单库200万数据,仅仅占用200MB的磁盘空间。
一般来说,分库分表其实就是指的水平拆分。垂直拆分一般做业务涉及的时候就进行了拆分。一般是按照某个关键字段取余。
五、如何设计可以动态扩容的分库分表方案
1、停机扩容
这个方案和停机迁移一样,步骤几乎一致。唯一的点就是那个导数的工具。是吧现有表里的数据查出来插入到新表里去,但是最好别这么晚,因为不靠谱。既然分库分表就说明数据量实在太大了。可能多达几亿条、甚至几十亿。这么玩,可能会出问题。
从单库单表迁移到分库分表,数据量并不是很大,单表最大也就两三千万。写个工具,多弄几台机器并行跑。1个小时数据就导完了。
2、优化后的方案
01_分库分表的扩容方案
一开始上来就是32个库,每个库32个表。1024张表。这个分法,第一,基本上国内的互联网公司基本上是够用了。第二,无论是并发支撑还是数据量支撑都没问题。
每个库正常承载的并发量是1000,那么32个库就可以承载32*1000=32000的写并发。如果每个库承载1500的写并发,32*1500=48000,接近5万每秒的写入并发。前面再加一个MQ,削峰,每秒写入MQ8万条数据,每秒消费5万条数据。
1024张表,假设每个表放500万数据,在MySQL里面可以放50亿条数据。5万/s的写并发,总共50亿条数据,对于大部分公司而言足够了。
谈及分库分表的扩容,第一次分库分表就给他分个够。32个库,1024张表。
来源:oschina
链接:https://my.oschina.net/u/4334778/blog/4536468