「道可道,非常道」,AI 领域的表征却一直在向着「常道可道」的方向前进,让可以表征的东西越来越接近「常道」。2017 年,DARPA 提出的第三波机器学习概念 [1] 中,其中一个方向也是找到更加通用的表征,从而让 AI 从当前「精心定义」过的任务中解脱出来,能够完成更加复杂的任务,更进一步接近人类的表现。为了解决这个问题,主要有两个方向——找到新的表征方式 [2](更有效的计算方式或是全新的表征)或是提升当前表征计算方法的通用性 [3, 4]。本文涉及了在今年 CVPR 中提出的三个解决方案,先是说明了如何改进现有的表征,然后说明了如何提升表征的表现,最后基于多任务学习说明了如何处理不太相关的两个任务的表征。本文对每篇论文的描述中会先说明任务和算法概述(方便大概了解论文),再进行算法细节的讨论(如果想深入了解可以把后面部分也看完)。
机器之心分析师网络,作者:王子嘉,编辑:Joni Zhong。
1. Distribution-Aware Coordinate Representation for Human Pose Estimation


论文链接:https://arxiv.org/abs/1910.06278
1.1 任务描述
本文的目标任务是人类姿态估计(human pose estimation),主要目的就是检测任意图片中人类关节的空间位置(坐标)。由于每张图片的光线、背景以及人们的穿着都不一样,因此这个任务的难点在于这些关节在图片中的呈现方式变化很大,从而一个好的标记(身体关节的坐标)表征也就显得尤为重要了。目前对于标签进行表征的标准方法是使用坐标热图 (heatmap)——以每个关节的标签坐标为核心而生成的二维高斯分布/核 [5],这个方法的核心在于坐标编码(也就是从坐标到热图的过程)与解码(从热图回到坐标的过程),而且目前的 SOTA 方法也是基于热图的 [6, 7]。因此本文的主要目的是改进热图的编码和解码方法,同时也用实验证明了一个好的表征的重要性。
1.2 算法概述
整个任务的最终目标是预测给定输入图像的关节坐标。为此,需要学习一个从输入图像到输出坐标的回归模型。这个过程可以分为两步,首先假设有一组训练图像,模型的学习分为两步,第一步编码过程:将节点的 ground truth 坐标编码为一个热图作为监督学习目标。第二步解码过程:在测试过程中,将预测的热图解码为原始图像坐标空间中的坐标。在编码的过程中,为了减少计算量,图像的像素进行了分辨率衰减,因此解码过程中需要进行对结果进行偏移才能得到好结果。而过去的基本方法都是根据经验确定的偏移量,本文则对这个偏移进行了详细的解释,并给出了更好的偏移方法。同样,在编码时,也要对其进行相应的变换以避免分辨率衰减带来的影响。
1.3 算法细节
1.3.1 解码过程
标准的解码方法是根据经验确定的,初步的坐标 p 可由下式计算得出:
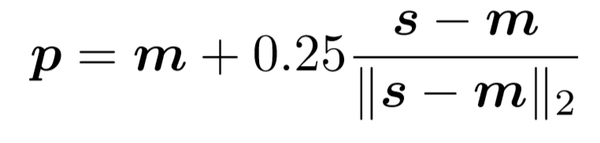
这里的 m 是热图中的最大激活值,s 是热图中的第二大激活值,|| . ||_2 是向量的模长。也就是说,真实坐标要在热图空间中从第一大激活值向着第二大激活值进行偏移才行。之所以要偏移,是因为在编码的过程中,为了减少计算量,图像的像素进行了分辨率衰减,因此最终热图中的第一大激活值的位置并不跟关节的在图片中的真实位置一致,而只是一个粗略的假设。假设开始的衰减率为\lambda,坐标经过分辨率修复(Resolution Recovery)后的最终坐标为:
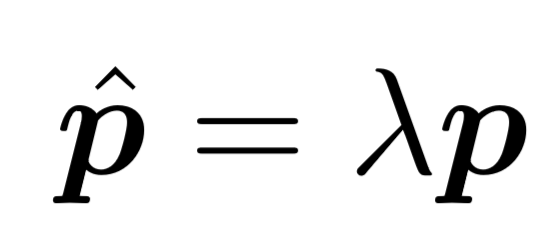
文中提出的的解码方法利用了热图的分布结构,从而找到真正的最大激活值。其基本流程如下图所示。
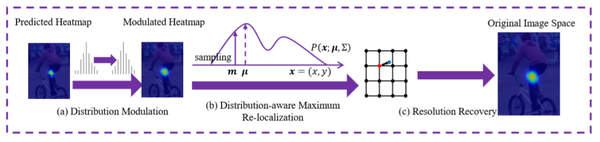 (图源自原论文)图 1:解码过程结构图
(图源自原论文)图 1:解码过程结构图
其中的分辨率修复与标准方法一致(如上式所示)。
Distribution-aware Maximum Relocalization是在基于分布假设的情况下对最大激活值进行重定位。具体来说,本文作者假定热图符合 2D 高斯分布,因此热图可以被表示为:
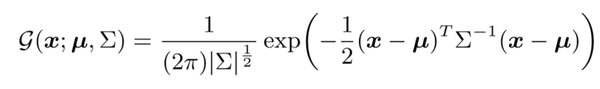
这里的 x 是热图像素的位置,\mu 是高斯的中心,这个中心与最重要预测的关节位置(原始图片中的位置)相关。协方差\Sigma 是个对角矩阵,与坐标编码过程中使用的相同(\sigma 是标准差):
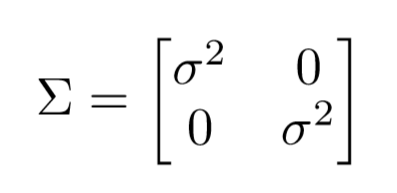
基于 log-likelihood 优化原则,作者在保持原始的最大激活值位置的前提下将通过对数将 G()进行了转换:
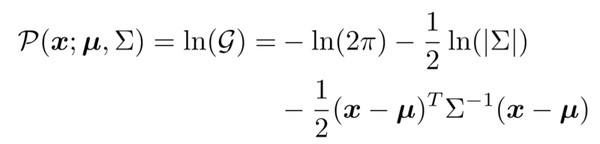
整个任务的最终目的还是为了估计\mu,因为这个点的特殊性,因此它的一阶导数 D』也有其特性:
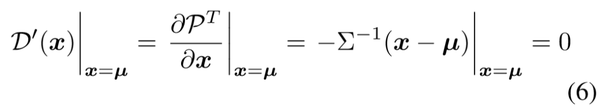
为了利用这一性质,作者利用了泰勒理论——利用最大激活值 M 处的泰勒级数对激活值 P(\mu) 进行逼近:
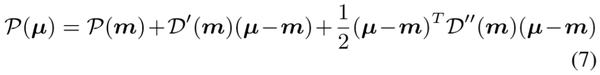
这里的二阶导数计算为:
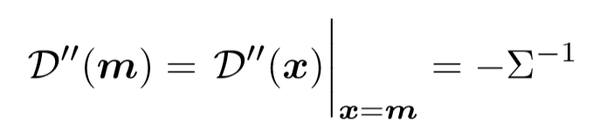
对上面三个式子进行整理,最终可以得到:
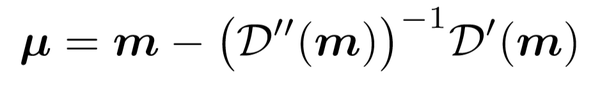
Distribution Modulation(分布调制)作者此后验证在 Distribution-aware Maximum Relocalization 中关于高斯分布的假设是否正确。验证如图 2 所示,通常来说训练集中的热图会有很好的高斯特征,而预测出来的热图(图 2(a))却一般会有多个峰值,并不怎么符合高斯分布,这可能会让我们的方法受到影响。
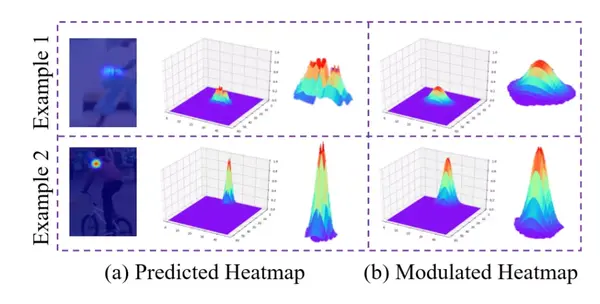 (图源自原论文)图 2:分布调制过程解读
(图源自原论文)图 2:分布调制过程解读
因此作者使用了一个与训练数据离散度相同的高斯核 K 来对预测的热图 h 进行调制(卷积),以减轻多峰值的影响:
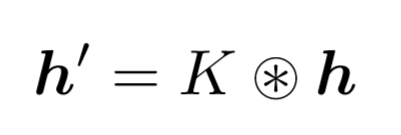
同时为了保证调制前后值大小的一致性,作者又对其进行了尺度变化:
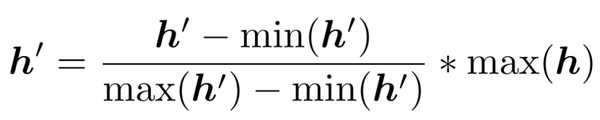
1.3.2 编码过程
这一部分作者为了解决跟解码相同的问题,将 gound-truth(关节坐标)先进行了转换以减轻分辨率衰减的影响,然后再生成热图。具体来说,作者首先对 ground-truth(g=(u,v))进行像素衰减(\lambda 为衰减率)得到 g':
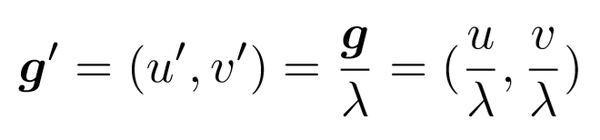
然后为了方便核的生成,作者又对其进行了量化处理(quantise(), 可以是向下取整, 向上取整, 四舍五入等)从而最终得到 g":
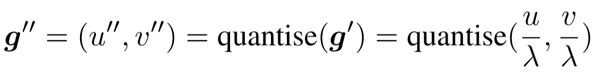
最终以这个坐标 (g'') 为中心的热图就可以生成了:
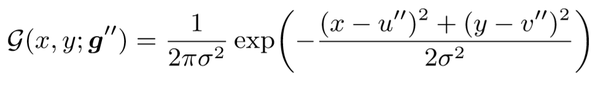
但是如图 3 所示,量化很大程度上会引入误差,因此虽然作者还是使用了上面这个式子,但是并没有使用 g",而是使用了 g'以减少误差。
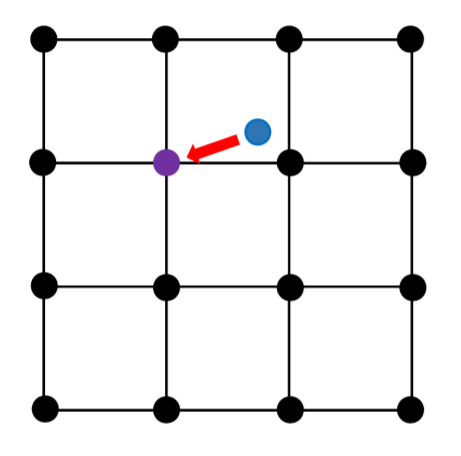 (图源自原论文)图 3:对 g'(蓝点)进行向下取整后引入的误差(红色箭头)
(图源自原论文)图 3:对 g'(蓝点)进行向下取整后引入的误差(红色箭头)
1.4 实验结果
数据集:COCO 和 MPII
评测方法: 在 COCO 上用对象关键点相似度(Object Keypoint Similarity, OKS), 在 MPII 上使用关键点正确概率(Percentage of Correct Keypoints (PCK))
模型:使用 Adam 优化器,HRNet 和基线模型使用与原论文相同的参数,Hourglass 的学习率调整为 2.5e-4,在第 90 个 epoch 衰减到 2.5e-5,在第 120 个 epoch 衰减到 2.6e-6
结果:下面三个表格分别说明了本文提出的编码和解码方法的环节都是有实际效果的。
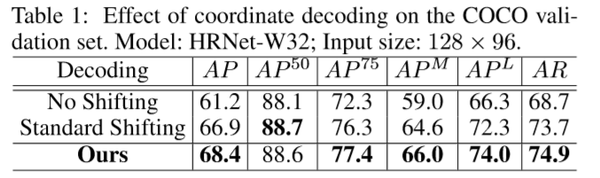
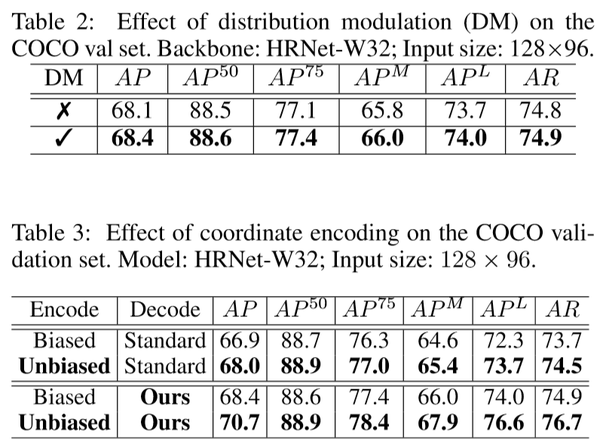
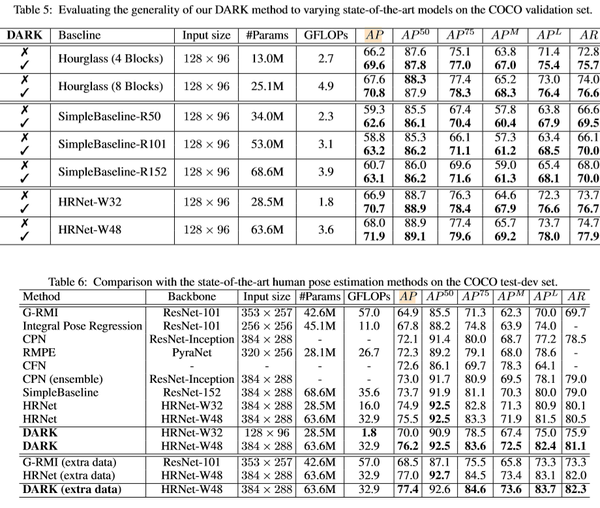
下面两个表格说明了 DARK 可以跟现有的大多数模型无缝连接,同时也比当前的 SOTA 方法的表现要好很多。
1.5 小结
这篇论文说明了一个好的表征对于模型的重要意义,同时也说明了在对模型中的每一步进行更深的了解时,即从经验到科学的过程,往往也能带来更好的表现。
2. Towards Universal Representation Learning for Deep Face Recognition

论文链接:https://arxiv.org/abs/2002.11841
2.1 任务描述
在面部识别任务中会将图片映射到一个特征空间去,人们希望这个空间中不同的对象之间的距离能尽可能的大,而相同对象之间的距离则尽可能小。但是面部图片的变化很大,尽管现在的一些大数据集已经尽可能的保证图库的多样性了,但是还是不够,SOTA 模型在一些特别具有挑战性的数据集上还是不能得到很好的结果。为了解决这一难题,也出现了一些方法,但是这些方法要么只处理特定的变化,要么需要访问测试数据分布,要么就是通过增加额外的运行时复杂性来处理更广泛的变化。如图 4 所示,本文作者即在避免上述问题的情况下学习了一个统一的特征表征,并且获得了很好的结果。
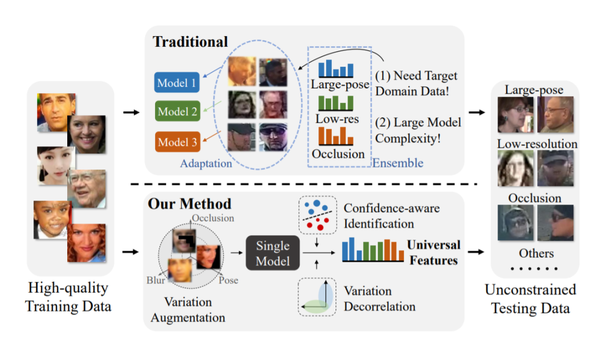 (图源自原论文)图 4:作者的方法避免了在获取统一特征时常见的几个问题
(图源自原论文)图 4:作者的方法避免了在获取统一特征时常见的几个问题
2.2 算法概述
首先,作者注意到,具有非正面姿态、低分辨率和严重遮挡的输入是对「野外」(『in-the-wild』) 应用程序提出挑战可见的关键因素,对于这些应用程序,可以对训练数据进行综合增强。但是直接在训练中添加硬增强的样本会带给人们一个更困难的优化问题。作者通过提出一种识别损失(identification loss)来缓解这种情况,这种识别损失考虑了每个样本的置信度,从而学习到概率特征嵌入。其次,作者试图通过将嵌入分解为子嵌入来最大化嵌入的表示能力,每个子嵌入在训练过程中都有一个独立的置信度值。第三,鼓励所有的子嵌入在不同区域通过两个相反的正则化来进一步去相关,即特征分类损失和特征对抗损失。第四,作者通过挖掘训练数据中的其他变化来进一步扩展去相关正则化,对于这些变化,合成增强是很重要的。最后,作者通过一个概率聚合来解释不同因素的不确定性,从而解释子嵌入的不同识别能力。
如图 5 所示,本文的方法先对输入样本进行增强,然后利用置信度将特征分成子嵌入。训练过程中使用了基于置信度的识别损失和离散去相关损失。
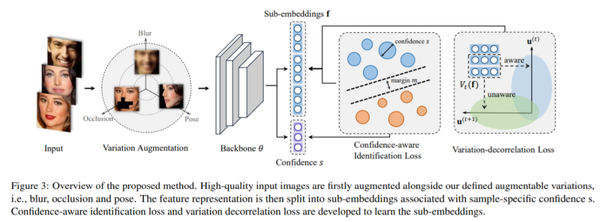 (图源自原论文)图 5:本文方法的流程图
(图源自原论文)图 5:本文方法的流程图
2.3 算法细节
2.3.1 具有置信度的识别损失(Confidence-aware Identification Loss)
设 f_i 为第 i 个样本的特征嵌入,w_j 为第 j 个类的向量。此时概率嵌入网络\theta 可以把每个样本 x_i 表示为一个特征空间的一个高斯分布 N(f_i, \sigma^2 I),则样本 x_i 属于第 j 个类的可能性 (likelihood) 为(D 为特征的维度):
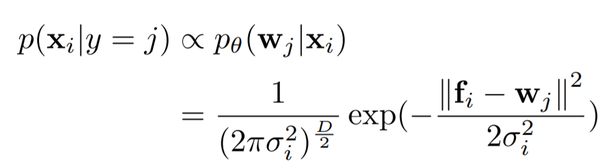
假设每个样本属于任何类的先验概率一样,那么 X_i 属于第 j 个类的后验概率就可以表示为:
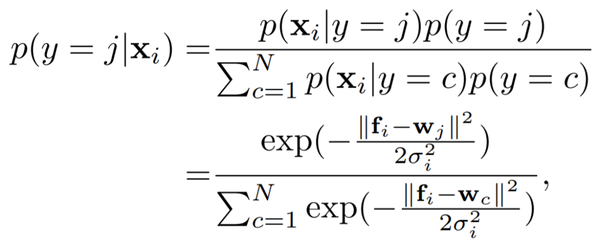
对上式进行简化,将 frac{1}{\sigma^2} 变为评价信心的置信度 s_i,将 f_i 和 w_j 限制在 l2 标准化的单位球面内,此时上式变成了:
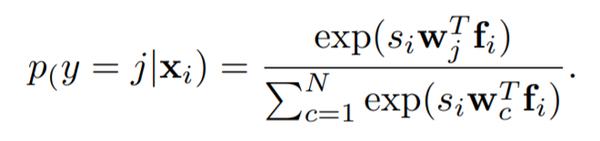
如图 6 所示,加入了置信度之后,为了最大化后验概率,各个类的原型(prototype)会靠近高质量的样本(因为有更高的置信度),而在嵌入 f_i 进行更新的过程中,这也会让低质量样本趋向于原型,从而趋向于高质量样本。
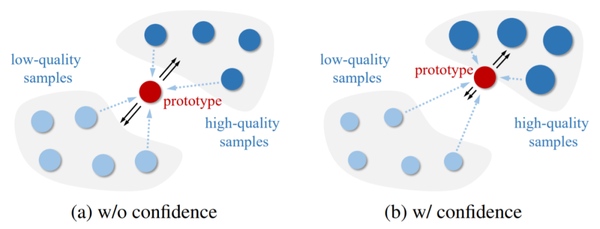 (图源自原论文)图 6:置信度的作用
(图源自原论文)图 6:置信度的作用
同时为了缩紧相同对象的分布,作者在损失函数中加入了损失边界以缩小同类的分布(within-identity distribution):
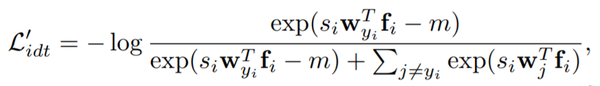
这里的 y_i 是 x_i 的 ground truth,m 是边界参数(以实现损失边界的引入)。
2.3.2 具有置信度的子嵌入(Confidence-aware Sub-Embeddings)
为了让表征的能力最大化,作者对嵌入中的每个条目进行了去相关的操作——先将特征嵌入 f_i、原型矩阵 w_j 和置信度标量 s_i 分成 K 个等长的矩阵:
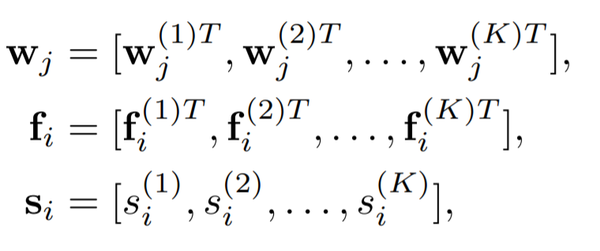
每个子嵌入 f_{i}^{k} 都各自经过了 l2 标准化,因此最终的识别损失变成了:
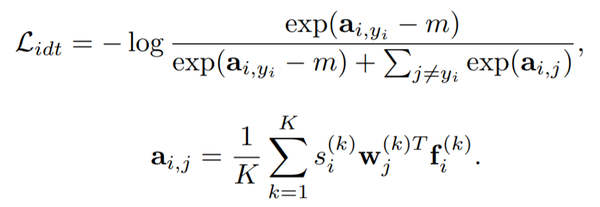
同时,为了避免模型变得过度自信,作者又加入了一个 l2 正则化条目以限制置信度的无限变大:
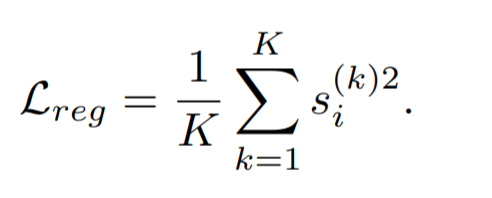
2.3.3 子嵌入去相关
让各个子嵌入分离开来并没有真的实现它们的去相关,因此作者通过将不同的子嵌入与不同的特征联系起来,对所有子嵌入的一个子集计算特征分类损失,同时对其他变异类型计算特征对抗性损失。给定多个特征,这两个正则化项被强制放在不同的子集上,从而得到更好的子嵌入去相关效果。对于增强后的特征 t,作者生成了一个二进制的掩码 V_t,从而随机从所有的子嵌入中选一般,剩下的设为 0,而且保证对于不同的特征,这个掩码都是不同的。作者希望 V_t(f_i) 能够只影响第 t 个变种,因此,作者希望能利用掩码预测出是哪个特征,从而建立了一个多类别判别器 C:
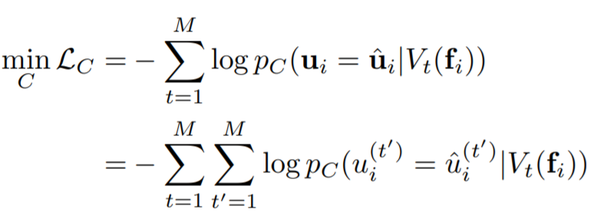
这里的 u_i 是一个二进制值,代表特征。如 t=1 代表分辨率,则如果 u=1 表示高分辨率的变种。这个式子只是用来训练判别器的,整个嵌入网络的分类损失和对抗损失分别为:
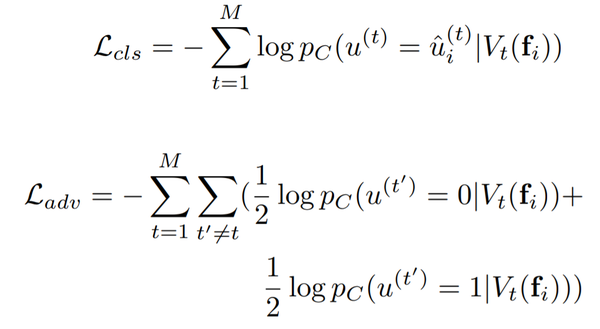
第一个损失是为了让每个特征的 V_t 都不同,同时第二个损失则让这些 V_t 在其他的非对应特征上都尽量不变。因此,作者得到了最终的损失函数:
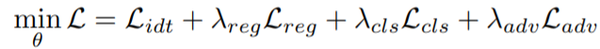
2.3.4 找到更多的变化特征
为了让上一节的去相关效果更好,就需要更多的增强特征。因此作者建立了一个属性分类模型,用对抗损失来找到一些不好直接进行增强的变化体征(如微笑等):
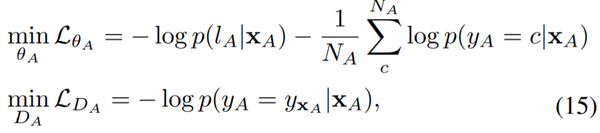
l_A 是属性标签,y_A 是图片类别标签,x_A 是输入的图片,N_A 是数据集中类的数量。第一个损失惩罚对面部属性进行分类的特征,第二项则惩罚同一类中特征的不变性。然后这个分类器就被用来生成 T 个新的特征变种(如年轻与否等)。这些特征会跟一开始图像增强时使用的变化特征合并在一起,并应用于 2.3.3 中说的去相关性。
2.4 实验结果
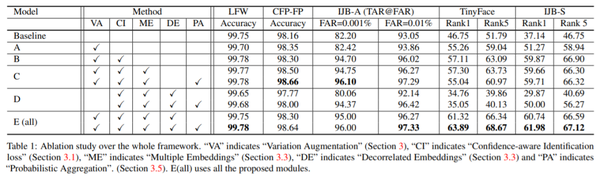
数据集:三种——LFW, CFP, YTF, MegaFace (变化有限);IJB-A,IJB-C(分辨率不一);TinyFace,IJB-S(低分辨率)Ablation Study 结果:下表说明了本文提出各个环节基本都是有实际效果的(E 的效果基本都是最好的)。
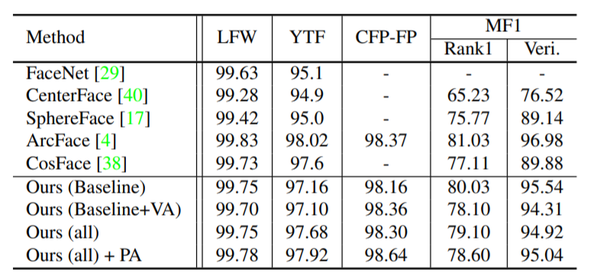
与其他模型比较结果:下面两个表格说明在上述三种类型的数据集中,本文提出的模型效果基本都是最好的。
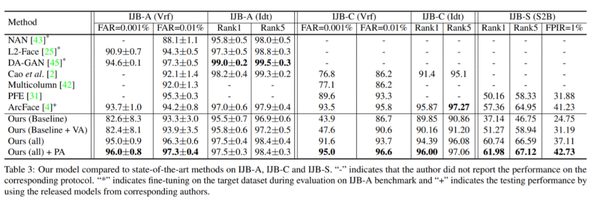
2.5 小结
本文的元素很多,本质目的是为了让表征的能力更加强大。对表征的理解越深刻,可能表征时所需要的模型就越复杂,但是对应的,获取的表征也会带来更好的结果。
3. 12-in-1: Multi-Task Vision and Language Representation Learning

论文链接:https://arxiv.org/abs/1912.02315
3.1 任务描述
许多视觉和语言的研究集中在一组小而多样的独立任务及其对应数据集上,这些数据集通常是单独研究的,然而,完成这些任务所需的视觉语言理解能力有很大的重叠。虽然单个任务呈现出不同的挑战和不同的接口,但语言和视觉概念之间的基本关联在不同任务之间通常是通用的。例如,学着表达「小红花瓶」和理解与回答「小红花瓶是什么颜色的?」是基本相同的概念。联合训练多个任务可以潜在地汇集这些不同的监督任务。此外,开发能够同时在大范围任务中表现良好的模型可以帮助防止研究圈对特定数据集和度量的过度拟合。本文的模型涉及了四类任务(视觉问题回答-visual question answering,基于图像描述的图像检索-caption-based image retrieval,看图识物-grounding referring expressions 和多模态验证-multi-modal verification),并在总共 12 个不同的数据集上联合训练。
3.2 算法概述
本文中,作者基于 ViLBERT (https://syncedreview.com/2019/08/15/facebook-georgia-tech-osu-vilbert-achieves-sota-on-vision-and-language-tasks/) [4] 开发了一个视觉-语言的多任务模型来学习 12 个不同的数据集。这个大规模的多任务学习具有挑战性,实验之前作者们也不肯定单个模型是否能同时学习 12 个不同的数据集,而且数据集的大小和难度各不相同。为了解决这些问题,作者引入了动态训练调度器(dynamic stop-and-go training scheduler)、基于任务的输入标记(task dependent input tokens)和简单的启发式超参(simple hyper-parameter heuristics)。基于这个流程,人们就能够用不同的数据集训练各种多任务模型,并评估不同视觉和语言任务在一起训练时的性能之间的关系。
3.3 算法细节
3.3.1 基本框架
本文的基本框架是基于 ViLBERT,作者在其基础上做了两个改进:首先,在掩蔽视觉区域时,作者还遮住了具有显著重叠 (> 0.4 IoU, intersection over union) 的其他区域,以避免泄漏视觉信息。这迫使模型更加依赖于语言来预测图像内容。其次,在对负 (不匹配) 语言进行多模态对齐预测时,作者不强制掩蔽多模态建模损失。这将有效地消除由负样本引入的噪声。
3.3.2 多任务学习
文中作者使用了一个简单的多任务模型,其中每个任务可以看作一个特定于任务的树枝网络(原文称「head」),该网络从一个公共的、共享的树干 ViLBERT 模型(原文称「trunk」)中分出来。这样, 我们学习共享树干参数θs 和一组基于各个任务层的特定参数 {θt}({θt} 代表所有任务的特定参数)。我们的目标是学习参数θs∪{θt},并最小化所有任务的损失。具体修改细节如下:
Token: 为了将任务信息编码进去,最终的输入格式如下图所示,并且本文提出的结构采用从底向上的方式对输入信息进行处理。其中 v_i 是图片的特征,w_i 是词的 token,IMG, CLS 和 SEP 是特殊 token。

下面是各个任务的「head」:
Vocab-Based VQA 的输出:作者将基于 Vocab-Based VQA 视为一个多标签分类任务——根据每个答案与真实答案的相关性为每个答案分配一个软目标分数。文中使用了一个两层的 MLP 来计算一组预先定义的答案 A 的分数(σ指的是 sigmoid function,h_{IMG} 和 h_{CLS} 分别是 ViLBERT 输出的图片和文字的特征向量):
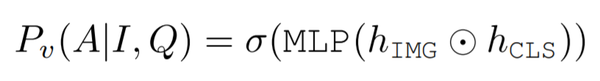
图像检索的输出:在这个任务中,作者同样基于 ViLBERT 输出的特征向量来计算图像-文本对之间的对齐分数(此处的 W_i 在 COCO Flickr30k 数据集的图像检索任务中共享):
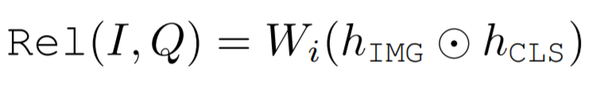
看图识物的输出:基于给定的描述,作者对一组区域提案进行了重排,并将每个图像区域 i 的最终表示 h_vi 传递到一个学习投影 W_r 中,从而预测出一个匹配的分数(注意这里 Q 的形式根据数据集不同也会变化):
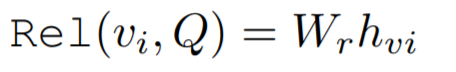
多模态验证的输出:输入为两张图片(I_0 和 I_1)和一段描述(Q),模型需要判断这段描述的有效性。作者将其定义为分类问题,因此这个 head 的输出为([] 的意思为 concatenate):
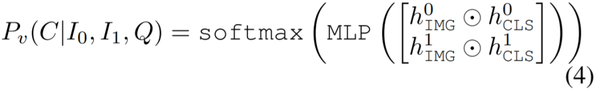
除此之外,作者还描述了其在大规模训练上用到的一些 trick,跟其框架无关,有兴趣可以自己查阅论文。
3.4 实验结果
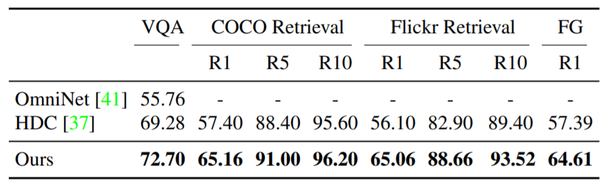
如下表所示,本文提出的多任务模型在表现上比其他的多任务模型都要好。同时,文中还列出了很多在各个单个任务上与 SOTA 方法的对比,也都表现很抢眼(要么比它们强,要么差不多),如果对某个上述的特定任务感兴趣,可以去原文中查一下其对应的实验结果。
3.5 小结
本文提出了一种多任务学习的框架,利用了统一的表征矩阵,而且利用共享的参数减少了很多参数量。这种重叠的东西,也正是在寻求表征统一化的过程中需要发现的。
总结
本文介绍了三篇跟表征相关的论文,可以发现让表征变得更加强大、发现共性是很重要的,都能让他们的模型在各个任务上获得很大的成功。在未来的探索的方向,可以集中在如何像第三篇文章那样找到各个任务表征中的共性,从而降低表征模型的训练需求,或是像前两篇文章那样,在表征的训练过程中下手,用更广泛的方式获得更广泛、更精确的表征模型。
References
[1] A DARPA perspective on Artificial Intelligence. Access at: https://www.darpa.mil/attachments/AIFull.pdf
[2] Feng Zhang, Xiatian Zhu, Hanbin Dai, Mao Ye, and Ce Zhu. Distribution-aware coordinate representation for human pose estimation, 2019.
[3] Yichun Shi, Xiang Yu, Kihyuk Sohn, Manmohan Chandraker, and Anil K.Jain. Towards universal representation learning for deep face recognition,2020.2
[4] Jiasen Lu, Vedanuj Goswami, Marcus Rohrbach, Devi Parikh, and StefanLee. 12-in-1: Multi-task vision and language representation learning, 2019
[5] Tompson,J.J.;Jain,A.;LeCun,Y.;andBregler, C. 2014. Joint training of a convolutional network and a graphical model for human pose estimation. In Advances in Neural Information Processing Systems
[6]Xiao, B.; Wu, H.; and Wei, Y. 2018. Simple baselines for human pose estimation and tracking. In European Conference on Computer Vision.
[7]Sun, K.; Xiao, B.; Liu, D.; and Wang, J. 2019. Deep high-resolution representation learning for human pose estimation. In IEEE Conference on Computer Vision and Pattern Recognition.
作者介绍:本文作者为王子嘉,目前在帝国理工学院人工智能硕士在读。主要研究方向为 NLP 的推荐等,喜欢前沿技术,热爱稀奇古怪的想法,是立志做一个不走寻常路的研究者的男人!
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?提交申请:http://jiqizhixin.mikecrm.com/rg2RY52
来源:oschina
链接:https://my.oschina.net/u/4361003/blog/4257091