转载自:https://blog.frognew.com/2018/12/kubernetes-ipvs-long-connection-optimize.html
Kubernetes IPVS模式下服务间长连接通讯的优化,解决Connection reset by peer问题
前段时间测试将一套Kubernetes环境的kube-proxy切换成了ipvs模式,参见Kubernetes kube-proxy开启IPVS模式。 这套Kubernetes集群上主要运行http restful和gRPC两类服务,切换后这段时间还算稳定,只是最近某些客户端服务在调用gRPC服务时小概率出现Connection reset by peer的错误。
经过本地环境测试,当发一起一波请求到客户端服务预热一下,然后停止大约不到二十分钟时间,再请求客户端服务,客户端服务就会返回Connection reset by peer的错误,这说明是gRPC服务端将连接主动关闭了。 接下来再发起一波请求到客户端服务,一切又微服务正常。
在切换成ipvs模式后,客户端服务和gRPC服务之间的通信是基于ipvs的:
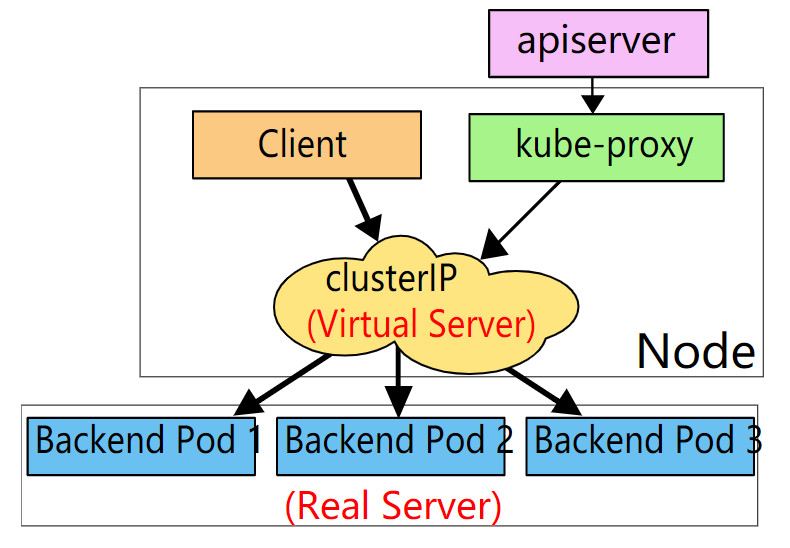
把上图中client看成是客户端服务Pod,3个Backend Pod(1~3)看成是后端的gRPC服务。 可以看出客户端服务和gRPC服务之间的交互路径:
|
|
我们知道gRPC是基于HTTP/2协议的,gRPC的client和server在交互时会建立多条连接,为了性能,这些连接都是长连接并且是一直保活的。 这段环境中不管是客户端服务还是gRPC服务都被调度到各个相同配置信息的Kubernetes节点上,这些k8s节点的keep-alive是一致的,如果出现连接主动关闭的问题,因为从client到server经历了一层ipvs,所以最大的可能就是ipvs出将连接主动断开,而client端还不知情。
搜索ipvs timeout关键字找到了下面相关的链接:
https://github.com/moby/moby/issues/31208中是关于docker swarm在overlay网络下长连接的问题,这个和k8s kube-proxy应该是类似的,按照这个链接中的描述查看 我们这套环境关于tcp keepalive的内核参数:
|
|
上面这段参数的含义: net.ipv4.tcp_keepalive_time是连接时长,当超过这个时间后,每个net.ipv4.tcp_keepalive_intvl的时间间隔会发送keepalive数据包,net.ipv4.tcp_keepalive_probe是发送keepalived数据包的频率。
使用ipvsadm命令查看k8s节点上ipvs的超时时间:
|
|
经过上面的分析可以看出,各个k8s节点上tcp keepalive超时是7200秒(即2小时),ipvs超时是900秒(15分钟),这就出现如果客户端或服务端在15分钟内没有应答时,ipvs会主动将tcp连接终止,而客户端服务还傻傻以为是2个小时呢。 很明显net.ipv4.tcp_keepalive_time不能超过ipvs的超时时间。
按照https://github.com/moby/moby/issues/31208中描述的,在测试环境中调节k8s节点上的tcp keepalive参数如下:
|
|
再去测试Connection reset by peer问题已经解决。由于我们维护k8s集群的ansible role包含配置内核参数的task,将其完善如下:
|
|
参考
文章作者 青蛙小白
来源:oschina
链接:https://my.oschina.net/u/4272511/blog/4279580