上一章分析了mybatis的源码的日志模块,像我们经常说的mybatis一级缓存,二级缓存,缓存究竟在底层是怎样实现的。此次开始分析缓存模块
1. 源码位置,mybatis源码包位于org.apache.ibatis.cache下,如图
2. 先从org.apache.ibatis.cache下的cache接口开始
// 缓存接口
public interface Cache {
// 获取缓存ID
String getId();
// 放入缓存
void putObject(Object key, Object value);
// 获取缓存
Object getObject(Object key);
// 移除某一缓存
Object removeObject(Object key);
// 清除缓存
void clear();
// 获取缓存大小
int getSize();
// 获取锁
ReadWriteLock getReadWriteLock();
}mybatis提供了自定义的缓存接口,功能通俗易懂,没什么好解释的。有接口,必然有实现,看一下缓存接口的基本实现类PerpetualCache,所在路径为org.apache.ibatis.cache.impl下。
public class PerpetualCache implements Cache {
// 缓存的ID
private String id;
// 使用HashMap充当缓存(老套路,缓存底层实现基本都是map)
private Map<Object, Object> cache = new HashMap<Object, Object>();
// 唯一构造方法(即缓存必须有ID)
public PerpetualCache(String id) {
this.id = id;
}
// 获取缓存的唯一ID
public String getId() {
return id;
}
// 获取缓存的大小,实际就是hashmap的大小
public int getSize() {
return cache.size();
}
// 放入缓存,实际就是放入hashmap
public void putObject(Object key, Object value) {
cache.put(key, value);
}
// 从缓存获取,实际就是从hashmap中获取
public Object getObject(Object key) {
return cache.get(key);
}
// 从缓存移除
public Object removeObject(Object key) {
return cache.remove(key);
}
// hashmap清除数据方法
public void clear() {
cache.clear();
}
// 暂时没有其实现
public ReadWriteLock getReadWriteLock() {
return null;
}
// 缓存是否相同
public boolean equals(Object o) {
if (getId() == null) throw new CacheException("Cache instances require an ID.");
if (this == o) return true; // 缓存本身,肯定相同
if (!(o instanceof Cache)) return false; // 没有实现cache类,直接返回false
Cache otherCache = (Cache) o; // 强制转换为cache
return getId().equals(otherCache.getId()); // 直接比较ID是否相等
}
// 获取hashCode
public int hashCode() {
if (getId() == null) throw new CacheException("Cache instances require an ID.");
return getId().hashCode();
}
}
如上分析,mybatis的基本缓存实现类其实就是内部维护了一个HashMap,通过对HashMap操作来实现基本的功能。但需要注意的是,判断两个缓存是否相等,是比较的缓存ID是否相等。看Cache otherCache = (Cache) o;也就是说缓存接口可能有多种实现,也确实如此。PerpetualCache只提供了缓存的基本实现功能,但一看HashMap就是不安全的类,多线程下肯定会出问题。又比如说我想这个缓存有固定大小,缓存过期策越为先进先出或者LRU功能等。myabtis肯定想到这点,查看org.apache.ibatis.cache.decorators包。看名字就知道用到了装饰者模式。查看包下的类,如SynchronizedCache为缓存保障了线程安全,LruCache定义了缓存的过期策略为淘汰最近最少访问的数据,LoggIngCache提供了日志打印功能。用户想让自己的缓存具备什么功能,就使用这些装饰者类进行装饰。
3. 分析缓存装饰类SynchronizedCache
// 在操作前加锁,保证线程安全
@Override
public synchronized int getSize() {
return delegate.getSize();
}
@Override
public synchronized void putObject(Object key, Object object) {
delegate.putObject(key, object);
}
@Override
public synchronized Object getObject(Object key) {
return delegate.getObject(key);
}
@Override
public synchronized Object removeObject(Object key) {
return delegate.removeObject(key);
}
@Override
public synchronized void clear() {
delegate.clear();
}很简单。就是在方法前使用synchronized加锁,保证线程安全。
4. 分析缓存装饰类LruCache
介绍LruCache前,先介绍下Lru的实现,Lru是很常用的淘汰策略,意为最近最少使用的对象。查看LruCache,发现内部使用了LinkedHashMap,熟悉LinkedHashMap的伙伴应该知道了。我们一般手写LRU功能就是通过复写LinkedHashMap的方法来实现,LruCache也一样。先大致了解下LinkedHashMap。
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>LinkedHashMap继承HashMap类,实际上就是对HashMap的一个封装。
// 内部维护了一个自定义的Entry,集成HashMap中的node类
static class Entry<K,V> extends HashMap.Node<K,V> {
// linkedHashmap用来连接节点的字段,根据这两个字段可查找按顺序插入的节点
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}查看LinkedHashMap构造方法,具体访问顺序见下文分析
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
// 调用HashMap的构造方法
super(initialCapacity, loadFactor);
// 访问顺序维护,默认false不开启
this.accessOrder = accessOrder;
} 引入两张图来理解下HashMap和LinkedHashMap

以上时HashMap的结构,采用拉链法解决冲突。LinkedHashMap在HashMap基础上增加了一个双向链表来表示节点插入顺序。
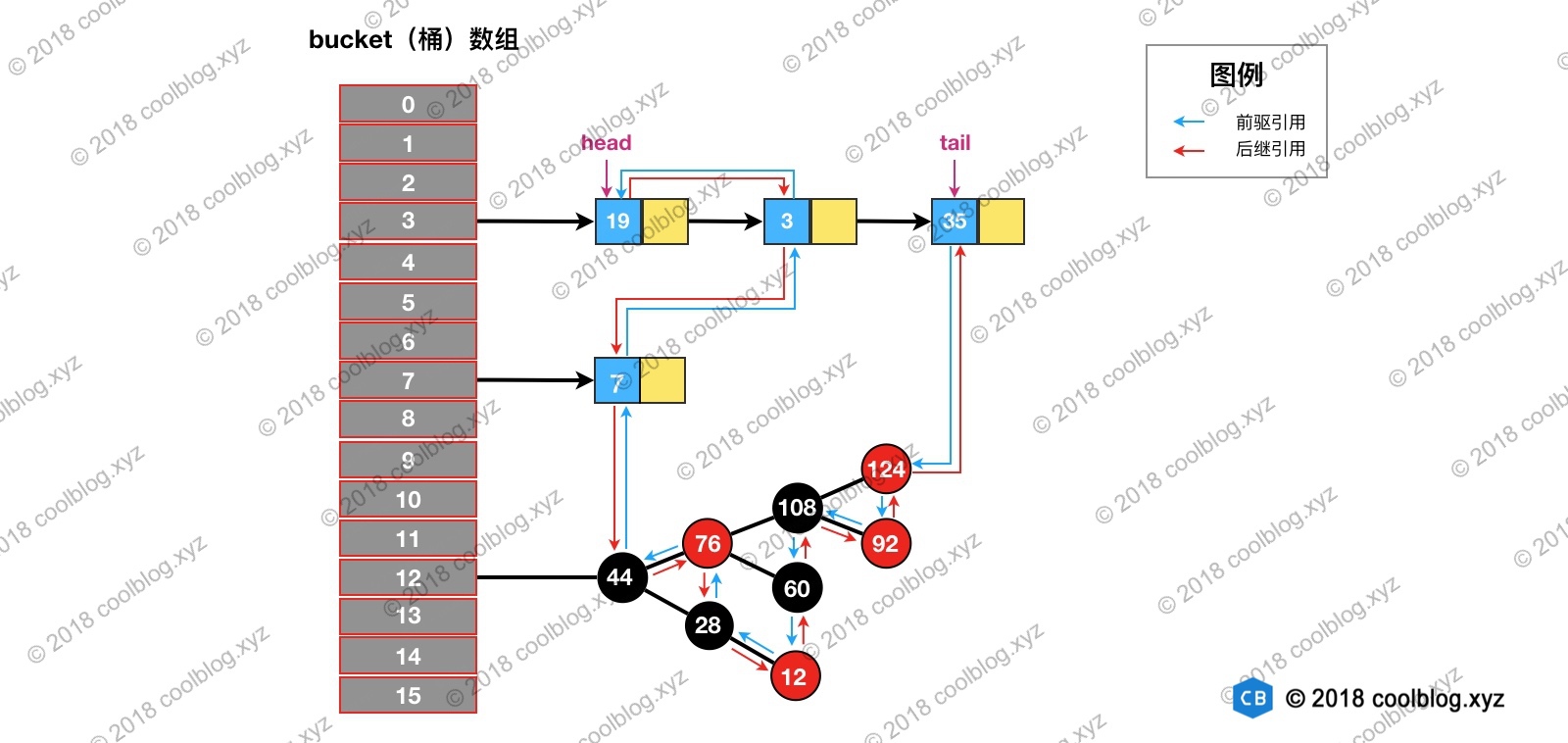
如上,节点上多出的红色和蓝色箭头代表了Entry中的before和after。在put元素时,会自动在尾节点后加上该元素,维持双向链表。了解LinkedHashMap结构后,在看看究竟什么是维护节点的访问顺序。先说结论,当开启accessOrder后,在对元素进行get操作时,会将该元素放在双向链表的队尾节点。源码如下:
public V get(Object key) {
Node<K,V> e;
// 调用HashMap的getNode方法,获取元素
if ((e = getNode(hash(key), key)) == null)
return null;
// 默认为false,如果开启维护链表访问顺序,执行如下方法
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
// 方法实现(将e放入尾节点处)
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 当节点不是双向链表的尾节点时
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; // 将待调整的e节点赋值给p
p.after = null;
if (b == null) // 说明e为头节点,将老e的下一节点值为头节点
head = a;
else
b.after = a;// 否则,e的上一节点直接指向e的下一节点
if (a != null)
a.before = b; // e的下一节点的上节点为e的上一节点
else
last = b;
if (last == null)
head = p;
else {
p.before = last; // last和p互相连接
last.after = p;
}
tail = p; // 将双向链表的尾节点指向p
++modCount; // 修改次数加以
}
}代码很简单,如上面的图,我访问了节点值为3的节点,那木经过get操作后,结构变成如下

经过如上分析我们知道,如果限制双向链表的长度,每次删除头节点的值,就变为一个lru的淘汰策略了。举个例子,我想限制双向链表的长度为3,依次put 1 2 3,链表为 1 -> 2 -> 3,访问元素2,链表变为 1 -> 3-> 2,然后put 4 ,发现链表长度超过3了,淘汰1,链表变为3 -> 2 ->4;
那木linkedHashMap是怎样知道自定义的限制策略,看代码,因为LinkedHashMap中没有提供自己的put方法,是直接调用的HashMap的put方法,查看hashMap代码如下:
// hashMap
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
// 看这个方法
afterNodeInsertion(evict);
return null;
}
// linkedHashMap重写了此方法
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// removeEldestEntry默认返回fasle
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
// 移除双向链表中的头指针元素
removeNode(hash(key), key, null, false, true);
}
}大功告成。原来只需要重新实现removeEldestEntry就可以自定义实现lru功能了。
下文分析LruCache就好多了。
来源:oschina
链接:https://my.oschina.net/u/4321684/blog/4449143