0.介绍
RabbitMQ是一个消息代理:它接受并转发消息。你可以把它当成一个邮局:当你想邮寄信件的时候,你会把信件放在投递箱中,并确信邮递员最终会将信件送到收件人的手里。在这个例子中,RabbitMQ就相当与投递箱、邮局和邮递员。
RabbitMQ与邮局的区别在于:RabbitMQ并不处理纸质信件,而是接受、存储并转发二进制数据---消息。
谈到RabbitMQ的消息,通常有几个术语:
-
生产者:是指发送消息的程序
-
队列:相当于RabbitMQ的投递箱。尽管消息在RabbitMQ和你的应用之间传递,但是消息仅仅会在队列之中存储。队列只能存储在内存或磁盘中,本质上是一个大的消息缓冲区。不同的生产者可以发送消息到同一个对队列,不同的消费者也可以从同一个队列中获取消息。
-
消费者:等待接受消息的程序。
注意,生产者、消费者以及RabbitMQ并不一定要在同一个主机上,在绝大部分的应用中它们都不在同一主机上。
RabbitMQ 一般工作流程
生产者和RabbitMQ服务器建立连接和通道,声明路由器,同时为消息设置路由键,这样,所有的消息就会以特定的路由键发给路由器,具体路由器会发送到哪个或哪几个队列,生产者在大部分场景中都不知道。(1个路由器,但不同的消息可以有不同的路由键)。
消费者和RabbitMQ服务器建立连接和通道,然后声明队列,声明路由器,然后通过设置绑定键(或叫路由键)为队列和路由器指定绑定关系,这样,消费者就可以根据绑定键的设置来接收消息。(1个路由器,1个队列,但不同的消费者可以设置不同的绑定关系)。
主要方法
-
声明队列(创建队列):可以生产者和消费者都声明,也可以消费者声明生产者不声明,也可以生产者声明而消费者不声明。最好是都声明。(生产者未声明,消费者声明这种情况如果生产者先启动,会出现消息丢失的情况,因为队列未创建)
channel.queueDeclare(String queue, //队列的名字
boolean durable, //该队列是否持久化(即是否保存到磁盘中)
boolean exclusive,//该队列是否为该通道独占的,即其他通道是否可以消费该队列
boolean autoDelete,//该队列不再使用的时候,是否让RabbitMQ服务器自动删除掉
Map<String, Object> arguments)//其他参数-
声明路由器(创建路由器):生产者、消费者都要声明路由器---如果声明了队列,可以不声明路由器。
channel.exchangeDeclare(String exchange,//路由器的名字
String type,//路由器的类型:topic、direct、fanout、header
boolean durable,//是否持久化该路由器
boolean autoDelete,//是否自动删除该路由器
boolean internal,//是否是内部使用的,true的话客户端不能使用该路由器
Map<String, Object> arguments) //其他参数-
绑定队列和路由器:只用在消费者
channel.queueBind(String queue, //队列
String exchange, //路由器
String routingKey, //路由键,即绑定键
Map<String, Object> arguments) //其他绑定参数-
发布消息:只用在生产者
channel.basicPublish(String exchange, //路由器的名字,即将消息发到哪个路由器
String routingKey, //路由键,即发布消息时,该消息的路由键是什么
BasicProperties props, //指定消息的基本属性
byte[] body)//消息体,也就是消息的内容,是字节数组-
BasicProperties props:指定消息的基本属性,如deliveryMode为2时表示消息持久,2以外的值表示不持久化消息
//BasicProperties介绍
String corrId = "";
String replyQueueName = "";
Integer deliveryMode = 2;
String contentType = "application/json";
AMQP.BasicProperties props = new AMQP.BasicProperties
.Builder()
.correlationId(corrId)
.replyTo(replyQueueName)
.deliveryMode(deliveryMode)
.contentType(contentType)
.build();-
接收消息:只用在消费者
channel.basicConsume(String queue, //队列名字,即要从哪个队列中接收消息
boolean autoAck, //是否自动确认,默认true
Consumer callback)//消费者,即谁接收消息-
消费者中一般会有回调方法来消费消息
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, //该消费者的标签
Envelope envelope,//字面意思为信封:packaging data for the message
AMQP.BasicProperties properties, //message content header data
byte[] body) //message body
throws IOException {
//获取消息示例
String message = new String(body, "UTF-8");
//接下来就可以根据消息处理一些事情
}
};
路由器类型
-
fanout:会忽视绑定键,每个消费者都可以接受到所有的消息(前提是每个消费者都要有各自单独的队列,而不是共有同一队列)。
-
direct:只有绑定键和路由键完全匹配时,才可以接受到消息。
-
topic:可以设置多个关键词作为路由键,在绑定键中可以使用
*和#来匹配 -
headers:(可以忽视它的存在)
一、Hello World
在这一部分,我们将会使用Java编写两个小程序:一个发送单个消息的生产者、一个接受消息并打印出消息的消费者。这个消息就是Hello World。
下图中,P代表生产者,C代表消费者,中间红色的小箱子就代表队列--RabbitMQ为了让消费者收到消息而保持的消息缓冲区。


在这一部分,只需要引入Java客户端依赖即可:amqp-client.jar,也可以通过maven的方式引入:
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>4.1.0</version>
</dependency>1、生产者
我们将消息的发布者(生产者)命名为Send,将消息的消费者命名为Recv。发布者将会连接到RabbitMQ,并且发送一条消息,然后退出。
public class Send {
//定义队列名字
private final static String QUEUE_NAME = "weixiaotao";
public static void main(String[] argv) throws Exception {
//创建连接和通道 创建一个连接到Rabbit服务器的连接
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.24.128");
factory.setUsername("admin");
factory.setPassword("admin");
Connection connection = factory.newConnection();
//创建了一个通道(channel),大部分的API操作均在这里完成
Channel channel = connection.createChannel();
//为通道指明队列 对于Send来说,必须指明消息要发到哪个队列:
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
String message = "Hello World aaaaa...!";
//发布消息
channel.basicPublish("", QUEUE_NAME, null, message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + message + "'");
//关闭连接
channel.close();
connection.close();
}
}
上面的代码中,connection是socket连接的抽象,为我们处理了通信协议版本协商以及认证等。这样,我们就连接到了本地机器上的一个消息代理(broker)。如果想连接到其他机器上的broker,只要修改IP即可。
队列的定义是幂等的,它仅仅在不存在时才会创建。消息的内容是一个字节数组,所以你可以随意编码
2、接收者(消费者)
完整代码如下:
public class Recv {
private final static String QUEUE_NAME = "weixiaotao";
public static void main(String[] argv) throws Exception {
//建立连接和通道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.24.128");
factory.setUsername("admin");
factory.setPassword("admin");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//声明要消费的队列
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
//回调消费消息
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body)
throws IOException {
String message = new String(body, "UTF-8");
System.out.println(" [x] Received '" + message + "'");
}
};
channel.basicConsume(QUEUE_NAME, true, consumer);
}
} 消费者从RabbitMQ中取出消息。不同于发布者只发送一条消息就退出,这里我们让消费者一直监听消息,并把接受到的消息打印出来。 上面引入的DefaultConsumer是Consumer接口的实现类,我们使用它来缓冲从服务器push来的消息。 接下来的设置与发布者类似,打开连接和通道,声明我们想消费的队列。注意,这里的队列的名字要与发布者中声明的队列的名字一致。
注意,消费者同样声明了队列。这是因为,我们可能在启动生产者之前启动了消费者应用,我们想确保在从一个队列消费消息之前,这个队列是存在的。
接下来,告诉服务器(RabbitMQ)把队列中的消息发过来。因为这个过程是异步的,可以通过DefaultConsumer来进行回调。
这样,消费者就会一直监听声明的队列。运行一次生产者(即Send.java中的main方法),消费者就会打印出接受到的消息。
二. Work Queues
在第一个教程中,我们实现了从一个指定的队列中发送和接收消息。在这一部分,我们将会创建一个工作队列:用来讲耗时的任务分发给多个工作者。
工作队列的主要思想是避免这样的情况:直接去做一件资源密集型的任务,并且还得等它完成。相反,我们将任务安排到之后再去做。我们将任务封装为一个消息,并发到队列中。一个工作进程将会在后台取出任务并最终完成工作。如果开启多个工作进程,任务将会在这多个工作进程间共享。
这个概念在web应用中是非常有用的,因为web应用不可能在一个HTTP请求中去处理一个复杂的任务。
准备
在上一个教程中,我们发送了“hello world”的消息。现在,我们会发送一些代表复杂任务的字符串。我们没有真实的任务(比如调整图片大小、PDF文件加载等),所以我们使用Thread.sleep()方法来伪造耗时任务,假装我们很忙。我们用字符串中的点号.来表示任务的复杂性,一个点就表示需要耗时1秒,比如一个描述为hello...的假任务,它需要耗时3秒。
循环分发
使用任务队列的一个优势在于容易并行处理。如果积压了大量的工作,我们只需要添加更多的工作者(上文中的Worker.java中的概念),这样很容易扩展。
首先,我们来尝试同时运行两个工作者实例(Worker.java)。
启动NewTask,之后,可以依次将message修改为"2.."、"3..."、"4...."、"5....."等,每修改一次就运行一次。
可以看出,默认情况下,RabbitMQ是轮流发送消息给下一个消费者,平均每个消费者接收到的消息数量是相等的。这种分发消息的方式叫做循环分发。
消息确认
完成一项任务可能会耗费几秒钟,你可能会问,假如其中一个消费者开始了一个非常耗时的任务,并在执行这个任务的时候崩溃了(也就是没有完成这个任务),将会发生什么事情。按照上面的代码,一旦RabbitMQ向消费者发出消息,消息就会立即从内存中移除。在这种情况下,如果你杀死一个工作者,我们将会失去它正在处理的消息,同时也会丢失所有发给这个工作者但这个工作者还未处理的消息。
但我们不想丢掉任务,如果一个工作者死掉,我们想将这个任务发给其他的工作者。
为了确保消息永远不会丢失,RabbitMQ支持消息确认。消费者将会发送一个确认信息来告诉RabbitMQ,我已经接收到了消息,并且处理完了,你可以随便删它了。
如果一个消费者在发送确认信息前死去(连接或通道关闭、TCP连接丢失等),RabbitMQ将会认为该消息没有被完全处理并会重新将消息加入队列。如果此时有其他的消费者,RabbitMQ很快就会重新发送该消息到其他的消费者。通过这种方式,你完全可以保证没有消息丢失,即使某个消费者意外死亡。
对RabbitMQ而言,没有消息超时这一说。如果消费者死去,RabbitMQ将会重新发送消息。即使处理一个消息需要耗时很久很久也没有关系。
消息确认机制是默认打开的。只是在前面的代码中,我们显示地关掉了:boolean autoAck=true。
注意到最上面的那句代码:
//channel.basicQos(int prefetchCount);
channel.basicQos(1); // accept only one unack-ed message at a time (see below) 其中的参数prefetchCount表示:maximum number of messages that the server will deliver。
这样,就可以确保即使消费者挂了,消息也不会丢失。
消息持久化
通过上面的教程,我们知道如何确保消费者挂掉也不会丢失消息。但是,加入RabbitMQ服务器挂掉了怎么办?
如果关闭RabbitMQ服务或者RabbitMQ服务崩溃了,RabbitMQ就会丢掉所有的队列和消息:除非你告诉它不要这样。要确保RabbitMQ服务关闭或崩溃后消息不会丢失,要做两件事情:持久化队列、持久化消息。
首先,我们要确保RabbitMQ永远不会丢失我们的队列。怎么做呢?在声明队列的时候,指定durable参数为true。
boolean durable = true;
channel.queueDeclare("hello", durable, false, false, null); 尽管上面的代码没有错,但是它不会按所想的那样将队列持久化:因为之前我们已经将hello这个队列设置了不持久化,RabbitMQ不允许重新定义已经存在的队列,否则就会报错。快速的解决办法:声明另外一个队列就行了,只要不叫hello,比如task_queue:
现在,我们已经确保队列不会丢失了,那么如何将消息持久化呢:将MessageProperties的值设置为PERSISTENT_TEXT_PLAIN。
import com.rabbitmq.client.MessageProperties;
channel.basicPublish("", "task_queue",
MessageProperties.PERSISTENT_TEXT_PLAIN,
message.getBytes()); 将消息标记为持久化并不能完全保证消息不会丢失。尽管它告诉RabbitMQ将消息保存到磁盘中,但是在RabbitMQ接收到消息和保存消息之间会与一个很短的时间窗。同时,RabbitMQ不会为每个消息做fsync(2)处理,消息可能仅仅保存到缓存中而不会真正地写入到磁盘中。这种持久化保证尽管不够健壮,但已经远远足够我们的简单任务队列。如果你需要更强大的保证,可以使用[publisher confirms](https://www.rabbitmq.com/confirms.html)。
公平分发
你可能已经发现,循环消息分发并不是我们想要的。比如,有两个工作者,当奇数消息(如上文中的"1..."、"3..."、"5..."、"7...")很耗时而偶数消息(如上文中的"2."、"4."、"6."、"8.")很简单的时候,其中一个工作者就会一直很忙而另一个工作者就会闲。然而RabbitMQ对这些一概不知,它只是在轮流平均地发消息。
这种情况的发生是因为,RabbitMQ 只是当消息进入队列时就分发出去,而没有查看每个工作者未返回确认信息的数量。
为了改变这种情况,我们可以使用basicQos方法,并将参数prefetchCount设为1。这样做,工作者就会告诉RabbitMQ:不要同时发送多个消息给我,每次只发1个,当我处理完这个消息并给你确认信息后,你再发给我下一个消息。这时候,RabbitMQ就不会轮流平均发送消息了,而是寻找闲着的工作者。
int prefetchCount = 1;
channel.basicQos(prefetchCount);注意,如果所有的工作者都很忙,你的队列可能会装满,你必须留意这种情况:或者添加更多的工作者,或者采取其他策略。
相关完整代码:
import java.io.IOException;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.MessageProperties;
public class NewTask {
private static final String TASK_QUEUE_NAME = "task_queue";
public static void main(String[] argv)
throws java.io.IOException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);
String message = getMessage(argv);
channel.basicPublish( "", TASK_QUEUE_NAME,
MessageProperties.PERSISTENT_TEXT_PLAIN,
message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
channel.close();
connection.close();
}
//...
}
import com.rabbitmq.client.*;
import java.io.IOException;
public class Worker {
private static final String TASK_QUEUE_NAME = "task_queue";
public static void main(String[] argv) throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
final Connection connection = factory.newConnection();
final Channel channel = connection.createChannel();
channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
channel.basicQos(1);
final Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println(" [x] Received '" + message + "'");
try {
doWork(message);
} finally {
System.out.println(" [x] Done");
channel.basicAck(envelope.getDeliveryTag(), false);
}
}
};
boolean autoAck = false;
channel.basicConsume(TASK_QUEUE_NAME, autoAck, consumer);
}
private static void doWork(String task) {
for (char ch : task.toCharArray()) {
if (ch == '.') {
try {
Thread.sleep(1000);
} catch (InterruptedException _ignored) {
Thread.currentThread().interrupt();
}
}
}
}
}
三.Publish/Subscribe
在之前的教程中,我们创建了一个工作队列:一个消息只能发送到一个工作者(消费者)中。而在这个教程中我们将会做完全不同的事情:我们发送同一个消息到多个消费者中。这种模式一般被称为“发布/订阅”模式。
为了演示这种模式,我们将会创建一个简单的日志系统。它由两个程序组成:第一个将会输出日志消息,第二个将会接受并打印出日志消息。
在这个日志系统中,每一个接收程序(消费者)都会收到所有的消息,其中一个消费者将消息直接保存到磁盘中,而另一个消费者则将日志输出到控制台。从本质上讲,发布的日志消息将会广播给所有的接收者(消费者)。
交换器Exchanges
在之前的教程里,我们都是直接往队列里发送消息,然后又直接从队列里取出消息。现在是时候介绍RabbitMQ的整个消息模型了。
先让我们快速地回顾一下之前教程中的几个概念:
-
生产者:发送消息的用户程序
-
队列:存储消息的缓冲区
-
消费者:接收消息的用户程序
RabbitMQ的消息模型中的一个核心思想是,生产者绝不会将消息直接发送到队列中,实际上,在大部分场景中生产者根本不知道消息会发送到哪些队列中。
-
相反,生产者只会将消息发送给一个Exchange(路由器/交换器)。Exchange其实很简单,它所做的就是,接收生产者发来的消息,并将这些消息推送到队列中。Exchange必须清楚地知道怎么处理接收到的消息:是将消息放到一个特定的队列中,还是放到多个队列中,还是直接将消息丢弃。下图示意了Exchange在消息模型中的位置:

Exchange一共有四种类型:direct、topic、headers 和fanout。今天的教程将会使用fanout类型的Exchange,让我们创建一个名为logs的fanout类型的Exchange
channel.exchangeDeclare("logs", "fanout"); fanout类型的Exchange非常简单,从它的名字你可能就已经猜出来了(fanout翻译过来是扇形的意思),它将会将接收到的消息广播给所有它知道的队列。这正是我们的日志系统所需要的类型。可以通过下面的命令列出Rabbit服务器上的所有Exchange
sudo rabbitmqctl list_exchanges没有命名的Exchange 在前面的教程中,我们对Exchange一无所知,但是我们仍然可以将消息发送到队列中,这可能是因为我们使用了默认的Exchange,我们是通过空字符串""来定义这个Exchange的。 回想一下我们之前是怎么发布消息的:
channel.basicPublish("", "hello", null, message.getBytes());
//该方法的定义为:
basicPublish(String exchange, String routingKey, BasicProperties props, byte[] body) 上面代码的方法中,第一个参数就是Exchange的名字,空字符串表示默认或无名Exchange:消息通过由routingKey定义的队列被路由的。现在,我们通过下面的方式来发布消息:
channel.basicPublish( "logs", "", null, message.getBytes());临时队列
你可能记得之前我们使用了特定名字的队列(还记得hello和task_queue吗)。可以指明一个队列这一点对我们而言至关重要,因为我们也要让工作者指向同一个队列。当你在生产者和消费者之间共用一个队列时,给这个队列取个名字就非常重要。
但这不适应于我们的日志系统。我们想让每个消费者都接收到所有的日志消息,而不是其中的一部分日志消息。我们关心的是当前广播的消息而不是之前的那些。为了解决这些问题,我们需要做两件事情。
首先,无论何时我们连接到RabbitMQ服务的时候,我们都需要一个新鲜的空的队列。为了达到这个效果,我们可以为队列取一个随机的名字,或者更好的是,让RabbitMQ服务器为我们的队列随机起个名字。
其次,当我们关闭了消费者的时候,队列应该自动删除。
当我们调用无参的queueDeclare()的时候,意味着创建了一个非持久、独特的、自动删除的队列,并返回一个自动生成的名字:
String queueName = channel.queueDeclare().getQueue(); 这样就可以获取随机的队列名字了,这个名字看起来形如:amq.gen-JzTY20BRgKO-HjmUJj0wLg。
绑定
我们已经创建了一个fanout类型的Exchange和一个队列。现在我们需要告诉Exchange发送消息到我们的队列中。Exchange和队列之间的关系称为绑定。
channel.queueBind(queueName, "logs", "");

这样,我们创建的队列就和我们创建的logs路由器建立了关系,路由器就会将消息发送到这个队列中。可以通过下面的命令查看所有已经存在的绑定关系:
# sudo rabbitmqctl list_bindings整合到一起
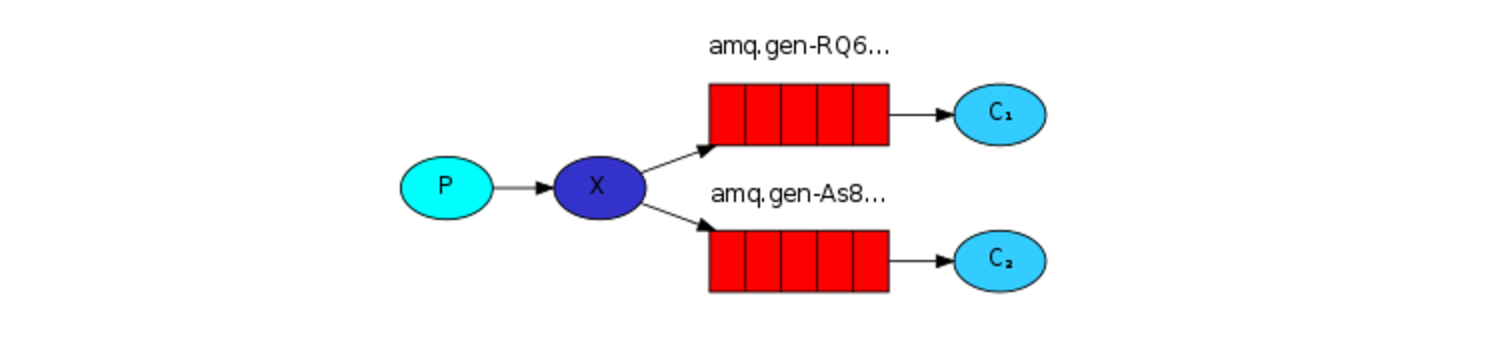
对生产者程序,它输出日志消息,与之前的教程并没与很大不同。最重要的改变就是,我们将消息发布给logs路由器,而不是无名的路由的。当发消息的时候,我们需要提供一个路由键routingKey,但是它的值会被fanout类型的路由器忽略,以下是生产者Publish.java
public class Publish {
private static final String EXCHANGE_NAME = "logs";
public static void main(String[] argv) throws Exception {
//建立连接和通道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.24.128");
factory.setUsername("admin");
factory.setPassword("admin");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//声明路由以及路由的类型
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.FANOUT);
String message = "msg...";
//发布消息
channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + message + "'");
//关闭连接和通道
channel.close();
connection.close();
}
}可以看到,在建立了连接之后,我们声明了路由器Exchange。这一步是必须的,因为不允许将消息发给一个不存在的路由器。
如果路由器还没有绑定队列,这些发送给路由器的消息将会丢失。但这对我们无所谓,如果还没有消费者监听,我们可以安全地丢弃这些消息。
消费者Subscribe.java的完整代码如下:
public class Subscribe {
private static final String EXCHANGE_NAME = "logs";
public static void main(String[] argv) throws Exception {
//建立连接和通道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.24.128");
factory.setUsername("admin");
factory.setPassword("admin");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//声明路由器及类型
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.FANOUT);
//声明一个随机名字的队列
String queueName = channel.queueDeclare().getQueue();
//绑定队列到路由器上
channel.queueBind(queueName, EXCHANGE_NAME, "");
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
//开始监听消息
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println(" [x] Received '" + message + "'");
}
};
channel.basicConsume(queueName, true, consumer);
}
}现在,可以运行程序并查看结果了。首先运行两个消费者实例,然后运行生产者。看看两个消费者实例是不是都接收到了所有的消息。
可以看到,当生产者发出消息后,两个消费者最终都收到了消息
为了验证我们的代码真正地将队列和路由器绑定到了一起,可以使用rabbitmqctl list_bindings命令查看绑定关系,假定我们运行了两个消费者,那么你应该可以看到如下的类似信息:
Listing bindings
exchange amq.gen-FuqxysSF0akXEawRd9678g queue amq.gen-FuqxysSF0akXEawRd9678g []
exchange amq.gen-YUDPKpiKHUCqs9MQwNCsLQ queue amq.gen-YUDPKpiKHUCqs9MQwNCsLQ []
exchange task_queue queue task_queue []
logs exchange amq.gen-FuqxysSF0akXEawRd9678g queue []
logs exchange amq.gen-YUDPKpiKHUCqs9MQwNCsLQ queue [] 从上面的结果可以看到,数据从logs路由器传输到两个随机名字的队列中,这正是我们想要的。
四.Routing
在上一个教程中,我们创建了一个简单的日志系统。我们可以将日志消息广播给所有的接收者(消费者)。
在这个教程中,我们将为我们的日志系统添加一个功能:仅仅订阅一部分消息。比如,我们可以直接将关键的错误类型日志消息保存到日志文件中,还可以同时将所有的日志消息打印到控制台
绑定(Bindings)
在之前的例子中,我们已经创建了绑定:
channel.queueBind(queueName, EXCHANGE_NAME, "");一个绑定是建立在一个队列和一个路由器之间的关系,可以解读为:该队列对这个路由器中的消息感兴趣。
绑定可以设置另外的参数:路由键routingKey。为了避免和void basicPublish(String exchange, String routingKey, BasicProperties props, byte[] body)中的routingKey混淆,我们将这里的key称为绑定键binding key,下面的代码展示了如何使用绑定键来创建一个绑定关系:
channel.queueBind(queueName, EXCHANGE_NAME, "black"); 绑定键的含义取决于路由器的类型,我们之前使用的fanout类型路由器会忽略该值。
直接路由器 (Direct Exchange)
我们之前的日志系统会将所有消息广播给所有消费者。现在我们想根据日志的严重程度来过滤日志。比如,我们想要一个程序来将error日志写到磁盘文件中,而不要将warning或info日志写到磁盘中,以免浪费磁盘空间。
我们之前使用的fanout路由器缺少灵活性,它只是没头脑地广播消息。所以,我们用direct路由器来替换它。direct路由器背后的路由算法很简单:只有当消息的路由键routing key与队列的绑定键binding key完全匹配时,该消息才会进入该队列。
为了演示上面拗口的表述中的意思,考虑下面的设置:
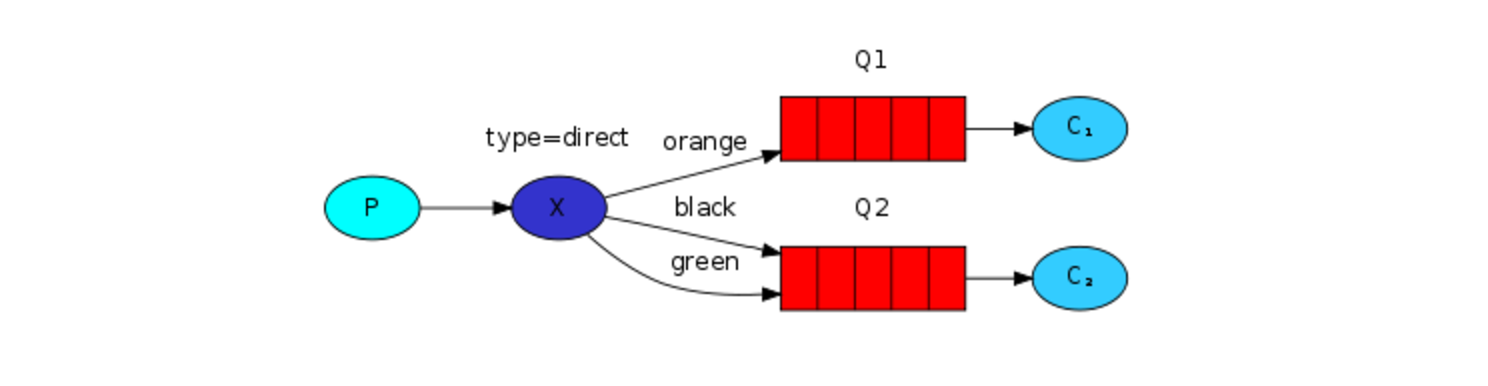
上图中,直接路由器x与两个队列绑定。第一个队列以绑定键orange来绑定,第二个队列以两个绑定键black和green和路由器绑定。
按照这种设置,路由键为orange的消息以发布给路由器后,将会被路由到队列Q1,路由键为black或者green的消息将会路由到队列Q2。
多重绑定(Multiple bindings)
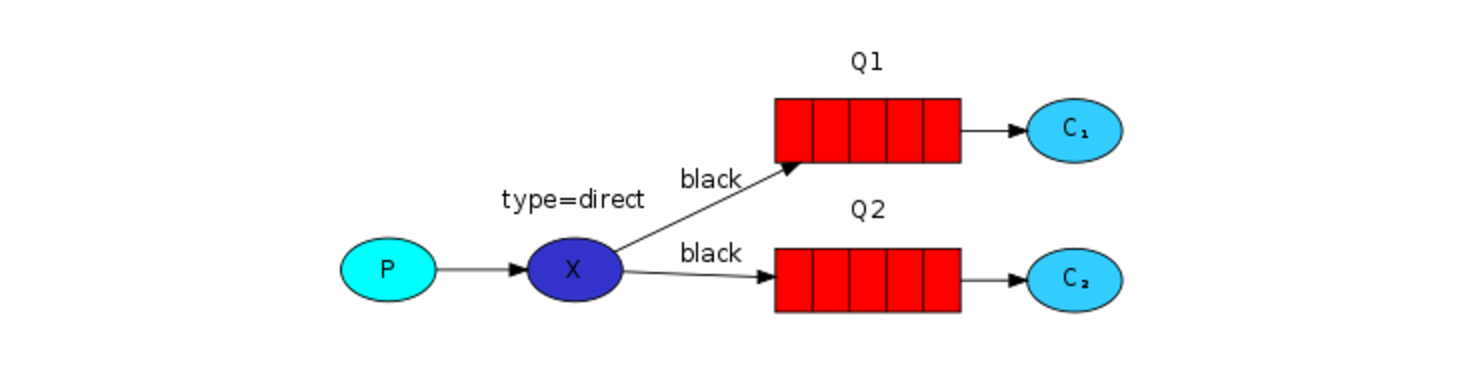
多个队列以相同的绑定键binding key绑定到同一个Exchange上,是完全可以的。按照这种方式设置的话,直接路由器就会像fanout路由器一样,将消息广播给所有符合路由规则的队列。一个路由键为black的消息将会发布到队列Q1和Q2。
发布消息
在这个教程中,我们使用direct路由器来代替上个教程中的fanout路由器。同时,我们为日志设置严重级别,并将此作为路由键。这样,接收者(消费者)就可以选择性地接收日志消息。 首先,创建一个路由器:
channel.exchangeDeclare(EXCHANGE_NAME, "direct");接着,发送一个消息:
channel.basicPublish(EXCHANGE_NAME, severity, null, message.getBytes());简单起见,我们假设severity只能是 info、warning、error中的一种。
消息订阅
接收消息将会和之前的教程类似,只是我们会为每一个级别的消息来创建不同的绑定:
String queueName = channel.queueDeclare().getQueue();
for(String severity : argv){
channel.queueBind(queueName, EXCHANGE_NAME, severity);
}放在一块
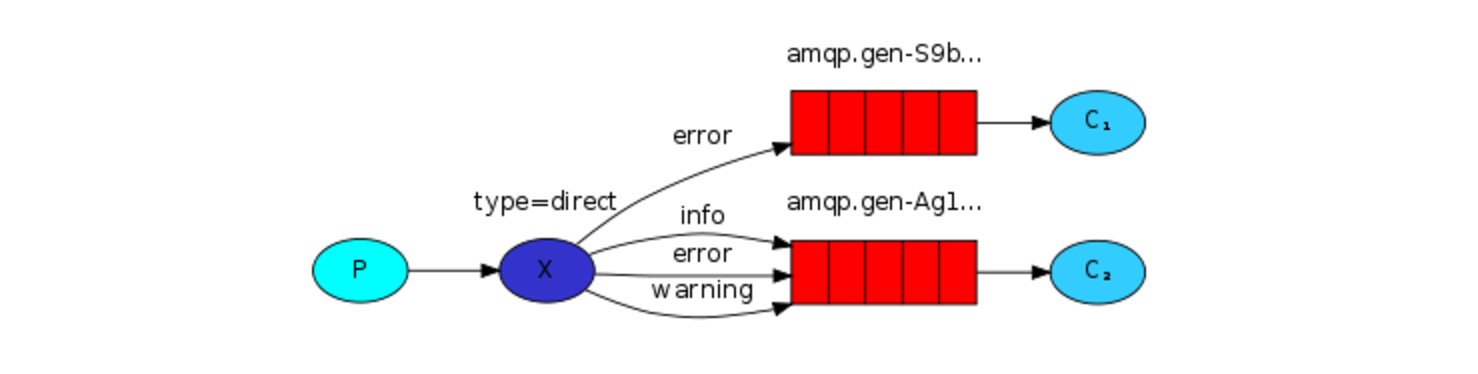
生产者代码
public class SendDirect {
private static final String EXCHANGE_NAME = "direct_logs";
public static void main(String[] argv) throws Exception {
//创建连接
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.24.128");
factory.setUsername("admin");
factory.setPassword("admin");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//声明路由器和路由器的类型
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
String severity = "info";
String message = ".........i am msg.........";
//发布消息
channel.basicPublish(EXCHANGE_NAME, severity, null, message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + severity + "':'" + message + "'");
channel.close();
connection.close();
}
}消费者代码
public class ReceiveDirect {
private static final String EXCHANGE_NAME = "direct_logs";
public static void main(String[] argv) throws Exception {
//建立连接和通道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.24.128");
factory.setUsername("admin");
factory.setPassword("admin");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//声明路由器和类型
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
//声明队列
String queueName = channel.queueDeclare().getQueue();
//定义要监听的级别
String[] severities = {"info", "warning", "error"};
//根据绑定键绑定
for (String severity : severities) {
channel.queueBind(queueName, EXCHANGE_NAME, severity);
}
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println(" [x] Received '" + envelope.getRoutingKey() + "':'" + message + "'");
}
};
channel.basicConsume(queueName, true, consumer);
}
} 现在可以进行测试了。首先,启动一个消费者实例,然后将其中的要监听的级别改为String[] severities = {"error"};,再启动另一个消费者实例。此时,这两个消费者都开始监听了,一个监听所有级别的日志消息,另一个监听error日志消息。 然后,启动生产者(EmitLogDirect.java),之后将String severity = "info";中的info,分别改为warning、error后运行。
五.Topic
在上一个教程中我们改进了我们的日志系统:使用direct路由器替代了fanout路由器,从而可以选择性地接收日志。
尽管使用direct路由器给我们的日志系统带了了改进,但仍然有一些限制:不能基于多种标准进行路由。
在我们的日志系统中,我们可能不仅需要根据日志的严重级别来接收日志,而且有时想基于日志来源进行路由。如果你知道syslog这个Unix工具,你可能了解这个概念,sysylog会基于日志严重级别(info/warn/crit...)和设备(auth/cron/kern...)进行日志分发。
如果我们可以监听来自corn的错误日志,同时也监听kern的所有日志,那么我们的日志系统就会更加灵活。
为了实现这个功能,我们需要了解一个复杂的路由器:topic路由器。
主题路由器(Topic Exchange)
发送到topic路由器的消息的路由键routing_key不能任意给定:它必须是一些单词的集合,中间用点号.分割。这些单词可以是任意的,但通常会体现出消息的特征。一些有效的路由键示例:stock.usd.nyse,nyse.vmw,quick.orange.rabbit。这些路由键可以包含很多单词,但路由键总长度不能超过255个字节。
绑定键binding key也必须是这种形式。topic路由器背后的逻辑与direct路由器类似:以特定路由键发送的消息将会发送到所有绑定键与之匹配的队列中。但绑定键有两种特殊的情况:
①*(星号)仅代表一个单词
②#(井号)代表任意个单词
下图可以很好地解释这两个符号的含义:
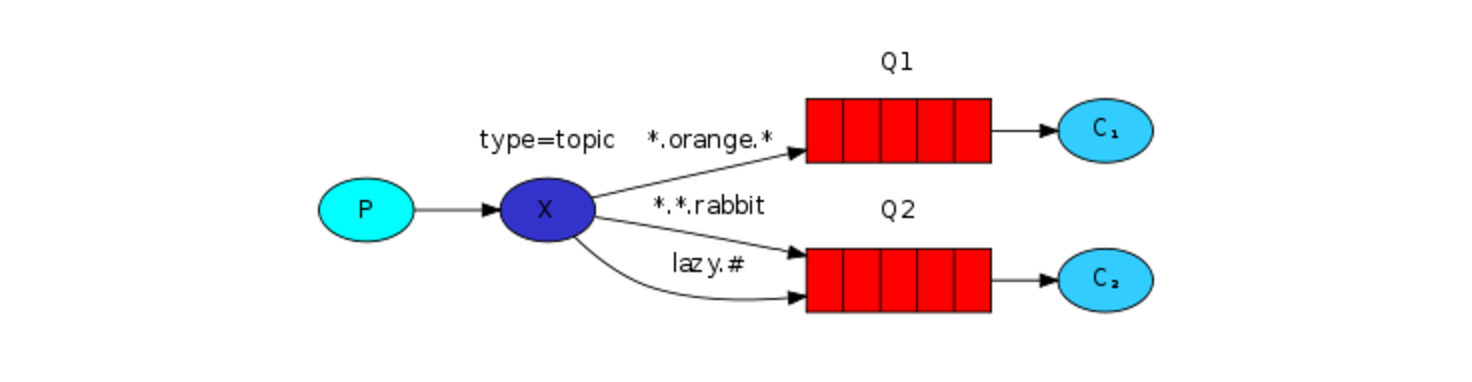
对于上图的例子,我们将会发送描述动物的消息。这些消息将会以由三个单词组成的路由键发送。路由键中的第一个单词描述了速度,第二个描述了颜色,第三个描述了物种:<speed>.<colour>.<species>。
我们创建了三个绑定,Q1的绑定键为*.orange.*,Q2的绑定键有两个,分别是*.*.rabbit和lazy.#。
上述绑定关系可以描述为:
①Q1关注所有颜色为orange的动物。
②Q2关注所有的rabbit,以及所有的lazy的动物。
如果一个消息的路由键是quick.orange.rabbit,那么Q1和Q2都可以接收到,路由键是lazy.orange.elephant的消息同样如此。但是,路由键是quick.orange.fox的消息只会到达Q1,路由键是lazy.brown.fox的消息只会到达Q2。注意,路由键为lazy.pink.rabbit的消息只会到达Q2一次,尽管它匹配了两个绑定键。路由键为quick.brown.fox的消息因为不和任意的绑定键匹配,所以将会被丢弃。
假如我们不按常理出牌:发送一个路由键只有一个单词或者四个单词的消息,像orange或者quick.orange.male.rabbit,这样的话,这些消息因为不和任意绑定键匹配,都将会丢弃。但是,lazy.orange.male.rabbit消息因为和lazy.#匹配,所以会到达Q2,尽管它包含四个单词。
Topic exchange Topic exchange非常强大,可以实现其他任意路由器的功能。 当一个队列以绑定键#绑定,它将会接收到所有的消息,而无视路由键(实际是绑定键#匹配了任意的路由键)。----这和fanout路由器一样了。 当*和#这两个特殊的字符不出现在绑定键中,Topic exchange就会和direct exchange类似了。
放在一块
我们将会在我们的日志系统中使用主题路由器Topic exchange,并假设所有的日志消息以两个单词<facility>.<severity>为路由键。
代码和上个教程几乎一样。
生产者SendTopic.java:
public class SendTopic {
private static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] argv) {
Connection connection = null;
Channel channel = null;
try {
//建立连接和通道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.24.128");
factory.setUsername("admin");
factory.setPassword("admin");
connection = factory.newConnection();
channel = connection.createChannel();
//声明路由器和路由器类型
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
//定义路由键和消息
String routingKey = "";
String message = "msg.....";
//发布消息
channel.basicPublish(EXCHANGE_NAME, routingKey, null, message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + routingKey + "':'" + message + "'");
} catch (Exception e) {
e.printStackTrace();
} finally {
if (connection != null) {
try {
connection.close();
} catch (Exception ignore) {
}
}
}
}
}消费者ReceiveTopic.java:
public class ReceiveTopic {
private static final String EXCHANGE_NAME = "topic_logs";
public static void main(String[] argv) throws Exception {
//建立连接和通道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.24.128");
factory.setUsername("admin");
factory.setPassword("admin");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
//声明路由器和路由器类型
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
String queueName = channel.queueDeclare().getQueue();
//
String bingingKeys[] = {""};
for (String bindingKey : bingingKeys) {
channel.queueBind(queueName, EXCHANGE_NAME, bindingKey);
}
System.out.println(" [*] Waiting for messages. To exit press CTRL+C");
//监听消息
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println(" [x] Received '" + envelope.getRoutingKey() + "':'" + message + "'");
}
};
channel.basicConsume(queueName, true, consumer);
}
} 现在,可以动手实验了。 开头提到的:日志严重级别info/warn/crit...和设备auth/cron/kern...。
消费者: 将String bingingKeys[] = {""}改为String bingingKeys[] = {"#"},启动第一个消费者; 再改为String bingingKeys[] = {"kern.*"},启动第二个消费者; 再改为String bingingKeys[] = {"*.critical"},启动第三个消费者; 再改为String bingingKeys[] = {"kern.*", "*.critical"},启动第四个消费者。
生产者,发送多个消息,如: 路由键为kern.critical 的消息:A critical kernel error; 路由键为kern.info 的消息:A kernel info; 路由键为kern.warn 的消息:A kernel warning; 路由键为auth.critical 的消息:A critical auth error; 路由键为cron.warn 的消息:A cron waning; 路由键为cron.critical 的消息:A critical cron error;
试试最后的结果:第一个消费者将会接收到所有的消息,第二个消费者将会kern的所有严重级别的日志,第三个消费者将会接收到所有设备的critical消息,第四个消费者将会接收到kern设备的所有消息和所有 critical消息。
六.RPC
远程过程调用(RPC)
在第二个教程中,我们学会了如何使用工作队列将耗时的任务分发给多个工作者。
但假如我们想调用远程电脑上的一个函数(或方法)并等待函数执行的结果,这时候该怎么办呢?好吧,这是一个不同的故事。这种模式通常称为远程过程调用RPC(Remote Procedure Call)。
在今天的教程中,我们将会使用RabbitMQ来建立一个RPC系统:一个客户端和一个可扩展的RPC服务端。因为我们没有任何现成的耗时任务,我们将会创建一个假的RPC服务,它将返回斐波那契数(Fibonacci numbers)。
客户端接口(Client interface)
为了演示如何使用RPC服务,我们将创建一个简单的客户端类。它负责暴露一个名为call的方法,该方法将发送一个RPC请求并阻塞,直到接收到回答。
FibonacciRpcClient fibonacciRpc = new FibonacciRpcClient();
String result = fibonacciRpc.call("4");
System.out.println( "fib(4) is " + result);关于RPC 尽管在计算领域RPC这种模式很普遍,但它仍备受批评。当程序员不清楚一个方法到底是本地的还是一个在远程机器上执行,问题就来了。此类疑惑通常给调试带来不必要的复杂性。相比简单的软件,不恰当的RPC使用会导致产生不可维护的面条代码(spaghetti code)。 将上面的话记在脑子里,并考虑一下建议: ①确保让哪个函数调用是本地调用哪个是远程调用看起来很明显。 ②为系统写文档,清楚地表述组件间的依赖关系。 ③处理错误,比如当RPC服务很久没有反应,客户端应该怎么办。 </br>尽量避免RPC。如果可能,你可以使用异步管道来代替RPC,像阻塞,结果将会异步地推送到下一个计算阶段。
回调队列(Callback queue)
使用RabbitMQ来做RPC很容易。客户端发送一个请求消息,服务端以一个响应消息回应。为了可以接收到响应,需要与请求(消息)一起,发送一个回调的队列。我们使用默认的队列(Java独有的):
callbackQueueName = channel.queueDeclare().getQueue();
BasicProperties props = new BasicProperties
.Builder()
.replyTo(callbackQueueName)
.build();
channel.basicPublish("", "rpc_queue", props, message.getBytes());
// ... then code to read a response message from the callback_queue ...消息属性 AMPQ 0-9-1协议预定义了消息的14种属性。大部分属性都很少用到,除了下面的几种: ①
deliveryMode:标记一个消息是持久的(值为2)还是短暂的(2以外的任何值),你可能还记得我们的第二个教程中用到过这个属性。 ②contentType:描述编码的mime-type(mime-type of the encoding)。比如最常使用JSON格式,就可以将该属性设置为application/json。 ③replyTo:通常用来命名一个回调队列。 ④correlationId:用来关联RPC的响应和请求。
我们需要引入一个新的类:
import com.rabbitmq.client.AMQP.BasicProperties;关联标识(Correlation Id)
在上面的方法中,我们为每一个RPC请求都创建了一个新的回调队列。这样做显然很低效,但幸好我们有更好的方式:让我们为每一个客户端创建一个回调队列。
这样做又引入了一个新的问题,在回调队列中收到响应后不知道到底是属于哪个请求的。这时候,Correlation Id就可以派上用场了。对每一个请求,我们都创建一个唯一性的值作为Correlation Id。之后,当我们从回调队列中收到消息的时候,就可以查找这个属性,基于这一点,我们就可以将一个响应和一个请求进行关联。如果我们看到一个不知道的Correlation Id值,我们就可以安全地丢弃该消息,因为它不属于我们的请求。
你可能会问,为什么要忽视回调队列中的不知道的消息,而不是直接以一个错误失败(failing with an error)。这是由于服务端可能存在的竞争条件。尽管不会,但这种情况仍有可能发生:RPC服务端在发给我们答案之后就挂掉了,还没来得及为请求发送一个确认信息。如果发生这种情况,重启后的RPC服务端将会重新处理该请求(因为没有给RabbitMQ发送确认消息,RabbitMQ会重新发送消息给RPC服务)。这就是为什么我们要在客户端优雅地处理重复响应,并且理想情况下,RPC服务要是幂等的。
总结
我们的RPC系统的工作流程如下:
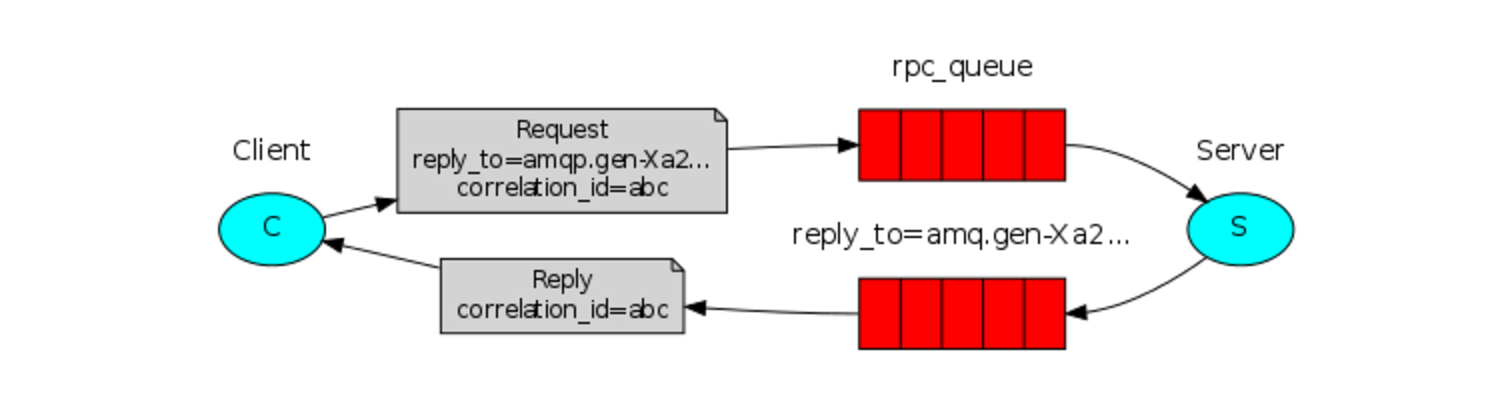
当客户端启动后,它会创建一个异步的独特的回调队列。对于一个RPC请求,客户端将会发送一个配置了两个属性的消息:一个是replyTo属性,设置为这个回调队列;另一个是correlation id属性,每一个请求都会设置为一个具有唯一性的值。这个请求将会发送到rpc_queue队列。
RPC工作者(即图中的server)将会等待rpc_queue队列的请求。当有请求到来时,它就会开始干活(计算斐波那契数)并将结果通过发送消息来返回,该返回消息发送到replyTo指定的队列。
客户端将等待回调队列返回数据。当返回的消息到达时,它将检查correlation id属性。如果该属性值和请求匹配,就将响应返回给程序。
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Consumer;
import com.rabbitmq.client.DefaultConsumer;
import com.rabbitmq.client.AMQP;
import com.rabbitmq.client.Envelope;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
public class RPCServer {
private static final String RPC_QUEUE_NAME = "rpc_queue";
//模拟的耗时任务,即计算斐波那契数
private static int fib(int n) {
if (n == 0) return 0;
if (n == 1) return 1;
return fib(n - 1) + fib(n - 2);
}
public static void main(String[] argv) {
//创建连接和通道
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
Connection connection = null;
try {
connection = factory.newConnection();
final Channel channel = connection.createChannel();
//声明队列
channel.queueDeclare(RPC_QUEUE_NAME, false, false, false, null);
//一次只从队列中取出一个消息
channel.basicQos(1);
System.out.println(" [x] Awaiting RPC requests");
//监听消息(即RPC请求)
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
AMQP.BasicProperties replyProps = new AMQP.BasicProperties
.Builder()
.correlationId(properties.getCorrelationId())
.build();
//收到RPC请求后开始处理
String response = "";
try {
String message = new String(body, "UTF-8");
int n = Integer.parseInt(message);
System.out.println(" [.] fib(" + message + ")");
response += fib(n);
} catch (RuntimeException e) {
System.out.println(" [.] " + e.toString());
} finally {
//处理完之后,返回响应(即发布消息)
System.out.println("[server current time] : " + System.currentTimeMillis());
channel.basicPublish("", properties.getReplyTo(), replyProps, response.getBytes("UTF-8"));
channel.basicAck(envelope.getDeliveryTag(), false);
}
}
};
channel.basicConsume(RPC_QUEUE_NAME, false, consumer);
//loop to prevent reaching finally block
while (true) {
try {
Thread.sleep(100);
} catch (InterruptedException _ignore) {
}
}
} catch (IOException | TimeoutException e) {
e.printStackTrace();
} finally {
if (connection != null)
try {
connection.close();
} catch (IOException _ignore) {
}
}
}
}RPC服务的代码很直白:
通常我们开始先建立连接、通道并声明队列。
我们可能会运行多个服务进程。为了负载均衡我们通过设置prefetchCount =1将任务分发给多个服务进程。
我们使用了basicConsume来连接队列,并通过一个DefaultConsumer对象提供回调。这个DefaultConsumer对象将进行工作并返回响应。
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.DefaultConsumer;
import com.rabbitmq.client.AMQP;
import com.rabbitmq.client.Envelope;
import java.io.IOException;
import java.util.UUID;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.TimeoutException;
public class RPCClient {
private Connection connection;
private Channel channel;
private String requestQueueName = "rpc_queue";
private String replyQueueName;
//定义一个RPC客户端
public RPCClient() throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("localhost");
connection = factory.newConnection();
channel = connection.createChannel();
replyQueueName = channel.queueDeclare().getQueue();
}
//真正地请求
public String call(String message) throws IOException, InterruptedException {
final String corrId = UUID.randomUUID().toString();
AMQP.BasicProperties props = new AMQP.BasicProperties
.Builder()
.correlationId(corrId)
.replyTo(replyQueueName)
.build();
channel.basicPublish("", requestQueueName, props, message.getBytes("UTF-8"));
final BlockingQueue<String> response = new ArrayBlockingQueue<String>(1);
channel.basicConsume(replyQueueName, true, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
if (properties.getCorrelationId().equals(corrId)) {
System.out.println("[client current time] : " + System.currentTimeMillis());
response.offer(new String(body, "UTF-8"));
}
}
});
return response.take();
}
//关闭连接
public void close() throws IOException {
connection.close();
}
public static void main(String[] argv) {
RPCClient fibonacciRpc = null;
String response = null;
try {
//创建一个RPC客户端
fibonacciRpc = new RPCClient();
System.out.println(" [x] Requesting fib(30)");
//RPC客户端发送调用请求,并等待影响,直到接收到
response = fibonacciRpc.call("30");
System.out.println(" [.] Got '" + response + "'");
} catch (IOException | TimeoutException | InterruptedException e) {
e.printStackTrace();
} finally {
if (fibonacciRpc != null) {
try {
//关闭RPC客户的连接
fibonacciRpc.close();
} catch (IOException _ignore) {
}
}
}
}
}客户端代码看起来有一些复杂:我们建立连接和通道,并声明了一个独特的回调队列。我们订阅这个回调队列,所以我们可以接收RPC响应。我们的call方法执行RPC请求。在call方法中,我们首先生成一个具有唯一性的correlationId值并存在变量corrId中。我们的DefaultConsumer中的实现方法handleDelivery会使用这个值来获取争取的响应。然后,我们发布了这个请求消息,并设置了replyTo和correlationId这两个属性。好了,现在我们可以坐下来耐心等待响应到来了。由于我们的消费者处理(指handleDelivery方法)是在子线程进行的,因此我们需要在响应到来之前暂停主线程(否则主线程结束了,子线程接收到了影响传给谁啊)。使用BlockingQueue是一种解决方案。在这里我们创建了一个阻塞队列ArrayBlockingQueue并将它的容量设为1,因为我们只需要接受一个响应就可以啦。handleDelivery方法所做的很简单,当有响应来的时候,就检查是不是和correlationId匹配,匹配的话就放到阻塞队列ArrayBlockingQueue中。同时,主线程正等待影响。最终我们就可以将影响返回给用户了。
现在,可以动手实验了。首先,执行RPC服务端,让它等待请求的到来。
[x] Awaiting RPC requests然后,执行RPC客户端,即RPCClient中的main方法,发起请求:
[x] Requesting fib(30)
[client current time] : 1500474305838
[.] Got '832040'可以看到,客户端很快就接受到了请求,回头看RPC服务端的时间:[.] fib(30)
[server current time] : 1500474305835 上面这种设计并不是RPC服务端的唯一实现,但是它有以下几个重要的优势:①如果RPC服务端很慢,你可以通过运行多个实例就可以实现扩展。②在RPC客户端,RPC要求发送和接受一个消息。非同步的方法queueDeclare是必须的。这样,RPC客户端只需要为一个RPC请求只进行一次网络往返。
但我们的代码仍然太简单,并没有处理更复杂但也非常重要的问题,像:①如果没有服务端在运行,客户端该怎么办②客户端应该为一次RPC设置超时吗③如果服务端发生故障并抛出异常,它还应该返回给客户端吗?④在处理消息前,先通过边界检查、类型判断等手段过滤掉无效的消息等
代码地址:https://gitee.com/weixiaotao1992/Working/tree/master/technology_code/rabbitmq
来源:oschina
链接:https://my.oschina.net/u/4269622/blog/3646958